
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models翻译
大型语言模型 (LLM) 彻底改变了人工智能中的数学推理方法,推动了定量推理基准和几何推理基准的重大进步。此外,这些模型已被证明有助于帮助人类解决复杂的数学问题。然而,GPT-4 和 Gemini-Ultra 等尖端模型尚未公开,目前可访问的开源模型在性能上远远落后。在本研究中,我们引入了 DeepSeekMath,这是一种特定领域语言模型,其数学能力显著优于开源模型,并在学术基准上接近 GPT-
摘要
数学推理因其复杂性和结构性而对语言模型构成了重大挑战。在本文中,我们引入了 DeepSeekMath 7B,它继续使用来自 Common Crawl 的 120B 个数学相关 token 以及自然语言和代码数据对 DeepSeek-Coder-Base-v1.5 7B 进行预训练。DeepSeekMath 7B 在不依赖外部工具包和投票技术的情况下,在竞赛级 MATH 基准上取得了令人印象深刻的 51.7% 的成绩,接近 Gemini-Ultra 和 GPT-4 的性能水平。DeepSeekMath 7B 在 64 个样本上的自一致性在 MATH 上达到 60.9%。DeepSeekMath 的数学推理能力归功于两个关键因素:首先,我们通过精心设计的数据选择 pipline 利用了公开可用的网络数据的巨大潜力。其次,我们引入了近端策略优化(Proximal Policy Optimization, PPO)的一种变体——群相对策略优化(Group Relative Policy Optimization, GRPO),它可以增强数学推理能力,同时优化 PPO 的内存使用情况。
1.介绍
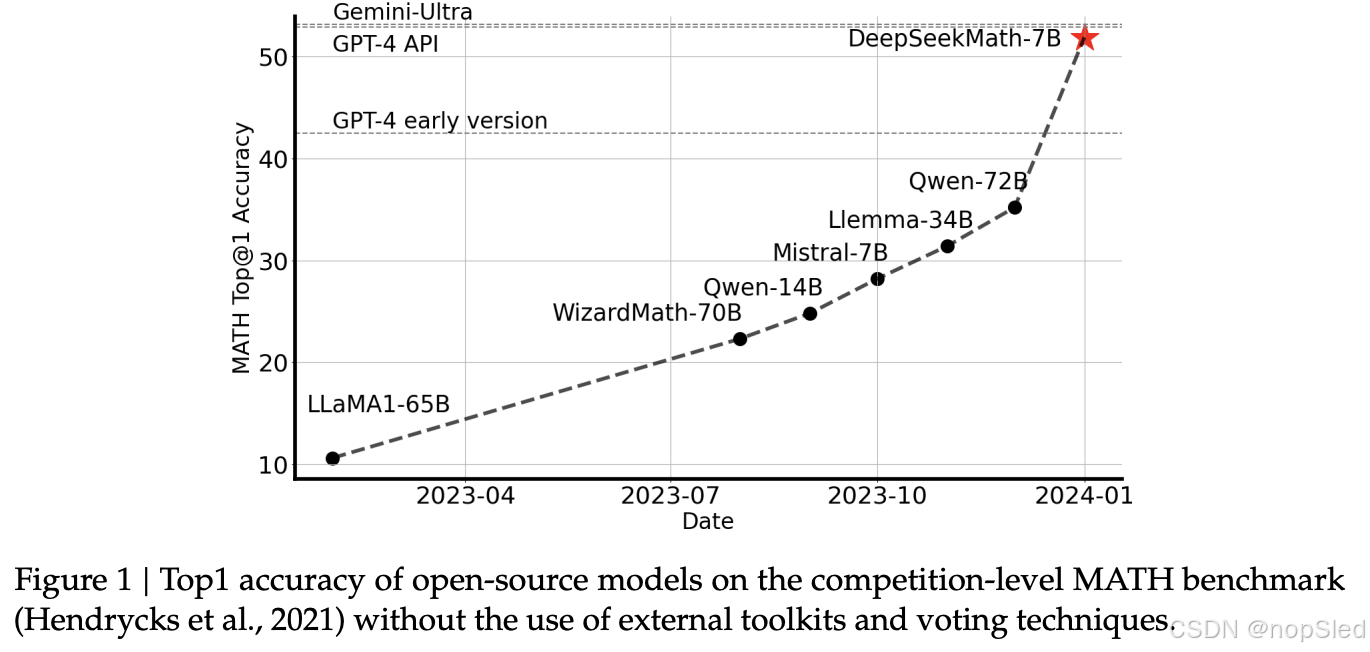
大型语言模型 (LLM) 彻底改变了人工智能中的数学推理方法,推动了定量推理基准和几何推理基准的重大进步。此外,这些模型已被证明有助于帮助人类解决复杂的数学问题。然而,GPT-4 和 Gemini-Ultra 等尖端模型尚未公开,目前可访问的开源模型在性能上远远落后。
在本研究中,我们引入了 DeepSeekMath,这是一种特定领域语言模型,其数学能力显著优于开源模型,并在学术基准上接近 GPT-4 的性能水平。为了实现这一目标,我们创建了 DeepSeekMath 语料库,这是一个包含 1200 亿个数学 token 的大规模高质量预训练语料库。此数据集是使用基于 fastText 的分类器从 Common Crawl (CC) 中提取的。在初始迭代中,分类器使用来自 OpenWebMath 的实例作为正例进行训练,同时结合各种其他网页作为负例。随后,我们使用分类器从 CC 中挖掘更多正例,并通过人工标注进一步细化。然后使用这个增强的数据集更新分类器以提高其性能。评估结果表明,大规模语料库质量很高,我们的基础模型 DeepSeekMath-Base 7B 在 GSM8K 上达到 64.2%,在竞赛级 MATH 数据集上达到 36.2%,优于 Minerva 540B。此外,DeepSeekMath 语料库是多语言的,因此我们注意到中文数学基准测试有所改进。我们相信我们在数学数据处理方面的经验是研究界的起点,未来还有很大的改进空间。
