
十分钟sparkstreaming简单入门测试(2018-04-19)
idea编辑器安装下载spark安装包和scala的安装包添加环境变量idea中新建项目启动nc -lk启动流计算程序idea编辑器安装参考笔记:http://www.aboutyun.com/thread-22320-1-1.html给大家准备了资料包:下载地址:https://pan.baidu.com/s/1auAjP4npWDD0o...
idea编辑器安装
参考笔记:http://www.aboutyun.com/thread-22320-1-1.html

给大家准备了资料包:
下载地址:
https://pan.baidu.com/s/1auAjP4npWDD0oGfNjXlySQ

###下载spark安装包和scala的安装包
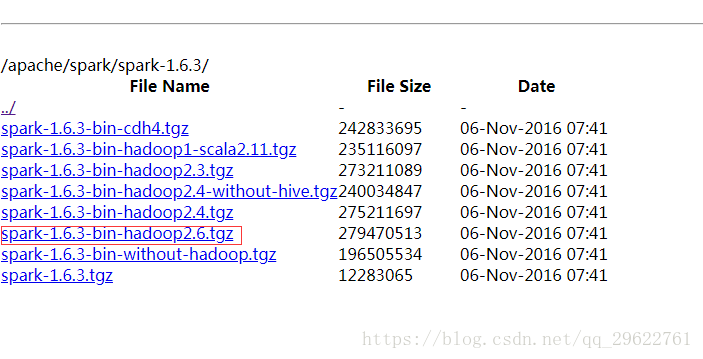
http://mirrors.hust.edu.cn/apache/spark/spark-1.6.3/
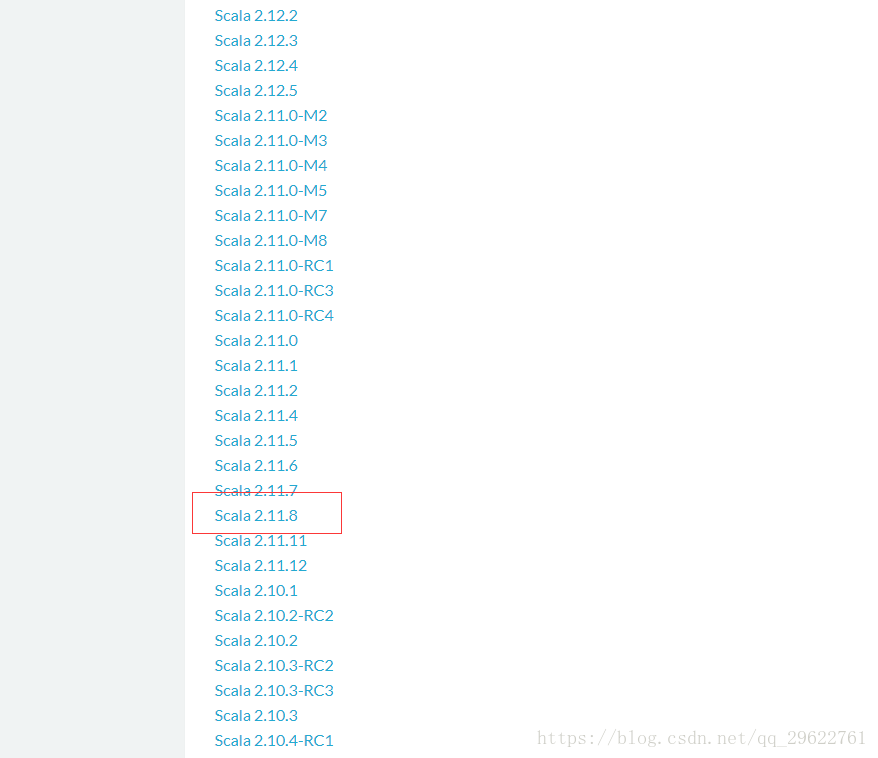
https://www.scala-lang.org/download/all.html
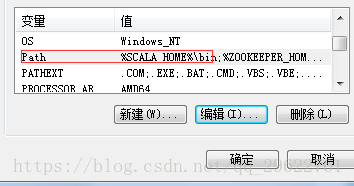
添加环境变量
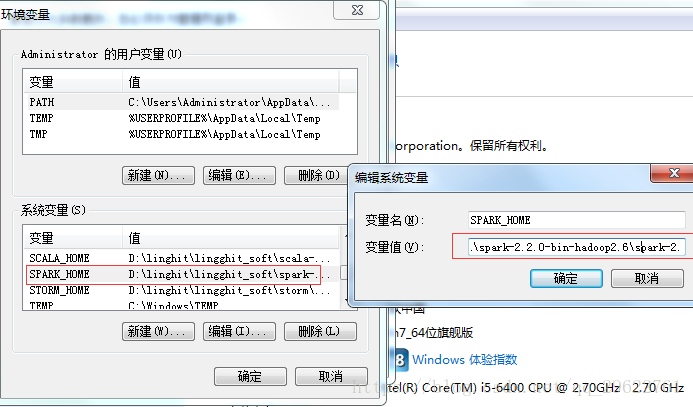
我的地址是D:\linghit\lingghit_soft\spark-2.2.0-bin-hadoop2.6\spark-2.2.0-bin-hadoop2.6
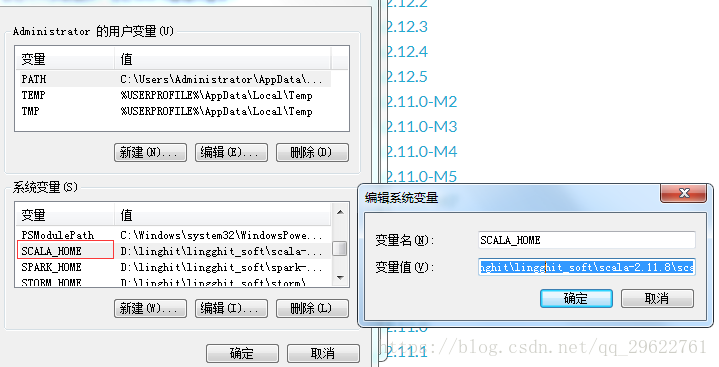
