
【Hackathon 4th AIGC】当中国水墨山水遇上AIGC
飞桨黑客松第四期 No.105:基于PaddleNLP PPDiffusers 训练 AIGC 趣味模型 Gradio应用
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
【PaddlePaddle Hackathon 第四期】No.105 作品提交
活动链接 👉 No.105:基于PaddleNLP PPDiffusers 训练 AIGC 趣味模型
【队名】:megemini
【模型简介】:当中国水墨山水遇上AIGC
【模型链接】:Hugging Face 地址:
- 模型 👉 megemini/shanshui_style 可以生成水墨山水画。
- 模型 👉 megemini/shanshui_gen_style 可以生成水墨山水画的具像图片。
【AI Studio 项目】:👉 【Hackathon 4th AIGC】当中国水墨山水遇上AIGC
【AI Studio 应用中心】:👉 ☯ 当中国水墨山水遇上AIGC ☯
【Hugging Face 应用中心】:👉 megemini/shanshui
✨ 创意简介&效果展示 ✨
中国水墨山水画算的上中国文化的瑰宝,AIGC这么火,碰巧有个亲属 👉 亦石 画得一手好山水,那么就来看看模型学的如何,画得可有意境 。・:*˚:✧。
这里有两个模型,利用 Textual Inversion 学习 style,预训练模型为 runwayml/stable-diffusion-v1-5 :
megemini/shanshui_style可以生成水墨山水画。megemini/shanshui_gen_style可以生成水墨山水画的具像图片。
| Image | model | prompt |
|---|---|---|
 |
megemini/shanshui_style | A fantasy landscape in <shanshui-style> |
 |
megemini/shanshui_style | A fantasy landscape in <shanshui-style> |
 |
megemini/shanshui_style | A fantasy landscape in <shanshui-style> |
 |
megemini/shanshui_gen_style | A fantasy landscape in <shanshui-gen-style> |
 |
megemini/shanshui_gen_style | A fantasy landscape in <shanshui-gen-style> |
 |
megemini/shanshui_gen_style | A fantasy landscape in <shanshui-gen-style> |
AIGC虽然还有点问题,比如第一张图片上面的文字明显是乱画的~ 但是,这也比俺强啊 … … 😶🌫
另外,这里解释一下 megemini/shanshui_gen_style 这个模型的来历~
当时看到官方例子中的 StableDiffusionMegaPipeline 有个 img2img,出于好奇,就用水墨画(不是官方例子中的那种简笔画)作为输入,结果就是类似 megemini/shanshui_gen_style 风格的图片~
当时,确实是有点被震惊到,感觉很像是水墨画的一种具像,有种中西艺术揉合的样子,然后就用这些由水墨画生成的图片,又训练了一把 Textual Inversion 的 style,然后就有了 megemini/shanshui_gen_style。
这里看看当时我是被什么图片震撼到的(runwayml/stable-diffusion-v1-5 生成):
| 原画 | 生成(并用于此模型的训练) | prompt |
|---|---|---|
 |
 |
A fantasy landscape |
 |
 |
A fantasy landscape |
 |
 |
A fantasy landscape |
 |
 |
A fantasy landscape |
 |
 |
A fantasy landscape, trending on artstation |
都知道AIGC能够生成很不错的图片,可当自己亲手生成这种图片,感觉还是不一样的,希望您能有同感 ଘ(੭ˊᵕˋ)੭ ੈ♡‧₊˚
接下来,就看看怎么一步步训练这些模型,并生成图片。
🖍️ 水墨山水画 - shanshui_style 模型 🖍️
1. 模型训练
模型的训练需要具备几个方面:
数据
这里我将一些亲属的水墨画放到了
./train_shanshui/目录下面 (传播时要注明作者哦~),您也可以自己添加自己喜欢的画作。





工具
这里用的是 Textual Inversion,
paddlenlp封装了train_textual_inversion.py可以很方便的调用。方法
这里学习的是
style,也就是利用模型学习水墨山水画的风格。预训练模型
这里用的是
runwayml/stable-diffusion-v1-5
万事具备,只需一行命令就可以训练模型了 ~ 训练之前记得要安装必要的包 ~
%%capture
# 安装好之后要重启此 notebook
!pip install "paddlenlp>=2.5.2" safetensors "ppdiffusers>=0.11.1" --user
# 训练模型
!python -u train_textual_inversion.py \
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5" \
--train_data_dir="train_shanshui" \
--learnable_property="style" \
--placeholder_token="<shanshui-style>" --initializer_token="style" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=1000 \
--learning_rate=5.0e-04 \
--scale_lr \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--seed 2023 \
--output_dir="shanshui_style"
/opt/conda/envs/python35-paddle120-env/lib/python3.9/site-packages/sklearn/utils/multiclass.py:14: DeprecationWarning: Please use `spmatrix` from the `scipy.sparse` namespace, the `scipy.sparse.base` namespace is deprecated.
from scipy.sparse.base import spmatrix
[32m[2023-05-06 14:57:05,895] [ INFO][0m - Downloading tokenizer_config.json from https://bj.bcebos.com/paddlenlp/models/community/runwayml/stable-diffusion-v1-5/tokenizer/tokenizer_config.json[0m
100%|███████████████████████████████████████████| 312/312 [00:00<00:00, 227kB/s]
[32m[2023-05-06 14:57:05,987] [ INFO][0m - We are using <class 'paddlenlp.transformers.clip.tokenizer.CLIPTokenizer'> to load 'runwayml/stable-diffusion-v1-5/tokenizer'.[0m
[32m[2023-05-06 14:57:05,987] [ INFO][0m - Downloading https://bj.bcebos.com/paddlenlp/models/community/runwayml/stable-diffusion-v1-5/tokenizer/vocab.json and saved to /home/aistudio/.paddlenlp/models/runwayml/stable-diffusion-v1-5/tokenizer[0m
[32m[2023-05-06 14:57:06,542] [ INFO][0m - Downloading vocab.json from https://bj.bcebos.com/paddlenlp/models/community/runwayml/stable-diffusion-v1-5/tokenizer/vocab.json[0m
100%|████████████████████████████████████████| 842k/842k [00:00<00:00, 32.2MB/s]
[32m[2023-05-06 14:57:06,671] [ INFO][0m - Downloading https://bj.bcebos.com/paddlenlp/models/community/runwayml/stable-diffusion-v1-5/tokenizer/merges.txt and saved to /home/aistudio/.paddlenlp/models/runwayml/stable-diffusion-v1-5/tokenizer[0m
[32m[2023-05-06 14:57:06,708] [ INFO][0m - Downloading merges.txt from https://bj.bcebos.com/paddlenlp/models/community/runwayml/stable-diffusion-v1-5/tokenizer/merges.txt[0m
100%|████████████████████████████████████████| 512k/512k [00:00<00:00, 32.8MB/s]
[32m[2023-05-06 14:57:06,911] [ INFO][0m - Downloading https://bj.bcebos.com/paddlenlp/models/community/runwayml/stable-diffusion-v1-5/tokenizer/added_tokens.json and saved to /home/aistudio/.paddlenlp/models/runwayml/stable-diffusion-v1-5/tokenizer[0m
[32m[2023-05-06 14:57:07,006] [ INFO][0m - Downloading added_tokens.json from https://bj.bcebos.com/paddlenlp/models/community/runwayml/stable-diffusion-v1-5/tokenizer/added_tokens.json[0m
100%|████████████████████████████████████████| 2.00/2.00 [00:00<00:00, 1.83kB/s]
[32m[2023-05-06 14:57:07,079] [ INFO][0m - Downloading https://bj.bcebos.com/paddlenlp/models/community/runwayml/stable-diffusion-v1-5/tokenizer/special_tokens_map.json and saved to /home/aistudio/.paddlenlp/models/runwayml/stable-diffusion-v1-5/tokenizer[0m
[32m[2023-05-06 14:57:07,121] [ INFO][0m - Downloading special_tokens_map.json from https://bj.bcebos.com/paddlenlp/models/community/runwayml/stable-diffusion-v1-5/tokenizer/special_tokens_map.json[0m
100%|███████████████████████████████████████████| 478/478 [00:00<00:00, 331kB/s]
[32m[2023-05-06 14:57:07,167] [ INFO][0m - Already cached /home/aistudio/.paddlenlp/models/runwayml/stable-diffusion-v1-5/tokenizer/tokenizer_config.json[0m
Downloading (…)cheduler_config.json: 100%|█████| 342/342 [00:00<00:00, 50.0kB/s]
W0506 14:57:07.386356 16163 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0506 14:57:07.389185 16163 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[32m[2023-05-06 14:57:08,854] [ INFO][0m - Adding <shanshui-style> to the vocabulary[0m
[32m[2023-05-06 14:57:08,889] [ INFO][0m - Downloading config.json from https://bj.bcebos.com/paddlenlp/models/community/runwayml/stable-diffusion-v1-5/text_encoder/config.json[0m
100%|███████████████████████████████████████████| 592/592 [00:00<00:00, 532kB/s]
[32m[2023-05-06 14:57:08,959] [ INFO][0m - loading configuration file /home/aistudio/.paddlenlp/models/runwayml/stable-diffusion-v1-5/text_encoder/config.json[0m
[33m[2023-05-06 14:57:08,959] [ WARNING][0m - You are using a model of type clip_text_model to instantiate a model of type . This is not supported for all configurations of models and can yield errors.[0m
[32m[2023-05-06 14:57:08,960] [ INFO][0m - Model config PretrainedConfig {