DeepSeekMath-Base 使用 DeepSeek-Coder-Base-v1.5 7B 进行初始化,我们注意到,与一般的 LLM 相比,从代码训练模型开始是更好的选择。此外,我们观察到数学训练还提高了 MMLU 和 BBH 基准上的模型能力,这表明它不仅增强了模型的数学能力,还增强了一般推理能力。
在预训练之后,我们利用思维链、思维程序和工具集成推理数据对 DeepSeekMath-Base 进行数学指令微调,最终得到的模型 DeepSeekMath-Instruct 7B 超越了所有 7B 同类模型,可与 70B 开源指令微调模型相媲美。
此外,我们引入了 Group Relative Policy Optimization (GRPO),这是近端策略优化 (PPO) 的变体强化学习 (RL) 算法。GRPO 放弃了 critic 模型,而是从组分数估计基线,从而显着减少了训练资源。通过仅使用英语指令微调数据的子集,GRPO 比强大的 DeepSeekMath-Instruct 获得了显着的改进,包括强化学习阶段的领域内(GSM8K:82.9% → 88.2%,MATH:46.8% → 51.7%)和领域外数学任务(例如,CMATH:84.6% → 88.8%)。我们还提供了一个统一的范式来理解不同的方法,例如拒绝抽样微调 (RFT)、直接偏好优化 (DPO)、PPO 和 GRPO。基于这样一个统一的范式,我们发现所有这些方法都被概念化为直接或简化的 RL 技术。我们还进行了大量实验,例如在线与离线训练、结果与过程监督、单轮与迭代强化学习等,以深入研究此范式的基本要素。最后,我们解释了为什么我们的强化学习可以提高指令微调模型的性能,并进一步总结了基于此统一范式实现更有效的强化学习的潜在方向。
1.1 Contributions
我们的贡献包括可扩展的数学预训练,以及强化学习的探索和分析。
Math Pre-Training at Scale
- 我们的研究提供了令人信服的证据,表明可公开访问的 Common Crawl 数据包含有价值的数学信息。通过实施精心设计的数据选择 pipline,我们成功构建了 DeepSeekMath Corpus,这是一个高质量的数据集,包含 1200 亿个token,这些 token 来自经过数学内容过滤的网页,其大小几乎是 Minerva 使用的数学网页的 7 倍,是最近发布的 OpenWebMath 的 9 倍。
- 我们预训练的基础模型 DeepSeekMath-Base 7B 实现了与 Minerva 540B 相当的性能,表明参数数量并不是数学推理能力的唯一关键因素。使用高质量数据进行预训练的较小模型也可以实现出色的性能。
- 我们分享了数学训练实验的发现。数学训练之前的 code 训练提高了模型解决数学问题的能力,无论是否使用工具。这为长期存在的问题提供了部分答案:代码训练是否能提高推理能力?我们相信它确实能提高推理能力,至少对于数学推理而言是如此。
- 尽管在 arXiv 论文上进行训练很常见,尤其是在许多与数学相关的论文中,但它并没有为本文采用的所有数学基准带来显著的改进。
Exploration and Analysis of Reinforcement Learning
- 我们引入了组相对策略优化 (GRPO),这是一种高效且有效的强化学习算法。GRPO 放弃了 critic 模型,而是根据组分数估计基线,与近端策略优化 (PPO) 相比,显著减少了训练资源。
