
传统渲染管线
Local treatment of VPDT is rare but important for improving the understanding of light behavior in photodynamic reaction. For this, a device possesses the abilities of adjusting the irradiance, irradi
1 基本概念
在计算机图形学中,渲染管线是一套CPU与GPU协同作用,将三维场景中的几何形状、纹理、光照等信息转换成二维图像的一系列的计算机操作的总和。渲染管线也称为渲染流水线。
流水线可以类比汽车工业的发展,在1913年前福特开发出汽车流水线前,汽车组装只能让一位位工人逐工序完成,年产不过12台,效率极低;而引入了流水线概念后,每位工人只需要做不停地做同一道工序,所有工序并行进行,极大地提高了工厂的生产效率,生产效率提高了8倍。
GPU对图像处理的高效率体现了同样的思路,GPU采用了数量众多的计算单元和超长的流水线,但每一个部分只有非常简单的控制逻辑(如同《摩登时代》中一个流水线工人只负责拧一个螺丝)。尽管计算能力不如CPU,但耐不住人多力量大;这就好比拿出一百道十以内加减法运算题给一百个小学生和一个资深大学教授来做,尽管小学生能力并不如何,但这么多个小学生同时做这些题消耗的总时长,总比一个学识渊博大学教授做要来得快。
渲染管线的特点:分工与并行。分工是首要特点,它是将任务拆分成多个子任务,并根据不同子任务的特点,交付给不同的执行单元。并行是指(1)不同的子任务的执行单元允许同时进行操作;(2)一个子任务的执行单元包含多个子单元并行操作。
2 完整流程
渲染管线的流程并没有绝对统一的一个标准,而是随着技术的发而持续变化。Unity Shader入门精要将流程分为应用阶段、几何阶段和光栅化阶段,Real-time Rendering则分为应用阶段、几何阶段、光栅化和像素处理等。除应用阶段外,后续阶段均在GPU实施。
2.1 应用阶段
应用阶段:用户进行数据准备、上传数据、渲染状态设置、调用Draw Call等操作。
数据准备:在内存中创建或加载完毕一切与渲染有关的数据,如待渲染物体的几何、颜色和法线信息、相机信息、光源信息、纹理、法线贴图等数据创建、加载到内存中,等待后续数据处理。
由于大多数的显卡没有直接访问RAM的能力,或其访问速度很慢,因此需要将数据提前加载到显卡GPU可以快速读写的显存中。当把数据加载到显存后,内存中的数据便可以释放了,但对于一些还需要使用的数据则需要继续保留在内存中,如CPU需要网格数据进行碰撞检测。
上传数据:是将处理完毕的数据从内存上传到显存的过程,这里特指的是几何信息、纹理贴图等信息量较大的数据。若每个顶点具有不同的颜色,则顶点颜色信息量较大。在上传渲染数据时,颜色信息被一次性上传到显存中,占用一片连续显存。但若所有的顶点具有相同颜色,则可作为渲染状态直接设置到着色器中。
