
DeepSeek本地&联网部署(手把手教学)
DeepSeek一键式部署,包括本地、联网部署和知识库搭建!解决Ollama拉取模型速度过慢。
文章目录
一、本地部署
1、Ollama
1、下载并安装Ollama
Ollama是一个AI模型运行容器
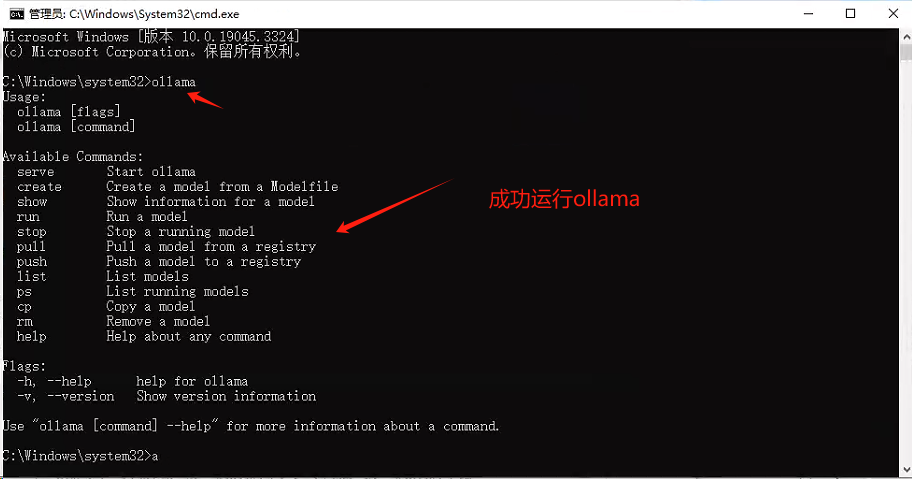
2、运行ollama
打开cmd,在命令行输入ollama
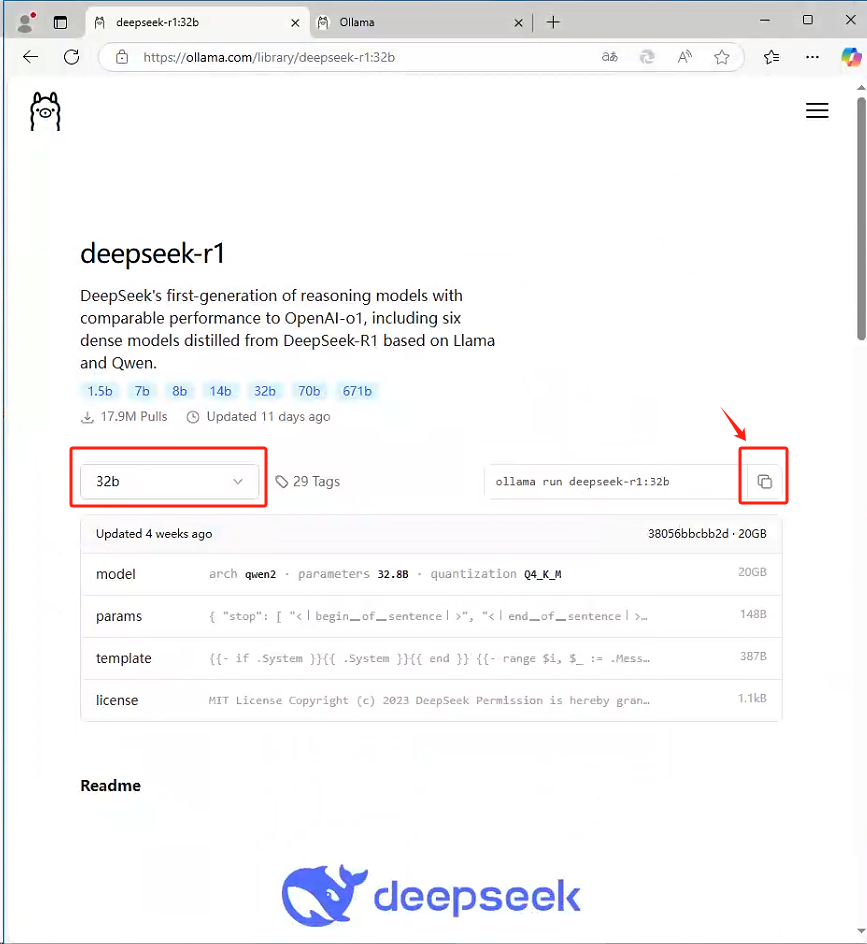
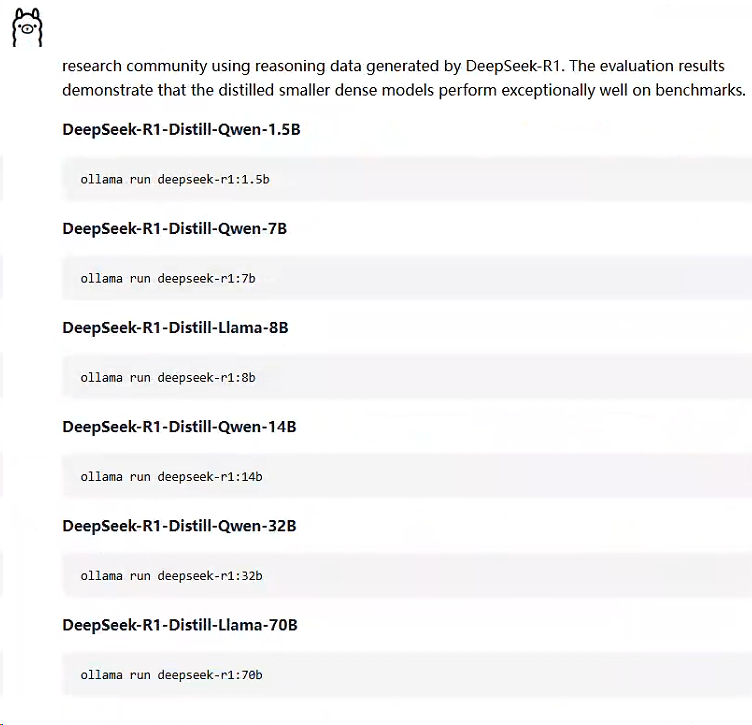
3、选择合适的模型下载
- 1.5b 模型,4GB显存就能跑。
- 7b、8b 模型,8GB显存
- 14b 模型,12GB显存。
- 32b 模型,24GB显存。
- 72b 模型,30GB显存。
拉取32b模型命令:ollama run deepseek-r1:32b
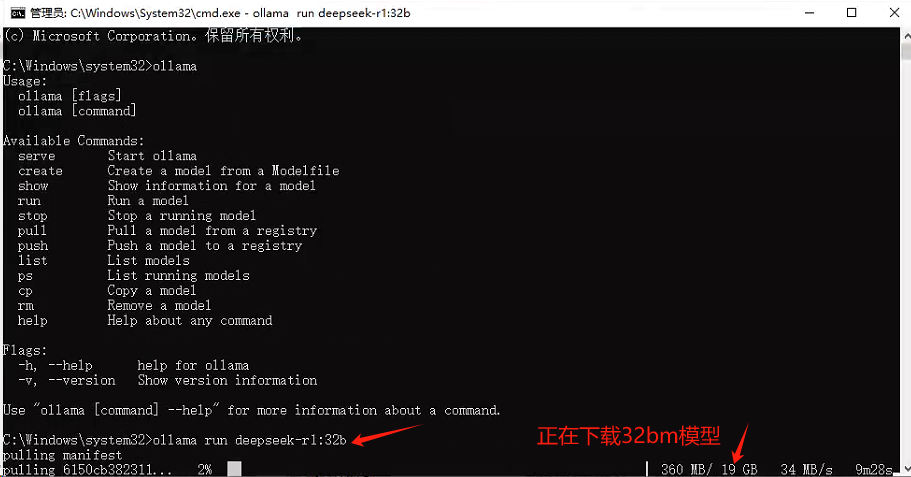
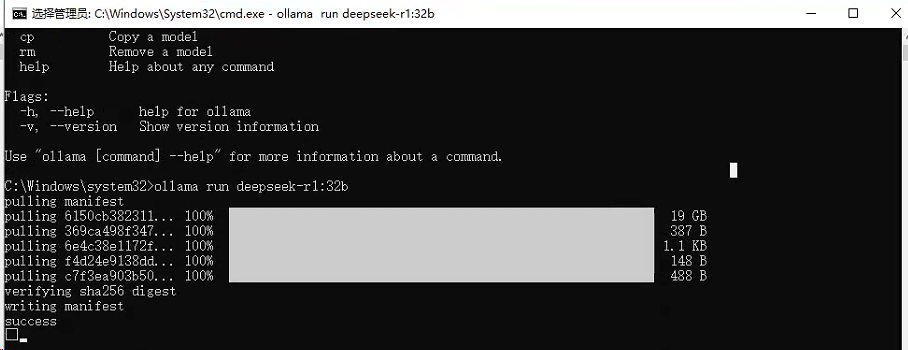