"_name_or_path": "openai/clip-vit-large-patch14",
"architectures": [
"CLIPTextModel"
],
"attention_dropout": 0.0,
"bos_token_id": 0,
"dropout": 0.0,
"eos_token_id": 2,
"hidden_act": "quick_gelu",
"hidden_size": 768,
"initializer_factor": 1.0,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 77,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"paddlenlp_version": null,
"torch_dtype": "float32",
"transformers_version": "4.21.0.dev0",
"vocab_size": 49408
}
[0m
[32m[2023-05-06 14:57:09,000] [ INFO][0m - Downloading config.json from https://bj.bcebos.com/paddlenlp/models/community/runwayml/stable-diffusion-v1-5/text_encoder/config.json[0m
100%|███████████████████████████████████████████| 592/592 [00:00<00:00, 675kB/s]
[32m[2023-05-06 14:57:09,050] [ INFO][0m - loading configuration file /home/aistudio/.cache/paddlenlp/ppdiffusers/runwayml/stable-diffusion-v1-5/text_encoder/config.json[0m
[32m[2023-05-06 14:57:09,051] [ INFO][0m - Model config CLIPTextConfig {
"_name_or_path": "openai/clip-vit-large-patch14",
"architectures": [
"CLIPTextModel"
],
"attention_dropout": 0.0,
"bos_token_id": 0,
"dropout": 0.0,
"eos_token_id": 2,
"hidden_act": "quick_gelu",
"hidden_size": 768,
"initializer_factor": 1.0,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 77,
"model_type": "clip_text_model",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"paddlenlp_version": null,
"projection_dim": 512,
"return_dict": true,
"torch_dtype": "float32",
"transformers_version": "4.21.0.dev0",
"vocab_size": 49408
}
[0m
Downloading (…)model_state.pdparams: 100%|████| 492M/492M [00:03<00:00, 126MB/s]
Downloading (…)v1-5/vae/config.json: 100%|██████| 610/610 [00:00<00:00, 246kB/s]
Downloading (…)model_state.pdparams: 100%|████| 335M/335M [00:02<00:00, 127MB/s]
Downloading (…)1-5/unet/config.json: 100%|██████| 807/807 [00:00<00:00, 318kB/s]
Downloading (…)model_state.pdparams: 100%|██| 3.44G/3.44G [00:27<00:00, 126MB/s]
[32m[2023-05-06 14:57:52,806] [ INFO][0m - ----------- Configuration Arguments -----------[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - adam_beta1: 0.9[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - adam_beta2: 0.999[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - adam_epsilon: 1e-08[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - adam_weight_decay: 0.01[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - center_crop: False[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - dataloader_num_workers: 0[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - enable_xformers_memory_efficient_attention: False[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - gradient_accumulation_steps: 4[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - gradient_checkpointing: False[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - height: 512[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - hub_model_id: None[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - hub_token: None[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - initializer_token: style[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - language: en[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - learnable_property: style[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - learning_rate: 0.002[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - logging_dir: shanshui_style/logs[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - lr_num_cycles: 1[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - lr_power: 1.0[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - lr_scheduler: constant[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - lr_warmup_steps: 0[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - max_grad_norm: -1[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - max_train_steps: 1000[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - num_train_epochs: 2[0m
[32m[2023-05-06 14:57:52,807] [ INFO][0m - num_validation_images: 4[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - only_save_embeds: False[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - output_dir: shanshui_style[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - placeholder_token: <shanshui-style>[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - pretrained_model_name_or_path: runwayml/stable-diffusion-v1-5[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - push_to_hub: False[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - repeats: 100[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - report_to: visualdl[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - resolution: 512[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - save_steps: 500[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - scale_lr: True[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - seed: 2023[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - tokenizer_name: None[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - train_batch_size: 1[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - train_data_dir: train_shanshui[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - validation_epochs: 50[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - validation_prompt: None[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - width: 512[0m
[32m[2023-05-06 14:57:52,808] [ INFO][0m - ------------------------------------------------[0m
[32m[2023-05-06 14:57:52,933] [ INFO][0m - ***** Running training *****[0m
[32m[2023-05-06 14:57:52,933] [ INFO][0m - Num examples = 2300[0m
[32m[2023-05-06 14:57:52,933] [ INFO][0m - Num batches each epoch = 2300[0m
[32m[2023-05-06 14:57:52,933] [ INFO][0m - Num Epochs = 2[0m
[32m[2023-05-06 14:57:52,933] [ INFO][0m - Instantaneous batch size per device = 1[0m
[32m[2023-05-06 14:57:52,933] [ INFO][0m - Total train batch size (w. parallel, distributed & accumulation) = 4[0m
[32m[2023-05-06 14:57:52,933] [ INFO][0m - Gradient Accumulation steps = 4[0m
[32m[2023-05-06 14:57:52,933] [ INFO][0m - Total optimization steps = 1000[0m
Train Steps: 50%|▌| 500/1000 [09:37<09:40, 1.16s/it, epoch=0000, lr=0.002, ste[32m[2023-05-06 15:07:30,439] [ INFO][0m - Saving embeddings[0m
Train Steps: 100%|█| 1000/1000 [19:14<00:00, 1.15s/it, epoch=0001, lr=0.002, st[32m[2023-05-06 15:17:07,914] [ INFO][0m - Saving embeddings[0m
Downloading (…)1-5/model_index.json: 100%|█████| 601/601 [00:00<00:00, 70.2kB/s][A
Fetching 10 files: 0%| | 0/10 [00:00<?, ?it/s][A
Downloading (…)rocessor_config.json: 100%|█████| 342/342 [00:00<00:00, 49.1kB/s][A[A
Fetching 10 files: 20%|█████ | 2/10 [00:00<00:00, 18.71it/s][A
Downloading (…)model_state.pdparams: 0%| | 0.00/1.22G [00:00<?, ?B/s][A[A
Downloading (…)model_state.pdparams: 1%| | 10.5M/1.22G [00:00<00:14, 83.3MB/s][A[A
