
《scikit-learn机器学习》糖尿病预测(KNN)
本章看完以后的感受:1、我们先对数据进行加载,由于确定了数据是没有问题的,所以不用对数据进行清洗2、然后确定每行每列,找到我们需要的目标值,也就是target,在本书中的target为0或者13、找到目标值以后,将目标值与非目标值分离,再将数据按照比例分为测试集和训练集。4、选择的是knn的三种模型,一种是原基础的knn,一种是带有权重的knn,还有一种是确定了半径的knn(上一篇中的knn的俩个
本章看完以后的感受:
- 1、我们先对数据进行加载,由于确定了数据是没有问题的,所以不用对数据进行清洗
- 2、然后确定每行每列,找到我们需要的目标值,也就是target,在本书中的target为0或者1
- 3、找到目标值以后,将目标值与非目标值分离,再将数据按照比例分为测试集和训练集。
- 4、选择的是knn的三种模型,一种是原基础的knn,一种是带有权重的knn,还有一种是确定了半径的knn(上一篇中的knn的俩个变异就是后面的这俩种)
- 5、然后对他们三个进行训练集训练,选取最佳的一个模型,在对模型进行训练,通过学习曲线确定模型是否ok,然后结束了。
- 6、但是本书的knn模型的训练集score只有0.84,测试集的score也只有0.72,说明模型是欠拟合了
- 7、后面还教到将数据特征缩小,也就是提取出关系最大的数据特征,再来训练模型等等
正式开始代码理解:
1、加载数据
format的作用就是格式化
# 加载数据
data = pd.read_csv('datasets/pima-indians-diabetes/diabetes.csv')
print(data.shape)
print('dataset shape {}'.format(data.shape)) # 格式化
data.head()
输出: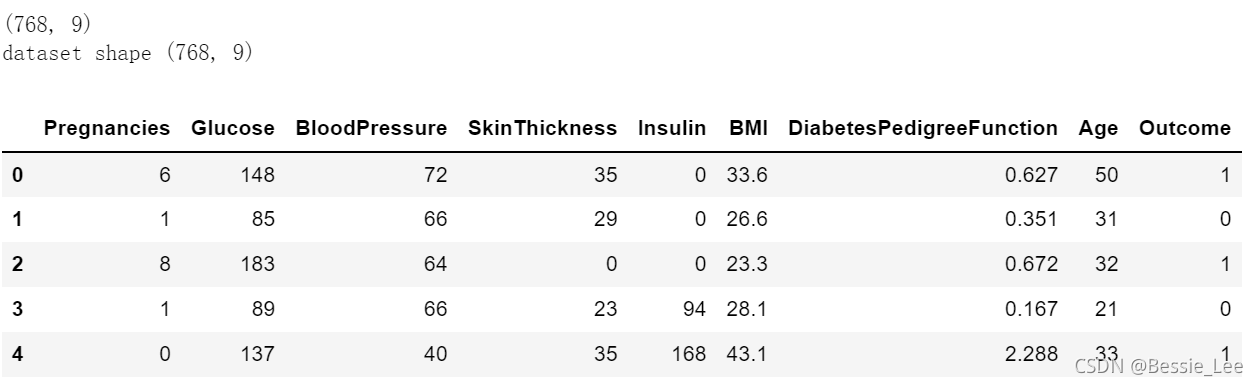
2、特征值
看看特征值的比例
data.groupby("Outcome").size()