模型下载完毕
3、执行模型
下载模型后,根据下载模型去执行命令运行
ollama run deepseek-r1:32b
此外,我们可以通过输入
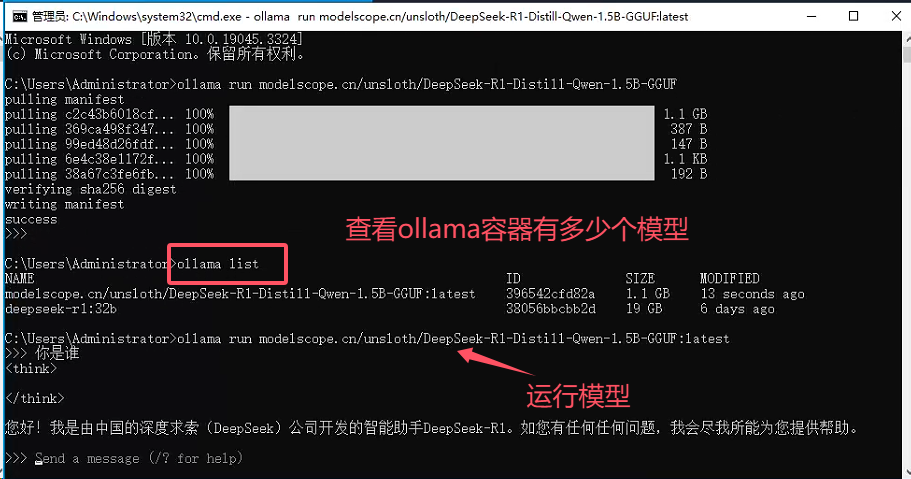
ollama list查看已经下载好的模型。

4、验证模型

2、cherry studio 可视化软件
1、下载cherry studio
2、开启ollama后,设置cherry studio
开启ollama后,cherry studio会自动设置ollama
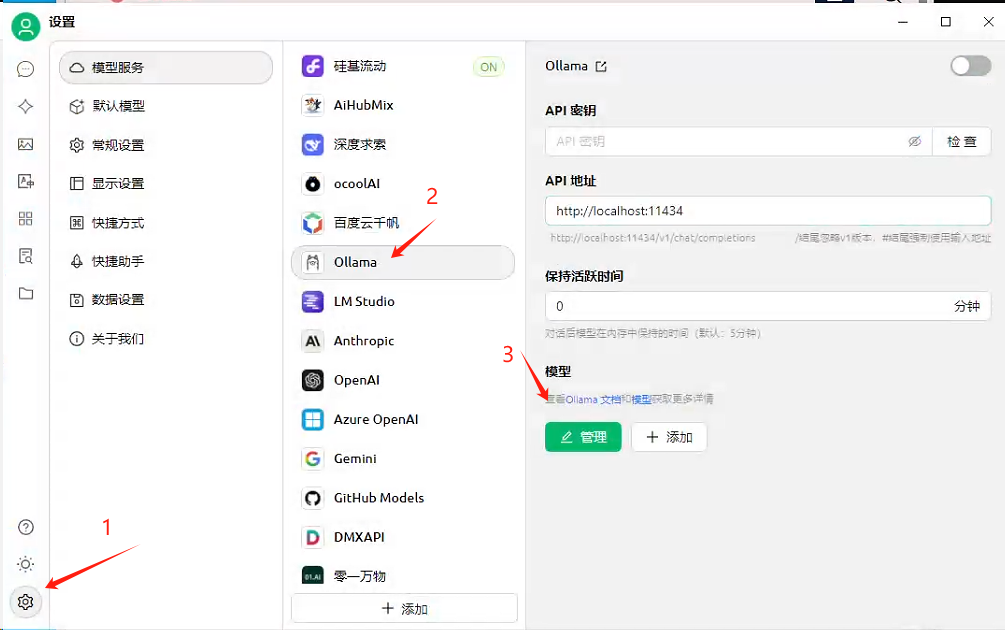
通过点击管理,选择模型

回到对话框,点击模型,找到自己想要的模型

3、Web UI 体验
1、安装Page Assist 浏览器插件
2、打开Page Assist,在设置中设置中文语言。
3、回到聊天窗口,选择DeepSeek模型

测试效果

二、联网部署
注册即送2000万Token,足够日常使用。