Downloading (…)model_state.pdparams: 3%| | 31.5M/1.22G [00:00<00:09, 123MB/s][A[A
Downloading (…)model_state.pdparams: 4%| | 52.4M/1.22G [00:00<00:09, 120MB/s][A[A
Downloading (…)model_state.pdparams: 6%| | 73.4M/1.22G [00:00<00:11, 102MB/s][A[A
Downloading (…)model_state.pdparams: 8%| | 94.4M/1.22G [00:00<00:11, 95.8MB/s][A[A
Downloading (…)model_state.pdparams: 9%|▏ | 105M/1.22G [00:01<00:11, 94.3MB/s][A[A
Downloading (…)model_state.pdparams: 10%|▎ | 126M/1.22G [00:01<00:10, 104MB/s][A[A
Downloading (…)model_state.pdparams: 12%|▎ | 147M/1.22G [00:01<00:09, 110MB/s][A[A
Downloading (…)model_state.pdparams: 14%|▍ | 168M/1.22G [00:01<00:09, 107MB/s][A[A
Downloading (…)model_state.pdparams: 16%|▍ | 189M/1.22G [00:01<00:09, 107MB/s][A[A
Downloading (…)model_state.pdparams: 17%|▎ | 210M/1.22G [00:02<00:10, 97.6MB/s][A[A
Downloading (…)model_state.pdparams: 18%|▎ | 220M/1.22G [00:02<00:11, 83.5MB/s][A[A
Downloading (…)model_state.pdparams: 20%|▍ | 241M/1.22G [00:02<00:10, 89.9MB/s][A[A
Downloading (…)model_state.pdparams: 22%|▍ | 262M/1.22G [00:02<00:10, 88.7MB/s][A[A
Downloading (…)model_state.pdparams: 23%|▍ | 283M/1.22G [00:02<00:09, 93.6MB/s][A[A
Downloading (…)model_state.pdparams: 25%|▌ | 304M/1.22G [00:03<00:10, 90.8MB/s][A[A
Downloading (…)model_state.pdparams: 27%|▌ | 325M/1.22G [00:03<00:09, 97.4MB/s][A[A
Downloading (…)model_state.pdparams: 28%|▊ | 346M/1.22G [00:03<00:08, 101MB/s][A[A
Downloading (…)model_state.pdparams: 30%|▉ | 367M/1.22G [00:03<00:08, 102MB/s][A[A
Downloading (…)model_state.pdparams: 32%|▉ | 388M/1.22G [00:03<00:07, 104MB/s][A[A
Downloading (…)model_state.pdparams: 34%|█ | 409M/1.22G [00:04<00:07, 108MB/s][A[A
Downloading (…)model_state.pdparams: 35%|█ | 430M/1.22G [00:04<00:06, 113MB/s][A[A
Downloading (…)model_state.pdparams: 37%|▋ | 451M/1.22G [00:04<00:08, 92.3MB/s][A[A
Downloading (…)model_state.pdparams: 39%|▊ | 472M/1.22G [00:04<00:07, 97.4MB/s][A[A
Downloading (…)model_state.pdparams: 41%|▊ | 493M/1.22G [00:05<00:08, 88.5MB/s][A[A
Downloading (…)model_state.pdparams: 41%|▊ | 503M/1.22G [00:05<00:08, 87.2MB/s][A[A
Downloading (…)model_state.pdparams: 42%|▊ | 514M/1.22G [00:05<00:07, 88.5MB/s][A[A
Downloading (…)model_state.pdparams: 44%|▉ | 535M/1.22G [00:05<00:07, 90.4MB/s][A[A
Downloading (…)model_state.pdparams: 46%|█▎ | 556M/1.22G [00:05<00:06, 100MB/s][A[A
Downloading (…)model_state.pdparams: 47%|█▍ | 577M/1.22G [00:05<00:06, 102MB/s][A[A
Downloading (…)model_state.pdparams: 49%|█▍ | 598M/1.22G [00:06<00:05, 110MB/s][A[A
Downloading (…)model_state.pdparams: 51%|█▌ | 619M/1.22G [00:06<00:05, 100MB/s][A[A
Downloading (…)model_state.pdparams: 52%|█ | 629M/1.22G [00:06<00:06, 96.4MB/s][A[A
Downloading (…)model_state.pdparams: 53%|█ | 640M/1.22G [00:06<00:05, 96.4MB/s][A[A
Downloading (…)model_state.pdparams: 54%|█ | 661M/1.22G [00:06<00:05, 92.6MB/s][A[A
Downloading (…)model_state.pdparams: 55%|█ | 671M/1.22G [00:06<00:06, 87.8MB/s][A[A
Downloading (…)model_state.pdparams: 57%|█▏| 692M/1.22G [00:07<00:05, 92.3MB/s][A[A
Downloading (…)model_state.pdparams: 58%|█▏| 703M/1.22G [00:07<00:06, 81.9MB/s][A[A
Downloading (…)model_state.pdparams: 60%|█▏| 724M/1.22G [00:07<00:05, 82.2MB/s][A[A
Downloading (…)model_state.pdparams: 60%|█▏| 734M/1.22G [00:07<00:05, 81.7MB/s][A[A
Downloading (…)model_state.pdparams: 61%|█▏| 744M/1.22G [00:07<00:05, 81.6MB/s][A[A
Downloading (…)model_state.pdparams: 63%|█▎| 765M/1.22G [00:08<00:05, 88.1MB/s][A[A
Downloading (…)model_state.pdparams: 65%|█▎| 786M/1.22G [00:08<00:04, 98.2MB/s][A[A
Downloading (…)model_state.pdparams: 66%|█▎| 797M/1.22G [00:08<00:04, 96.9MB/s][A[A
Downloading (…)model_state.pdparams: 66%|█▎| 807M/1.22G [00:08<00:04, 92.5MB/s][A[A
Downloading (…)model_state.pdparams: 68%|█▎| 828M/1.22G [00:08<00:03, 99.6MB/s][A[A
Downloading (…)model_state.pdparams: 70%|█▍| 849M/1.22G [00:08<00:03, 96.1MB/s][A[A
Downloading (…)model_state.pdparams: 71%|█▍| 860M/1.22G [00:08<00:03, 96.9MB/s][A[A
Downloading (…)model_state.pdparams: 72%|█▍| 870M/1.22G [00:09<00:03, 89.5MB/s][A[A
Downloading (…)model_state.pdparams: 72%|█▍| 881M/1.22G [00:09<00:03, 91.7MB/s][A[A
Downloading (…)model_state.pdparams: 74%|█▍| 902M/1.22G [00:09<00:03, 98.3MB/s][A[A
Downloading (…)model_state.pdparams: 76%|██▎| 923M/1.22G [00:09<00:02, 104MB/s][A[A
Downloading (…)model_state.pdparams: 77%|█▌| 933M/1.22G [00:09<00:04, 65.4MB/s][A[A
Downloading (…)model_state.pdparams: 79%|█▌| 965M/1.22G [00:10<00:02, 94.7MB/s][A[A
Downloading (…)model_state.pdparams: 81%|█▌| 986M/1.22G [00:10<00:02, 94.8MB/s][A[A
Downloading (…)model_state.pdparams: 83%|▊| 1.01G/1.22G [00:10<00:02, 92.0MB/s][A[A
Downloading (…)model_state.pdparams: 85%|▊| 1.03G/1.22G [00:10<00:01, 99.1MB/s][A[A
Downloading (…)model_state.pdparams: 86%|▊| 1.05G/1.22G [00:10<00:01, 97.3MB/s][A[A
Downloading (…)model_state.pdparams: 88%|▉| 1.07G/1.22G [00:11<00:01, 93.1MB/s][A[A
Downloading (…)model_state.pdparams: 89%|▉| 1.08G/1.22G [00:11<00:01, 93.5MB/s][A[A
Downloading (…)model_state.pdparams: 91%|█▊| 1.10G/1.22G [00:11<00:01, 100MB/s][A[A
Downloading (…)model_state.pdparams: 92%|▉| 1.12G/1.22G [00:11<00:00, 95.1MB/s][A[A
Downloading (…)model_state.pdparams: 93%|▉| 1.13G/1.22G [00:12<00:01, 76.1MB/s][A[A
Downloading (…)model_state.pdparams: 96%|█▉| 1.16G/1.22G [00:12<00:00, 102MB/s][A[A
Downloading (…)model_state.pdparams: 97%|█▉| 1.18G/1.22G [00:12<00:00, 106MB/s][A[A
Downloading (…)model_state.pdparams: 100%|█| 1.22G/1.22G [00:12<00:00, 95.4MB/s][A[A
Downloading (…)_checker/config.json: 100%|██████| 553/553 [00:00<00:00, 188kB/s][A[A
Fetching 10 files: 40%|██████████ | 4/10 [00:13<00:23, 3.85s/it][A
Downloading (…)er/model_config.json: 100%|██████| 614/614 [00:00<00:00, 176kB/s][A[A
Fetching 10 files: 100%|████████████████████████| 10/10 [00:13<00:00, 1.32s/it]
[32m[2023-05-06 15:17:21,677] [ INFO][0m - loading configuration file /home/aistudio/.cache/paddlenlp/ppdiffusers/runwayml/stable-diffusion-v1-5/safety_checker/config.json[0m
[32m[2023-05-06 15:17:21,678] [ INFO][0m - Model config CLIPVisionConfig {
"architectures": [
"StableDiffusionSafetyChecker"
],
"attention_dropout": 0.0,
"dropout": 0.0,
"hidden_act": "quick_gelu",
"hidden_size": 1024,
"image_size": 224,
"initializer_factor": 1.0,
"initializer_range": 0.02,
"intermediate_size": 4096,
"layer_norm_eps": 1e-05,
"model_type": "clip_vision_model",
"num_attention_heads": 16,
"num_channels": 3,
"num_hidden_layers": 24,
"paddlenlp_version": null,
"patch_size": 14,
"projection_dim": 768,
"return_dict": true
}
[0m
[32m[2023-05-06 15:17:24,896] [ INFO][0m - loading configuration file /home/aistudio/.cache/paddlenlp/ppdiffusers/runwayml/stable-diffusion-v1-5/feature_extractor/preprocessor_config.json from cache at /home/aistudio/.cache/paddlenlp/ppdiffusers/runwayml/stable-diffusion-v1-5/feature_extractor/preprocessor_config.json[0m