3、分离目标值
由于目标值target位于最后一列,所以直接分离(剔除了“outcome”)
# 分离目标值
X = data.iloc[:, 0:8]
Y = data.iloc[:, 8]
print('shape of X {}; shape of Y {}'.format(X.shape, Y.shape))
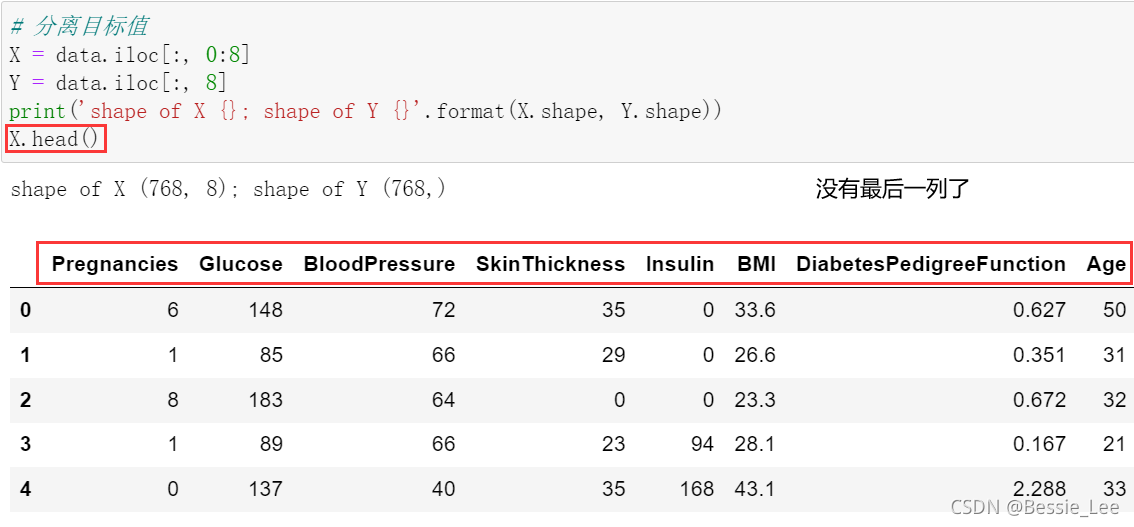
4、分离测试集和训练集
按照0.2比例的分离数据集
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2);
5、选择模型(三个knn)
三个模型:knn,带有权重的knn,确定圆圈范围的knn算法
from sklearn.neighbors import KNeighborsClassifier, RadiusNeighborsClassifier
models = []
models.append(("KNN", KNeighborsClassifier(n_neighbors=2)))
models.append(("KNN with weights", KNeighborsClassifier(
n_neighbors=2, weights="distance")))
models.append(("Radius Neighbors", RadiusNeighborsClassifier(
n_neighbors=2, radius=500.0)))
6、输出结果
把训练集放进去,一个个去判断,计算score的值,就是model.score(X_test, Y_test)
results = []
for name, model in models:
model.fit(X_train, Y_train)
results.append((name, model.score(X_test, Y_test)))
for i in range(len(results)):
print("name: {}; score: {}".format(results[i][0],results[i][1]))
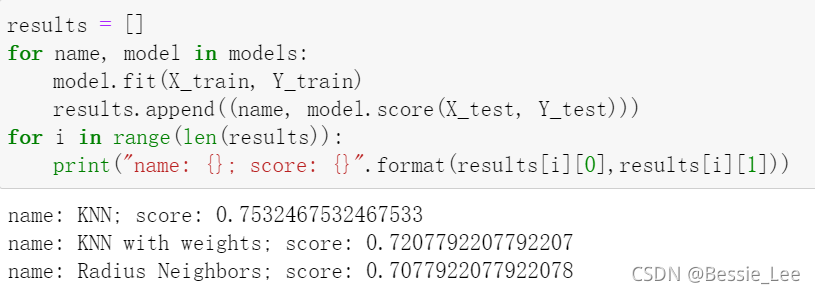
7、把数据集再分,分成10段,有一段称为交叉训练集,然后搞平均值
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
results = []
for name, model in models:
kfold = KFold(n_splits=10)
cv_result = cross_val_score(model, X, Y, cv=kfold)
results.append((name, cv_result))
for i in range(len(results)):
print("name: {}; cross val score: {}".format(
results[i][0],results[i][1].mean()))

8、确定模型
根据上面的数据,咱知道基础的KNN是最好的模型
9、训练KNN模型,看看预测结果
knn = KNeighborsClassifier(n_neighbors=2)
knn.fit(X_train, Y_train)
train_score = knn.score(X_train, Y_train)
test_score = knn.score(X_test, Y_test)
print("train score: {}; test score: {}".format(train_score, test_score))