注册完硅基后,点击API秘钥,新建API秘钥,再回到Cherry Studio 导入该秘钥
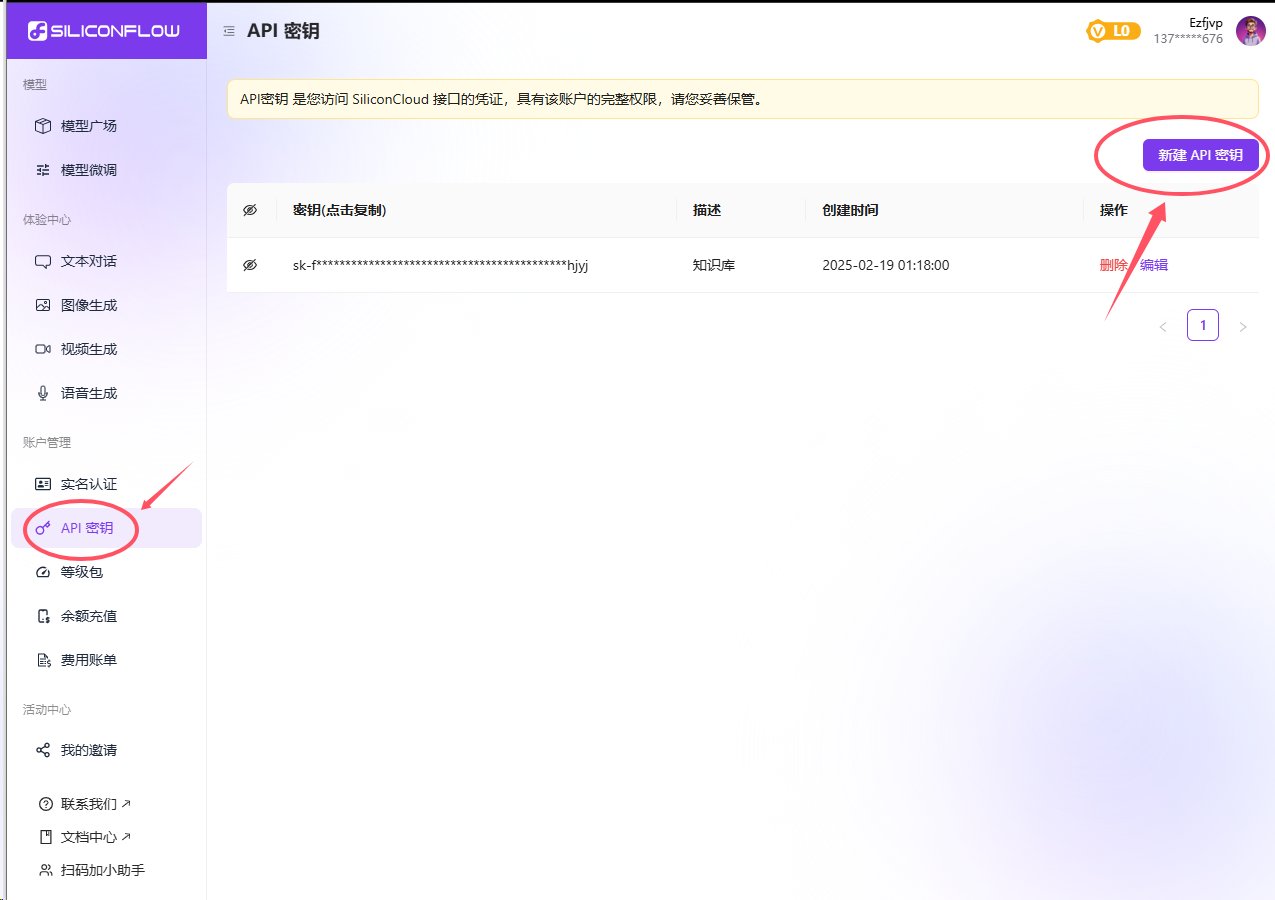
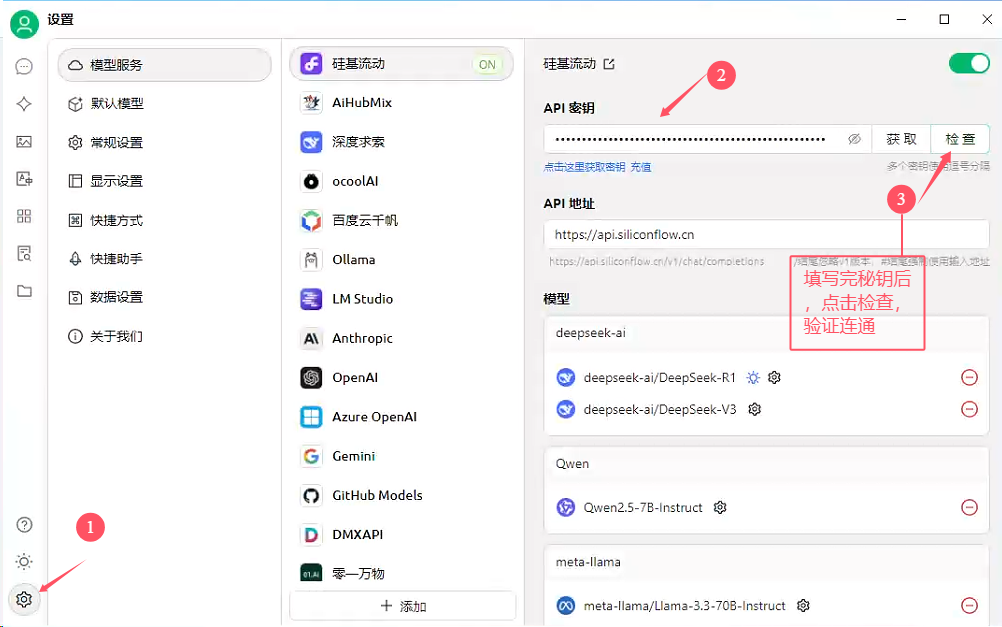
点击管理,根据需求将适合的模型添加进来
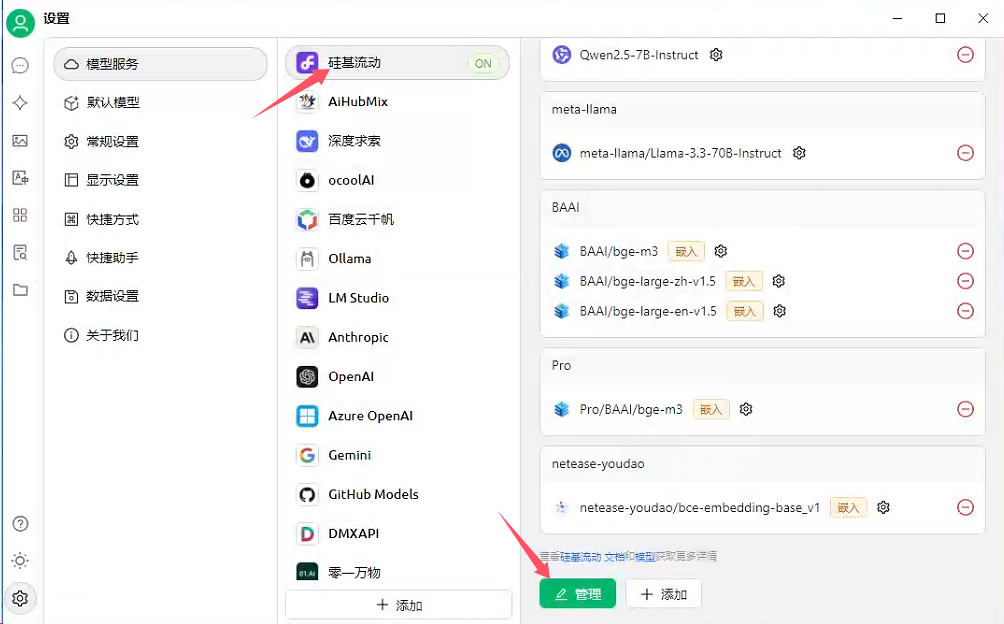

三、搭建知识库
注意:必须先注册硅基,有硅基账户才能使用其嵌入模型
1、设置–选择模型(硅基流动)–管理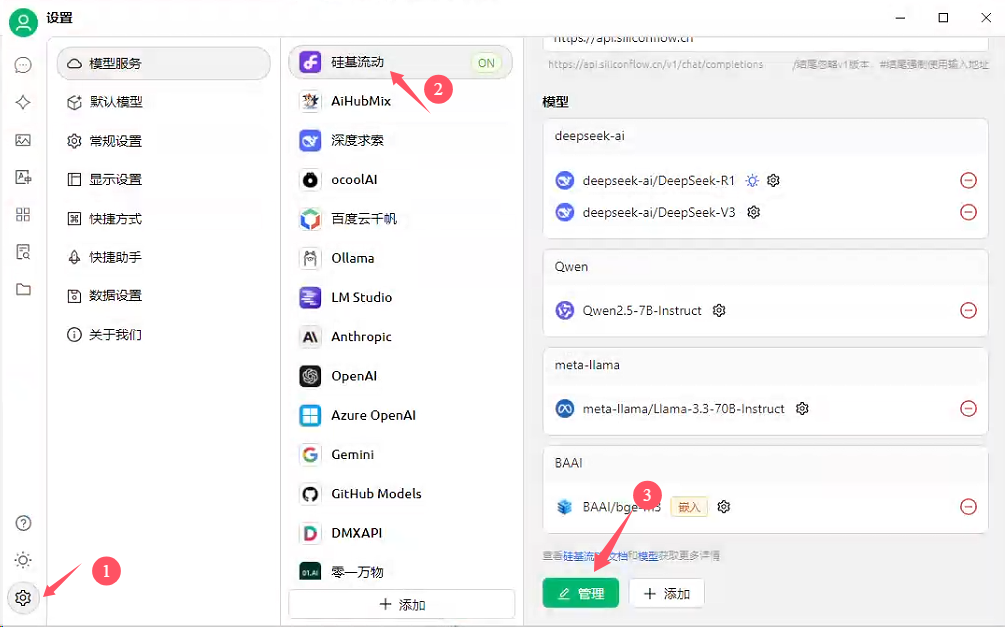
2、嵌入–添加模型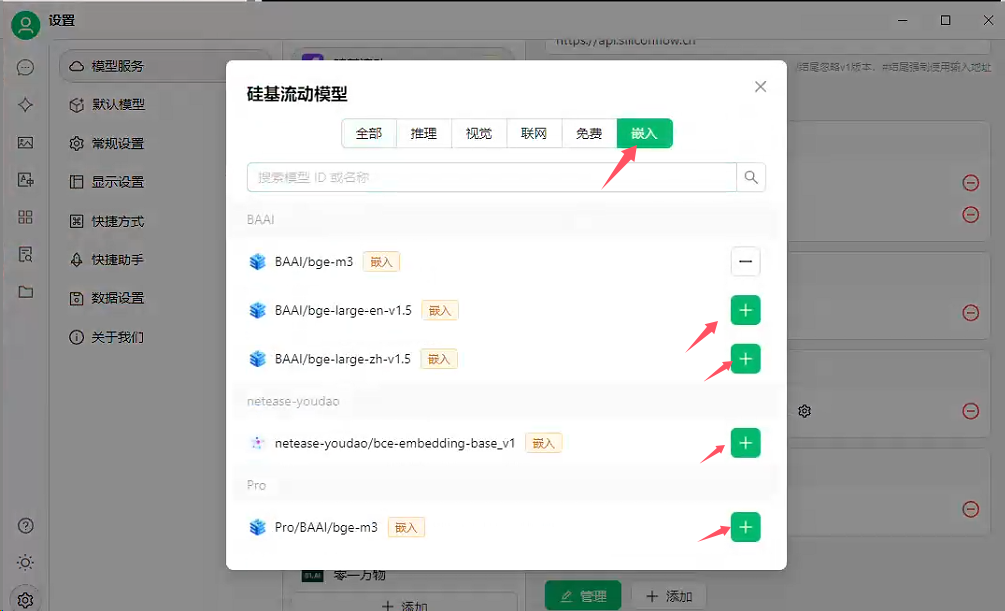
3、选中知识库

4、添加知识库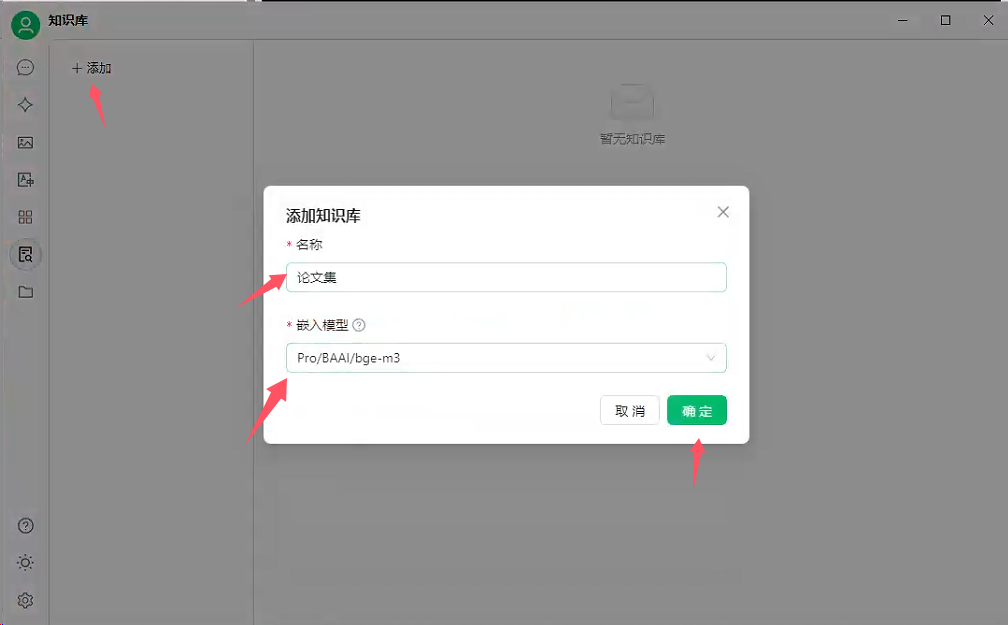
5、上传知识集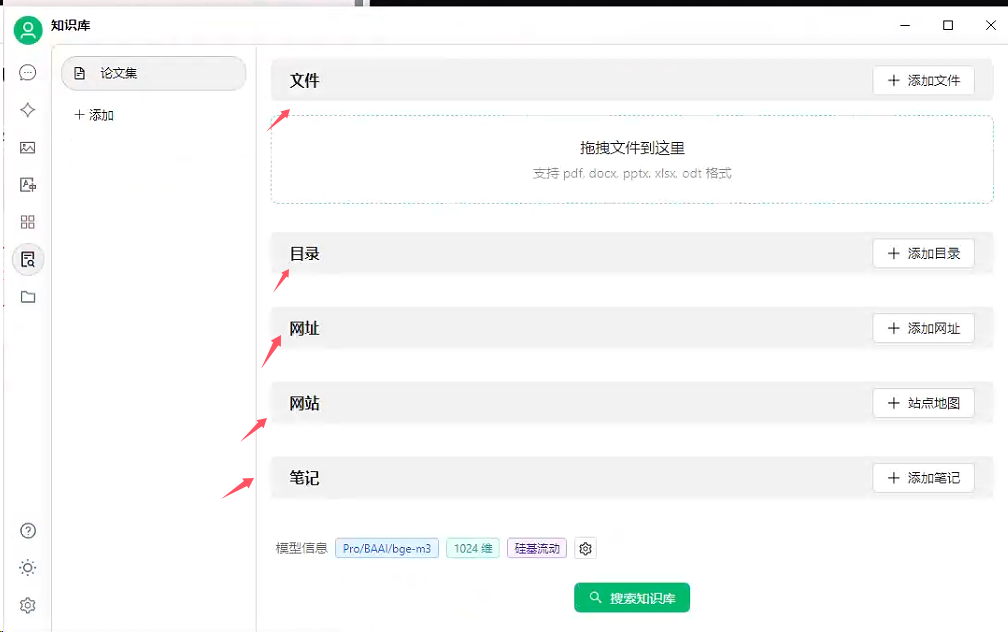
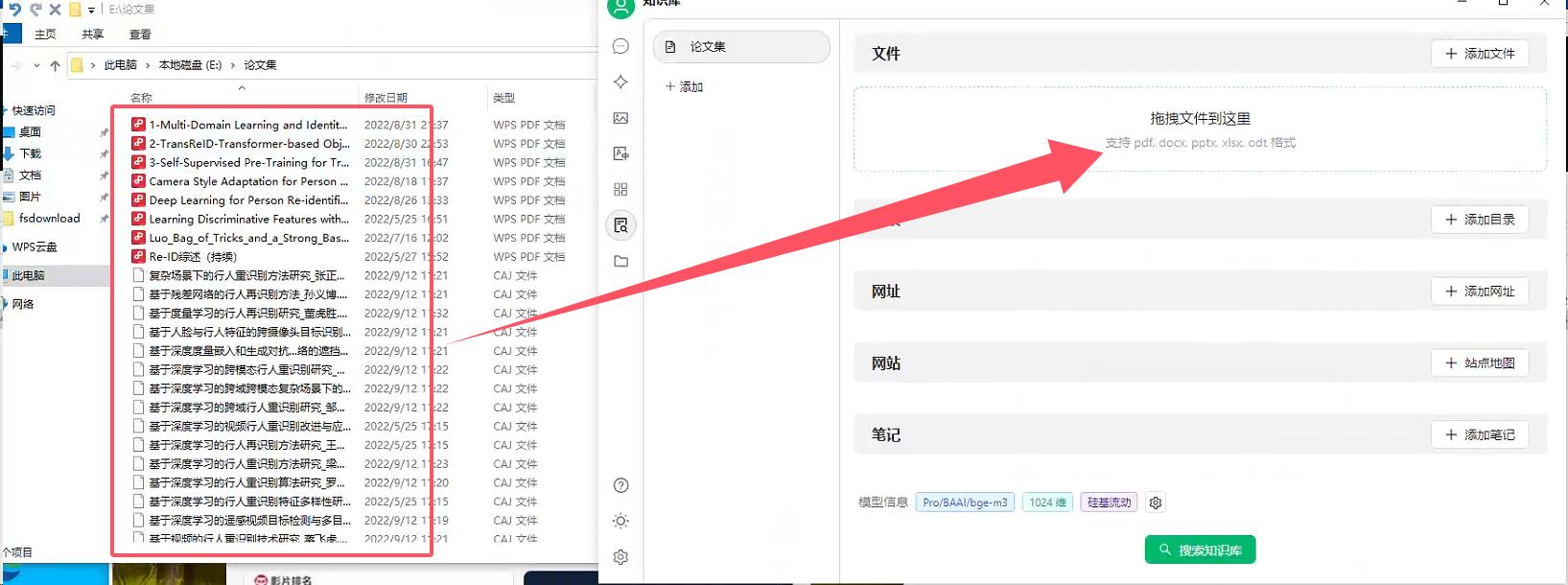