- 我们证明,仅使用指令微调数据,GRPO 就能显著提高我们指令微调模型 DeepSeekMath-Instruct 的性能。此外,我们在强化学习过程中观察到领域外性能的增强。
- 我们提供了一个统一的范式来理解不同的方法,例如 RFT、DPO、PPO 和 GRPO。我们还进行了广泛的实验,例如在线与离线训练、结果与过程监督、单轮与迭代强化学习等,以深入研究该范式的基本要素。
- 基于我们的统一范式,我们探索强化学习有效性背后的原因,并总结出实现更有效的 LLM 强化学习的几个潜在方向。
1.2 Summary of Evaluations and Metrics
- English and Chinese Mathematical Reasoning。我们对我们的模型进行了全面的英语和中文基准测试评估,涵盖了从小学到大学水平的数学问题。英语基准测试包括 GSM8K、MATH、SAT、OCW 课程、MMLU-STEM。中文基准测试包括 MGSM-zh、CMATH、高考-MathCloze 和高考-MathQA。我们评估模型在不使用工具的情况下生成自包含文本解决方案的能力,以及使用 Python 解决问题的能力。
在英文基准测试中,DeepSeekMath-Base 可与闭源的 Minerva 540B 相媲美,并超越所有开源基础模型(例如 Mistral 7B 和 Llemma-34B),无论它们是否经过数学预训练,通常都领先很多。值得注意的是,DeepSeekMath-Base 在中文基准测试中更胜一筹,这可能是因为我们没有像前人一样只收集英文数学预训练数据,而是包含了高质量的非英文数据。通过数学指令微调和强化学习,DeepSeekMath-Instruct 和 DeepSeekMath-RL 表现出色,在开源社区中首次在竞赛级 MATH 数据集上获得了超过 50% 的准确率。 - Formal Mathematics。我们使用 (Jiang et al., 2022) 在 miniF2F 上的非形式化到形式化定理证明任务对 DeepSeekMath-Base 进行了评估,并选择 Isabelle 作为证明助手。DeepSeekMath-Base 表现出了强大的少量自动形式化性能。
- Natural Language Understanding, Reasoning, and Code。为了全面了解模型的通用理解、推理和编码能力,我们在大规模多任务语言理解 (MMLU) 基准上评估了 DeepSeekMath-Base,该基准包含 57 个涵盖不同主题的多项选择任务,BIG-Bench Hard (BBH) 包含 23 个具有挑战性的任务,这些任务大多需要多步推理才能解决,以及广泛用于评估代码语言模型的 HumanEval 和 MBPP。数学预训练有利于提高语言理解和推理性能。
2. Math Pre-Training
2.1 Data Collection and Decontamination
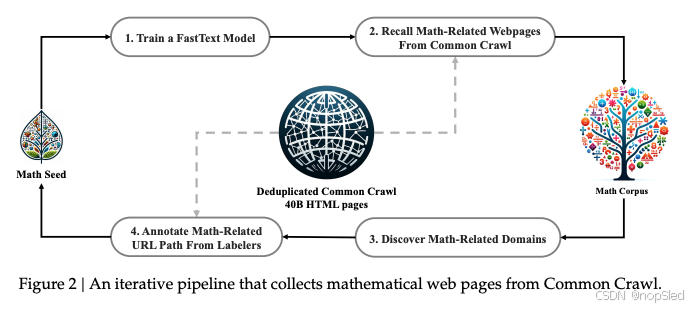
在本节中,我们将概述从 Common Crawl 构建 DeepSeekMath 语料库的过程。如图 2 所示,我们展示了一个迭代流程,演示了如何从 Common Crawl 系统地收集大规模数学语料库,从种子语料库(例如,一组小型但高质量的数学相关数据集)开始。值得注意的是,这种方法也适用于其他领域,例如编码。
