
【YOLO-V3-SPP 源码解读】二、模型搭建
以下的全部内容都是构建yolov3_spp模型另外下面的所有的内容都是按照代码执行的顺序进行讲解的在网络搭建之前大家应该已经准备好了自己的数据集,并将数据集转换为yolo的格式,如果不是很清楚的朋友可以看看我的另一篇文章一、数据集制作和格式处理一、生成模型对应的cfg文件我们拿到官方给的yolov3-spp.cfg 文件,是不能直接开始训练的,因为官方给的文件是默认在VOC数据集训练的,所以还需要
以下的全部内容都是构建yolov3_spp模型
另外下面的所有的内容都是按照代码执行的顺序进行讲解的
在网络搭建之前大家应该已经准备好了自己的数据集,并将数据集转换为yolo的格式,如果不是很清楚的朋友可以看看我的另一篇文章一、数据集制作和格式处理
项目全部代码已上传至GitHub: yolov3-spp-annotations.
目录标题
下图是整个模型搭建的流程: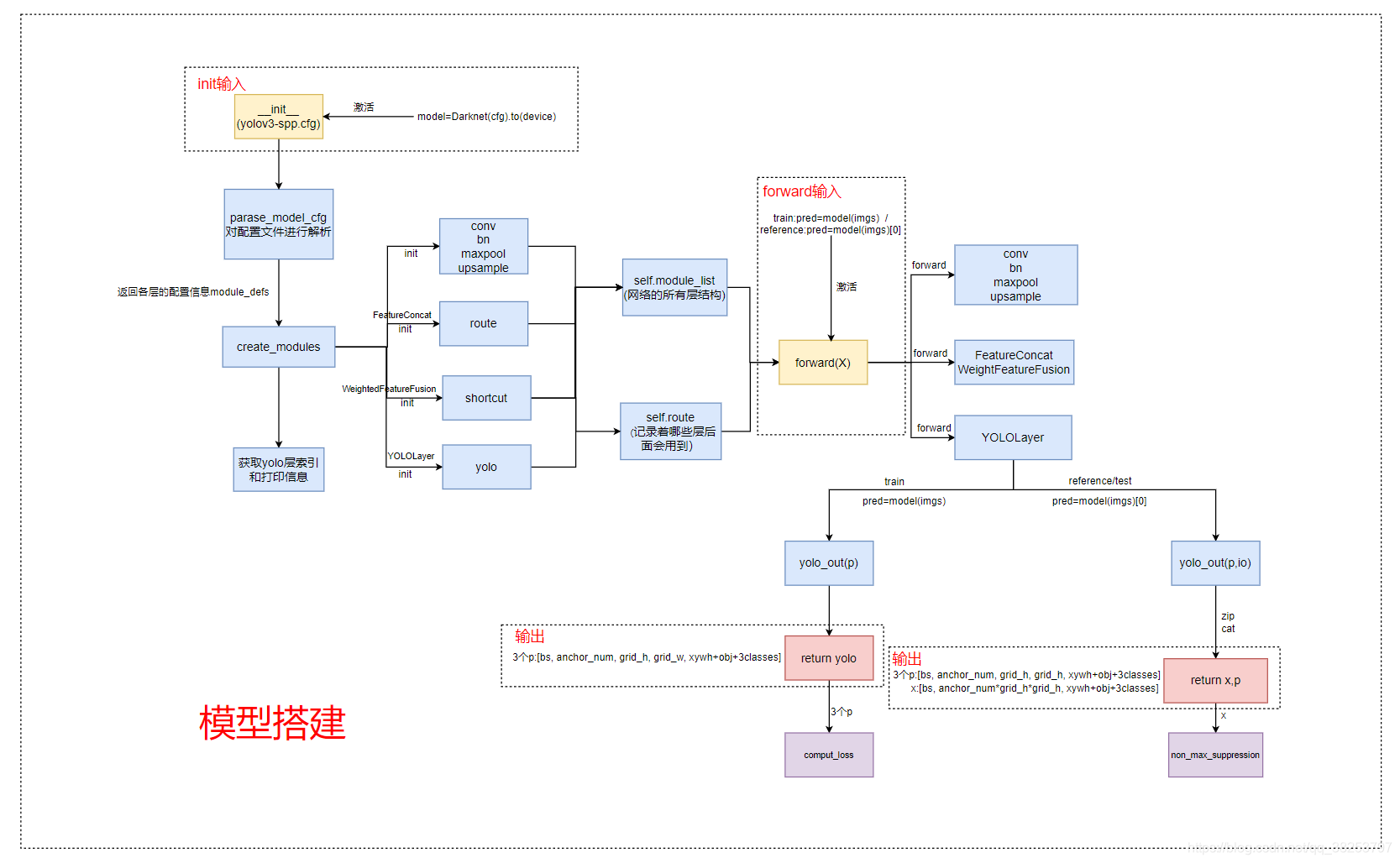
一、生成模型对应的cfg文件
我们拿到官方给的yolov3-spp.cfg 文件,是不能直接开始训练的,因为官方给的文件是默认在VOC数据集训练的,所以还需要修改一下yolo层的classes数和yolo前一层的卷积核个数,如下图: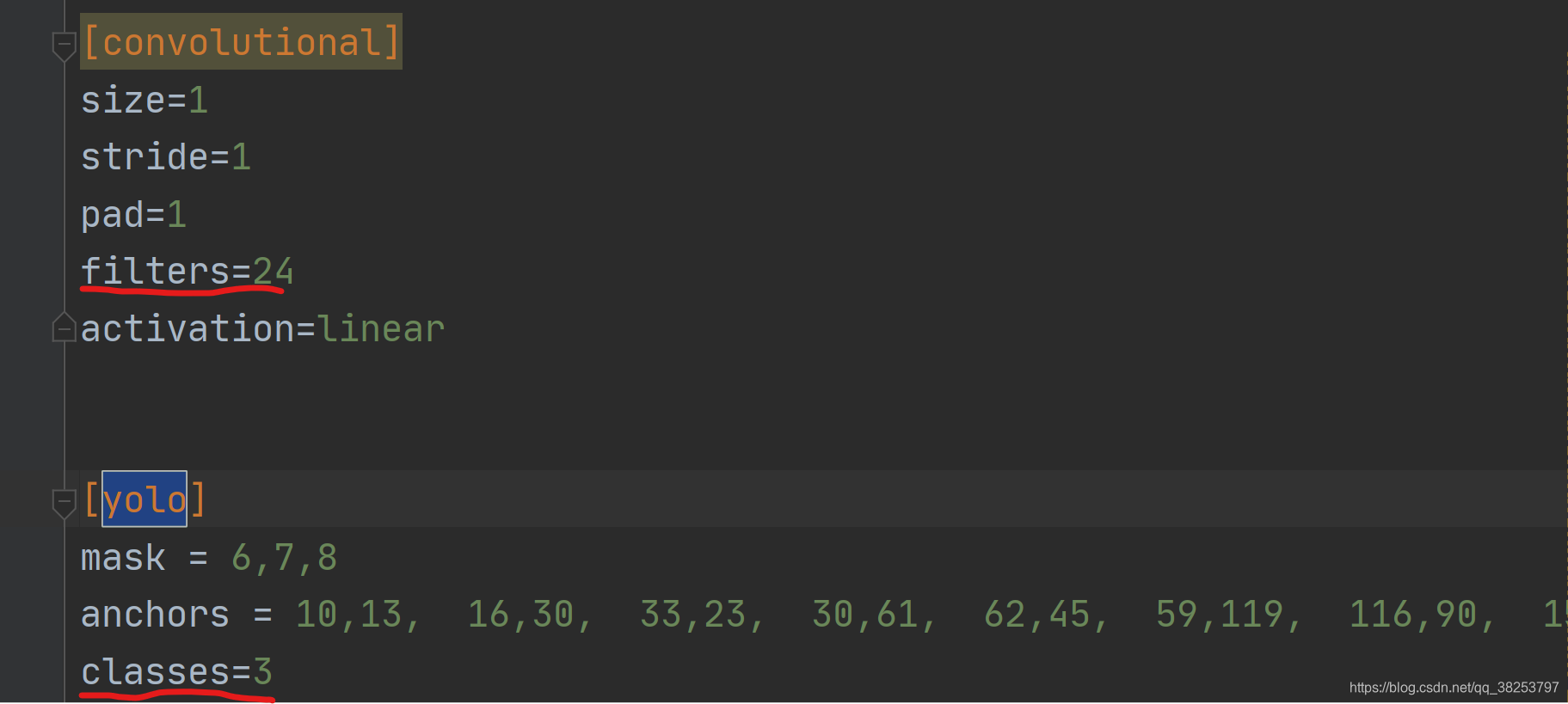
注意:因为yolov3-spp整个模型架构有三个yolo预测层,所以不要忘了,需要修改三个yolo层的classes数和yolo前一层的卷积核个数,当然网上关于这部分有人是写好了脚本的,感兴趣的也可以去查一下。
二、网络初始化
在源码中网络初始化的入口:
model = Darknet(cfg).to(device)
关于网络的初始化过程,主要就是调用了Darknet函数的__init__()函数:
class DarkNet(nn.Module):
def __init__(self, cfg, verbose=True):
"""
:param cfg: 网络模型对应的cfg配置文件
:param verbose: 是否需要打印模型信息 True打印 False不打印
"""
super(DarkNet, self).__init__()
# 解析网络对应的.cfg文件
self.module_defs = parse_model_cfg(cfg)
# 根据解析的网络结构一层一层去初始化网络
# module_list: 所有层结构 self.routs: 后面会用到那些层(concat/shortcut)
self.module_list, self.routs = create_modules(self.module_defs)
# 获取所有YOLOLayer层的索引
self.yolo_layers = get_yolo_layers(self)
# 打印下模型的信息,如果verbose为True则打印详细信息
self.info(verbose) # print model description
下面再根据源码详细解释下网络初始化的每一步。
2.1、解析cfg文件
在Darknet的初始化函数__init__中调用parse_model_cfg(cfg)函数:
self.module_defs = parse_model_cfg(cfg)
parse_model_cfg(cfg)函数:
def parse_model_cfg(path: str):
"""
读取并解析模型的配置文件(cfg)
:param path: 配置文件地址 如:cfg/yolov3-spp.cfg
:return mdefs: 返回一个list,list中由很多的dict字典组成,每个字典对应一层的信息(第0层是net)
"""
# 1、检查配置文件是否存在/格式是否正确
if not path.endswith(".cfg") or not os.path.exists(path):
raise FileNotFoundError("the cfg file not exist...")