6、回到聊天窗口,勾选知识库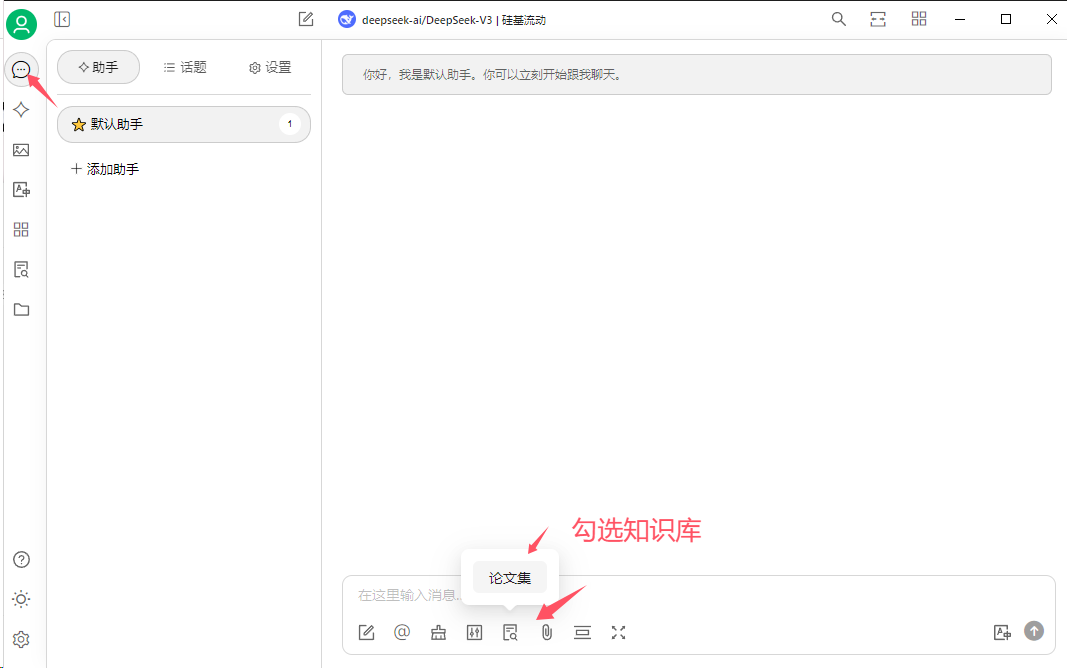
7、提问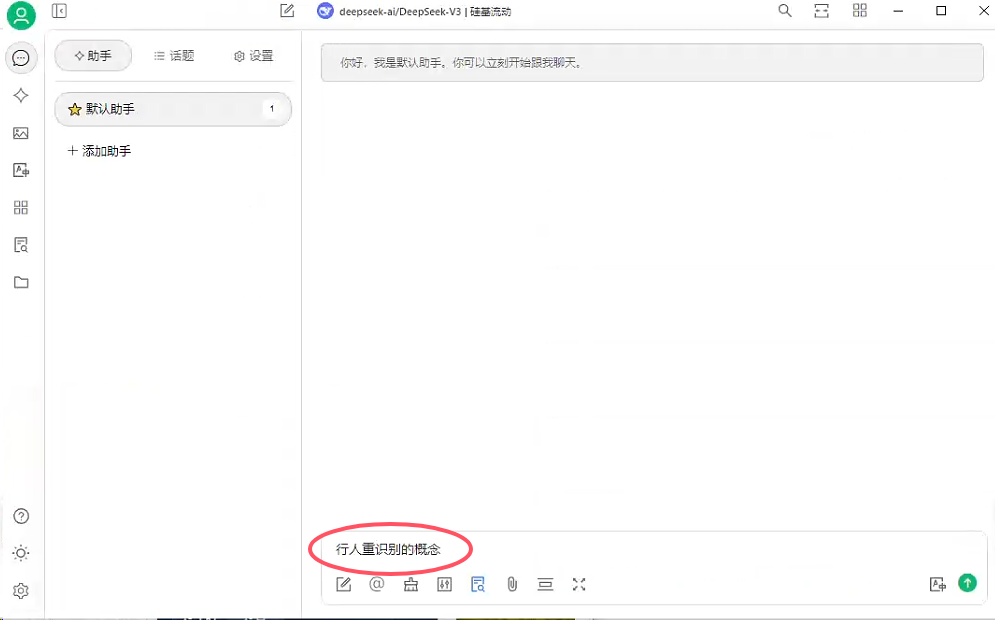
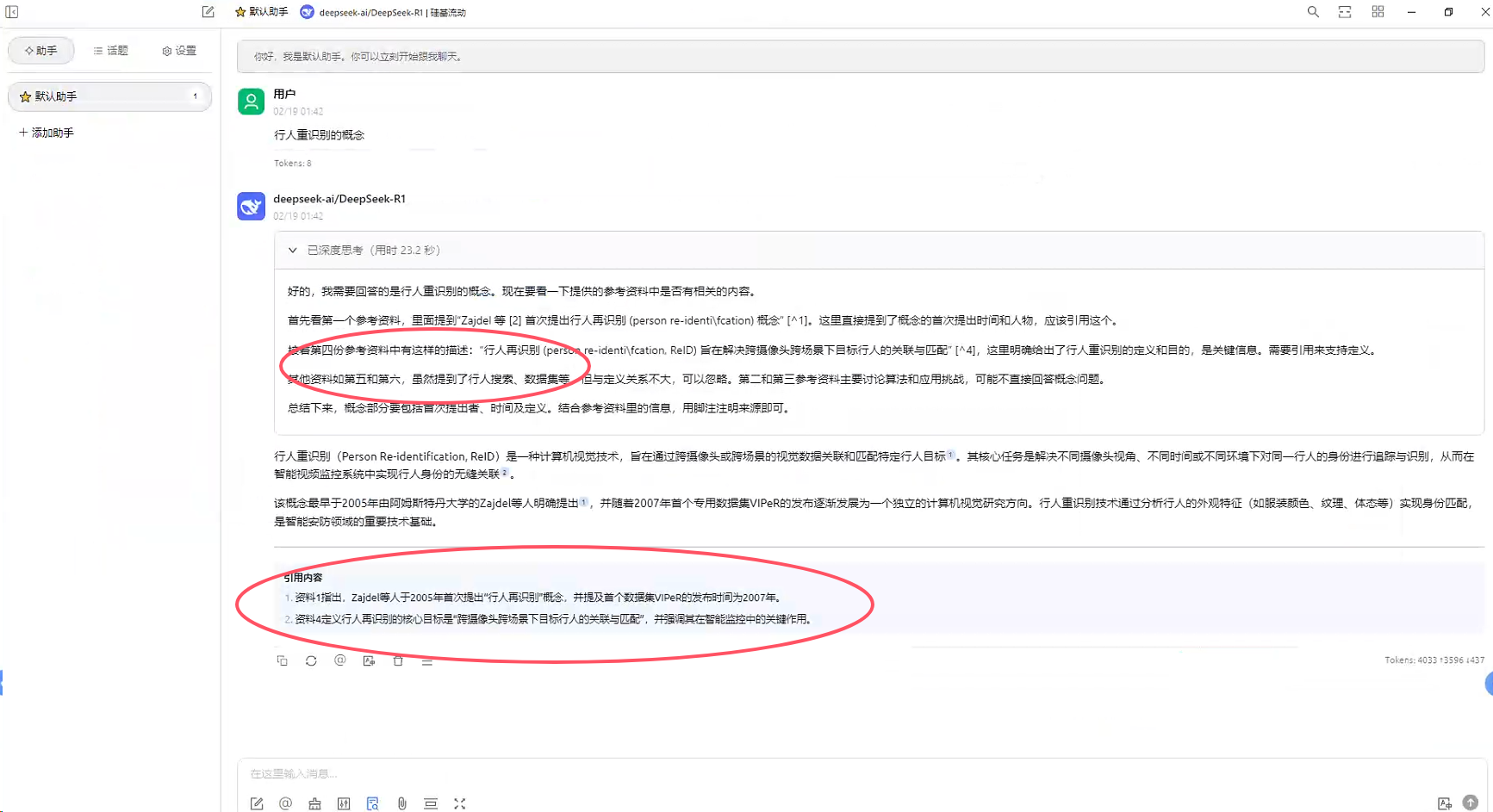
四、Ollama提速拉取模型
现象:有的时候,我们在ollama pull 拉取模型时,很长时间都拉取不下来,
原因:这是由于ollama拉取模型的网址并不在国内,网速就比较慢。
解决方案:使用魔塔社区的 GGUF 模型,或者 绿色上网后,挂 Tun 模式。
- ModelScope-魔塔社区上托管了数千个优质的GGUF格式的大模型(包括LLM和视觉多模态模型),并支持了Ollama框架和ModelScope平台的链接,通过简单的 ollama run命令,就能直接加载运行ModelScope模型库上的GGUF模型。
- GGUF(GPTQ for GPUs Unified Format)是一种针对大语言模型(LLM)权重文件的统一格式,旨在简化和标准化不同模型格式之间的转换和加载,有助于模型的加载和更加方便操作。