首先,我们选取 OpenWebMath(一个高质量的数学网页文本集合)作为初始种子语料。利用该语料,我们训练一个 fastText 模型来召回更多类似 OpenWebMath 的数学网页。具体来说,我们从种子语料中随机选取 500,000 个数据点作为正向训练样本,从 Common Crawl 中随机选取 500,000 个网页作为负向训练样本。我们使用一个开源库进行训练,将向量维度配置为 256,学习率为 0.1,单词 n-gram 的最大长度为 3,单词出现的最小次数为 3,训练 epoch 数为 3。为了减小原始 Common Crawl 的大小,我们采用了基于 URL 的去重和近去重技术,最终得到 40B 的 HTML 网页。然后,我们使用 fastText 模型从去重后的 Common Crawl 中召回数学网页。为了过滤掉低质量的数学内容,我们根据 fastText 模型预测的分数对收集到的页面进行排序,只保留排名靠前的页面。保留的数据量是通过对前 40B、80B、120B 和 160B 个 token 进行预训练实验来评估的。在第一次迭代中,我们选择保留前 40B 个 token。
在第一次数据收集迭代之后,仍有许多数学网页未被收集,这主要是因为 fastText 模型是在一组缺乏足够多样性的正面样例上进行训练的。因此,我们确定了其他数学网络资源来丰富种子语料库,以便我们可以优化 fastText 模型。具体来说,我们首先将整个 Common Crawl 组织成不相交的域;域被定义为共享相同基本 URL 的网页。对于每个域,我们计算在第一次迭代中收集的网页百分比。收集了超过 10% 网页的域被归类为与数学相关的域(例如 mathoverflow.net)。随后,我们手动标注这些已识别域中与数学内容相关的 URL(例如 mathoverflow.net/questions)。链接到这些 URL 的网页(尚未收集)将被添加到种子语料库中。这种方法使我们能够收集更多正面示例,从而训练出一个改进的 fastText 模型,该模型能够在后续迭代中调用更多数学数据。经过四次迭代的数据收集,我们最终得到了 3550 万个数学网页,总计 1200 亿个 token。在第四次迭代中,我们注意到在第三次迭代中已经收集了近 98% 的数据,因此我们决定停止数据收集。
为了避免基准污染,我们遵循 Guo et al. (2024) 的方法,过滤掉包含英语数学基准(例如 GSM8K 和 MATH)和中文基准(例如 CMATH 和 AGIEval)的问题或答案的网页。过滤标准如下:任何包含 10 元组字符串的文本段,如果该字符串与评估基准中的任何子字符串完全匹配,则将其从数学训练语料库中删除。对于短于 10 元组但至少包含 3 元组的基准文本,我们使用精确匹配来过滤掉受污染的网页。
2.2 Validating the Quality of the DeepSeekMath Corpus
我们进行了预训练实验,以研究 DeepSeekMath 语料库与最近发布的数学训练语料库相比如何:
- MathPile。一个多源语料库(89 亿个 token),由教科书、维基百科、ProofWiki、CommonCrawl、StackExchange 和 arXiv 汇总而成,其中大部分(超过 85%)来自 arXiv;