[32m[2023-05-06 15:17:24,896] [ INFO][0m - size should be a dictionary on of the following set of keys: ({'width', 'height'}, {'shortest_edge'}, {'longest_edge', 'shortest_edge'}), got 224. Converted to {'shortest_edge': 224}.[0m
[32m[2023-05-06 15:17:24,896] [ INFO][0m - crop_size should be a dictionary on of the following set of keys: ({'width', 'height'}, {'shortest_edge'}, {'longest_edge', 'shortest_edge'}), got 224. Converted to {'height': 224, 'width': 224}.[0m
[32m[2023-05-06 15:17:24,897] [ INFO][0m - Image processor CLIPFeatureExtractor {
"crop_size": {
"height": 224,
"width": 224
},
"do_center_crop": true,
"do_convert_rgb": true,
"do_normalize": true,
"do_rescale": true,
"do_resize": true,
"feature_extractor_type": "CLIPFeatureExtractor",
"image_mean": [
0.48145466,
0.4578275,
0.40821073
],
"image_processor_type": "CLIPFeatureExtractor",
"image_std": [
0.26862954,
0.26130258,
0.27577711
],
"resample": 3,
"rescale_factor": 0.00392156862745098,
"size": {
"shortest_edge": 224
}
}
[0m
[32m[2023-05-06 15:17:32,510] [ INFO][0m - Configuration saved in shanshui_style/text_encoder/config.json[0m
[32m[2023-05-06 15:17:33,173] [ INFO][0m - tokenizer config file saved in shanshui_style/tokenizer/tokenizer_config.json[0m
[32m[2023-05-06 15:17:33,173] [ INFO][0m - Special tokens file saved in shanshui_style/tokenizer/special_tokens_map.json[0m
[32m[2023-05-06 15:17:33,174] [ INFO][0m - added tokens file saved in shanshui_style/tokenizer/added_tokens.json[0m
[32m[2023-05-06 15:17:39,729] [ INFO][0m - Configuration saved in shanshui_style/safety_checker/config.json[0m
[32m[2023-05-06 15:17:41,937] [ INFO][0m - Image processor saved in shanshui_style/feature_extractor/preprocessor_config.json[0m
[32m[2023-05-06 15:17:41,937] [ INFO][0m - Saving embeddings[0m
Train Steps: 100%|█| 1000/1000 [19:49<00:00, 1.19s/it, epoch=0001, lr=0.002, st
[0m
几个主要的参数:
–pretrained_model_name_or_path=“runwayml/stable-diffusion-v1-5” \ # 预训练模型
–train_data_dir=“train_shanshui” \ # 数据目录
–learnable_property=“style” \ # 学习 style
–placeholder_token=“<shanshui-style>” \ # prompt 中用来表示此 style 的 token
–initializer_token=“style” \ # 初始化 token
–resolution=512 \
–train_batch_size=1 \
–gradient_accumulation_steps=4 \
–max_train_steps=1000 \ # 训练步骤,有时间可以设置多一些
–learning_rate=5.0e-04 \
–scale_lr \
–lr_scheduler=“constant” \
–lr_warmup_steps=0 \
–seed 2023 \
–output_dir=“shanshui_style” # 模型保存的路径
2. 模型预测
模型预测利用 ppdiffusers 的 StableDiffusionPipeline,这里注意,要在 prompt 中加入上面 placeholder_token 设置的token <shanshui-style>。
另外,生成图片的分辨率越高,貌似生成的图片 *质量* 越好 ~
import matplotlib.pyplot as plt
%matplotlib inline
from ppdiffusers import StableDiffusionPipeline
# 我们所需加载的模型地址,这里我们输入了训练时候使用的 output_dir 地址
model_path = "shanshui_style"
pipe = StableDiffusionPipeline.from_pretrained(model_path)
prompt = "A fantasy landscape in <shanshui-style>"
image = pipe(prompt, num_inference_steps=100, guidance_scale=7.5, height=432, width=768,).images[0]
[2023-05-06 15:21:08,008] [ INFO] - loading configuration file shanshui_style/feature_extractor/preprocessor_config.json from cache at shanshui_style/feature_extractor/preprocessor_config.json
[2023-05-06 15:21:08,011] [ INFO] - Image processor CLIPFeatureExtractor {
"crop_size": {
"height": 224,
"width": 224
},
"do_center_crop": true,
"do_convert_rgb": true,
"do_normalize": true,
"do_rescale": true,
"do_resize": true,
"feature_extractor_type": "CLIPFeatureExtractor",
"image_mean": [
0.48145466,
0.4578275,
0.40821073
],
"image_processor_type": "CLIPFeatureExtractor",
"image_std": [
0.26862954,
0.26130258,
0.27577711
],
"resample": 3,
"rescale_factor": 0.00392156862745098,
"size": {
"shortest_edge": 224
}
}
[2023-05-06 15:21:08,013] [ INFO] - loading configuration file shanshui_style/safety_checker/config.json
[2023-05-06 15:21:08,015] [ INFO] - Model config CLIPVisionConfig {
"architectures": [
"StableDiffusionSafetyChecker"
],
"attention_dropout": 0.0,
"dropout": 0.0,
"dtype": "float32",
"hidden_act": "quick_gelu",
"hidden_size": 1024,
"image_size": 224,
"initializer_factor": 1.0,
"initializer_range": 0.02,
"intermediate_size": 4096,
"layer_norm_eps": 1e-05,
"model_type": "clip_vision_model",
"num_attention_heads": 16,
"num_channels": 3,
"num_hidden_layers": 24,
"paddlenlp_version": null,
"patch_size": 14,
"projection_dim": 768,
"return_dict": true
}
[2023-05-06 15:21:10,500] [ INFO] - loading configuration file shanshui_style/text_encoder/config.json
[2023-05-06 15:21:10,503] [ INFO] - Model config CLIPTextConfig {
"_name_or_path": "openai/clip-vit-large-patch14",
"architectures": [
"CLIPTextModel"
],
"attention_dropout": 0.0,
"bos_token_id": 0,
"dropout": 0.0,
"dtype": "float32",
"eos_token_id": 2,
"hidden_act": "quick_gelu",
"hidden_size": 768,
"initializer_factor": 1.0,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 77,
"model_type": "clip_text_model",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"paddlenlp_version": null,
"projection_dim": 512,
"return_dict": true,
"torch_dtype": "float32",
"transformers_version": "4.21.0.dev0",
"vocab_size": 49409
}
[2023-05-06 15:21:11,683] [ INFO] - Adding <shanshui-style> to the vocabulary
0%| | 0/100 [00:00<?, ?it/s]
plt.imshow(image)
<matplotlib.image.AxesImage at 0x7fd1203a91f0>
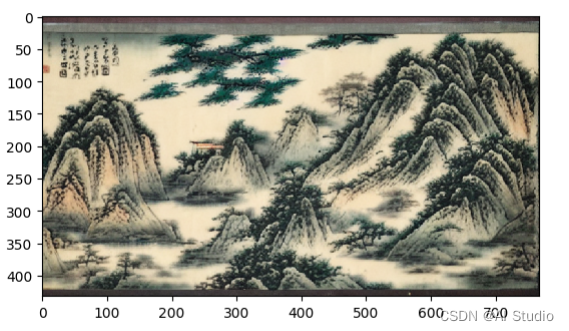
🖍️ 水墨山水画具像图 - shanshui_gen_style 模型 🖍️
1. 模型训练
同样,这里看看模型训练的几个要素:
数据
这里需要利用
Stable diffusion的img2img,将之前用到的水墨画先生成具像图,作为此模型的训练数据。





工具
同
shanshui_style,这里用的是 Textual Inversion,paddlenlp封装了train_textual_inversion.py可以很方便的调用。方法
同
shanshui_style,这里学习的是style,也就是利用模型学习水墨山水画具像之后的风格。预训练模型
同
shanshui_style,这里用的是runwayml/stable-diffusion-v1-5
这里单独介绍一下如何用 img2img 生成图片:
from stable_diffusion_mega import StableDiffusionMegaPipeline
import PIL
import paddle
pipe = StableDiffusionMegaPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", paddle_dtype=paddle.float16)
pipe.enable_attention_slicing()
generator = paddle.Generator().manual_seed(202305)
prompt = "A fantasy landscape"
init_image = PIL.Image.open("train_shanshui/mmexport1477788619881.jpg").convert("RGB")
with paddle.amp.auto_cast(True, level="O2"):
image = pipe.img2img(prompt=prompt,
image=init_image,
strength=0.75,
guidance_scale=7.5,
generator=generator).images[0]
Fetching 18 files: 0%| | 0/18 [00:00<?, ?it/s]
[2023-05-06 15:42:09,430] [ INFO] - loading configuration file /home/aistudio/.cache/paddlenlp/ppdiffusers/runwayml/stable-diffusion-v1-5/feature_extractor/preprocessor_config.json from cache at /home/aistudio/.cache/paddlenlp/ppdiffusers/runwayml/stable-diffusion-v1-5/feature_extractor/preprocessor_config.json
[2023-05-06 15:42:09,433] [ INFO] - size should be a dictionary on of the following set of keys: ({'width', 'height'}, {'shortest_edge'}, {'shortest_edge', 'longest_edge'}), got 224. Converted to {'shortest_edge': 224}.