10、进一步画学习曲线
我们发现,这个学习曲线也很低,所以说这个模型是属于欠拟合模型
from sklearn.model_selection import ShuffleSplit
from common.utils import plot_learning_curve
knn = KNeighborsClassifier(n_neighbors=2)
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
plt.figure(figsize=(10, 6))
plot_learning_curve(plt, knn, "Learn Curve for KNN Diabetes",
X, Y, ylim=(0.0, 1.01), cv=cv);
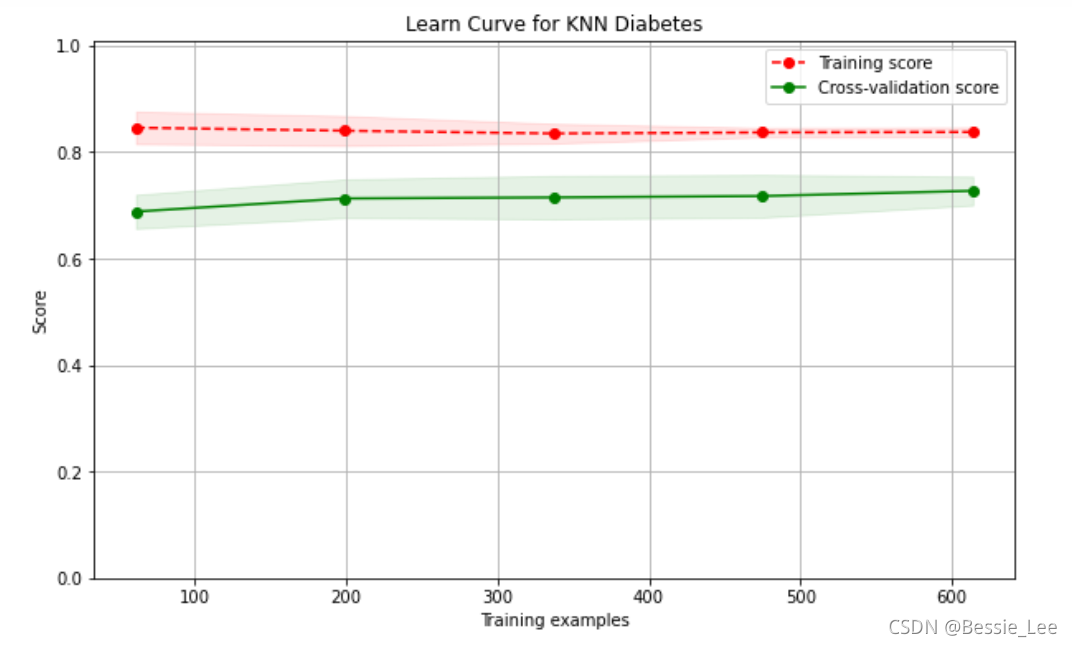
结束了
数据可视化:
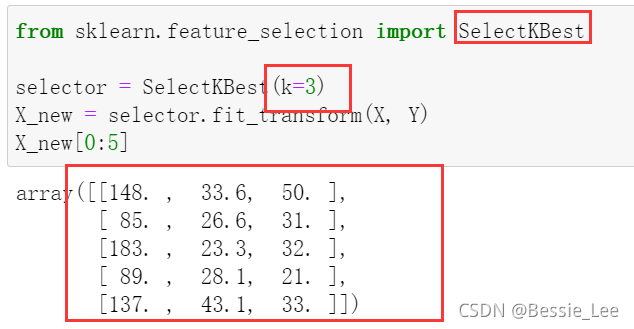
1、我们使用 SelectKBest 来选择相关性最大的两个特征
直接调用SelectKBest(k = n),n就是我们需要的特征变量的数量
from sklearn.feature_selection import SelectKBest
selector = SelectKBest(k=2)
X_new = selector.fit_transform(X, Y)
X_new[0:5]
2、再进行模型的一个选择
进行选择一个合适的模型
results = []
for name, model in models:
kfold = KFold(n_splits=10)
cv_result = cross_val_score(model, X_new, Y, cv=kfold)
results.append((name, cv_result))
for i in range(len(results)):
print("name: {}; cross val score: {}".format(
results[i][0],results[i][1].mean()))

3、发现问题
发现knn还是最高的,同时他还是欠拟合,这就很🐕了
4、解决问题
为啥knn就是不能分辨呢???
画出对应的数据图:
# 画出数据
plt.figure(figsize=(10, 6))
plt.ylabel("BMI")
plt.xlabel("Glucose")
plt.scatter(X_new[Y==0][:, 0], X_new[Y==0][:, 1], c='r', s=20, marker='o'); # 画出样本
plt.scatter(X_new[Y==1][:, 0], X_new[Y==1][:, 1], c='g', s=20, marker='^'); # 画出样本
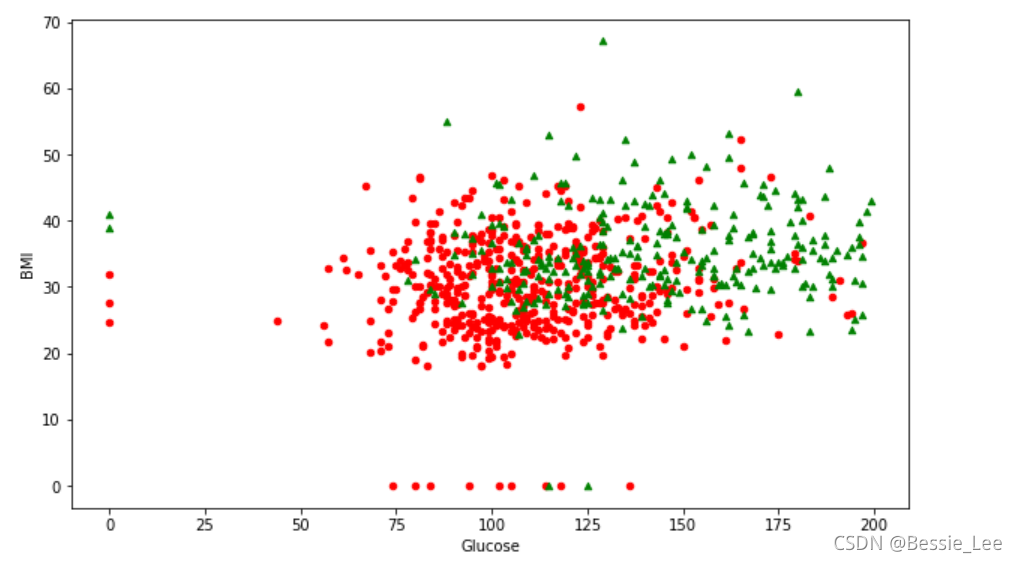
原来是因为数据太密集了,分不清到底是在哪个地方,导致最后的结果只有0.72,属于欠拟合。
模型的进化:

卡方差与F值

提个小问题:在本篇博客中,哪一种算法相对较为合适?

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)