渲染状态设置:渲染状态是在渲染过程中使用到的渲染信息的总和。我们可以将渲染信息分为以下两类:
(1)单个物体着色过程中使用到的渲染信息。包含渲染该物体使用的着色器,着色时使用的纹理(及采样方式)、材质、光照、阴影等信息。可以理解为从CPU传递到GPU辅助着色的变量均可视为是渲染状态(这里不包含待渲染数据本身)。
(2)配置渲染管线流程的参数和设置。常见的渲染状态包括:
渲染目标(Render Targets):指定渲染结果的输出目标,可以是帧缓冲、纹理或渲染缓冲等。
混合模式(Blending Modes):控制颜色的混合方式,用于实现透明度和混合效果。
深度测试(Depth Testing):用于确定像素的深度值,以决定是否进行深度写入和深度测试。
模板测试(Stencil Testing):根据模板缓冲中的模板值,决定是否进行模板写入和模板测试。
视口:定义渲染结果在屏幕上的位置和大小。
调用Draw Call:CPU调用图形编程接口,命令GPU进行渲染。Draw Call命令仅仅会指向一个需要被渲染的图元列表,而不包含任何材质信息,因为这些信息已经在上一个阶段中完成。执行DrawCall后GPU就会按照渲染流水线进行渲染计算,并输出到显示设备中,所执行的操作便是下述GPU渲染管线的内容。
DrawCall实际上指的是一次图形渲染接口的调用,比如OpenGL的glDrawArrays或者glDrawElements的一次调用,以及DirectX的DrawPrimitive或者DrawIndexedPrimitive。
在上述CPU与GPU的通信中,提供了一个命令缓冲区以进行CPU与GPU的并行操作。该命令缓冲区由CPU添加,GPU读取,添加和读取相互独立。如Unity中的CommandBuffer便是一个典型的命令缓冲区。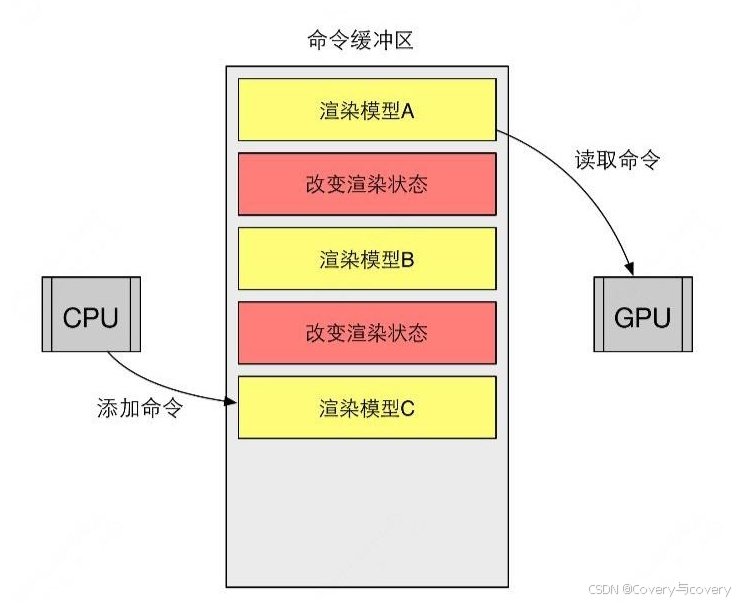
2.2 几何阶段
该过程包含顶点着色器、曲面细分着色器和几何着色器和裁剪与屏幕映射等阶段。
顶点着色器:用于对输入的顶点信息进行处理,包含顶点坐标变换(非常重要,可见博客)、顶点法向量变换,顶点颜色采样(直接从顶点颜色信息数组或纹理中获取)等操作。
曲面细分着色器:可选的着色器,用于细分图元。
曲面细分着色器是一个概述的概念,实际上包含三个阶段:(1)The Tessellation Control Shader (TCS);(2)The Tessellation Primitive Generator;(3)The Tessellation Evaluation Shader (TES)。TCS对应DX的Hull Shader,TES对应DX的domain Shader。The tessellation primitive generator是不可编程的固定方法,只有TES激活的状态下,才会执行。主要用来创建点。这里的创建点只是生成点的uv坐标。