[2023-05-06 15:42:09,435] [ INFO] - crop_size should be a dictionary on of the following set of keys: ({'width', 'height'}, {'shortest_edge'}, {'shortest_edge', 'longest_edge'}), got 224. Converted to {'height': 224, 'width': 224}.
[2023-05-06 15:42:09,437] [ INFO] - Image processor CLIPFeatureExtractor {
"crop_size": {
"height": 224,
"width": 224
},
"do_center_crop": true,
"do_convert_rgb": true,
"do_normalize": true,
"do_rescale": true,
"do_resize": true,
"feature_extractor_type": "CLIPFeatureExtractor",
"image_mean": [
0.48145466,
0.4578275,
0.40821073
],
"image_processor_type": "CLIPFeatureExtractor",
"image_std": [
0.26862954,
0.26130258,
0.27577711
],
"resample": 3,
"rescale_factor": 0.00392156862745098,
"size": {
"shortest_edge": 224
}
}
[2023-05-06 15:42:09,439] [ INFO] - loading configuration file /home/aistudio/.cache/paddlenlp/ppdiffusers/runwayml/stable-diffusion-v1-5/safety_checker/config.json
[2023-05-06 15:42:09,441] [ INFO] - Model config CLIPVisionConfig {
"architectures": [
"StableDiffusionSafetyChecker"
],
"attention_dropout": 0.0,
"dropout": 0.0,
"hidden_act": "quick_gelu",
"hidden_size": 1024,
"image_size": 224,
"initializer_factor": 1.0,
"initializer_range": 0.02,
"intermediate_size": 4096,
"layer_norm_eps": 1e-05,
"model_type": "clip_vision_model",
"num_attention_heads": 16,
"num_channels": 3,
"num_hidden_layers": 24,
"paddlenlp_version": null,
"patch_size": 14,
"projection_dim": 768,
"return_dict": true
}
[2023-05-06 15:42:12,238] [ INFO] - loading configuration file /home/aistudio/.cache/paddlenlp/ppdiffusers/runwayml/stable-diffusion-v1-5/text_encoder/config.json
[2023-05-06 15:42:12,242] [ INFO] - Model config CLIPTextConfig {
"_name_or_path": "openai/clip-vit-large-patch14",
"architectures": [
"CLIPTextModel"
],
"attention_dropout": 0.0,
"bos_token_id": 0,
"dropout": 0.0,
"eos_token_id": 2,
"hidden_act": "quick_gelu",
"hidden_size": 768,
"initializer_factor": 1.0,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 77,
"model_type": "clip_text_model",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"paddlenlp_version": null,
"projection_dim": 512,
"return_dict": true,
"torch_dtype": "float32",
"transformers_version": "4.21.0.dev0",
"vocab_size": 49408
}
0%| | 0/37 [00:00<?, ?it/s]
plt.figure(figsize=(16, 6))
plt.subplot(211)
plt.imshow(init_image)
plt.subplot(212)
plt.imshow(image)
<matplotlib.image.AxesImage at 0x7fd331dd6c70>
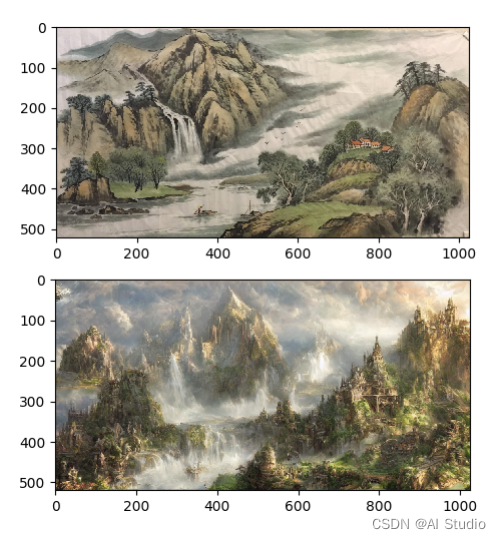
只需要将 ./train_shanshui/ 目录下面的图片通过上面的 img2img 方法生成具像图片,然后保存下来即可。
这里已经提前生成好了,保存在 ./train_shanshui_gen 目录下。
您可以直接使用,也可以换个 prompt 重新生成一下 ~
有了这些图片,就可以训练 shanshui_gen_style 模型了,方法跟 shanshui_style 一样 ~
!python -u train_textual_inversion.py \
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5" \
--train_data_dir="train_shanshui_gen" \
--learnable_property="style" \
--placeholder_token="<shanshui-gen-style>" --initializer_token="style" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=1000 \
--learning_rate=5.0e-04 \
--scale_lr \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--seed 2023 \
--output_dir="shanshui_gen_style"
/opt/conda/envs/python35-paddle120-env/lib/python3.9/site-packages/sklearn/utils/multiclass.py:14: DeprecationWarning: Please use `spmatrix` from the `scipy.sparse` namespace, the `scipy.sparse.base` namespace is deprecated.
from scipy.sparse.base import spmatrix
[2023-05-06 15:46:35,822] [ INFO] - Found /home/aistudio/.paddlenlp/models/runwayml/stable-diffusion-v1-5/tokenizer/tokenizer_config.json
[2023-05-06 15:46:35,822] [ INFO] - We are using <class 'paddlenlp.transformers.clip.tokenizer.CLIPTokenizer'> to load 'runwayml/stable-diffusion-v1-5/tokenizer'.
[2023-05-06 15:46:35,822] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/runwayml/stable-diffusion-v1-5/tokenizer/vocab.json
[2023-05-06 15:46:35,822] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/runwayml/stable-diffusion-v1-5/tokenizer/merges.txt
[2023-05-06 15:46:35,822] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/runwayml/stable-diffusion-v1-5/tokenizer/added_tokens.json
[2023-05-06 15:46:35,823] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/runwayml/stable-diffusion-v1-5/tokenizer/special_tokens_map.json
[2023-05-06 15:46:35,823] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/runwayml/stable-diffusion-v1-5/tokenizer/tokenizer_config.json
W0506 15:46:35.914148 21179 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0506 15:46:35.917075 21179 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2023-05-06 15:46:37,482] [ INFO] - Adding <shanshui-gen-style> to the vocabulary
[2023-05-06 15:46:37,527] [ INFO] - Found /home/aistudio/.paddlenlp/models/runwayml/stable-diffusion-v1-5/text_encoder/config.json
[2023-05-06 15:46:37,528] [ INFO] - loading configuration file /home/aistudio/.paddlenlp/models/runwayml/stable-diffusion-v1-5/text_encoder/config.json
[2023-05-06 15:46:37,528] [ WARNING] - You are using a model of type clip_text_model to instantiate a model of type . This is not supported for all configurations of models and can yield errors.