# 2、读取配置文件所有信息 用换行符进行分割
with open(path, "r") as f:
lines = f.read().split("\n")
# 3、去除空行和注释行
lines = [x for x in lines if x and not x.startswith("#")]
# 4、去除每行开头和结尾的空格符
lines = [x.strip() for x in lines]
# 5、开始解析每一行
mdefs = [] # module definitions
for line in lines:
# 筛选后,所有的line都只剩两种情况: 1、[tpye名] 2、key=val
if line.startswith("["): # this marks the start of a new block
mdefs.append({})
mdefs[-1]["type"] = line[1:-1].strip() # 记录module类型 type=层结构名称
# 如果是卷积模块,设置默认不使用BN
if mdefs[-1]["type"] == "convolutional":
mdefs[-1]["batch_normalize"] = 0
else:
key, val = line.split("=")
key = key.strip() # 去除前后的空格
val = val.strip()
if key == "anchors":
# anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
val = val.replace(" ", "") # 将空格去除
# 将shape (1, 18)=>(9, 2) 九个anchors
mdefs[-1][key] = np.array([float(x) for x in val.split(",")]).reshape((-1, 2)) # np anchors
elif (key in ["from", "layers", "mask"]) or (key == "size" and "," in val):
# 如果是from/layers/mask, 就将值以数组的形式存储(一般是多个值)
mdefs[-1][key] = [int(x) for x in val.split(",")]
else:
# 其他情况就是一般的一个key对应一个val存储起来
# TODO: .isnumeric() actually fails to get the float case
if val.isnumeric(): # return int or float 如果是数值的情况
mdefs[-1][key] = int(val) if (int(val) - float(val)) == 0 else float(val)
else:
mdefs[-1][key] = val # return string 是字符的情况
# 6、检测所有读出的配置信息k是否符合标准 check all fields are supported
supported = ['type', 'batch_normalize', 'filters', 'size', 'stride', 'pad', 'activation', 'layers', 'groups',
'from', 'mask', 'anchors', 'classes', 'num', 'jitter', 'ignore_thresh', 'truth_thresh', 'random',
'stride_x', 'stride_y', 'weights_type', 'weights_normalization', 'scale_x_y', 'beta_nms', 'nms_kind',
'iou_loss', 'iou_normalizer', 'cls_normalizer', 'iou_thresh', 'probability']
# 遍历检查每个模型的配置
for x in mdefs[1:]: # 0对应net配置
# 遍历每个配置字典中的key值
for k in x:
if k not in supported:
raise ValueError("Unsupported fields:{} in cfg".format(k))
return mdefs
2.2、初始化各层结构
这一步是根据上一节解析出来的配置文件的信息进行初始化网络模型
具体的操作就是在Darknet的初始化函数__init__中调用create_modules(self.module_defs)函数:
self.module_list, self.routs = create_modules(self.module_defs)
def create_modules(modules_defs: list):
"""
:param modules_defs: 保存着解析模型配置文件后的每一层的信息
:return module_list: 保存着根据解析后的模型配置信息初始化的每一层的结构
:return routs_binary: 记录着哪些层在后面可能还会用到(concat/shortcut) 还会用到True 不会用到False
"""
hyperparams = modules_defs.pop(0) # 除去cfg training hyperparams (unused)
output_filters = [int(hyperparams['channels'])] # 保存每一层的输出channel(包括输入RGB图像的3个channels)
module_list = nn.ModuleList() # 保存每一层 每一层依次append进来
# 统计哪些特征层的输出会被后续的层使用到(可能是特征融合,也可能是拼接) 来自于concat,shortcut,yolo前一层(predictor)
routs = []
# 记录当前yolo是第几个yolo层
yolo_index = -1
# 遍历搭建每个层结构
for i, mdef in enumerate(modules_defs):
modules = nn.Sequential() # 初始化每一层
# 初始化所有卷积层
if mdef["type"] == "convolutional":
# 读取该层的所有信息
bn = mdef["batch_normalize"] # 1 or 0 / use or not 使用的话bias=false
filters = mdef["filters"] # 卷积核个数
k = mdef["size"] # 卷积核size
# 矩形 (mdef['stride_y'], mdef["stride_x"]) 没用到, 这里的stride都有
stride = mdef["stride"] if "stride" in mdef else (mdef['stride_y'], mdef["stride_x"])
padding = k // 2 if mdef["pad"] else 0 # 卷积padding
if isinstance(k, int):
modules.add_module("Conv2d", nn.Conv2d(in_channels=output_filters[-1], # 输入为上一层的输出 最开始是3
out_channels=filters,
kernel_size=k,
stride=stride,
padding=padding,
bias=not bn))
else:
raise TypeError("conv2d filter size must be int type")
if bn:
modules.add_module("BatchNorm2d", nn.BatchNorm2d(filters))
else:
# 在网络当中所有卷积层都使用bn层, 只用在yolo层前的一个卷积层(predictor预测层)没有bn层
# 如果该卷积操作没有bn层,意味着该层为yolo的predictor
routs.append(i)
if mdef["activation"] == "leaky":
modules.add_module("activation", nn.LeakyReLU(0.1, inplace=True))
else:
# 这里还可以选择其他的激活函数,如swish, mish等
pass
# yolov3-spp的结构中每一个bn都是接在conv后面的,所以只需要在conv层搭建的时候构建bn就可以了
elif mdef["type"] == "BatchNorm2d":
pass
# 初始化所有maxpool层
elif mdef["type"] == "maxpool":
# 普通的yolo结构是没有maxpool层的 只有在spp模块中使用了maxpool层
k = mdef["size"]
stride = mdef["stride"]
maxpool = nn.MaxPool2d(kernel_size=k, stride=stride, padding=(k-1)//2)
if k == 2 and stride == 1: # yolo-v3-tiny
modules.add_module("ZeroPad2d", nn.ZeroPad2d((0, 1, 0, 1)))
modules.add_module("MaxPool2d", maxpool)
else:
modules = maxpool
# 初始化所有上采样层
elif mdef["type"] == "upsample":
modules = nn.Upsample(scale_factor=mdef["stride"]) # scale_factor: 上采样率
# 初始化所有的concat操作
elif mdef["type"] == "route":
# layers:当前需要进行concat操作的所有层的层号 比如layers=-1,-3,-5,-6
layers = mdef["layers"]
# filters:concat之后得到feature map的channel个数 其中output_filters记录着所有层的输出channel
# 当l>0时是正着数的,需要l+1(net层);当l<0时是反着数,就直接l就行了
filters = sum([output_filters[l + 1 if l > 0 else l] for l in layers])
# routs:统计哪些特征层的输出会被后续的层使用到 concat
routs.extend([i + l if l < 0 else l for l in layers]) # i=当前层索引
modules = FeatureConcat(layers=layers) # 这里modules的类名就便成了FeatureConcat而不是Sequential
# 初始化所有残差结构
elif mdef["type"] == "shortcut":
# layers 全是 -3 from: 从当前layer往前数第3个层建立到当前层的shortcut
layers = mdef["from"]
# filters=上一层输出的channel
filters = output_filters[-1]
# routs.extend([i + l if l < 0 else l for l in layers]) 这里layers都是只用一个-3 所以可以简写下
routs.append(i + layers[0])
# shortcut操作 这里的weight=False 因为cfg中并没有weights_type这个参数 这里我们不做考虑
# 同理这里的类名变为WeightedFeatureFusion
modules = WeightedFeatureFusion(layers=layers, weight="weights_type" in mdef)
# 对YOLO的输出(predictor输出)进行处理
# 本质上这部分并不是网络构建的部分,有点像后处理了,写在这里也是为了方便
elif mdef["type"] == "yolo":
yolo_index += 1 # 记录是第几个yolo_layer 0, 1, 2
stride = [32, 16, 8] # 预测特征层对应原图的缩放比例(对应的是yolo_index)
