
python-selenium遍历文件列表
需求:遍历QQ邮箱的在线文档并下载:审查一下元素,这一块也就是我们所需要的文件列表:文件列表的xpath:/html/body/div[2]/div/div[2]/div[2]/div[2]/ul每个文件的xpath:/html/body/div[2]/div/div[2]/div[2]/div[2]/ul/li[i]这个就是下载按钮的页面元素!直接上代码:def download_onlined
需求:遍历QQ邮箱的在线文档并下载
关于QQ邮箱自动登录的问题可以参考:python实现滑动验证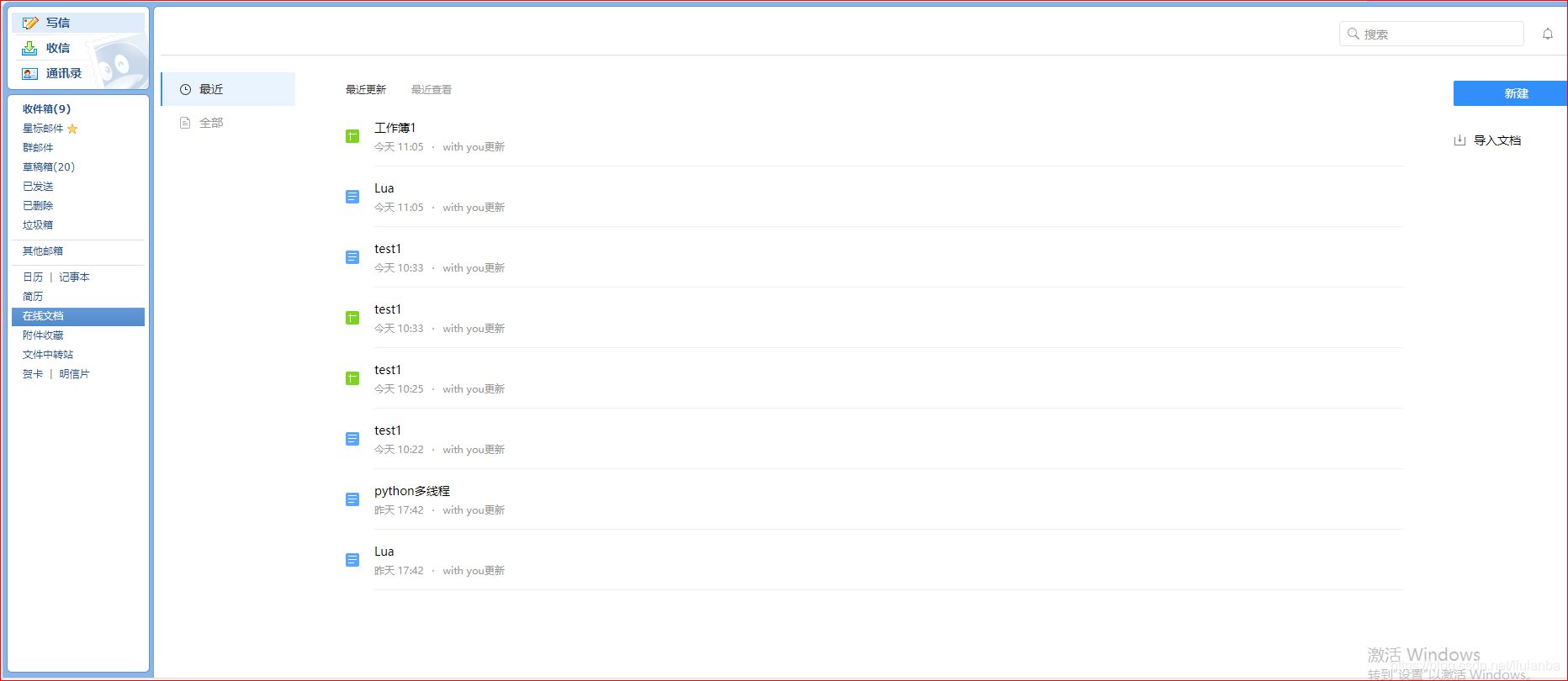 审查一下元素,这一块也就是我们所需要的文件列表:
审查一下元素,这一块也就是我们所需要的文件列表: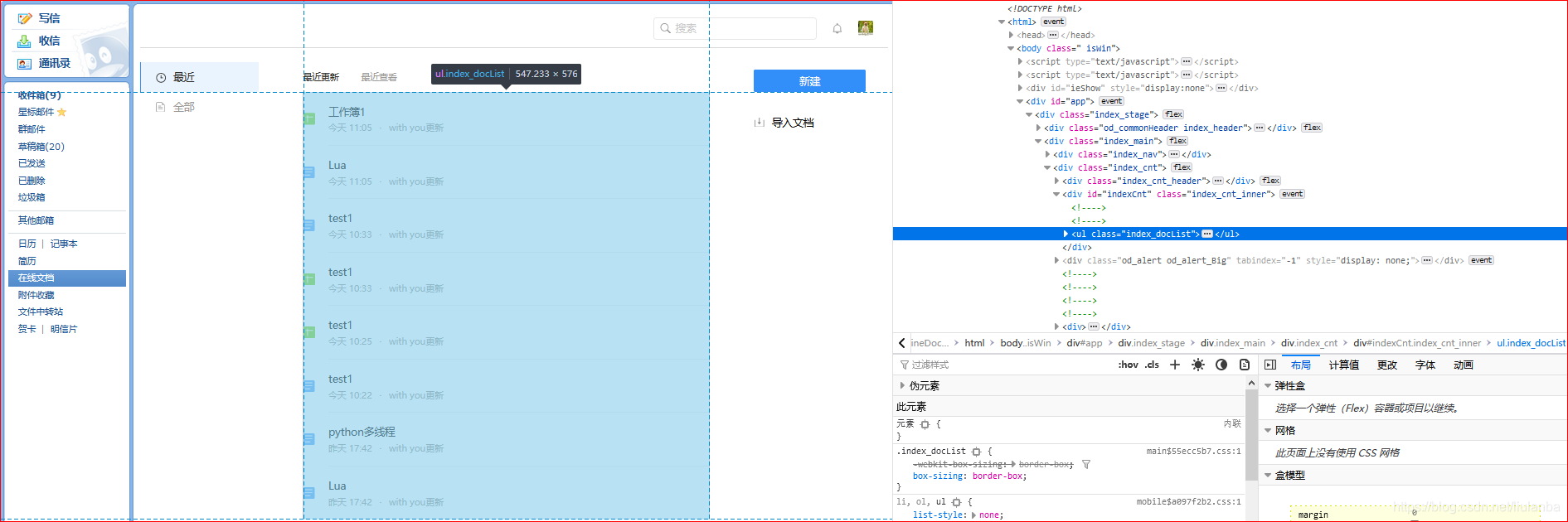
文件列表的xpath:/html/body/div[2]/div/div[2]/div[2]/div[2]/ul
每个文件的xpath:/html/body/div[2]/div/div[2]/div[2]/div[2]/ul/li[i]
 这个就是下载按钮的页面元素!
这个就是下载按钮的页面元素!
直接上代码:
def download_onlinedoc():
global browser
onlinedoc_button=browser.find_element_by_id('folder_onlinedoc_td')
onlinedoc_button.click()
time.sleep(2)
browser.switch_to.frame('mainFrame')