- OpenWebMath。CommonCrawl 数据经过过滤,包含数学内容,总计 136 亿个token;
- Proof-Pile-2。一个由 OpenWebMath、AlgebraicStack(10.3B 数学代码 token)和 arXiv 论文(28.0B token)组成的数学语料库。在对 Proof-Pile-2 进行实验时,我们遵循 Azerbayev et al. (2023) 的做法,使用 arXiv:Web:Code 的比例为 2:4:1。
2.2.1 Training Setting
我们将数学训练应用于具有 1.3B 参数的通用预训练语言模型,该模型与 DeepSeek LLM 共享相同的框架,记为 DeepSeek-LLM 1.3B。我们在每个数学语料库上分别训练一个模型,其中包含 150B 个 token。所有实验均使用高效、轻量级的 HAI-LLM 训练框架进行。遵循 DeepSeek LLM 的训练实践,我们使用 AdamW 优化器,其中 β1=0.9\beta_1 = 0.9β1=0.9、β2=0.95\beta_2 = 0.95β2=0.95 和 weight_decay = 0.1,以及一个多步学习率计划,其中学习率在 2,000 个预热步骤后达到峰值,在训练过程的 80% 后下降到 31.6%,并在训练过程的 90% 后进一步下降到峰值的 10.0%。我们将学习率的最大值设置为 5.3e−45.3e-45.3e−4,并使用 4M 个 token 的 batch size 和 4K 上下文长度。
2.2.2 Evaluation Results
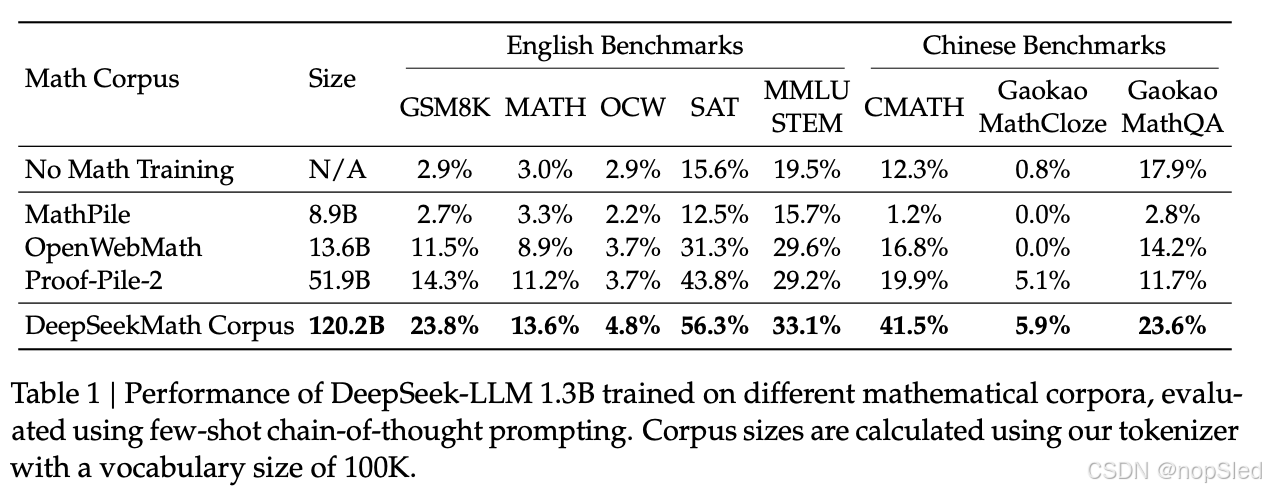
DeepSeekMath语料库质量高,涵盖多语言数学内容,并且规模最大。
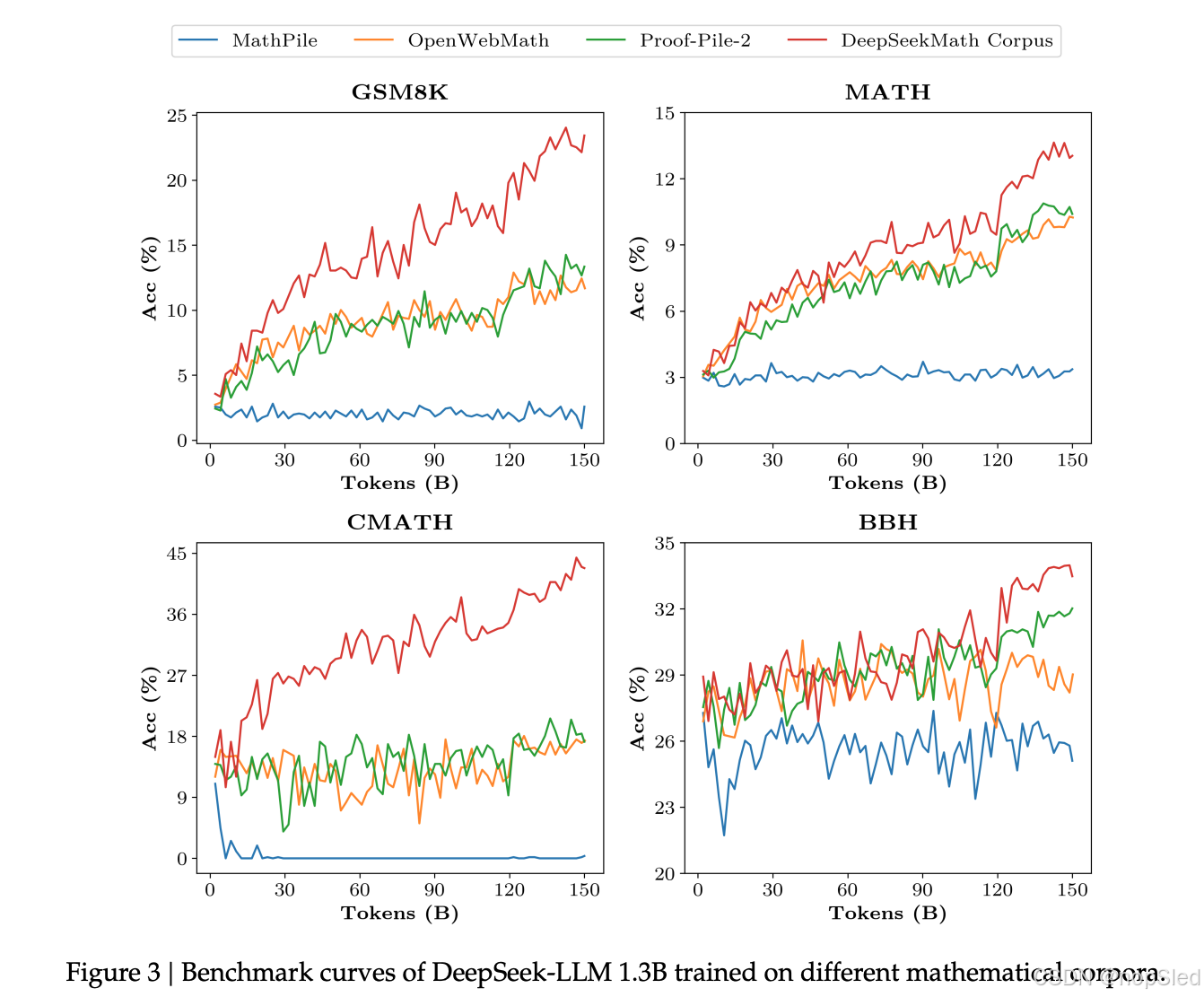
- High-quality。我们使用 Wei et al. (2022) 提出的 few-shot 思维链方法在 8 个数学基准上评估下游性能。如表 1 所示,在 DeepSeekMath Corpus 上训练的模型具有明显的性能领先优势。图 3 显示在 DeepSeekMath Corpus 上训练的模型在 50B 个 token(Proof-Pile-2 的 1 个完整 epoch)上表现出比 Proof-Pile-2 更好的性能,表明 DeepSeekMath Corpus 的平均质量更高。
- Multilingual。DeepSeekMath 语料库涵盖多种语言数据,其中英语和汉语是主要语言。如表 1 所示,使用 DeepSeekMath 语料库进行训练可以提高英语和汉语的数学推理性能。相比之下,现有的数学语料库主要以英语为中心,对中文数学推理的提升有限,甚至可能阻碍其表现。
- Large-scale。DeepSeekMath 语料库比现有的数学语料库大几倍。如图 3 所示,DeepSeek-LLM 1.3B 在 DeepSeekMath 语料库上训练时,学习曲线更陡峭,改进效果更持久。相比之下,基线语料库要小得多,并且在训练过程中已经重复了多轮,最终的模型性能很快达到了稳定状态。