几何着色器:根据现有的几何图元(点、线、三角形等)生成新的几何图元,同时也可以销毁现有的图元。这使得几何着色器可以实现几何图元的细分、几何的放大缩小、草地生成、粒子系统等各种复杂的效果。
裁剪和屏幕映射:裁剪将视锥体外的图元剔除,以优化渲染效率。对于部分在视锥体外,部分在视锥体外的图元则保存内部的部分。如下图所示,红色图元被剔除,绿色图元被完整保留,黄色图元新增了两个顶点,并和原始的顶点组成了新的图元。
然后将所有经过裁剪的顶点进行屏幕映射,从标准设备坐标系转换到屏幕坐标系中。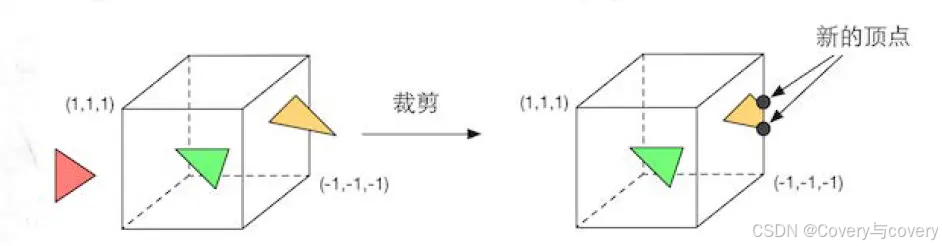
2.3 光栅化阶段
光栅化阶段是将顶点组装成图元,然后将图元光栅化为片元,并对片元进行着色、可见性测试、颜色混合等一系列过程的总和。狭义的光栅化仅指将图元光栅化为片元的过程。其中片元着色器前的操作,通常由GPU自动完成,用户主要是控制片元着色的方式,及选择逐片元操作的测试。
2.3.1 图元装配
将几何阶段输出的顶点和索引信息,组成成点、线、面等图元的过程。此过程在部分资料中被称为三角形设置。
2.3.2 三角形遍历
检查哪些像素被图元(主要是三角形图元)所覆盖,如果覆盖则利用三角形的顶点进行颜色,法线,深度等的插值,并输出包含以上信息和位置信息的片元。因此,片元并不等于像素,而是包含诸多数据的集合,并利用这些数据最终计算出像素的颜色。
如果对每个像素对判断是否位于三角形内,那如果图像的长款是w l,三角形片元的数量是n,总的计算徐需要wln。消耗较大。
如果对每个三角形判断其包含的像素。如果依然逐像素判断,那计算量和上面相同。其他做法:(1)先判断三角形包围盒,仅仅判断包围盒内的顶点。其他做法(2)扫描线法,使用一系列平行的,间隔为1像素,平行于图像x轴或y轴的射线穿过三角形,如果某条射线与三角形的三条边如果生成了两个交点,则交点内的点位于三角形内部。射线的范围通常限定在包围盒内。
但单线程的角度来看(2)的效率好于(1)好于逐三角形逐像素判断的方法。但从多线程的角度看逐像素逐三角形可以轻松实现完全的并行化,而(1)和(2)的输入是单个三角形,而输出是多个片元,逻辑上是三角形层次上的并行化。因此这几种方法的效率与实际场景相关了。
实际GPU硬件的做法:Coarse Raster(N卡称为Z Cull)。8x8x、4x4个像素作为一个单位进行一次光栅化,同时通过低分辨率的的Z-Buffer将被遮挡的块整块剔除。然后通过Z Cull的块会送到下一个阶段做fine Raster。
2.3.3 片元着色器