4.1、魔塔社区拉取模型格式
- 魔塔社区拉取模型格式:
ollama run modelscope.cn/{username}/{model} - 如
ollama run modelscope.cn/Qwen/Qwen2.5-3B-Instruct-GGUF
4.2、选择GGUF模型
在模型列表中,找到支持 GGUF 格式的模型。这些模型通常会标注“支持 GGUF”字样。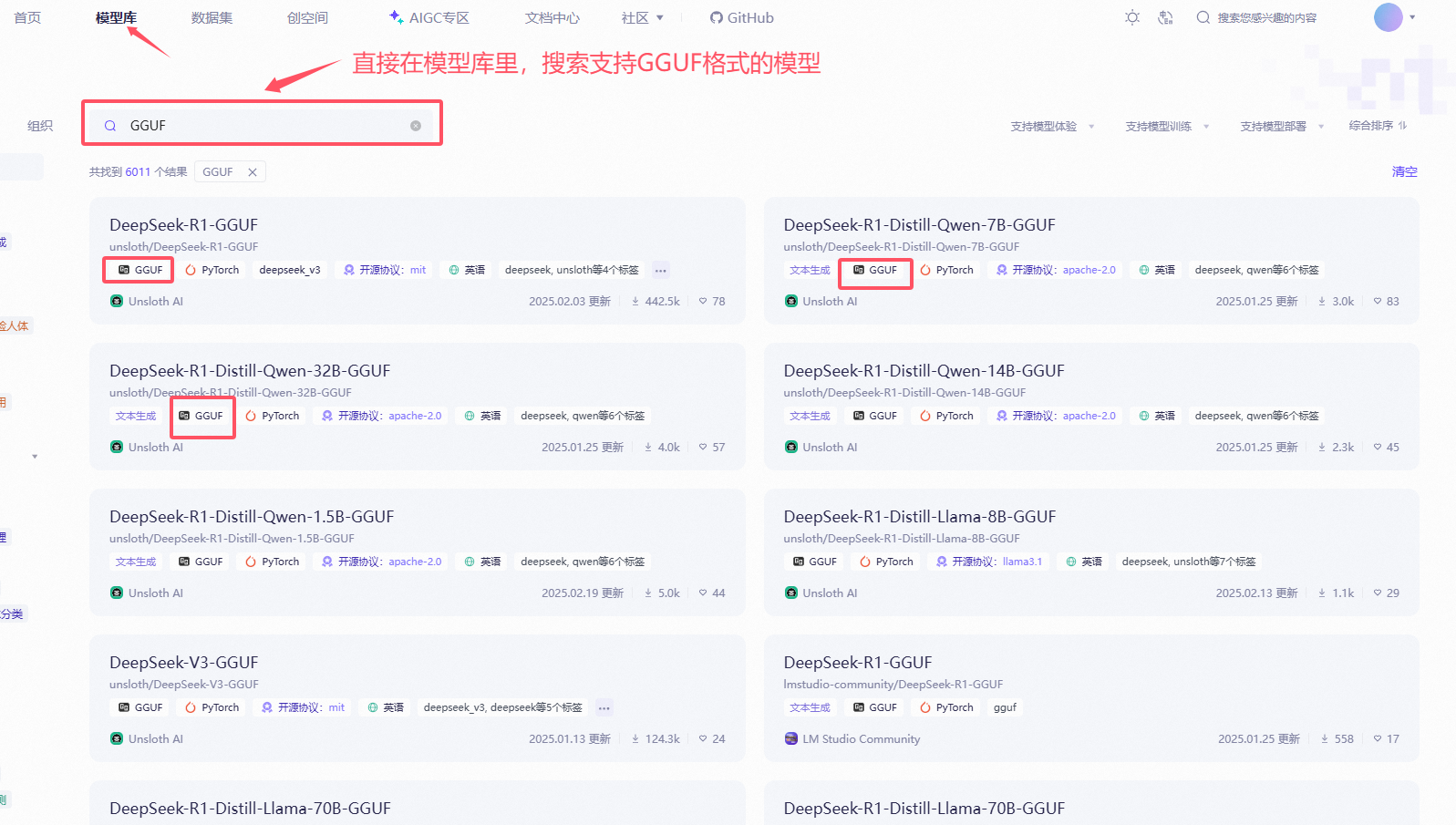
4.3、下载模型
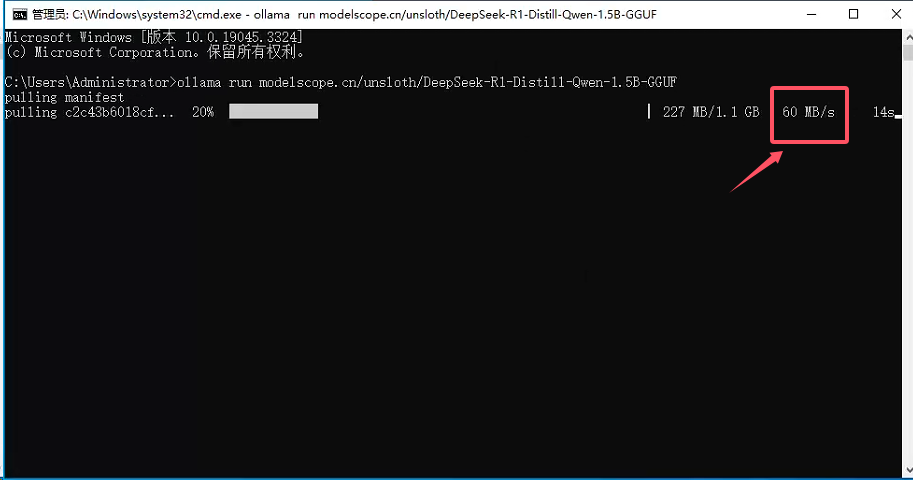
以DeepSeek-R1-Distill-Qwen-1.5B-GGUF为例,在ollama中运行命令
ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF
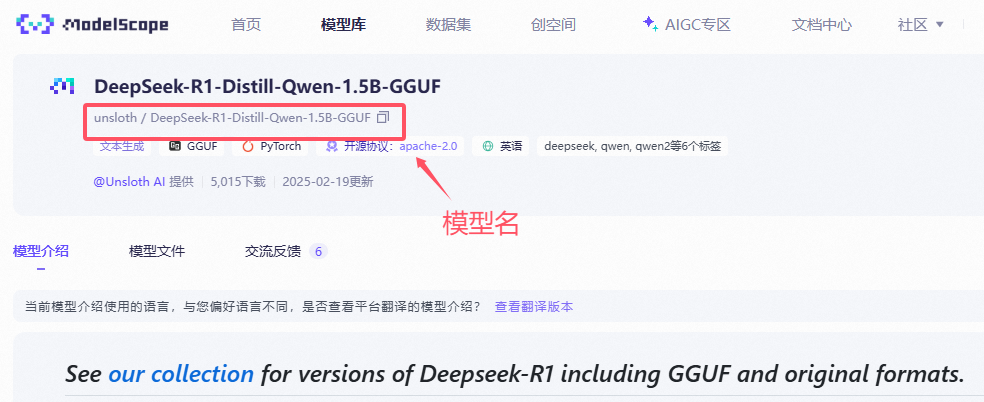
效果演示
模型测试
4.4、模型配置定制