2.3 Training and Evaluating DeepSeekMath-Base 7B
在本节中,我们介绍了 DeepSeekMath-Base 7B,这是一个具有强大推理能力(尤其是在数学方面)的基础模型。我们的模型使用 DeepSeek-Coder-Base-v1.5 7B 初始化,并针对 500B 个 token 进行训练。数据分布如下:56% 来自 DeepSeekMath Corpus,4% 来自 AlgebraicStack,10% 来自 arXiv,20% 是 Github 代码,其余 10% 是来自 Common Crawl 的英文和中文自然语言数据。我们主要采用第 2.2.1 节中指定的训练设置,但我们将学习率的最大值设置为 4.2e-4,并使用 10M 个 token 的 batch size。
我们对 DeepSeekMath-Base 7B 的数学能力进行了全面评估,重点关注其在不依赖外部工具的情况下生成自包含数学解决方案、使用工具解决数学问题以及进行正式定理证明的能力。除了数学之外,我们还提供了基础模型的更一般概况,包括其自然语言理解、推理和编程技能的表现。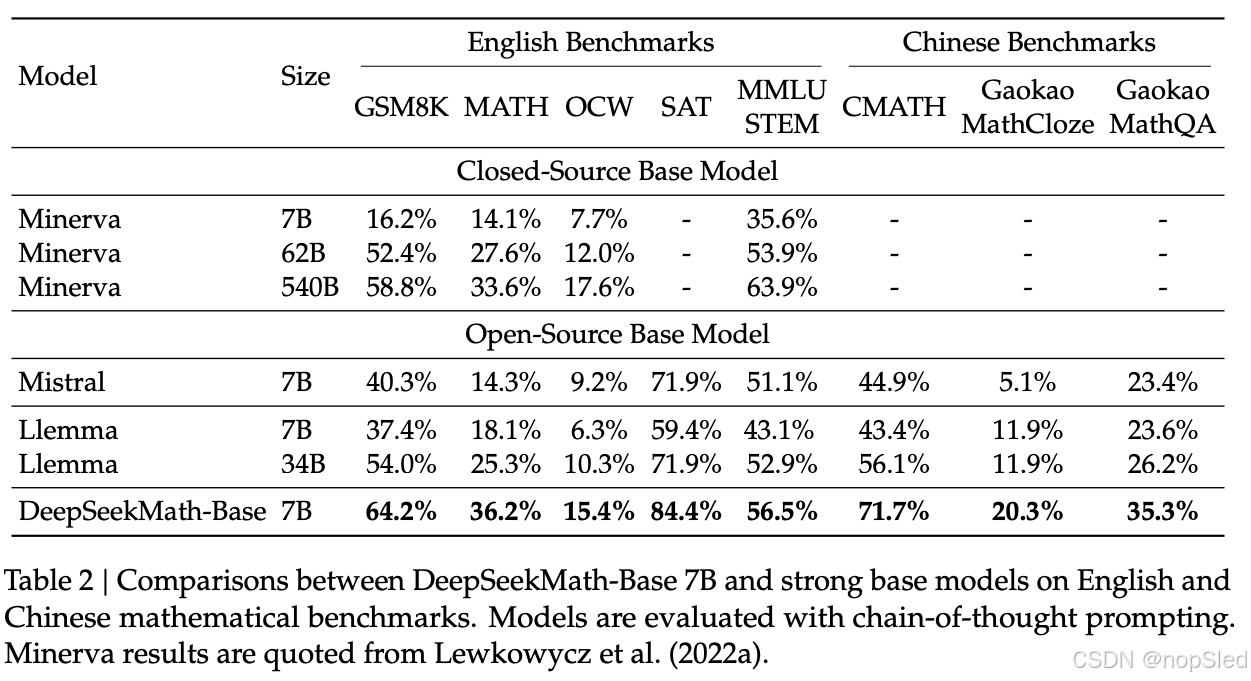
Mathematical Problem Solving with Step-by-Step Reasoning。我们在 8 个英语和中文基准中评估了 DeepSeekMathBase 使用少样本思维链提示解决数学问题的性能。这些基准涵盖定量推理(例如 GSM8K、MATH 和 CMATH)和多项选择题(例如 MMLU-STEM 和 Gaokao-MathQA),涵盖了从小学到大学水平的各种数学领域。
如表二所示,DeepSeekMath-Base 7B 在 8 个开源基础模型(包括广泛使用的通用模型 Mistral 7B 和最近发布的在 Proof-Pile-2 上进行数学训练的 Llemma 34B)的基准测试中均表现领先。值得注意的是,在竞赛级数学数据集上,DeepSeekMath-Base 绝对领先现有开源基础模型 10% 以上,并优于 Minerva 540B(一个规模大 77 倍、基于 PaLM 构建并在数学文本上进一步训练的闭源基础模型)。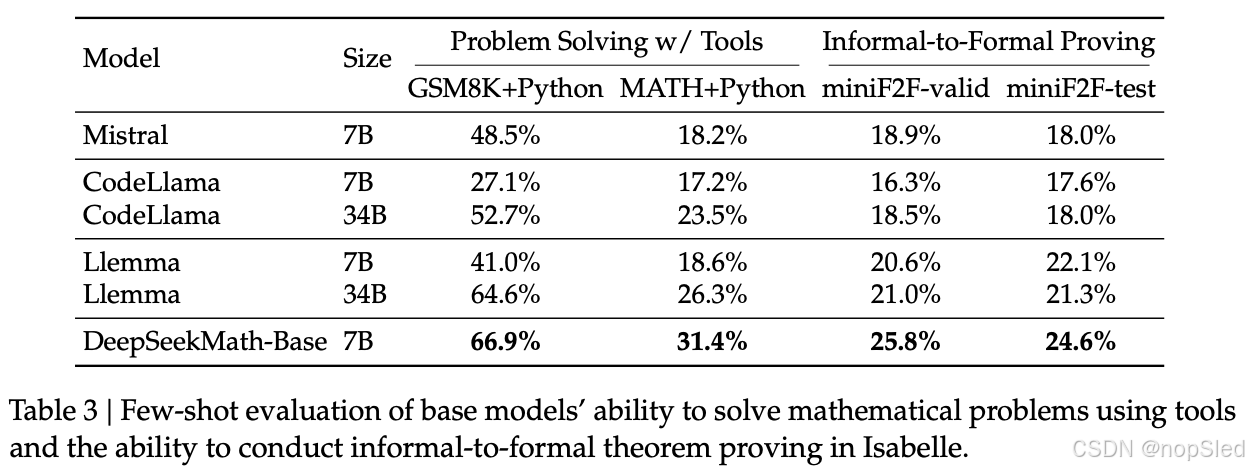
Mathematical Problem Solving with Tool Use。我们使用少样本思维程序提示来评估 GSM8K 和 MATH 上的程序辅助数学推理。通过编写 Python 程序来提示模型解决每个问题,其中可以使用 math 和 sympy 等库进行复杂的计算。程序的执行结果被评估为答案。如表 3 所示,DeepSeekMath-Base 7B 的表现优于之前最先进的 Llemma 34B。
Formal Mathematics。形式化证明自动化有利于保证数学证明的准确性和可靠性,提高证明效率,近年来受到越来越多的关注。我们在非形式化到形式化证明的任务上对 DeepSeekMath-Base 7B 进行了评估,该任务是基于非形式化语句、该语句的形式对应项和非形式化证明生成形式化证明。我们在正式的奥林匹克级数学基准 miniF2F 上进行了评估,并在 Isabelle 中为每个问题生成了一个形式化证明,只需少量提示即可。类似 Jiang et al. (2022),我们利用模型生成证明草图,并执行现成的自动证明器 Sledgehammer 来填补缺失的细节。如表 3 所示,DeepSeekMath-Base 7B 在证明自动形式化方面表现出色。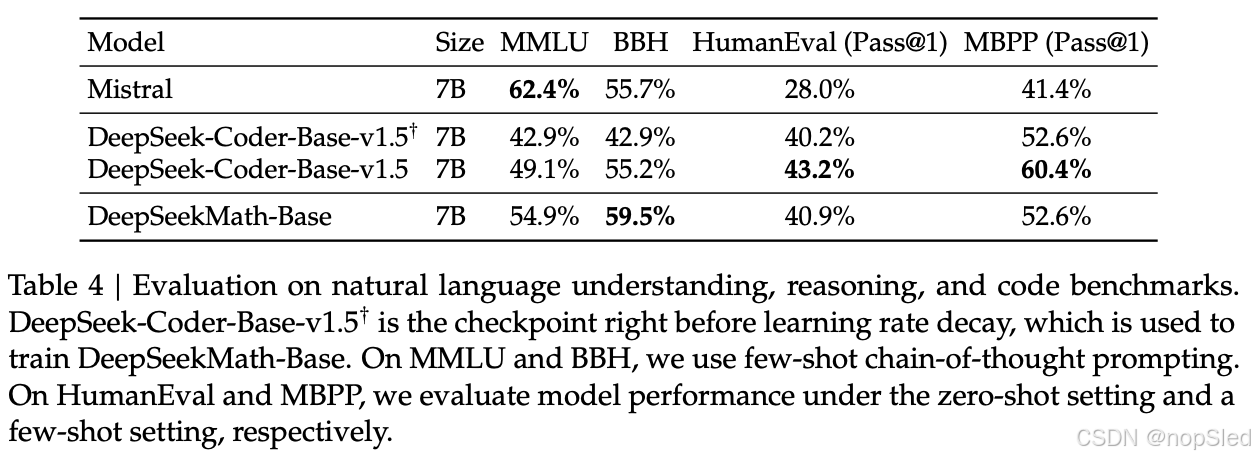