# anchors: 当前predictor使用哪几个anchors mask=anchor index
# nc: 数据集类别个数
# stride: 当前predictor输出feature map与原图的缩放比例
modules = YOLOLayer(anchors=mdef["anchors"][mdef["mask"]],
nc=mdef["classes"],
stride=stride[yolo_index])
# 初始化 yolo layer前一层conv(predictor)的bias 这一层没有BN, 所以前一层conv的bias要有初始化
# Initialize preceding Conv2d() bias (https://arxiv.org/pdf/1708.02002.pdf section 3.3)
try:
j = -1 # yolo层上一层
bias_ = module_list[j][0].bias # shape(255,) 索引0对应Sequential中的Conv2d
bias = bias_.view(modules.na, -1) # shape(3, 85)
bias[:, 4] += -4.5 # obj
bias[:, 5:] += math.log(0.6 / (modules.nc - 0.99)) # cls (sigmoid(p) = 1/nc)
# 其实不是很明白这里为什么传到是bias_而不是bias,那改变bias的意义在哪里???可能后面需要看下论文
module_list[j][0].bias = torch.nn.Parameter(bias_, requires_grad=bias_.requires_grad)
except Exception as e:
print('WARNING: smart bias initialization failure.', e)
else:
print("Warning: Unrecognized Layer Type: " + mdef["type"])
module_list.append(modules)
output_filters.append(filters)
# routs_binary 记录那些层在后面还会用到(concat/shortcut) 还会用到True 不会用到False
routs_binary = [False] * len(modules_defs)
for i in routs:
routs_binary[i] = True
return module_list, routs_binary
上述代码大体上还是比较简单的,主要的难点在于以下几点:
1、关于concat结构的初始化
class FeatureConcat(nn.Module):
"""将多个特征矩阵在channel维度进行concatenate拼接"""
def __init__(self, layers):
"""
:param layers: 记录下当前需要进行concat操作的所有层的层号 比如layers=-1,-3,-5,-6
"""
super(FeatureConcat, self).__init__()
self.layers = layers # layer index 记录当前需要concat的层序号
self.multiple = len(layers) > 1 # 是否是多层concat
2、关于残差结构的初始化
class WeightedFeatureFusion(nn.Module):
# weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070
"""将多个特征矩阵的值进行融合(add操作) 只在残差结构用到 只在2个特征矩阵进行融合"""
def __init__(self, layers, weight=False):
"""
:param layers: 从当前layer往前数第3个层建立到当前层的shortcut 实际上这里全都是[-3]
:param weight: False 这里是扩展功能 我们先不做考虑 没用到
"""
super(WeightedFeatureFusion, self).__init__()
self.layers = layers # layer index 需要进行融合(add)
self.weight = weight # apply weights boolean 没用到
self.n = len(layers) + 1 # number of layers 融合的特征矩阵个数 这里都是2
if weight:
self.w = nn.Parameter(torch.zeros(self.n), requires_grad=True) # layer weights
3、关于predictor输出进行处理
本质上来说这部分的内容并不是网络构建的内容,应该是属于数据后处理的部分了(对输出预测结果进行处理),但是源码把这部分写在这里,应该是为了方便处理吧。
详情请看YOLOLayer函数:
class YOLOLayer(nn.Module):
def __init__(self, anchors, nc, stride):
"""
YOLOLayer是对predictor的输出进行一个处理,它本质上并不属于网络构建的模块
:param anchors: 当前predictor的anchor list(一般是三个)
:param nc: 数据集类别个数
:param stride: 当前predictor输出feature map与原图的缩放比例
"""
super(YOLOLayer, self).__init__()
self.anchors = torch.Tensor(anchors) # 当前predictor的anchor list(一般是三个)
self.stride = stride # 特征图上一步对应原图上的步距 32/16/8 = feature map与原图的缩放比例
self.na = len(anchors) # na: anchor的数量
self.nc = nc # nc: 数据集的类别数
self.no = nc + 5 # number of outputs 8( x, y, w, h, confidence, cls1, cls2, cls3)
self.nx, self.ny, self.ng = 0, 0, (0, 0) # initialize number of x, y gridpoints
self.anchor_vec = self.anchors / self.stride # 将anchors大小缩放到预测特征层上的尺度
# self.anchor_wh = [batch_size, num of anchors, grid_h, grid_w, wh]=[1,3,1,1,2]
# self.anchor_wh:对应的是anchor映射在feature map上的高度和宽度
self.anchor_wh = self.anchor_vec.view(1, self.na, 1, 1, 2)
self.grid = None # 正向传播会重新赋值 self.grid=预测feature map上划分的每个网格的左上角坐标
2.3、获取所有YOLOLayer
这部分就是获取所有yolo层的index,很简单,直接上代码:
def get_yolo_layers(self):
"""
获取网络中三个"YOLOLayer"模块对应的索引
:return: 返回三个"YOLOLayer"模块对应的索引 [89, 101, 113]
"""
return [i for i, m in enumerate(self.module_list) if m.__class__.__name__ == 'YOLOLayer']
最后关于打印模型信息的代码,这里就不讲解了,因为并不是必须的部分,感兴趣可以自己读一读。
三、forward前向传播
在源码中forward前向传播的入口:
1、training阶段
pred = model(imgs)
2、reference阶段
pred = model(imgs)[0]
连个阶段的调用区别主要是因为yolo层的forward返回的参数不相同。
主要调用的是Darknet函数的forward函数:
class DarkNet(nn.Module):
def __init__(self, cfg, verbose=True):
"""
:param cfg: 网络模型对应的cfg配置文件
:param verbose: 是否需要打印模型信息 True打印 False不打印
"""
super(DarkNet, self).__init__()
# 解析网络对应的.cfg文件
self.module_defs = parse_model_cfg(cfg)
# 根据解析的网络结构一层一层去初始化网络
# module_list: 所有层结构 self.routs: 后面会用到那些层(concat/shortcut在前向传播时需要用到)
self.module_list, self.routs = create_modules(self.module_defs)
# 获取所有YOLOLayer层的索引
self.yolo_layers = get_yolo_layers(self)
# 打印下模型的信息,如果verbose为True则打印详细信息
self.info(verbose) # print model description
def forward(self, x, verbose=False):
return self.forward_once(x, verbose=verbose)
def forward_once(self, x, verbose=False):
"""
正向传播过程
:param x: 输出的图像数据
:param verbose: 是否需要打印模型信息 True打印 False不打印
下面代码涉及到的verbose其实并不需要太关注 只是一些简单的信息打印
:return: train 直接返回3个预测层的预测输出值(没有进行任何数值上的处理)
yolo_out [1, 3, 13, 13, 8] [batch_size, anchor_num, grid_h, grid_w, xywh + obj + classes]
reference 返回两个 x, p
x: predictor数据处理后的输出(数值发生变化) [batch_size, anchor_num*grid*grid, xywh + obj + classes]
p: predictor原始输出 [batch_size, anchor_num, grid, grid, xywh + obj + classes]
"""
# yolo_out收集每个yolo_layer(predictor)的输出
# out收集所有self.routs[i]=True层的输出(将在shortcut/concat中使用到)
yolo_out, out = [], []
if verbose:
print('0', x.shape)
str = ""
# 遍历每一层结构 进行正向传播
for i, module in enumerate(self.module_list):
name = module.__class__.__name__ # 返回当前层的类名
if name in ["WeightedFeatureFusion", "FeatureConcat"]: # shortcut, concat
if verbose:
l = [i - 1] + module.layers # layers
sh = [list(x.shape)] + [list(out[i].shape) for i in module.layers] # shapes
str = ' >> ' + ' + '.join(['layer %g %s' % x for x in zip(l, sh)])
x = module(x, out) # WeightedFeatureFusion(), FeatureConcat()
elif name == "YOLOLayer":
yolo_out.append(module(x)) # 将yolo层的输出(predictor)依次保存在yolo_out(分为train和reference两种情况)
else:
# run module directly
# i.e. mtype = 'convolutional', 'upsample', 'maxpool', 'batchnorm2d' etc.
x = module(x)
out.append(x if self.routs[i] else []) # 将每一层的输出依次加入out
if verbose:
print('%g/%g %s -' % (i, len(self.module_list), name), list(x.shape), str)
str = ''
if self.training:
# train yolo_out = [1, 3, 13, 13, 8] [batch_size, anchor_num, grid_h, grid_w, xywh + obj + classes]
# 训练模式直接返回3个预测层的预测输出值(没有进行任何数值上的处理)
return yolo_out
else:
# inference or test
# yolo_out 3个tuple 每个tuple存放着一个predictor的原始(没进行数值处理)输出p 和 一个已经经过数值处理后的输出io
# zip(*yolo_out) 将yolo_out中的3个tuple中的p合在一起传给p 3个tuple中的io合在一起传给x x=[1,507,8][1,2028,8][1,8112,8]
x, p = zip(*yolo_out)
# concat yolo outputs 将三个anchor输出在第一个维度上concat
# x=[1, 10647, 8]
x = torch.cat(x, 1)
# p: predictor原始输出 [batch_size, anchor_num, grid, grid, xywh + obj + classes]
# x: predictor数据处理后的输出 [batch_size, anchor_num*grid*grid, xywh + obj + classes]
return x, p
这里的主要难点是集中在:concat的forward、shortcut的forward、YOLOLayer的forward以及对Darknet的forward输出的理解;而其他层如’convolutional’, ‘upsample’, ‘maxpool’, 'batchnorm2d’等就相对比较简单了,只是做了个简单的传值计算(x = module(x)),这里就不多讲了,详情看上面代码。
3.1、concat的forward
入口:

class FeatureConcat(nn.Module):
"""将多个特征矩阵在channel维度进行concatenate拼接"""
def __init__(self, layers):
"""
:param layers: 记录下当前需要进行concat操作的所有层的层号 比如layers=-1,-3,-5,-6
"""
super(FeatureConcat, self).__init__()
self.layers = layers # layer index 记录当前需要concat的层序号
self.multiple = len(layers) > 1 # 是否是多层concat
def forward(self, x, outputs):
"""
:param outputs: 记录网络中每一层的输出feature map
:return: 返回concat之后的feature map
"""
return torch.cat([outputs[i] for i in self.layers], 1) if self.multiple else outputs[self.layers[0]]
3.2、shortcut的forward
入口:
class WeightedFeatureFusion(nn.Module):
# weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070
"""将多个特征矩阵的值进行融合(add操作) 只在残差结构用到 只在2个特征矩阵进行融合"""
def __init__(self, layers, weight=False):
"""
:param layers: 从当前layer往前数第3个层建立到当前层的shortcut 实际上这里全都是[-3]
:param weight: False 这里是扩展功能 我们先不做考虑 没用到
"""
super(WeightedFeatureFusion, self).__init__()
self.layers = layers # layer index 需要进行融合(add)
self.weight = weight # apply weights boolean 没用到
self.n = len(layers) + 1 # number of layers 融合的特征矩阵个数 这里都是2
if weight:
self.w = nn.Parameter(torch.zeros(self.n), requires_grad=True) # layer weights
def forward(self, x, outputs):
"""
:param x: 输入的特征矩阵 shortcut前一个卷积的输出特征
:param outputs: 收集的整个网络的每一个模块的输出
:return: 返回shortcut后的feature map
"""
# Weights 跳过 不执行
if self.weight:
w = torch.sigmoid(self.w) * (2 / self.n) # sigmoid weights (0-1)
x = x * w[0]
# Fusion
nx = x.shape[1] # input channels
# 这里只会遍历一次 shortcut只是两个特征矩阵进行融合 self.n=2
for i in range(self.n - 1):
# 其实执行的是a = outputs[self.layers[i]] a=要融合的层结构的feature map
a = outputs[self.layers[i]] * w[i + 1] if self.weight else outputs[self.layers[i]]
na = a.shape[1] # 取出要融合的层结构的feature map的channels
# Adjust channels
# 根据相加的两个特征矩阵的channel选择相加方式
if nx == na: # 残差结构只是用到这个 same shape 如果channel相同,直接相加
x = x + a
# 下面其实是不执行的
elif nx > na: # slice input 如果channel不同,将channel多的特征矩阵砍掉部分channel保证相加的channel一致
x[:, :na] = x[:, :na] + a # or a = nn.ZeroPad2d((0, 0, 0, 0, 0, dc))(a); x = x + a
else: # slice feature
x = x + a[:, :nx]
return x
3.3、YOLOLayer的forward
这部分本质上来说并不是模型构建的内容,放在这里一起写应该是为了代码方便。而且这部分也是非常非常重要的代码,和yolov3的原理息息相关,一定要掌握
入口:
这部分应该是模型构建部分最难的一部分代码了,为了方便大家理解我这里画了个这部分代码流程图: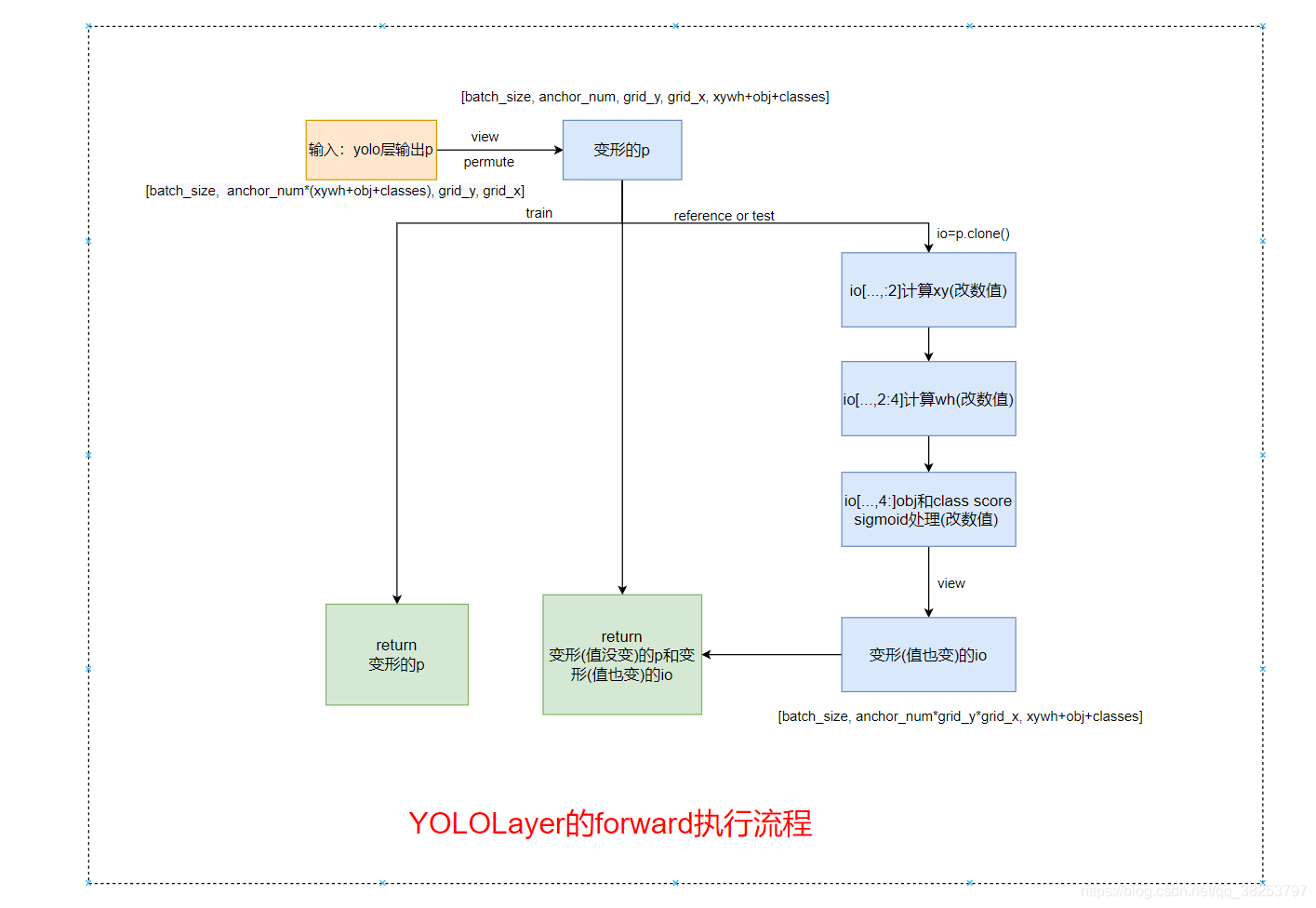
class YOLOLayer(nn.Module):
def __init__(self, anchors, nc, stride):
"""
YOLOLayer是对predictor的输出进行一个处理,它本质上并不属于网络构建的模块
:param anchors: 当前predictor的anchor list(一般是三个)
:param nc: 数据集类别个数
:param stride: 当前predictor输出feature map与原图的缩放比例
"""
super(YOLOLayer, self).__init__()
self.anchors = torch.Tensor(anchors) # 当前predictor的anchor list(一般是三个)
self.stride = stride # 特征图上一步对应原图上的步距 32/16/8 = feature map与原图的缩放比例
self.na = len(anchors) # na: anchor的数量
self.nc = nc # nc: 数据集的类别数
self.no = nc + 5 # number of outputs 8( x, y, w, h, confidence, cls1, cls2, cls3)
self.nx, self.ny, self.ng = 0, 0, (0, 0) # initialize number of x, y gridpoints