[2023-05-06 15:46:37,529] [ INFO] - Model config PretrainedConfig {
"_name_or_path": "openai/clip-vit-large-patch14",
"architectures": [
"CLIPTextModel"
],
"attention_dropout": 0.0,
"bos_token_id": 0,
"dropout": 0.0,
"eos_token_id": 2,
"hidden_act": "quick_gelu",
"hidden_size": 768,
"initializer_factor": 1.0,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 77,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"paddlenlp_version": null,
"torch_dtype": "float32",
"transformers_version": "4.21.0.dev0",
"vocab_size": 49408
}
[2023-05-06 15:46:37,568] [ INFO] - Found /home/aistudio/.cache/paddlenlp/ppdiffusers/runwayml/stable-diffusion-v1-5/text_encoder/config.json
[2023-05-06 15:46:37,569] [ INFO] - loading configuration file /home/aistudio/.cache/paddlenlp/ppdiffusers/runwayml/stable-diffusion-v1-5/text_encoder/config.json
[2023-05-06 15:46:37,570] [ INFO] - Model config CLIPTextConfig {
"_name_or_path": "openai/clip-vit-large-patch14",
"architectures": [
"CLIPTextModel"
],
"attention_dropout": 0.0,
"bos_token_id": 0,
"dropout": 0.0,
"eos_token_id": 2,
"hidden_act": "quick_gelu",
"hidden_size": 768,
"initializer_factor": 1.0,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 77,
"model_type": "clip_text_model",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"paddlenlp_version": null,
"projection_dim": 512,
"return_dict": true,
"torch_dtype": "float32",
"transformers_version": "4.21.0.dev0",
"vocab_size": 49408
}
[2023-05-06 15:46:48,452] [ INFO] - ----------- Configuration Arguments -----------
[2023-05-06 15:46:48,452] [ INFO] - adam_beta1: 0.9
[2023-05-06 15:46:48,452] [ INFO] - adam_beta2: 0.999
[2023-05-06 15:46:48,452] [ INFO] - adam_epsilon: 1e-08
[2023-05-06 15:46:48,452] [ INFO] - adam_weight_decay: 0.01
[2023-05-06 15:46:48,452] [ INFO] - center_crop: False
[2023-05-06 15:46:48,452] [ INFO] - dataloader_num_workers: 0
[2023-05-06 15:46:48,452] [ INFO] - enable_xformers_memory_efficient_attention: False
[2023-05-06 15:46:48,452] [ INFO] - gradient_accumulation_steps: 4
[2023-05-06 15:46:48,452] [ INFO] - gradient_checkpointing: False
[2023-05-06 15:46:48,452] [ INFO] - height: 512
[2023-05-06 15:46:48,452] [ INFO] - hub_model_id: None
[2023-05-06 15:46:48,452] [ INFO] - hub_token: None
[2023-05-06 15:46:48,452] [ INFO] - initializer_token: style
[2023-05-06 15:46:48,452] [ INFO] - language: en
[2023-05-06 15:46:48,453] [ INFO] - learnable_property: style
[2023-05-06 15:46:48,453] [ INFO] - learning_rate: 0.002
[2023-05-06 15:46:48,453] [ INFO] - logging_dir: shanshui_gen_style/logs
[2023-05-06 15:46:48,453] [ INFO] - lr_num_cycles: 1
[2023-05-06 15:46:48,453] [ INFO] - lr_power: 1.0
[2023-05-06 15:46:48,453] [ INFO] - lr_scheduler: constant
[2023-05-06 15:46:48,453] [ INFO] - lr_warmup_steps: 0
[2023-05-06 15:46:48,453] [ INFO] - max_grad_norm: -1
[2023-05-06 15:46:48,453] [ INFO] - max_train_steps: 1000
[2023-05-06 15:46:48,453] [ INFO] - num_train_epochs: 1
[2023-05-06 15:46:48,453] [ INFO] - num_validation_images: 4
[2023-05-06 15:46:48,453] [ INFO] - only_save_embeds: False
[2023-05-06 15:46:48,453] [ INFO] - output_dir: shanshui_gen_style
[2023-05-06 15:46:48,453] [ INFO] - placeholder_token: <shanshui-gen-style>
[2023-05-06 15:46:48,453] [ INFO] - pretrained_model_name_or_path: runwayml/stable-diffusion-v1-5
[2023-05-06 15:46:48,453] [ INFO] - push_to_hub: False
[2023-05-06 15:46:48,453] [ INFO] - repeats: 100
[2023-05-06 15:46:48,453] [ INFO] - report_to: visualdl
[2023-05-06 15:46:48,453] [ INFO] - resolution: 512
[2023-05-06 15:46:48,453] [ INFO] - save_steps: 500
[2023-05-06 15:46:48,453] [ INFO] - scale_lr: True
[2023-05-06 15:46:48,453] [ INFO] - seed: 2023
[2023-05-06 15:46:48,453] [ INFO] - tokenizer_name: None
[2023-05-06 15:46:48,453] [ INFO] - train_batch_size: 1
[2023-05-06 15:46:48,453] [ INFO] - train_data_dir: train_shanshui_gen
[2023-05-06 15:46:48,453] [ INFO] - validation_epochs: 50
[2023-05-06 15:46:48,453] [ INFO] - validation_prompt: None
[2023-05-06 15:46:48,453] [ INFO] - width: 512
[2023-05-06 15:46:48,453] [ INFO] - ------------------------------------------------
[2023-05-06 15:46:48,545] [ INFO] - ***** Running training *****
[2023-05-06 15:46:48,545] [ INFO] - Num examples = 4500
[2023-05-06 15:46:48,545] [ INFO] - Num batches each epoch = 4500
[2023-05-06 15:46:48,545] [ INFO] - Num Epochs = 1
[2023-05-06 15:46:48,545] [ INFO] - Instantaneous batch size per device = 1
[2023-05-06 15:46:48,545] [ INFO] - Total train batch size (w. parallel, distributed & accumulation) = 4
[2023-05-06 15:46:48,545] [ INFO] - Gradient Accumulation steps = 4
[2023-05-06 15:46:48,546] [ INFO] - Total optimization steps = 1000
Train Steps: 50%|▌| 500/1000 [09:32<09:32, 1.14s/it, epoch=0000, lr=0.002, ste[2023-05-06 15:56:20,836] [ INFO] - Saving embeddings
Train Steps: 100%|█| 1000/1000 [19:07<00:00, 1.15s/it, epoch=0000, lr=0.002, st[2023-05-06 16:05:55,695] [ INFO] - Saving embeddings
Fetching 10 files: 100%|███████████████████████| 10/10 [00:00<00:00, 318.92it/s]
[2023-05-06 16:06:03,860] [ INFO] - loading configuration file /home/aistudio/.cache/paddlenlp/ppdiffusers/runwayml/stable-diffusion-v1-5/feature_extractor/preprocessor_config.json from cache at /home/aistudio/.cache/paddlenlp/ppdiffusers/runwayml/stable-diffusion-v1-5/feature_extractor/preprocessor_config.json
[2023-05-06 16:06:03,861] [ INFO] - size should be a dictionary on of the following set of keys: ({'width', 'height'}, {'shortest_edge'}, {'longest_edge', 'shortest_edge'}), got 224. Converted to {'shortest_edge': 224}.
[2023-05-06 16:06:03,861] [ INFO] - crop_size should be a dictionary on of the following set of keys: ({'width', 'height'}, {'shortest_edge'}, {'longest_edge', 'shortest_edge'}), got 224. Converted to {'height': 224, 'width': 224}.