current_url1=browser.current_url
print("进入第一层框架:",current_url1)
time.sleep(2)
browser.switch_to.frame('onlineDoc_detail_iframe')
current_url2 = browser.current_url
print("进入第二层框架:", current_url2)
time.sleep(2)
docList=browser.find_element_by_class_name('index_docList')
alldocs=docList.find_elements_by_class_name('index_docItem')
print("一共含有{}个文件".format(len(alldocs)))
for x in alldocs:
print(x)
opreations=x.find_element_by_class_name("index_docItem_operation")
opreations.click()
time.sleep(2)
menus=opreations.find_element_by_class_name('od_dropdownMenu')
menusidd=menus.find_element_by_id('menu')
dowload_button=menusidd.find_element_by_class_name('od_dropdownMenu_item.od_tipsBubbleWrap')
dowload_button.click()
# pyautogui.hotkey('down')
pyautogui.hotkey('enter')
time,sleep(2)
pyautogui.click(250,600)
browser.refresh()
time.sleep(5)
注意:
**1.alldocs=docList.find_elements_by_class_name(‘index_docItem’)获取文件列表,得到一个list
2.嵌套元素元素需要一层一层的获取,不能跨层获取,不熟悉的话可以用xpath来理一下
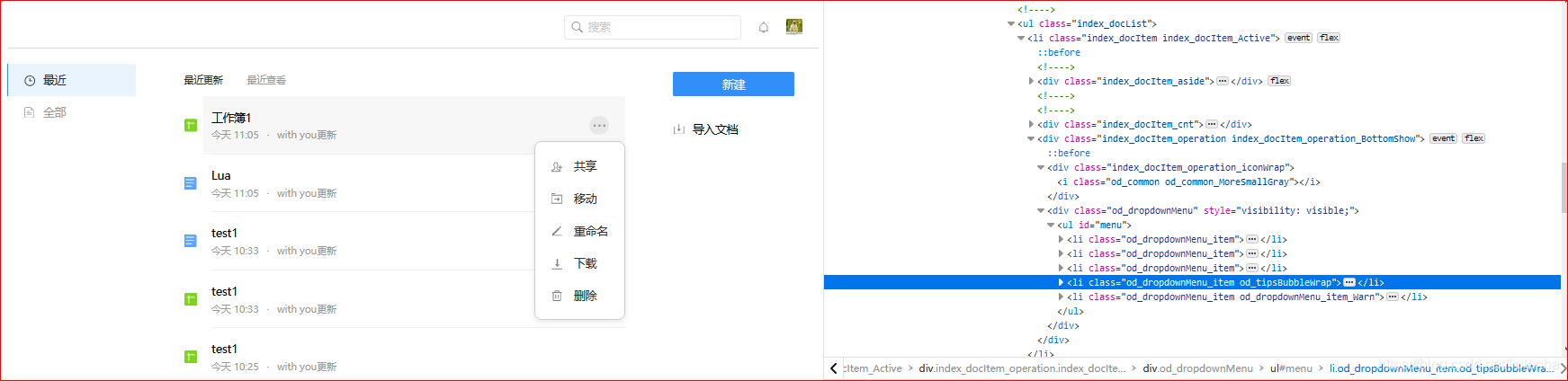
3.网页元素会变动(比如点击按钮出现新的下拉框),获取到哪一层就前进到那层并使用find_element_xxx定位,不要提前点开,否则可能会出错!**比如下面这个: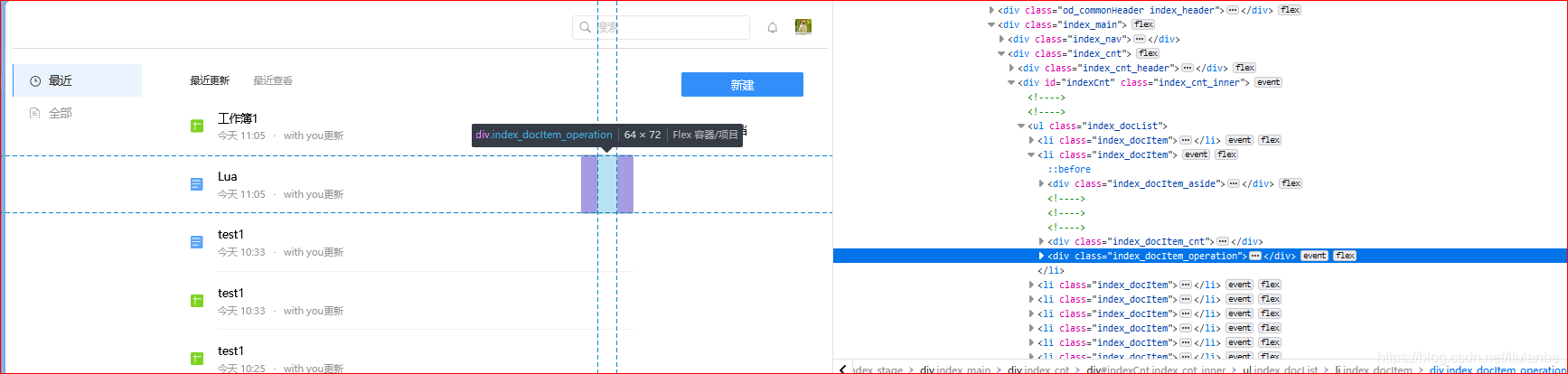
最右边的那个元素:
class=“index_docItem_operation”
但是点击之后就变了:
class=“index_docItem_operation index_docItem_operation_BottomShow”
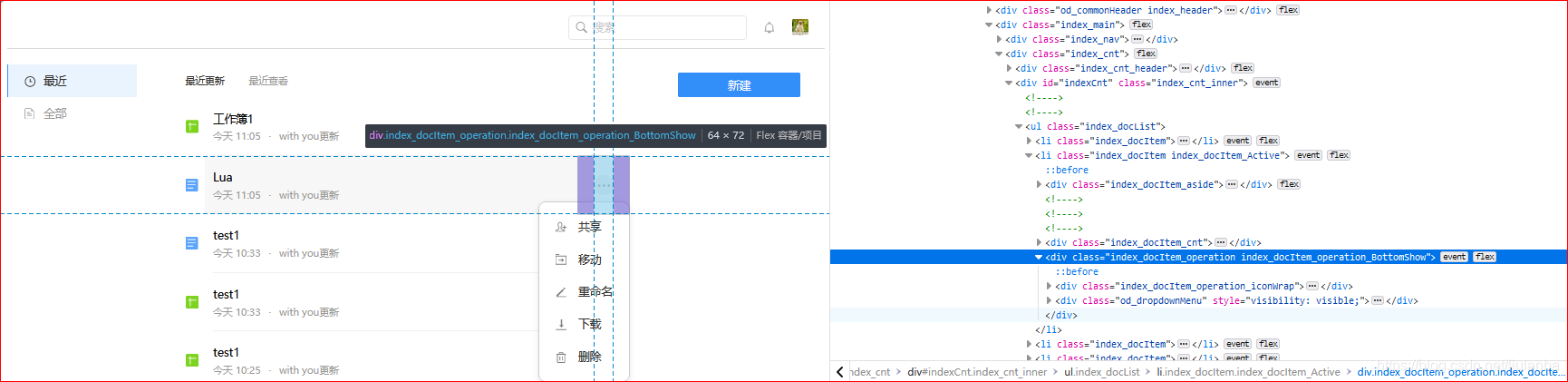 使用下面这个就会找不到元素!
使用下面这个就会找不到元素!
个人踩坑记录,欢迎交流讨论!

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 7
7 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)