self.anchor_vec = self.anchors / self.stride # 将anchors大小缩放到预测特征层上的尺度
# self.anchor_wh = [batch_size, num of anchors, grid_h, grid_w, wh]=[1,3,1,1,2]
# self.anchor_wh:对应的是anchor映射在feature map上的高度和宽度
self.anchor_wh = self.anchor_vec.view(1, self.na, 1, 1, 2)
self.grid = None # 正向传播会重新赋值 self.grid=预测feature map上划分的每个网格的左上角坐标
def create_grids(self, ng=(13, 13), device="cpu"):
"""
更新grids信息并生成新的grids参数 self.grid=[batch_size, na, grid_h, grid_w, wh]=[1, 1, 13, 13, 2]
:param ng: 当前predictor输出的feature map大小
"""
# 更新self.nx self.ny self.ng
self.nx, self.ny = ng
self.ng = torch.tensor(ng, dtype=torch.float)
# build xy offsets 构建每个cell处的anchor的xy偏移量(在feature map上的)
if not self.training: # 训练模式只需要计算损失, 不需要回归到最终预测boxes
# xv=13x13 13个0,1,2,3,4,5,6,7,8,9,10,11,12 记录网格中所有左上角的x坐标
# yv=13x13 13个0,13个1,…… 记录网格中所有左上角的y坐标
yv, xv = torch.meshgrid([torch.arange(self.ny, device=device),
torch.arange(self.nx, device=device)])
# stack:将对应网格的x坐标与y坐标组合在一起 生成所有网格的左上角的坐标
# self.grid:将feature map化分成一个个的网格,self.grid中就存储着所有网格的左上角的坐标
# view:增加了两个维度 batch_size, na, grid_h, grid_w, wh [1, 1, 13, 13, 2]
self.grid = torch.stack((xv, yv), 2).view((1, 1, self.ny, self.nx, 2)).float()
if self.anchor_vec.device != device:
self.anchor_vec = self.anchor_vec.to(device)
self.anchor_wh = self.anchor_wh.to(device)
def forward(self, p):
"""
:param p: batch_size, predict_param(24), grid(13), grid(13)
:return: train 返回p: [bs, anchor_num, grid_h, grid_w, xywh + obj + classes]
原始的预测结果,只是做了view和permute处理,没有对数值做任何的变动
reference 返回p和io
p: 同train的p
io: [bs, anchor_num*grid_h*grid_w , xywh + obj + classes]
对xywh+obj+classes的数值都进行了改变,并改变维度
"""
bs, _, ny, nx = p.shape
# 如果grid_size发生了变化(多尺度训练)或者第一次正向传播就需要生成grid
if (self.nx, self.ny) != (nx, ny) or self.grid is None: # fix no grid bug
# self.grid=[batch_size, na, grid_h, grid_w, wh]=[1, 1, 13, 13, 2]
# self.grid:对应的是各个网格(13x13)左上角的坐标
# 将feature map划分成一个个的网格
self.create_grids((nx, ny), p.device)
# view: (batch_size, 24, 13, 13) -> (batch_size, 3, 8, 13, 13)
# permute: (batch_size, 3, 8, 13, 13) -> (batch_size, 3, 13, 13, 8) 此时内存不再连续
# contiguous: 将p再变为内存连续的变量
# 最终p=[bs, anchor_num, grid_h, grid_w, xywh + obj + 3classes]=[batch_size, 3, 13, 13, 8]
p = p.view(bs, self.na, self.no, self.ny, self.nx).permute(0, 1, 3, 4, 2).contiguous() # prediction
if self.training:
# train: 直接返回预测器原始的输出 后续进行计算损失(只是对predictor的输出进行一个展平处理)
return p
else:
# predict: 返回对predictor数据处理后的输出 后续进行非极大值抑制和显示物体框等
io = p.clone() # inference output
# torch.sigmoid(io[..., :2])=[1,3,13,13,2] 每个网格的3个anchor预测得到的相对左上角的偏移量xy
# self.grid=[1,1,13,13,2] 每个网格的左上角坐标
# io[..., :2]=xy 计算更新所有anchor的xy(相对于feature map)
io[..., :2] = torch.sigmoid(io[..., :2]) + self.grid
# torch.exp(io[..., 2:4])=[1,3,13,13,2] 每个网格的3个anchor预测的h和w
# self.anchor_wh=[1, 3, 1, 1, 2] 3个anchor映射到feature map上对应的宽度和高度
# io[..., 2:4=wh 计算更新预测的wh信息(相对于feature map)
io[..., 2:4] = torch.exp(io[..., 2:4]) * self.anchor_wh
# 上面求得了预测的xywh相对feature map大小 这里再换算映射回原图尺度
io[..., :4] *= self.stride
# obj和classes socre都是sigmoid处理
torch.sigmoid_(io[..., 4:])
# p: [bs, anchor_num, grid_h, grid_w, xywh + obj + classes] 没有对数值进行任何的变动
# io: [bs, anchor_num*grid_h*grid_w , xywh + obj + classes] 对xywh+obj+classes的数值都进行了改变
return io.view(bs, -1, self.no), p # view [1, 3, 13, 13, 25] as [1, 507, 25]
3.4、对Darknet的forward输出的理解
代码:
if self.training:
# train yolo_out = [1, 3, 13, 13, 8] [batch_size, anchor_num, grid_h, grid_w, xywh + obj + classes]
# 训练模式直接返回3个预测层的预测输出值(没有进行任何数值上的处理)
return yolo_out
else:
# inference or test
# yolo_out 3个tuple 每个tuple存放着一个predictor的原始(没进行数值处理)输出p 和 一个已经经过数值处理后的输出io
# zip(*yolo_out) 将yolo_out中的3个tuple中的p合在一起传给p 3个tuple中的io合在一起传给x x=[1,507,8][1,2028,8][1,8112,8]
x, p = zip(*yolo_out)
# concat yolo outputs 将三个anchor输出在第一个维度上concat
# x=[1, 10647, 8] 表示这张图片总共生成了10647个anchor
x = torch.cat(x, 1)
# p: predictor原始输出 [batch_size, anchor_num, grid, grid, xywh + obj + classes]
# x: predictor数据处理后的输出 [batch_size, anchor_num*grid*grid, xywh + obj + classes]
return x, p
这里以后再完善!