利用片元数据、光照信息、相机信息、贴图信息等,利用各种逼真的光照模型计算出片元颜色的过程。常见的光照模型包括BlinnPhong,PBR等。
2.3.4 逐片元操作
该过程在DirectX中该过程也被称为输出合并阶段。该阶段的主要目的是:(1)通过各种测试,决定每个片元的可见性;(2)与片元颜色与颜色缓冲区颜色进行混合。OpenGL给出了详细的逐片元着色流程如下图所示,其中蓝色的过程是比较常见的操作。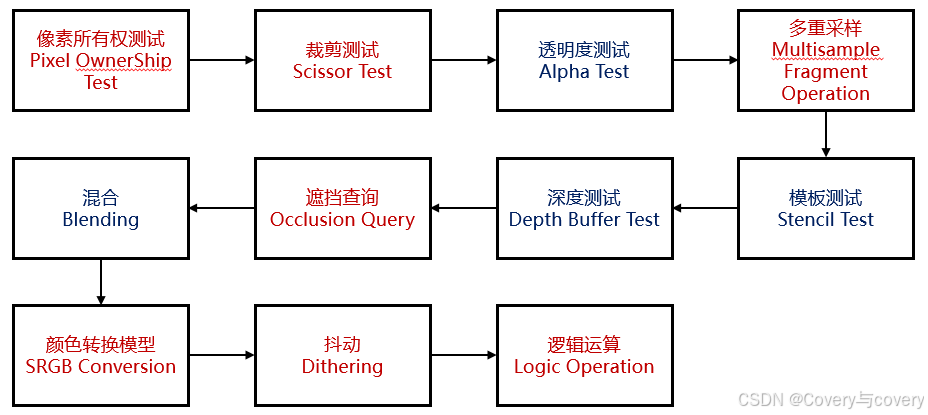
透明度测试
透明度测试用于区分透明和不透名物体。Alpha测试中,小于透明度(α)阈值的片元全部当作透明舍弃,满足条件的则当作不透明物体正常渲染。
多重采样
图形是图元组成的连续数据,而图像是像素组成的离散数据,因此图形的形状与显示像素块的形状一定存在区别。特别地,在上述的渲染流程中,当片元中心点位于某一图形内部时,该点颜色使用该图形特性进行渲染,同时片元的颜色完全等于片元中心点的颜色。当图形边缘穿过的片元块的中心点反复在图形的内部和外部跳变时(普遍现象),将呈现出明显的错误锯齿,如下所示。
为了减少锯齿,可以采用图像后处理(平滑,过滤);SSAA; MSAA等方法。
图像后处理通常对所有的像素进行计算和更新像素值,尽管对边缘的锯齿进行了平滑,但是对不需要处理的像素也会造成轻微的效果变化。优化:设置阈值进行操作?怎么判断阈值?
超级采样抗锯齿(Super Sample Anti-Aliasing, SSAA)使用N倍的屏幕分辨率大小的后台缓冲区和深度缓冲区,当数据要从后台缓冲区调往屏幕显示时,会将后台缓冲区按照N个子像素一组进行平均值计算作为屏幕像素的颜色值。该方法原理简单,效果好,但内(显)存消耗增加,同时渲染效率下降严重。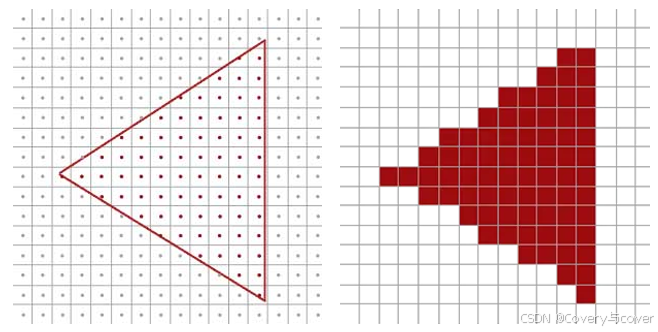
多重采样抗锯齿(Multi-Sample Anti-Aliasing, MSAA)
同样使用N倍的屏幕分辨率大小的后台缓冲区和深度缓冲区,但只需要计算1倍屏幕分辨率的像素颜色,然后降采样将每个像素分成N个子像素,根据子像素的覆盖性确定子像素的颜色,当数据要从后台缓冲区调往屏幕显示时,会将后台缓冲区按照4个像素一组进行平均值计算作为屏幕像素的颜色值。(只需要计算1倍屏幕分辨率的像素颜色)。MSAA 虽然相比 SSAA 提高了性能,但是存储占用与 SSAA 相同。
这里更加专业的解释可以见Games101的课程,闫令琪老师从数学的角度(频域)解释了多重采样的有效性。
深度测试
对当前片元的深度和深度缓冲区中对应位置的深度进行比较,如果通过测试,则进行稍后的处理,否则直接抛弃。可以选择是否将通过测试的深度写入到深度缓冲区中。深度比较的通过标准允许用户控制,如大于,小于,等于或其他。
模板测试