Ollama支持加载不同精度的GGUF模型,同时在一个GGUF模型库中,一般也会有不同精度的模型文件存在,例如Q3_K_M, Q4_K_M, Q5_K等等,入下图所示: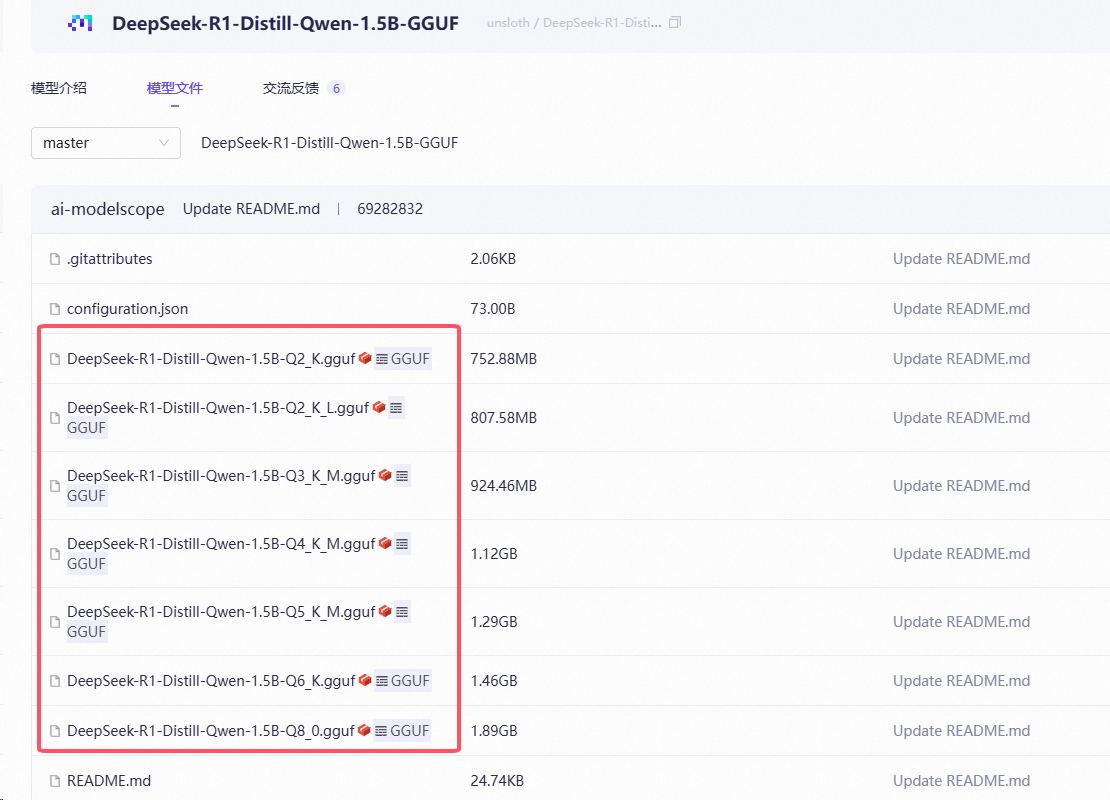
一个模型repo下的不同GGUF文件,对应的是不同量化精度与量化方法。默认情况下,**如果模型repo里有Q4_K_M版本的话,我们会自动拉取并使用该版本,在推理精度以及推理速度,资源消耗之间做一个较好的均衡。**如果没有该版本,我们会选择合适的其他版本。
拉取其他版本模型格式:
ollama run modelscope.cn/{username}/{model}:{模型版本}
以DeepSeek-R1-Distill-Qwen-1.5B-Q3_K_M.gguf模型为例子,这里选项大小写不敏感,也就是说,无论是:Q3_K_M,还是:q3_k_m,都是使用模型repo里的DeepSeek-R1-Distill-Qwen-1.5B-Q3_K_M.gguf 这个模型文件,完整命令如下:
ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF:DeepSeek-R1-Distill-Qwen-1.5B-Q3_K_M.gguf

五、VSCode+Cline+硅基流动
Cline:神级AI插件,对话式编程革命
- 功能特性:支持自然语言转代码、自动补全、代码优化,兼容ChatGPT、Claude等主流模型,更深度适配DeepSeek。
- 零成本优势:国内免费使用,无需订阅费用,仅需自行配置API密钥。
1、下载 Cline 插件
2、Cline 信息配置
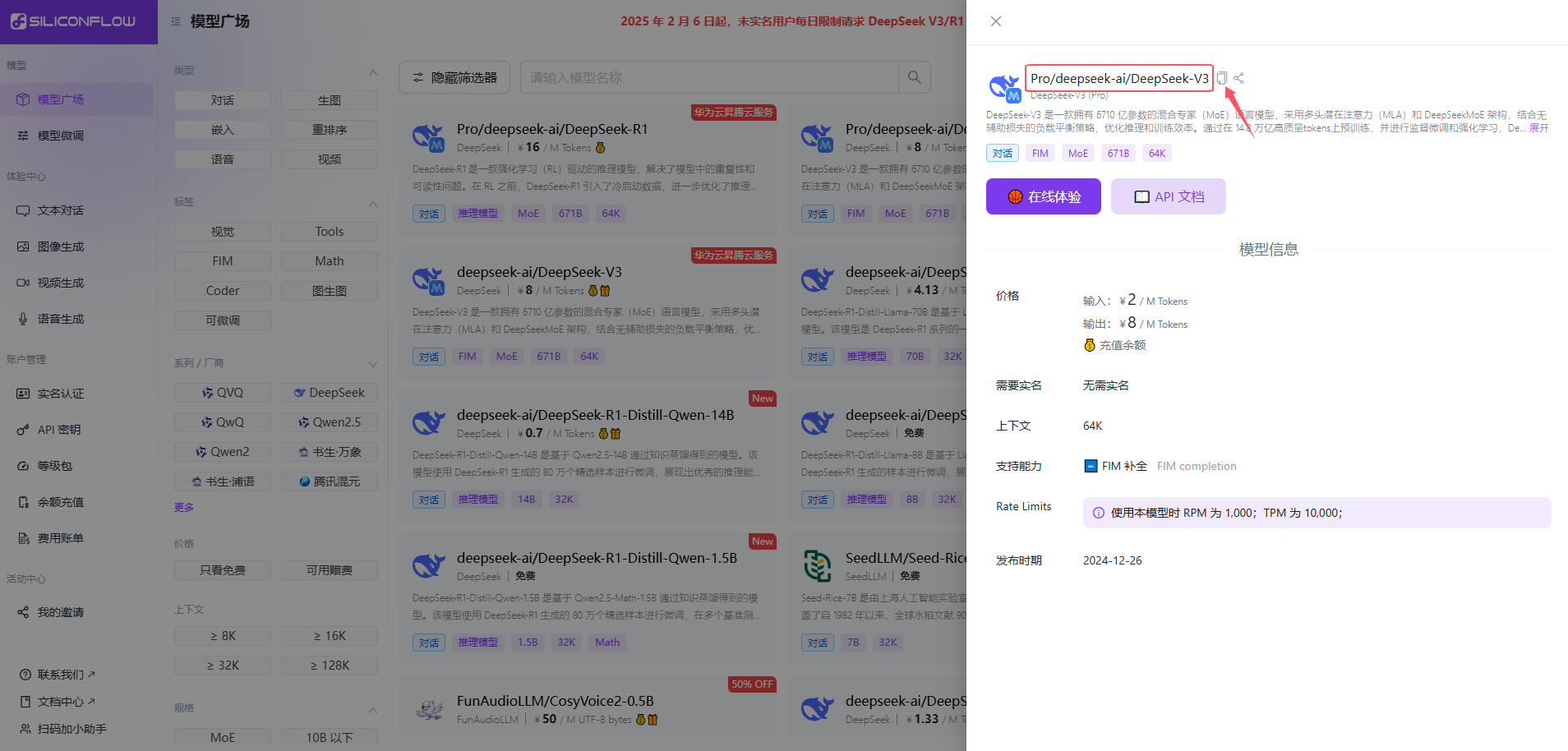
- API Provider: 选择
OpenAI Compatible - Base URL: https://api.siliconflow.cn
- API Key: 硅基流动获取的密钥
- Model ID: Pro/deepseek-ai/DeepSeek-V3(自行选择硅基流动的任意一模型)

3、cline 个性化设置

勾选下列四个框,最大请求设置为 20 到 1000之间,本文设置为 200