四、所有代码
4.1、model.py
import math
import torch
from torch import nn
from build_utils.layers import FeatureConcat, WeightedFeatureFusion
from build_utils.parse_config import parse_model_cfg
class DarkNet(nn.Module):
def __init__(self, cfg, verbose=True):
"""
:param cfg: 网络模型对应的cfg配置文件
:param verbose: 是否需要打印模型信息 True打印 False不打印
"""
super(DarkNet, self).__init__()
# 解析网络对应的.cfg文件
self.module_defs = parse_model_cfg(cfg)
# 根据解析的网络结构一层一层去初始化网络
# module_list: 所有层结构 self.routs: 后面会用到那些层(concat/shortcut在前向传播时需要用到)
self.module_list, self.routs = create_modules(self.module_defs)
# 获取所有YOLOLayer层的索引
self.yolo_layers = get_yolo_layers(self)
# 打印下模型的信息,如果verbose为True则打印详细信息
self.info(verbose) # print model description
def forward(self, x, verbose=False):
return self.forward_once(x, verbose=verbose)
def forward_once(self, x, verbose=False):
"""
正向传播过程
:param x: 输出的图像数据
:param verbose: 是否需要打印模型信息 True打印 False不打印
下面代码涉及到的verbose其实并不需要太关注 只是一些简单的信息打印
:return: train 直接返回3个预测层的预测输出值(没有进行任何数值上的处理)
yolo_out [1, 3, 13, 13, 8] [batch_size, anchor_num, grid_h, grid_w, xywh + obj + classes]
reference 返回两个 x, p
x: predictor数据处理后的输出(数值发生变化) [batch_size, anchor_num*grid*grid, xywh + obj + classes]
p: predictor原始输出 [batch_size, anchor_num, grid, grid, xywh + obj + classes]
"""
# yolo_out收集每个yolo_layer(predictor)的输出
# out收集所有self.routs[i]=True层的输出(将在shortcut/concat中使用到)
yolo_out, out = [], []
if verbose:
print('0', x.shape)
str = ""
# 遍历每一层结构 进行正向传播
for i, module in enumerate(self.module_list):
name = module.__class__.__name__ # 返回当前层的类名
if name in ["WeightedFeatureFusion", "FeatureConcat"]: # shortcut, concat
if verbose:
l = [i - 1] + module.layers # layers
sh = [list(x.shape)] + [list(out[i].shape) for i in module.layers] # shapes
str = ' >> ' + ' + '.join(['layer %g %s' % x for x in zip(l, sh)])
x = module(x, out) # WeightedFeatureFusion(), FeatureConcat()
elif name == "YOLOLayer":
# 将yolo层的输出(predictor)依次保存在yolo_out(分为train和reference两种情况)
yolo_out.append(module(x))
else:
# run module directly
# i.e. mtype = 'convolutional', 'upsample', 'maxpool', 'batchnorm2d' etc.
x = module(x)
out.append(x if self.routs[i] else []) # out收集所有self.routs[i]=True层的输出(将在shortcut/concat中使用到)
if verbose:
print('%g/%g %s -' % (i, len(self.module_list), name), list(x.shape), str)
str = ''
if self.training:
# train yolo_out = [1, 3, 13, 13, 8] [batch_size, anchor_num, grid_h, grid_w, xywh + obj + classes]
# 训练模式直接返回3个预测层的预测输出值(没有进行任何数值上的处理)
return yolo_out
else:
# inference or test
# yolo_out 3个tuple 每个tuple存放着一个predictor的原始(没进行数值处理)输出p 和 一个已经经过数值处理后的输出io
# zip(*yolo_out) 将yolo_out中的3个tuple中的p合在一起传给p 3个tuple中的io合在一起传给x x=[1,507,8][1,2028,8][1,8112,8]
x, p = zip(*yolo_out)
# concat yolo outputs 将三个anchor输出在第一个维度上concat
# x=[1, 10647, 8] 表示这张图片总共生成了10647个anchor
x = torch.cat(x, 1)
# p: predictor原始输出 [batch_size, anchor_num, grid, grid, xywh + obj + classes]
# x: predictor数据处理后的输出 [batch_size, anchor_num*grid*grid, xywh + obj + classes]
return x, p
def info(self, verbose=False):
"""
打印模型的信息
:param verbose: True 打印
:return:
"""
model_info(self, verbose)
def create_modules(modules_defs: list):
"""
:param modules_defs: 保存着解析模型配置文件后的每一层的信息
:return module_list: 保存着根据解析后的模型配置信息初始化的每一层的结构
:return routs_binary: 记录着哪些层在后面可能还会用到(concat/shortcut) 还会用到True 不会用到False
"""
hyperparams = modules_defs.pop(0) # 除去cfg training hyperparams (unused)
output_filters = [int(hyperparams['channels'])] # 保存每一层的输出channel(包括输入RGB图像的3个channels)
module_list = nn.ModuleList() # 保存每一层 每一层依次append进来
# 统计哪些特征层的输出会被后续的层使用到(可能是特征融合,也可能是拼接) 来自于concat,shortcut,yolo前一层(predictor)
routs = []
# 记录当前yolo是第几个yolo层
yolo_index = -1
# 遍历搭建每个层结构
for i, mdef in enumerate(modules_defs):
modules = nn.Sequential() # 初始化每一层 Sequential在forward时对于顺序的结构只需要执行一次即可
# 初始化所有卷积层
if mdef["type"] == "convolutional":
# 读取该层的所有信息
bn = mdef["batch_normalize"] # 1 or 0 / use or not 使用的话bias=false
filters = mdef["filters"] # 卷积核个数
k = mdef["size"] # 卷积核size
# 矩形 (mdef['stride_y'], mdef["stride_x"]) 没用到, 这里的stride都有
stride = mdef["stride"] if "stride" in mdef else (mdef['stride_y'], mdef["stride_x"])
padding = k // 2 if mdef["pad"] else 0 # 卷积padding
if isinstance(k, int):
modules.add_module("Conv2d", nn.Conv2d(in_channels=output_filters[-1], # 输入为上一层的输出 最开始是3
out_channels=filters,
kernel_size=k,
stride=stride,
padding=padding,
bias=not bn))
else:
raise TypeError("conv2d filter size must be int type")
if bn:
modules.add_module("BatchNorm2d", nn.BatchNorm2d(filters))
else:
# 在网络当中所有卷积层都使用bn层, 只用在yolo层前的一个卷积层(predictor预测层)没有bn层
# 如果该卷积操作没有bn层,意味着该层为yolo的predictor
routs.append(i)
if mdef["activation"] == "leaky":
modules.add_module("activation", nn.LeakyReLU(0.1, inplace=True))
else:
# 这里还可以选择其他的激活函数,如swish, mish等
pass
# yolov3-spp的结构中每一个bn都是接在conv后面的,所以只需要在conv层搭建的时候构建bn就可以了
elif mdef["type"] == "BatchNorm2d":
pass
# 初始化所有maxpool层
elif mdef["type"] == "maxpool":
# 普通的yolo结构是没有maxpool层的 只有在spp模块中使用了maxpool层
k = mdef["size"]
stride = mdef["stride"]
maxpool = nn.MaxPool2d(kernel_size=k, stride=stride, padding=(k-1)//2)
if k == 2 and stride == 1: # yolo-v3-tiny
modules.add_module("ZeroPad2d", nn.ZeroPad2d((0, 1, 0, 1)))
modules.add_module("MaxPool2d", maxpool)
else:
modules = maxpool
# 初始化所有上采样层
elif mdef["type"] == "upsample":
modules = nn.Upsample(scale_factor=mdef["stride"]) # scale_factor: 上采样率
# 初始化所有的concat操作
elif mdef["type"] == "route":
# layers:当前需要进行concat操作的所有层的层号 比如layers=-1,-3,-5,-6
layers = mdef["layers"]
# filters:concat之后得到feature map的channel个数 其中output_filters记录着所有层的输出channel
# 当l>0时是正着数的,需要l+1(net层);当l<0时是反着数,就直接l就行了
filters = sum([output_filters[l + 1 if l > 0 else l] for l in layers])
# routs:统计哪些特征层的输出会被后续的层使用到 concat
routs.extend([i + l if l < 0 else l for l in layers]) # i=当前层索引