通过与模板缓冲区(Stencil Buffer)中的值进行比较来决定片元是否通过测试,如果通过测试,则进行稍后的处理,否则直接抛弃。通过测试后,可以计算新的模板值,并写入到模板缓冲区中。模板测试与深度测试类似,只是比较的对象换成了模板缓冲区。如Unity Shader中的ColorMask模式。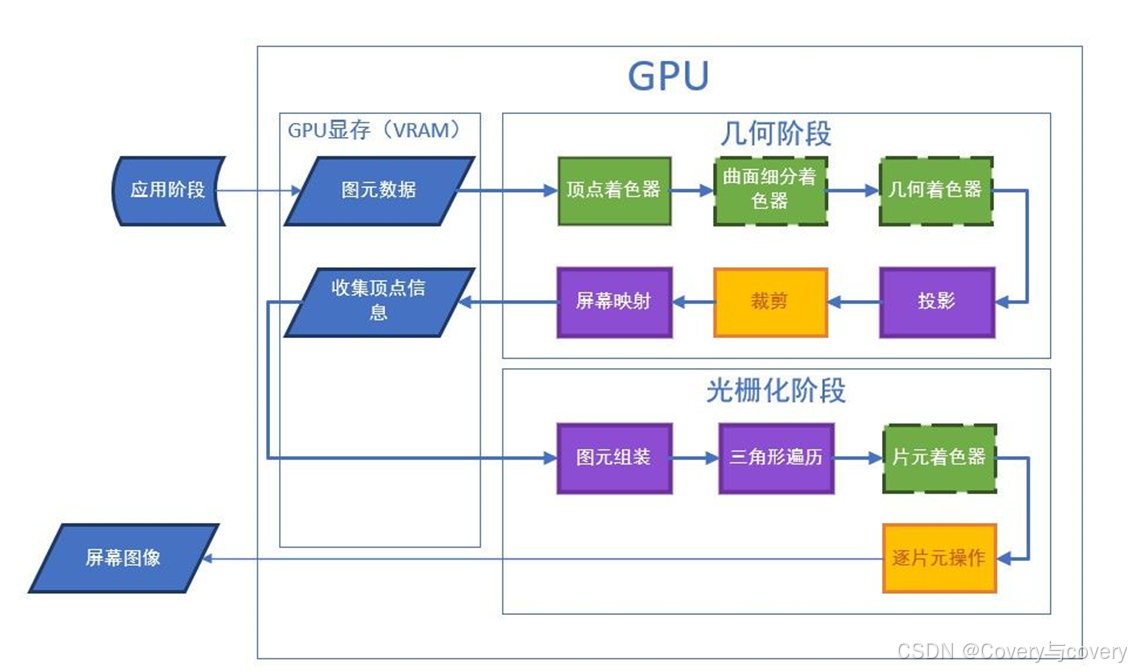
4 传统渲染管线的缺点与改进策略
这里简述一些常见的缺点和优化方法,但所有的优化方法都需要与用户场景和特点和需求相匹配。
4.1 不合理的DrawCall,导致帧率降低
每次DrawCall前,需要切换渲染状态。切换渲染状态是相对是比较费时的过程。而GPU操作往往是很快的,这就导致GPU已经完成了计算,而CPU还在准备渲染状态,这将导致帧率降低。
为了解决这一问题,需要降低DrawCall的频率,一般采用合批的操作。合批将具有相同渲染状态的渲染对象组成一个对象,一次drawCall完成绘制,如Unity中的静态合批。
4.2 OverDraw
在GPU渲染过程中,片元着色这一过程往往占据了较多的时间。传统渲染管线在在完成着色后,再进行深度比较,大部分片元将在这一过程被抛弃,即浪费了大部分时间在渲染无关片元上。
Early Z:将深度测试提前到片元着色前。该方法可以起到一定的效果,但如果多个渲染物体的深度是从远到近时,完全无法起到加速的效果。
Z PrePass:采用两个Pass进行渲染。这里每个Pass都经过一次完整的渲染过程。第一个Pass,仅写入深度,不进行颜色计算。第二个Pass中,关闭深度写入,并且将深度比较函数设置为相等,计算颜色。这个方法的问题是:顶点到光栅化这一过程重复,浪费。
延迟渲染:与Z PrePass类似,均是先确定渲染到屏幕上的像素,再使用像素去做光照。该技术将渲染分为两个过程,第一个过程除进行深度写入,同时将坐标、法线、贴图等信息存到缓存中(称为GBuffer)。在第二个Pass中,只需逐像素采样获得对应的几何信息,结合光照信息进行光照渲染。
该方法对于多光源的渲染非常友好,缺点是对MSAA支持不友好、透明物体渲染存在问题、占用大量的显存宽带。
4.3 多光源的渲染消耗
当存在多个光源时,往往需要每个物体进行逐光源的渲染,其中存在巨大的渲染开销。可以考虑采用以下的方式进行优化。
1 在顶点着色和片元着色之间进行切换
在顶点着色模式中,在顶点着色器阶段逐顶点、逐光源进行光照模型渲染,然后保存渲染结果。渲染结果在片元着色前,会自动进行插值并保存到片元的信息中,着色器阶段可以直接取出该颜色作为颜色输出。在片元着色模式中,仍然是在片元着色器阶段进行光照模型的渲染。
当顶点数较多,而待渲染片元较少时,为加速效率可以采用片元着色。当顶点数较少,而待渲染片元较多时,为加速效率可以采用顶点着色。通常情况下片元着色的效果好于顶点着色。
2 过滤光源
对于点光源或聚光灯,其有效辐照的范围有限,可以在CPU中进行处理,提前对物体进行光源的过滤。