[2023-05-06 16:06:03,861] [ INFO] - Image processor CLIPFeatureExtractor {
"crop_size": {
"height": 224,
"width": 224
},
"do_center_crop": true,
"do_convert_rgb": true,
"do_normalize": true,
"do_rescale": true,
"do_resize": true,
"feature_extractor_type": "CLIPFeatureExtractor",
"image_mean": [
0.48145466,
0.4578275,
0.40821073
],
"image_processor_type": "CLIPFeatureExtractor",
"image_std": [
0.26862954,
0.26130258,
0.27577711
],
"resample": 3,
"rescale_factor": 0.00392156862745098,
"size": {
"shortest_edge": 224
}
}
[2023-05-06 16:06:03,861] [ INFO] - loading configuration file /home/aistudio/.cache/paddlenlp/ppdiffusers/runwayml/stable-diffusion-v1-5/safety_checker/config.json
[2023-05-06 16:06:03,863] [ INFO] - Model config CLIPVisionConfig {
"architectures": [
"StableDiffusionSafetyChecker"
],
"attention_dropout": 0.0,
"dropout": 0.0,
"hidden_act": "quick_gelu",
"hidden_size": 1024,
"image_size": 224,
"initializer_factor": 1.0,
"initializer_range": 0.02,
"intermediate_size": 4096,
"layer_norm_eps": 1e-05,
"model_type": "clip_vision_model",
"num_attention_heads": 16,
"num_channels": 3,
"num_hidden_layers": 24,
"paddlenlp_version": null,
"patch_size": 14,
"projection_dim": 768,
"return_dict": true
}
[2023-05-06 16:06:08,550] [ INFO] - Configuration saved in shanshui_gen_style/text_encoder/config.json
[2023-05-06 16:06:09,679] [ INFO] - tokenizer config file saved in shanshui_gen_style/tokenizer/tokenizer_config.json
[2023-05-06 16:06:09,679] [ INFO] - Special tokens file saved in shanshui_gen_style/tokenizer/special_tokens_map.json
[2023-05-06 16:06:09,680] [ INFO] - added tokens file saved in shanshui_gen_style/tokenizer/added_tokens.json
[2023-05-06 16:06:25,831] [ INFO] - Configuration saved in shanshui_gen_style/safety_checker/config.json
[2023-05-06 16:06:28,328] [ INFO] - Image processor saved in shanshui_gen_style/feature_extractor/preprocessor_config.json
[2023-05-06 16:06:28,329] [ INFO] - Saving embeddings
Train Steps: 100%|█| 1000/1000 [19:39<00:00, 1.18s/it, epoch=0000, lr=0.002, st
2. 模型预测
同样,模型预测利用 ppdiffusers 的 StableDiffusionPipeline,这里注意,要在 prompt 中加入上面 placeholder_token 设置的token <shanshui-gen-style>。
另外,生成图片的分辨率越高,貌似生成的图片 *质量* 越好 ~
import matplotlib.pyplot as plt
%matplotlib inline
from ppdiffusers import StableDiffusionPipeline
# 我们所需加载的模型地址,这里我们输入了训练时候使用的 output_dir 地址
model_path = "shanshui_gen_style"
pipe = StableDiffusionPipeline.from_pretrained(model_path)
prompt = "A fantasy landscape in <shanshui-gen-style>"
image = pipe(prompt, num_inference_steps=100, guidance_scale=7.5, height=432, width=768,).images[0]
[2023-05-06 17:25:48,682] [ INFO] - loading configuration file shanshui_gen_style/feature_extractor/preprocessor_config.json from cache at shanshui_gen_style/feature_extractor/preprocessor_config.json
[2023-05-06 17:25:48,684] [ INFO] - Image processor CLIPFeatureExtractor {
"crop_size": {
"height": 224,
"width": 224
},
"do_center_crop": true,
"do_convert_rgb": true,
"do_normalize": true,
"do_rescale": true,
"do_resize": true,
"feature_extractor_type": "CLIPFeatureExtractor",
"image_mean": [
0.48145466,
0.4578275,
0.40821073
],
"image_processor_type": "CLIPFeatureExtractor",
"image_std": [
0.26862954,
0.26130258,
0.27577711
],
"resample": 3,
"rescale_factor": 0.00392156862745098,
"size": {
"shortest_edge": 224
}
}
[2023-05-06 17:25:48,686] [ INFO] - loading configuration file shanshui_gen_style/safety_checker/config.json
[2023-05-06 17:25:48,688] [ INFO] - Model config CLIPVisionConfig {
"architectures": [
"StableDiffusionSafetyChecker"
],
"attention_dropout": 0.0,
"dropout": 0.0,
"dtype": "float32",
"hidden_act": "quick_gelu",
"hidden_size": 1024,
"image_size": 224,
"initializer_factor": 1.0,
"initializer_range": 0.02,
"intermediate_size": 4096,
"layer_norm_eps": 1e-05,
"model_type": "clip_vision_model",
"num_attention_heads": 16,
"num_channels": 3,
"num_hidden_layers": 24,
"paddlenlp_version": null,
"patch_size": 14,
"projection_dim": 768,
"return_dict": true
}
[2023-05-06 17:25:48,691] [ INFO] - Configuration saved in /home/aistudio/.cache/paddlenlp/ppdiffusers/shanshui_gen_style/safety_checker/config.json
[2023-05-06 17:25:51,073] [ INFO] - loading configuration file shanshui_gen_style/text_encoder/config.json
[2023-05-06 17:25:51,077] [ INFO] - Model config CLIPTextConfig {
"_name_or_path": "openai/clip-vit-large-patch14",
"architectures": [
"CLIPTextModel"
],
"attention_dropout": 0.0,
"bos_token_id": 0,
"dropout": 0.0,
"dtype": "float32",
"eos_token_id": 2,
"hidden_act": "quick_gelu",
"hidden_size": 768,
"initializer_factor": 1.0,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 77,
"model_type": "clip_text_model",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"paddlenlp_version": null,
"projection_dim": 512,
"return_dict": true,
"torch_dtype": "float32",
"transformers_version": "4.21.0.dev0",
"vocab_size": 49409
}
[2023-05-06 17:25:51,080] [ INFO] - Configuration saved in /home/aistudio/.cache/paddlenlp/ppdiffusers/shanshui_gen_style/text_encoder/config.json
[2023-05-06 17:25:52,155] [ INFO] - Adding <shanshui-gen-style> to the vocabulary
": “quick_gelu”,
“hidden_size”: 768,
“initializer_factor”: 1.0,
“initializer_range”: 0.02,
“intermediate_size”: 3072,
“layer_norm_eps”: 1e-05,
“max_position_embeddings”: 77,
“model_type”: “clip_text_model”,
“num_attention_heads”: 12,
“num_hidden_layers”: 12,
“pad_token_id”: 1,
“paddlenlp_version”: null,
“projection_dim”: 512,
“return_dict”: true,
“torch_dtype”: “float32”,
“transformers_version”: “4.21.0.dev0”,
“vocab_size”: 49409
}
[2023-05-06 17:25:51,080] [ INFO] - Configuration saved in /home/aistudio/.cache/paddlenlp/ppdiffusers/shanshui_gen_style/text_encoder/config.json
[2023-05-06 17:25:52,155] [ INFO] - Adding <shanshui-gen-style> to the vocabulary
0%| | 0/100 [00:00<?, ?it/s]
plt.imshow(image)
<matplotlib.image.AxesImage at 0x7fd0ac2bb9a0>

🤗 HuggingFace 模型与应用 🤗
【飞桨黑客松】AIGC - DreamBooth LoRA 文生图模型微调
这个项目里面详细介绍了如何在 AI Studio 中使用 HuggingFace,有需要的同学可以过去看看 ~
项目里面提供了一个可以将模型上传到 HuggingFace 的方法:upload_lora_folder
使用前请确保已经登录了huggingface hub!