modules = FeatureConcat(layers=layers) # 这里modules的类名就便成了FeatureConcat而不是Sequential
# 初始化所有残差结构
elif mdef["type"] == "shortcut":
# layers 全是 -3 from: 从当前layer往前数第3个层建立到当前层的shortcut
layers = mdef["from"]
# filters=上一层输出的channel
filters = output_filters[-1]
# routs.extend([i + l if l < 0 else l for l in layers]) 这里layers都是只用一个-3 所以可以简写下
routs.append(i + layers[0])
# shortcut操作 这里的weight=False 因为cfg中并没有weights_type这个参数 这里我们不做考虑
# 同理这里的类名变为WeightedFeatureFusion
modules = WeightedFeatureFusion(layers=layers, weight="weights_type" in mdef)
# 对YOLO的输出(predictor输出)进行处理
# 本质上这部分并不是网络构建的部分,有点像后处理了,写在这里也是为了方便
elif mdef["type"] == "yolo":
yolo_index += 1 # 记录是第几个yolo_layer 0, 1, 2
stride = [32, 16, 8] # 预测特征层对应原图的缩放比例(对应的是yolo_index)
# anchors: 当前predictor使用哪几个anchors mask=anchor index
# nc: 数据集类别个数
# stride: 当前predictor输出feature map与原图的缩放比例
modules = YOLOLayer(anchors=mdef["anchors"][mdef["mask"]],
nc=mdef["classes"],
stride=stride[yolo_index])
# 初始化 yolo layer前一层conv(predictor)的bias 这一层没有BN, 所以前一层conv的bias要有初始化
# Initialize preceding Conv2d() bias (https://arxiv.org/pdf/1708.02002.pdf section 4.1)
try:
j = -1 # yolo层上一层
bias_ = module_list[j][0].bias # shape(255,) 索引0对应Sequential中的Conv2d
bias = bias_.view(modules.na, -1) # shape(3, 85)
bias[:, 4] += -4.5 # obj
bias[:, 5:] += math.log(0.6 / (modules.nc - 0.99)) # cls (sigmoid(p) = 1/nc)
# 其实不是很明白这里为什么传到是bias_而不是bias,那改变bias的意义在哪里???可能后面需要看下论文
module_list[j][0].bias = torch.nn.Parameter(bias_, requires_grad=bias_.requires_grad)
except Exception as e:
print('WARNING: smart bias initialization failure.', e)
else:
print("Warning: Unrecognized Layer Type: " + mdef["type"])
module_list.append(modules)
output_filters.append(filters)
# routs_binary 记录那些层在后面还会用到(concat/shortcut) 还会用到True 不会用到False
routs_binary = [False] * len(modules_defs)
for i in routs:
routs_binary[i] = True
return module_list, routs_binary
class YOLOLayer(nn.Module):
def __init__(self, anchors, nc, stride):
"""
YOLOLayer是对predictor的输出进行一个处理,它本质上并不属于网络构建的模块
:param anchors: 当前predictor的anchor list(一般是三个)
:param nc: 数据集类别个数
:param stride: 当前predictor输出feature map与原图的缩放比例
"""
super(YOLOLayer, self).__init__()
self.anchors = torch.Tensor(anchors) # 当前predictor的anchor list(一般是三个)
self.stride = stride # 特征图上一步对应原图上的步距 32/16/8 = feature map与原图的缩放比例
self.na = len(anchors) # na: anchor的数量
self.nc = nc # nc: 数据集的类别数
self.no = nc + 5 # number of outputs 8( x, y, w, h, confidence, cls1, cls2, cls3)
self.nx, self.ny, self.ng = 0, 0, (0, 0) # initialize number of x, y gridpoints
self.anchor_vec = self.anchors / self.stride # 将anchors大小缩放到预测特征层上的尺度
# self.anchor_wh = [batch_size, num of anchors, grid_h, grid_w, wh]=[1,3,1,1,2]
# self.anchor_wh:对应的是anchor映射在feature map上的高度和宽度
self.anchor_wh = self.anchor_vec.view(1, self.na, 1, 1, 2)
self.grid = None # 正向传播会重新赋值 self.grid=预测feature map上划分的每个网格的左上角坐标
def create_grids(self, ng=(13, 13), device="cpu"):
"""
更新grids信息并生成新的grids参数 self.grid=[batch_size, na, grid_h, grid_w, wh]=[1, 1, 13, 13, 2]
:param ng: 当前predictor输出的feature map大小
"""
# 更新self.nx self.ny self.ng
self.nx, self.ny = ng
self.ng = torch.tensor(ng, dtype=torch.float)
# build xy offsets 构建每个cell处的anchor的xy偏移量(在feature map上的)
if not self.training: # 训练模式只需要计算损失, 不需要回归到最终预测boxes
# xv=13x13 13个0,1,2,3,4,5,6,7,8,9,10,11,12 记录网格中所有左上角的x坐标
# yv=13x13 13个0,13个1,…… 记录网格中所有左上角的y坐标
yv, xv = torch.meshgrid([torch.arange(self.ny, device=device),
torch.arange(self.nx, device=device)])
# stack:将对应网格的x坐标与y坐标组合在一起 生成所有网格的左上角的坐标
# self.grid:将feature map化分成一个个的网格,self.grid中就存储着所有网格的左上角的坐标
# view:增加了两个维度 batch_size, na, grid_h, grid_w, wh [1, 1, 13, 13, 2]
self.grid = torch.stack((xv, yv), 2).view((1, 1, self.ny, self.nx, 2)).float()
if self.anchor_vec.device != device:
self.anchor_vec = self.anchor_vec.to(device)
self.anchor_wh = self.anchor_wh.to(device)
def forward(self, p):
"""
:param p: batch_size, predict_param(24), grid(13), grid(13)
:return: train 返回p: [bs, anchor_num, grid_h, grid_w, xywh + obj + classes]
原始的预测结果,只是做了view和permute处理,没有对数值做任何的变动
reference 返回p和io
p: 同train的p
io: [bs, anchor_num*grid_h*grid_w , xywh + obj + classes]
对xywh+obj+classes的数值都进行了改变,并改变维度
"""
bs, _, ny, nx = p.shape
# 如果grid_size发生了变化(多尺度训练)或者第一次正向传播就需要生成grid
if (self.nx, self.ny) != (nx, ny) or self.grid is None: # fix no grid bug
# self.grid=[batch_size, na, grid_h, grid_w, wh]=[1, 1, 13, 13, 2]
# self.grid:对应的是各个网格(13x13)左上角的坐标
# 将feature map划分成一个个的网格
self.create_grids((nx, ny), p.device)
# view: (batch_size, 24, 13, 13) -> (batch_size, 3, 8, 13, 13)
# permute: (batch_size, 3, 8, 13, 13) -> (batch_size, 3, 13, 13, 8) 此时内存不再连续
# contiguous: 将p再变为内存连续的变量
# 最终p=[bs, anchor_num, grid_h, grid_w, xywh + obj + 3classes]=[batch_size, 3, 13, 13, 8]
p = p.view(bs, self.na, self.no, self.ny, self.nx).permute(0, 1, 3, 4, 2).contiguous() # prediction
if self.training:
# train: 直接返回预测器原始的输出 后续进行计算损失(只是对predictor的输出进行一个展平处理)
return p
else:
# predict: 返回对predictor数据处理后的输出 后续进行非极大值抑制和显示物体框等
io = p.clone() # inference output
# torch.sigmoid(io[..., :2])=[1,3,13,13,2] 每个网格的3个anchor预测得到的相对左上角的偏移量xy
# self.grid=[1,1,13,13,2] 每个网格的左上角坐标
# io[..., :2]=xy 计算更新所有anchor的xy(相对于feature map)
io[..., :2] = torch.sigmoid(io[..., :2]) + self.grid
# torch.exp(io[..., 2:4])=[1,3,13,13,2] 每个网格的3个anchor预测的h和w
# self.anchor_wh=[1, 3, 1, 1, 2] 3个anchor映射到feature map上对应的宽度和高度
# io[..., 2:4=wh 计算更新预测的wh信息(相对于feature map)
io[..., 2:4] = torch.exp(io[..., 2:4]) * self.anchor_wh
# 上面求得了预测的xywh相对feature map大小 这里再换算映射回原图尺度
io[..., :4] *= self.stride
# obj和classes socre都是sigmoid处理
torch.sigmoid_(io[..., 4:])
# p: [bs, anchor_num, grid_h, grid_w, xywh + obj + classes] 没有对数值进行任何的变动
# io: [bs, anchor_num*grid_h*grid_w , xywh + obj + classes] 对xywh+obj+classes的数值都进行了改变
return io.view(bs, -1, self.no), p # view [1, 3, 13, 13, 25] as [1, 507, 25]