3 延迟渲染
延迟渲染可以避免大量不必要的片元光照计算,特别适合多光源的渲染。该方法也常与Light Volume结合,进一步加速渲染。
4.4 渲染物体数量巨大时,如何加速
该方法一般采用(1)视锥体剔除;(2)遮挡剔除;(3)LOD(Level of Degree)。
视锥剔除是将相机视锥体外的物体进行过滤,传统方法在CPU端进行,通过比较物体包围盒与视锥体之间的位置进行滤除。但物体的形状本身并非是标准的长方体,因此这样的滤除并不彻底。即(1)被过滤的物体一定位于视锥体外;(2)未被过滤的物体可能位于视锥体外,也可能位于视锥体内。而如果采用精细的过滤,即对物体的每个网格进行过滤,则CPU端往往难以承担这样的开销。可以考虑采用BVH,BSP树等将物体划分为多个子物体,可以加强过滤效果,但问题在于仍会大大增加CPU端的计算。
遮挡剔除是将在视锥体内,但被其他物体完全遮挡的物体进行过滤。显然包围盒过滤方法在该情况下错误率极高,无法使用进行过滤,精细过滤(逐网格)的方法效率较视锥体剔除更大,因此更难在CPU端进行。可以考虑BVH,BSP树等划分后逐子物体进行逐网格进行过滤。当然对于CPU的压力还是巨大。
更为先进的方法采样GPU-Driven-Pipeline的过滤方法,该方法通过compute shader在GPU上进行视锥剔除和遮挡剔除。
LOD的方法是考虑到距离相机较远的物体,可以减少其分辨率。当其在画面中所占的比例过小时,可以省略该物体的绘制。因此可以在渲染前,对待渲染物体进行划分,分层,即一个物体对应多个不同分辨率的物体。然后在渲染时根据物体与相机的距离,选择使用不同层的物体进行渲染。
Unity中采用网格合并的操作进行分层,如第0层是原始的网格,第一层是对第0层网格进行合并后的结果,以此类推。
而在UE在合并时采用了更加复杂的操作,基于面片构成组,组构成簇,对簇进行减面操作
这里简述下操作:(1)首先将网格分成不同的组,再每每将几个组结合成簇,对簇进行锁边,然后在簇内进行减面操作。不断重复该操作。同时在该过程中通过上下层的对应关系,将簇组合成BVH树,以便进行LOD的选择和后续的过滤。
UE5的Nanite技术可以说是解决上述问题的集大成之作,支持在多光源情况下快速渲染千万面片级别的场景。
该方法采用了BVH搭建LOD,然后使用GPU-Driven-Pipiline技术加速过滤。通过将延迟渲染的Gbuffer升级成Visibility Buffer进一步降低了GBuffer的内存消耗问题和由于可见性和着色不完美分离导致的渲染浪费问题。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐


 36
36 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)