右侧栏显示

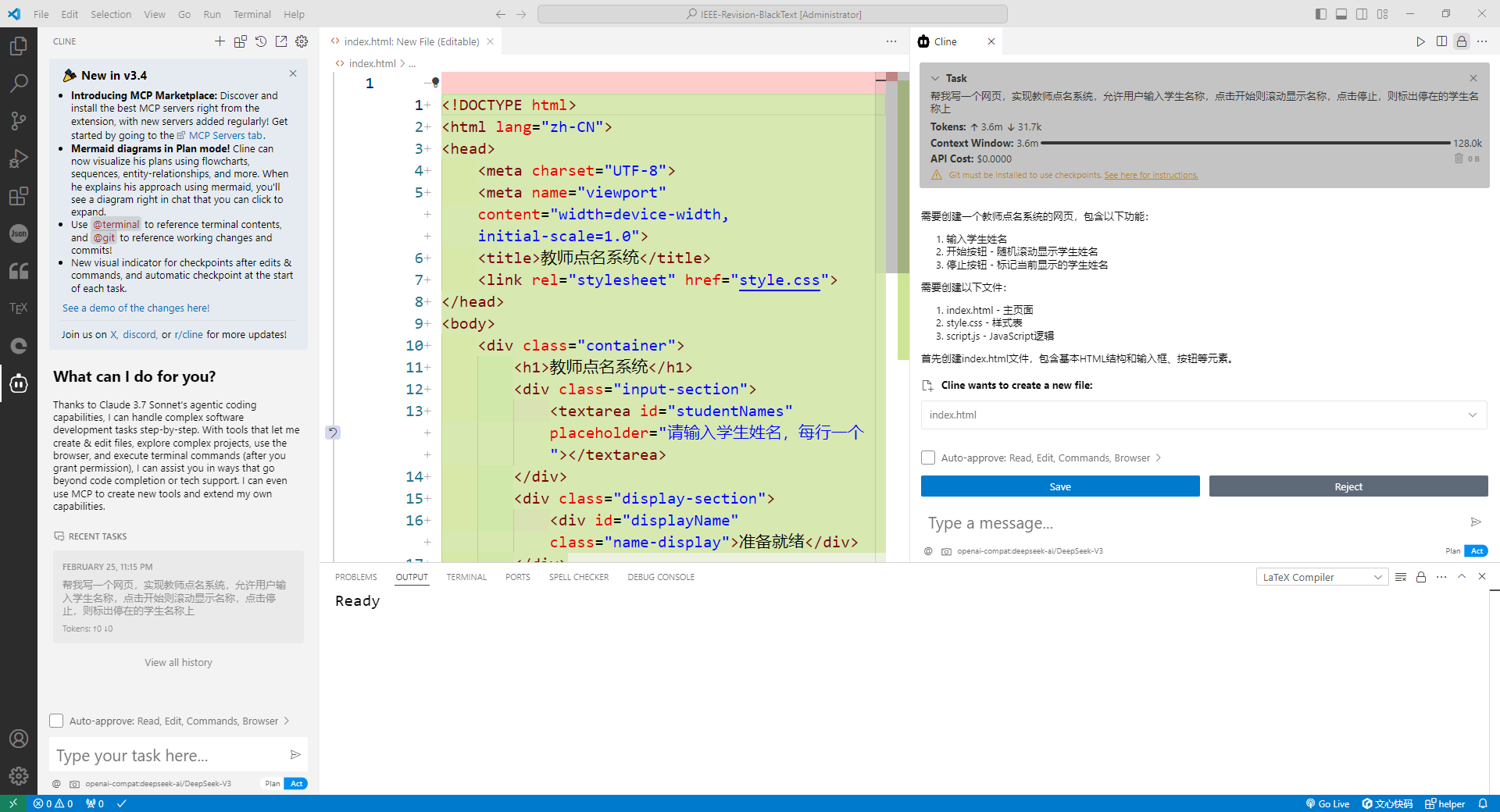
4、测试
需求:帮我写一个网页,实现教师点名系统,允许用户输入学生名称,点击开始则滚动显示名称,点击停止,则标出停在的学生名称上
六、常见问题
1、模型怎么不保存到C盘:关掉ollama之后,设置环境变量:OLLAMA_MODELS,环境变量的地址,改为你想要的地址,参考文章
2、怎么删除已经下载的模型,模型默认存放在了C盘,可以通过:ollama rm 模型名,删除新建的模型,但是缓存文件都还在,我的缓存文件放在C:\Users\ZG \ .ollama,找你对应的目录,删除即可。
3、本地部署 deepseek,也能联网,使用 page assist 的联网功能即可,page assist 默认用的是 google 浏览器,如果没有梯子,可以在设置中,修改使用的搜索引擎,用国内的。
七、参考文档

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)