我的地址是:D:\linghit\lingghit_soft\scala-2.11.8\scala-2.11.8
最后Path里面也要添加
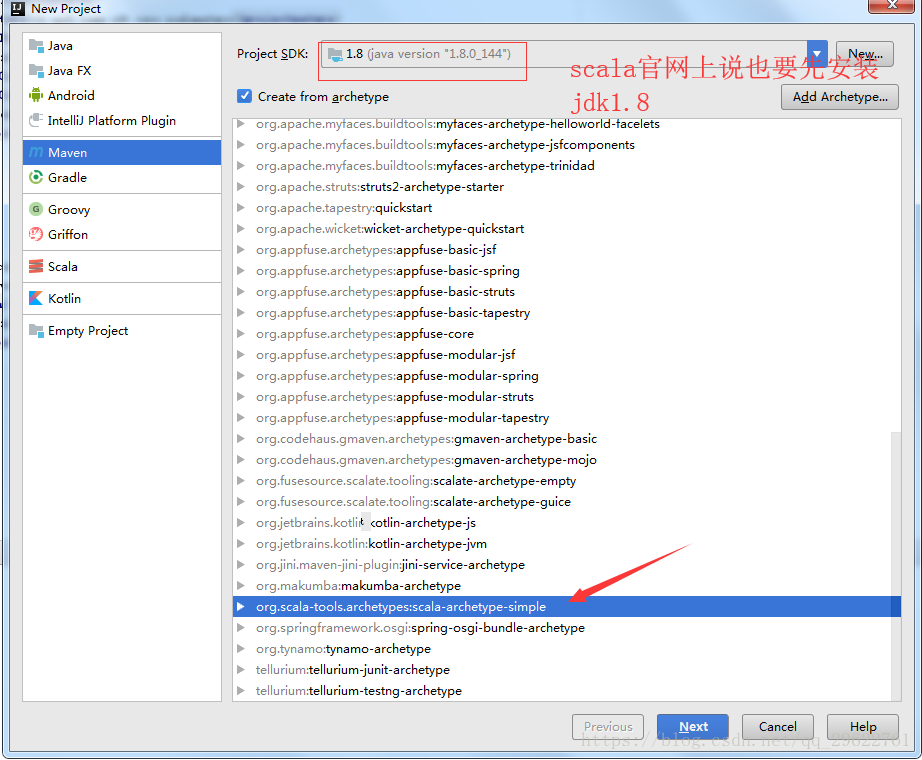
###idea中新建项目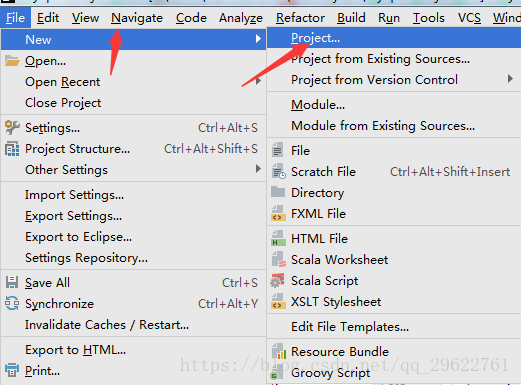
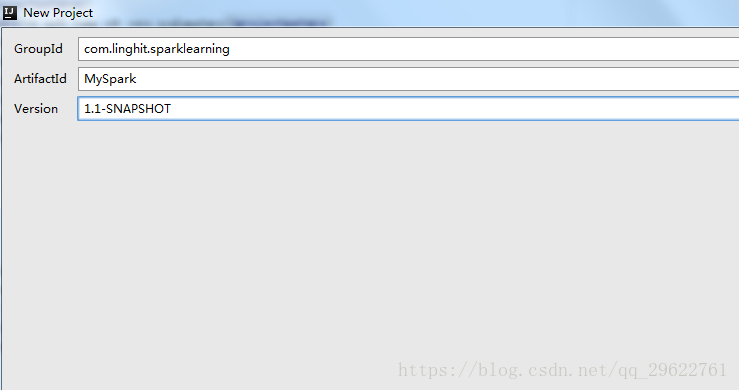


添加:
<spark.version>1.6.3</spark.version>
<hadoop.version>2.6.4</hadoop.version>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
最终的pom.xml文件是这样的
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.linghit.sparklearning</groupId>
<artifactId>MySpark</artifactId>
<version>1.1-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>1.6.3</spark.version>
<hadoop.version>2.6.4</hadoop.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
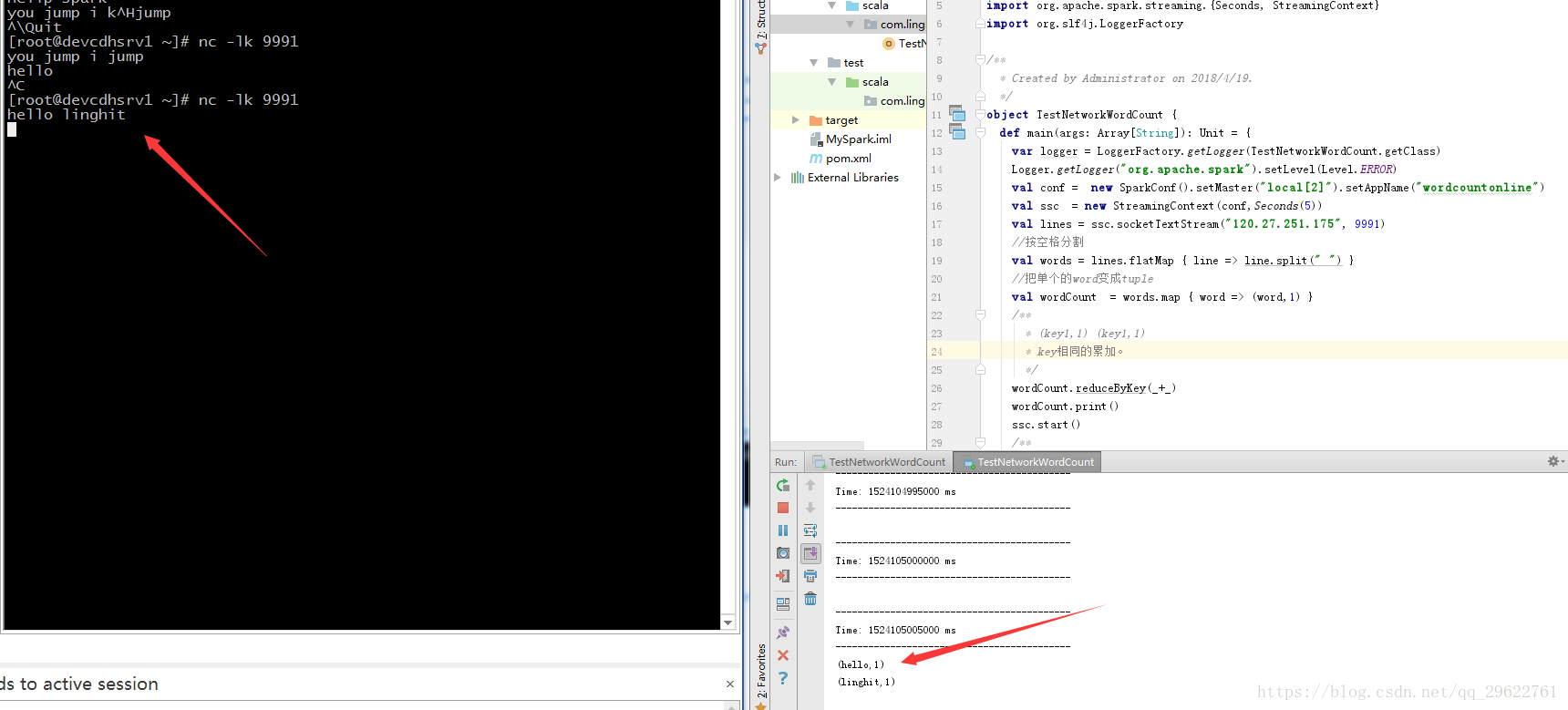
启动nc -lk
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.slf4j.LoggerFactory
/**
* Created by Administrator on 2018/4/19.
*/
object TestNetworkWordCount {
def main(args: Array[String]): Unit = {
var logger = LoggerFactory.getLogger(TestNetworkWordCount.getClass)
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
val conf = new SparkConf().setMaster("local[2]").setAppName("wordcountonline")
val ssc = new StreamingContext(conf,Seconds(5))
val lines = ssc.socketTextStream("120.27.251.175", 9991)
//按空格分割
val words = lines.flatMap { line => line.split(" ") }
//把单个的word变成tuple
val wordCount = words.map { word => (word,1) }
/**
* (key1,1) (key1,1)
* key相同的累加。
*/
wordCount.reduceByKey(_+_)
wordCount.print()
ssc.start()
/**
* 等待程序结束
*/
ssc.awaitTermination()
ssc.stop(true)
}
}
启动流计算程序


GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)