def get_yolo_layers(self):
"""
获取网络中三个"YOLOLayer"模块对应的索引
:return: 返回三个"YOLOLayer"模块对应的索引 [89, 101, 113]
"""
return [i for i, m in enumerate(self.module_list) if m.__class__.__name__ == 'YOLOLayer']
def model_info(model, verbose=False):
# 打印模型信息
# Plots a line-by-line description of a PyTorch model
n_p = sum(x.numel() for x in model.parameters()) # number parameters
n_g = sum(x.numel() for x in model.parameters() if x.requires_grad) # number gradients
if verbose:
print('%5s %40s %9s %12s %20s %10s %10s' % ('layer', 'name', 'gradient', 'parameters', 'shape', 'mu', 'sigma'))
for i, (name, p) in enumerate(model.named_parameters()):
name = name.replace('module_list.', '')
print('%5g %40s %9s %12g %20s %10.3g %10.3g' %
(i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std()))
try: # FLOPS
from thop import profile
macs, _ = profile(model, inputs=(torch.zeros(1, 3, 416, 416),), verbose=False)
fs = ', %.1f GFLOPS' % (macs / 1E9 * 2)
except:
fs = ''
print('Model Summary: %g layers, %g parameters, %g gradients%s' % (len(list(model.parameters())), n_p, n_g, fs))
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("Using {} device training.".format(device.type))
cfg = "F:\yolov3-my\cfg\yolov3-spp.cfg"
# Initialize model
model = DarkNet(cfg).to(device)
# print(model)
4.2、parse_config.py
import os
import numpy as np
def parse_model_cfg(path: str):
"""
读取并解析模型的配置文件(cfg)
:param path: 配置文件地址 如:cfg/yolov3-spp.cfg
:return: 返回一个list,list中由很多的dict字典组成,每个字典对应一层的信息(第0层是net)
"""
# 1、检查配置文件是否存在/格式是否正确
if not path.endswith(".cfg") or not os.path.exists(path):
raise FileNotFoundError("the cfg file not exist...")
# 2、读取配置文件所有信息 用换行符进行分割
with open(path, "r") as f:
lines = f.read().split("\n")
# 3、去除空行和注释行
lines = [x for x in lines if x and not x.startswith("#")]
# 4、去除每行开头和结尾的空格符
lines = [x.strip() for x in lines]
# 5、开始解析每一行
mdefs = [] # module definitions
for line in lines:
# 筛选后,所有的line都只剩两种情况: 1、[tpye名] 2、key=val
if line.startswith("["): # this marks the start of a new block
mdefs.append({})
mdefs[-1]["type"] = line[1:-1].strip() # 记录module类型 type=层结构名称
# 如果是卷积模块,设置默认不使用BN
if mdefs[-1]["type"] == "convolutional":
mdefs[-1]["batch_normalize"] = 0
else:
key, val = line.split("=")
key = key.strip() # 去除前后的空格
val = val.strip()
if key == "anchors":
# anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
val = val.replace(" ", "") # 将空格去除
# 将shape (1, 18)=>(9, 2) 九个anchors
mdefs[-1][key] = np.array([float(x) for x in val.split(",")]).reshape((-1, 2)) # np anchors
elif (key in ["from", "layers", "mask"]) or (key == "size" and "," in val):
# 如果是from/layers/mask, 就将值以数组的形式存储(一般是多个值)
mdefs[-1][key] = [int(x) for x in val.split(",")]
else:
# 其他情况就是一般的一个key对应一个val存储起来
# TODO: .isnumeric() actually fails to get the float case
if val.isnumeric(): # return int or float 如果是数值的情况
mdefs[-1][key] = int(val) if (int(val) - float(val)) == 0 else float(val)
else:
mdefs[-1][key] = val # return string 是字符的情况
# 6、检测所有读出的配置信息k是否符合标准 check all fields are supported
supported = ['type', 'batch_normalize', 'filters', 'size', 'stride', 'pad', 'activation', 'layers', 'groups',
'from', 'mask', 'anchors', 'classes', 'num', 'jitter', 'ignore_thresh', 'truth_thresh', 'random',
'stride_x', 'stride_y', 'weights_type', 'weights_normalization', 'scale_x_y', 'beta_nms', 'nms_kind',
'iou_loss', 'iou_normalizer', 'cls_normalizer', 'iou_thresh', 'probability']
# 遍历检查每个模型的配置
for x in mdefs[1:]: # 0对应net配置
# 遍历每个配置字典中的key值
for k in x:
if k not in supported:
raise ValueError("Unsupported fields:{} in cfg".format(k))
return mdefs
4.3、layers.py
import torch
from torch import nn
class FeatureConcat(nn.Module):
"""将多个特征矩阵在channel维度进行concatenate拼接"""
def __init__(self, layers):
"""
:param layers: 记录下当前需要进行concat操作的所有层的层号 比如layers=-1,-3,-5,-6
"""
super(FeatureConcat, self).__init__()
self.layers = layers # layer index 记录当前需要concat的层序号
self.multiple = len(layers) > 1 # 是否是多层concat
def forward(self, x, outputs):
"""
:param outputs: 记录网络中每一层的输出feature map
:return: 返回concat之后的feature map
"""
return torch.cat([outputs[i] for i in self.layers], 1) if self.multiple else outputs[self.layers[0]]
class WeightedFeatureFusion(nn.Module):
# weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070
"""将多个特征矩阵的值进行融合(add操作) 只在残差结构用到 只在2个特征矩阵进行融合"""
def __init__(self, layers, weight=False):
"""
:param layers: 从当前layer往前数第3个层建立到当前层的shortcut 实际上这里全都是[-3]
:param weight: False 这里是扩展功能 我们先不做考虑 没用到
"""
super(WeightedFeatureFusion, self).__init__()
self.layers = layers # layer index 需要进行融合(add)
self.weight = weight # apply weights boolean 没用到
self.n = len(layers) + 1 # number of layers 融合的特征矩阵个数 这里都是2
if weight:
self.w = nn.Parameter(torch.zeros(self.n), requires_grad=True) # layer weights
def forward(self, x, outputs):
"""
:param x: 输入的特征矩阵 shortcut前一个卷积的输出特征
:param outputs: 收集的整个网络的每一个模块的输出
:return: 返回shortcut后的feature map
"""
# Weights 跳过 不执行
if self.weight:
w = torch.sigmoid(self.w) * (2 / self.n) # sigmoid weights (0-1)
x = x * w[0]
# Fusion
nx = x.shape[1] # input channels
# 这里只会遍历一次 shortcut只是两个特征矩阵进行融合 self.n=2
for i in range(self.n - 1):
# 其实执行的是a = outputs[self.layers[i]] a=要融合的层结构的feature map
a = outputs[self.layers[i]] * w[i + 1] if self.weight else outputs[self.layers[i]]
na = a.shape[1] # 取出要融合的层结构的feature map的channels
# Adjust channels
# 根据相加的两个特征矩阵的channel选择相加方式
if nx == na: # 残差结构只是用到这个 same shape 如果channel相同,直接相加
x = x + a
# 下面其实是不执行的
elif nx > na: # slice input 如果channel不同,将channel多的特征矩阵砍掉部分channel保证相加的channel一致
x[:, :na] = x[:, :na] + a # or a = nn.ZeroPad2d((0, 0, 0, 0, 0, dc))(a); x = x + a
else: # slice feature
x = x + a[:, :nx]
return x
Reference
b站大佬1 霹雳吧啦Wz: YOLOv3 SPP源码解析(Pytorch版)
b站大佬2 比飞鸟贵重的多_HKL: 基于深度学习的目标检测算法

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)