
使用Python 爬取视频
本文章爬取视频以 “.ts” 文件为例,可从视频网站爬取相关视频碎片,最后拼接成一个完整的视频首先安装Python,安装方法可参考菜鸟教程(https://www.runoob.com/python/python-install.html)1、打开一个视频网站,F12,检查网站代码,找到 NetWork --> XHR ,选择视频碎片的链接,如下:2、开始编写代码进行视频下载import r
本文章爬取视频以 “.ts” 文件为例,可从视频网站爬取相关视频碎片,最后拼接成一个完整的视频
首先安装Python,安装方法可参考菜鸟教程(Python 环境搭建 | 菜鸟教程)
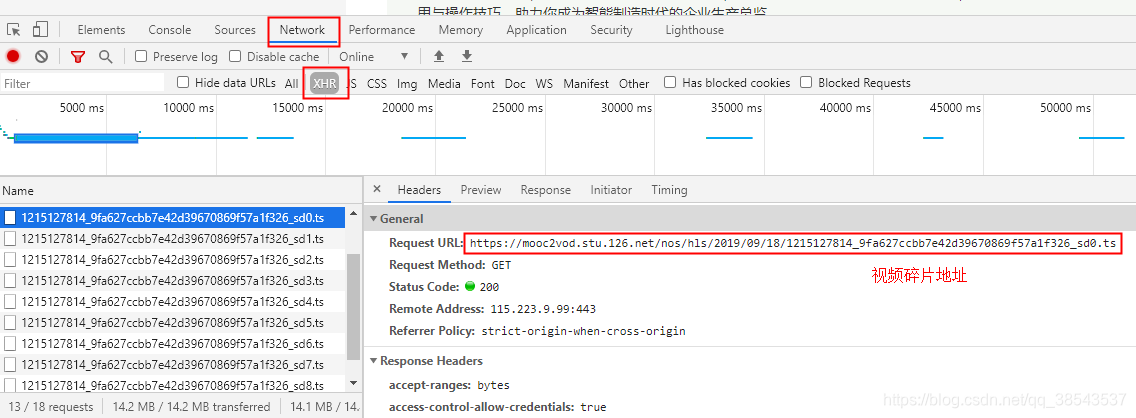
1、打开一个视频网站,F12,检查网站代码,找到 NetWork --> XHR ,选择视频碎片的链接,如下:
2、开始编写代码进行视频下载
import requests
import os
try:
def test(i):
# 1.准备url
url = "https://mooc2vod.stu.126.net/nos/hls/2019/09/18/1215127814_9fa627ccbb7e42d39670869f57a1f326_sd%d.ts" % i
# 视频存放位置
root = "D://video//"
# 抓取文件起的名字
path = root + "python%d.mp4" % i
print(path)
if not os.path.exists(root):
# 如果该目录不存在就创建它
os.mkdir(root)
if not os.path.exists(path):
# 获取到目标视频的所有信息
r = requests.get(url)
# 打印访问的状态码是否为200
print(r.status_code)
# 以二进制写的方式将r的二进制内容写入path
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
# 写一个循环方法,获取所有的视频
for i in range(99):
test(i) # 调用爬取视频方法
except:
print("爬取失败")代码解析:
视频碎片原地址:https://mooc2vod.stu.126.net/nos/hls/2019/09/18/1215127814_9fa627ccbb7e42d39670869f57a1f326_sd0.ts
循环下载的视频地址:https://mooc2vod.stu.126.net/nos/hls/2019/09/18/1215127814_9fa627ccbb7e42d39670869f57a1f326_sd%d.ts" % i
sd0:是视频的序号,视频会以sd0、sd1、sd2 ······进行排序,绥中组成一个完成的视频,要想循环下载所有视频,就需要一个循环方法,并且修改视频路径,用循环的数字代替sd后边的数字,
将sd后边的数字换成%d , 然后在路径后边添加 % i, i 是循环出来的数字,(默认从0开始)
我的示例循环次数是99,真正使用时,需要根据视频碎片的数量来进行循环(有多少个碎片就循环多少次)
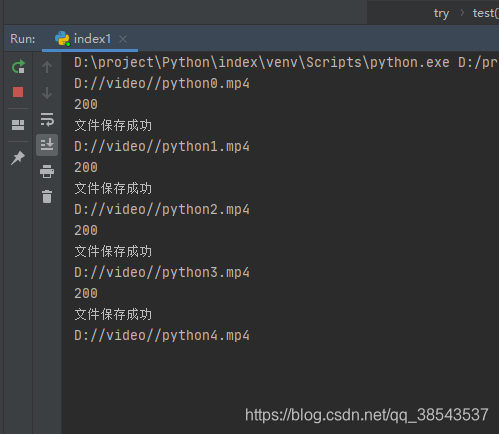
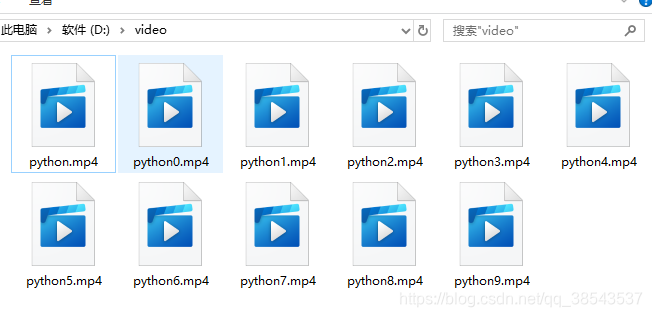
3、最后运行文件就可以爬取视频了,以下是成功截图
4、最后将视频碎片拼接成视频即可大功告成。
打开命令提示符窗口,将当前目录切换到视频碎片所在的文件夹,输入如下命令:
copy /b *.ts a.mp4我在爬取时直接爬取的.mp4文件,所以合并的时候使用的命令是:
copy /b *.mp4 a.mp4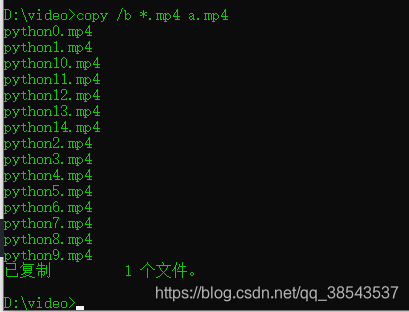
合并后如下图,文件夹里边生成了一个合并后新的a.mp4文件
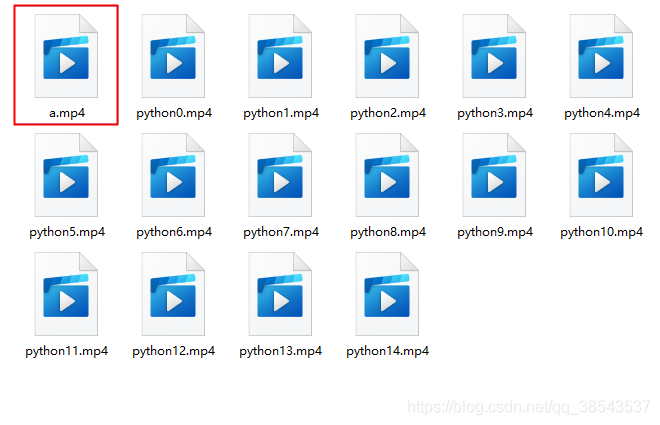
至此完成视频爬取,感谢支持!

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)