from utils import upload_lora_folder
upload_dir = "shanshui_gen_style" # 我们需要上传的文件夹目录
repo_name = "shanshui_gen_style" # 我们需要上传的repo名称
pretrained_model_name_or_path = "shanshui_gen_style" # 训练该模型所使用的基础模型
prompt = "A fantasy landscape in <shanshui-gen-style>" # 搭配该权重需要使用的Prompt文本
upload_lora_folder(
upload_dir=upload_dir,
repo_name=repo_name,
pretrained_model_name_or_path=pretrained_model_name_or_path,
prompt=prompt,
)
虽然名字是 lora 相关的,但是没关系,模型上传上去之后手动修改一下 Model card 即可。
这里之前已经将两个模型上传上去了:
- 模型 👉 megemini/shanshui_style 可以生成水墨山水画。
- 模型 👉 megemini/shanshui_gen_style 可以生成水墨山水画的具像图片。
另外,在 AI Studio 和 HuggingFace 上建了一个相关的一个应用:
【AI Studio 应用中心】:👉 ☯ 当中国水墨山水遇上AIGC ☯
【Hugging Face 应用中心】:👉 megemini/shanshui
由于用不起GPU 👀 ,而CPU的服务运行起来又太慢(1000~2000+秒 🎃 ),这里简单放两张运行之后的截图:
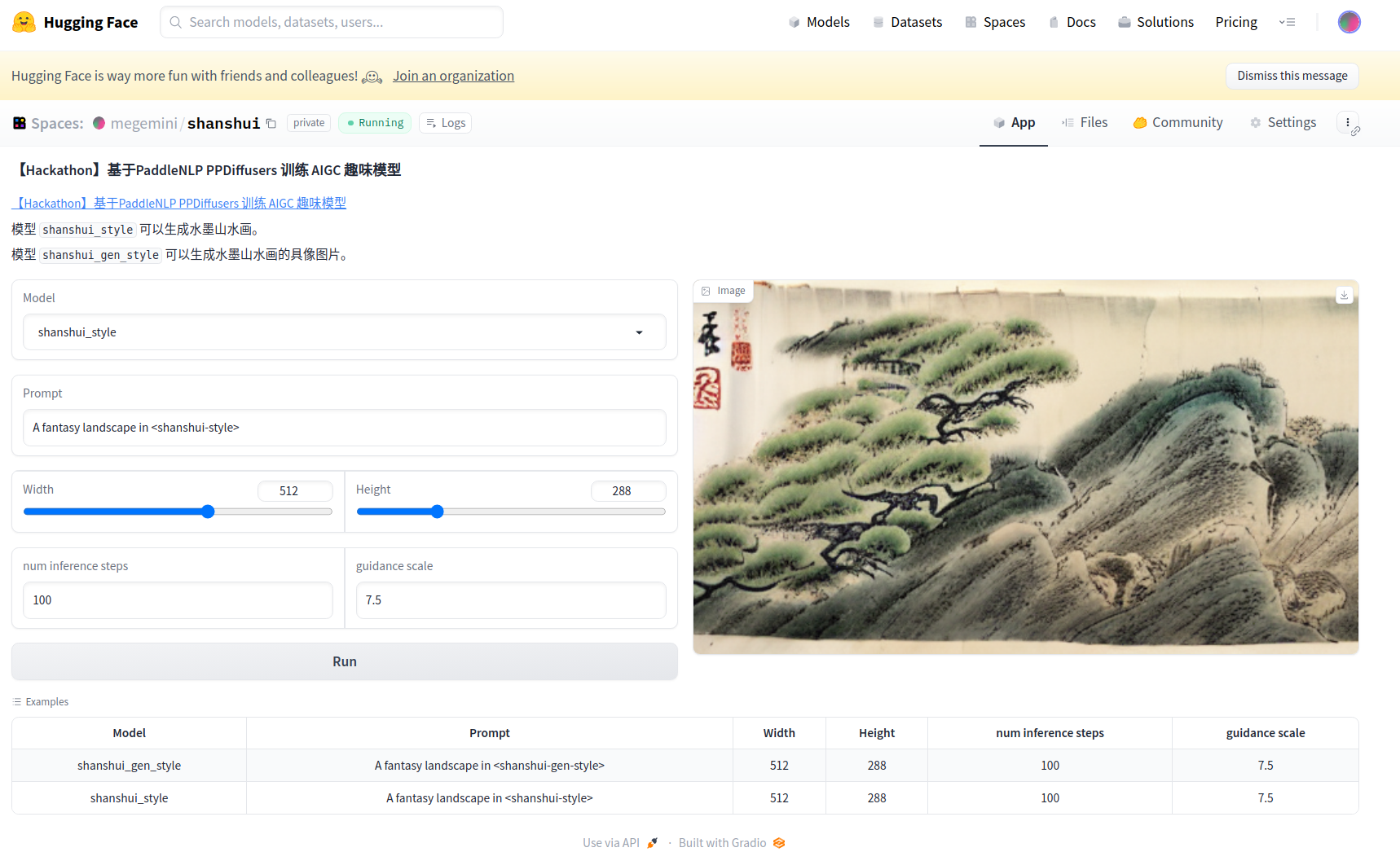
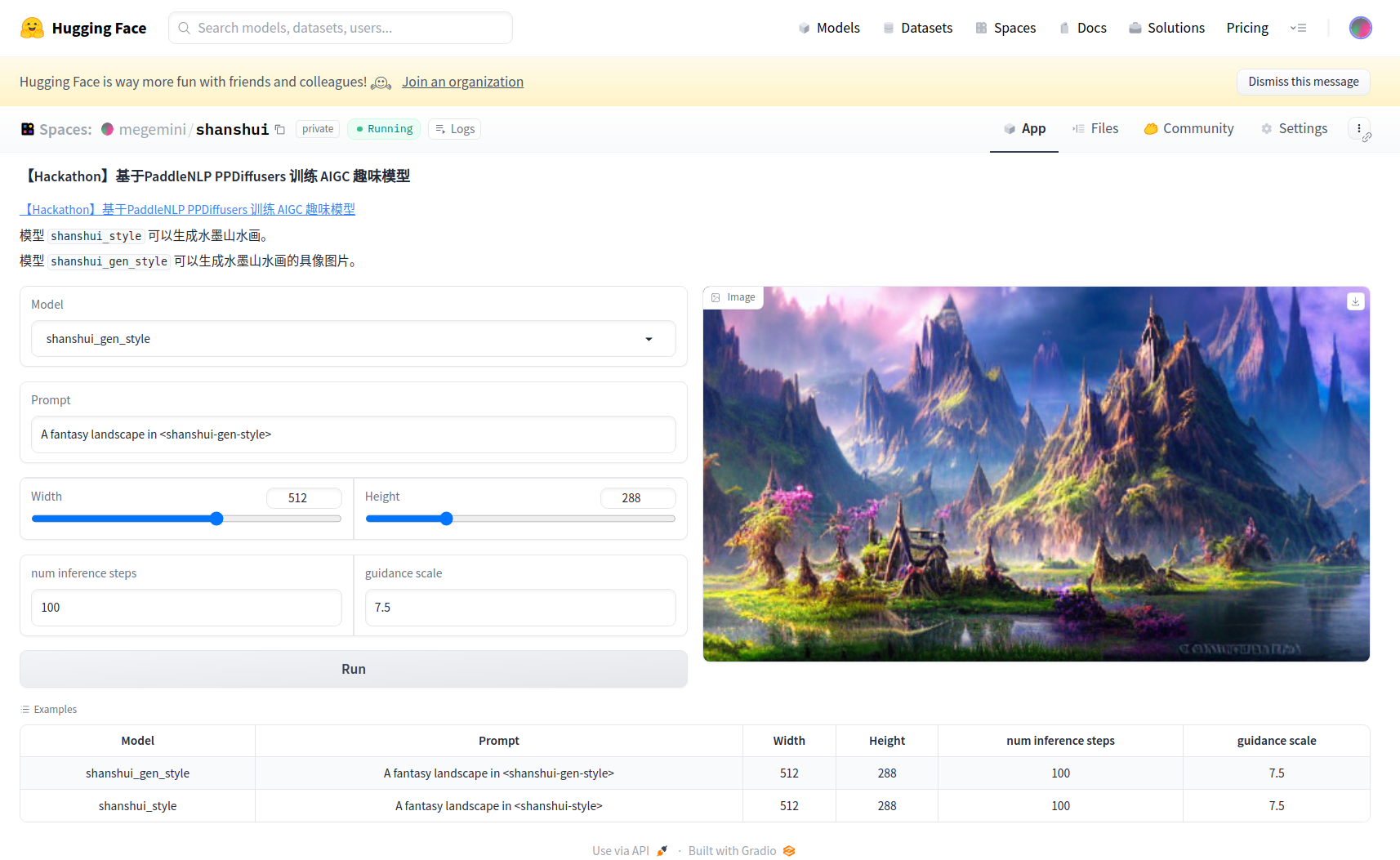
如何自建应用,又是可以水一期的话题了 (๑˃̵ᴗ˂̵),不过,很简单就是了 ~
总之,多看多学多试 ~
🍧 最后 🍧
欣赏别人的AIGC成果,远没有自己摸索来的有成就感!!!
不多说了,快来试试吧!😎
🍀 参考资料 🍀
【飞桨黑客松】AIGC - DreamBooth LoRA 文生图模型微调
此文章为搬运
原项目链接

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐


 0
0 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)