Natural Language Understanding, Reasoning, and Code。我们评估了模型在 MMLU 上的自然语言理解性能、在 BBH 上的推理性能以及在 HumanEval 和 MBPP 上的编码能力。如表 4 所示,DeepSeekMath-Base 7B 在 MMLU 和 BBH 上的性能显著优于其前身 DeepSeek-Coder-Base-v1.5,这说明了数学训练对语言理解和推理的积极影响。此外,通过包含用于持续训练的代码 token,DeepSeekMath-Base 7B 在两个编码基准上有效地保持了 DeepSeek-Coder-Base-v1.5 的性能。总体而言,DeepSeekMath-Base 7B 在三个推理和编码基准上的表现明显优于通用模型 Mistral 7B。
3. Supervised Fine-Tuning
3.1 SFT Data Curation
我们构建了一个数学指令微调数据集,涵盖不同数学领域、不同复杂程度的英语和汉语问题:问题与解决方案以思维链(CoT)、思维程序(PoT)和工具集成推理格式配对。训练样例总数为 776K。
- English mathematical datasets。我们用工具集成解决方案标注 GSM8K 和 MATH 问题,并采用 MathInstruct 的子集以及 Lila-OOD 的训练集,其中问题用 CoT 或 PoT 解决。我们的英文集涵盖了数学的不同领域,例如代数、概率、数论、微积分和几何。
- Chinese mathematical datasets。我们收集了中文 K-12 数学问题,涵盖 76 个子主题,例如线性方程,并以 CoT 和工具集成推理格式标注解决方案。
3.2 Training and Evaluating DeepSeekMath-Instruct 7B
4. Reinforcement Learning
4.1 Group Relative Policy Optimization
强化学习 (RL) 已被证明能够有效地在有监督微调 (SFT) 阶段之后进一步提高 LLM 的数学推理能力。在本节中,我们将介绍我们高效且有效的 RL 算法—— Group Relative Policy Optimization (GRPO)。
4.1.1 From PPO to GRPO
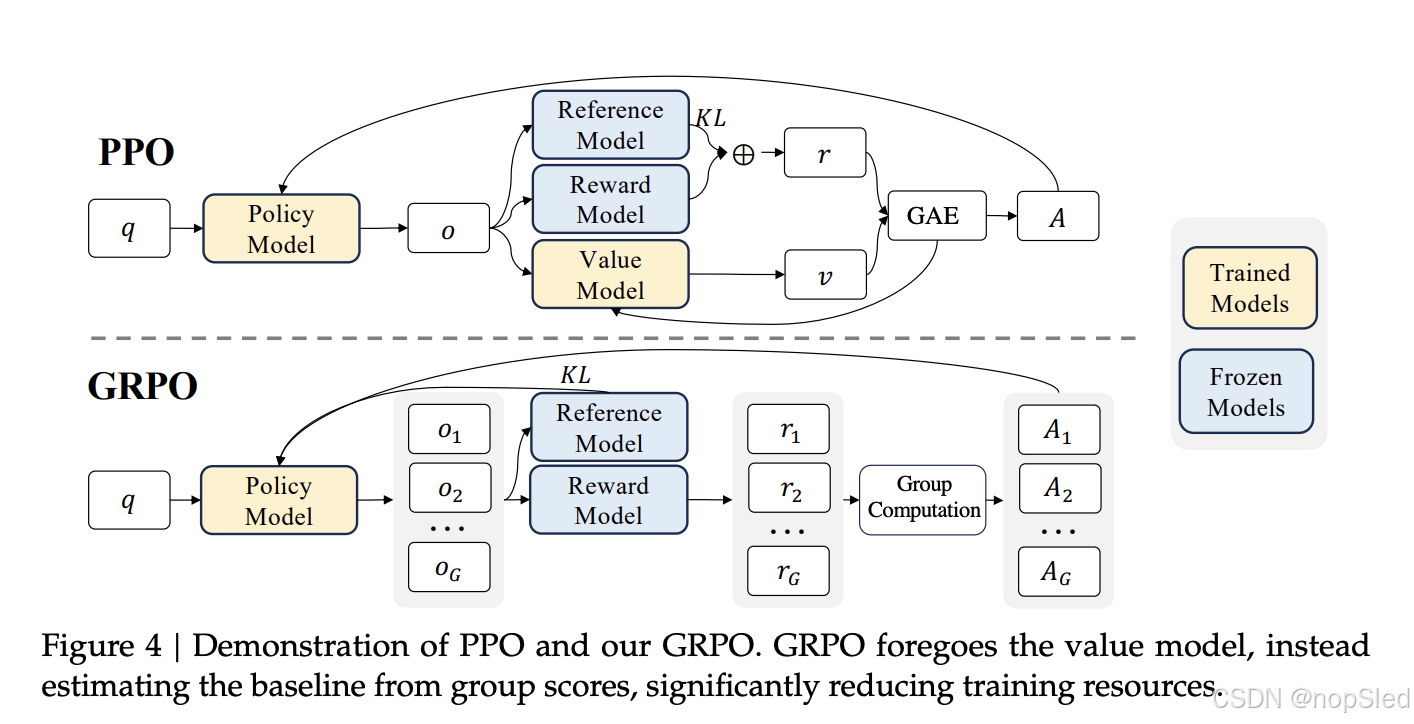
近端策略优化 (PPO) 是一种 actor-critic RL 算法,广泛应用于 LLM 的 RL 微调阶段。具体来说,它通过最大化以下目标来优化 LLM:
JPPO(θ)=E[q∼P(Q),o∼πθold(O∣q)]1∣o∣∑t=1∣o∣min[πθ(ot∣q,o<t)πθold(ot∣q,o<t)At,clip(πθ(ot∣q,o<t)πθold(ot∣q,o<t),1−ϵ,1+ϵ)At],(1)\mathcal J_{PPO}(\theta)=\mathbb E[q\sim P(Q),o\sim\pi_{\theta_{old}}(O|q)]\frac{1}{|o|}\sum^{|o|}_{t=1}min[\frac{\pi_{\theta}(o_t|q,o_{<t})}{\pi_{\theta_{old}}(o_t|q,o_{<t})}A_t,clip(\frac{\pi_{\theta}(o_t|q,o_{<t})}{\pi_{\theta_{old}}(o_t|q,o_{<t})},1-\epsilon,1+\epsilon)A_t],\tag{1}JPPO(θ)=E[q∼P(Q),o∼πθold(O∣q)]∣o∣1t=1∑∣o∣min[πθold(ot∣q,o<t)πθ(ot∣q,o<t)At,clip(πθold(ot∣q,o<t)πθ(ot∣q,o<t),1−ϵ,1+ϵ)At],(1)
其中 πθ\pi_{\theta}πθ 和 πθold\pi_{\theta_{old}}πθold 分别是当前和旧的策略模型,q,oq, oq,o 分别是从问题数据集和旧策略 πθold\pi_{\theta_{old}}πθold 中采样的问题和输出。ϵ\epsilonϵ 是 PPO 中引入的与 clip 相关的超参数,用于稳定训练。AtA_tAt 是优势,它是通过应用广义优势估计 (GAE) 计算得出的,基于奖赏 {r≤t}\{r_{\le t}\}{r≤t} 和学习到的价值函数 VψV_{\psi}Vψ。因此,在 PPO 中,需要与策略模型一起训练价值函数,为了减轻奖赏模型的过度优化,标准方法是在每个 token 的奖赏中添加来自参考模型的每个 token KL 惩罚,即,
rt=rϕ(q,o≤t)−βlogπθ(ot∣q,o<t)πref(ot∣q,o<t),(2)r_t=r_{\phi}(q,o_{\le t})-\beta log\frac{\pi_{\theta}(o_t|q,o_{\lt t})}{\pi_{ref}(o_t|q,o_{\lt t})},\tag{2}rt=rϕ(q,o≤t)−βlogπref(ot∣q,o<t)πθ(ot∣q,o<t),(2)
其中 rϕr_{\phi}rϕ 是奖赏模型,πref\pi_{ref}πref 是参考模型,通常是初始 SFT 模型,β\betaβ 是 KL 惩罚的系数。
由于 PPO 中采用的价值函数通常是与策略模型大小相当的另一个模型,因此它会带来大量内存和计算负担。此外,在 RL 训练期间,价值函数被视为计算方差减少优势的基线。而在 LLM 环境中,奖赏模型通常只为最后一个 token 分配分数,这可能会使训练针对每个 token 都准确的价值函数变得复杂。为了解决这个问题,如图 4 所示,我们提出了组相对策略优化 (GRPO),它避免了像 PPO 中那样需要额外的价值函数近似,而是使用针对同一问题产生的多个采样输出的平均奖赏作为基线。更具体地说,对于每个问题qqq,GRPO 从旧策略πθold\pi_{\theta_old}πθold中采样一组输出 {o1,o2,⋅⋅⋅,oG}\{o_1, o_2, · · · ,o_G\}{o1,o2,⋅⋅⋅,oG},然后通过最大化以下目标来优化策略模型:
JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πold(O∣q)]1G∑i=1G1∣oi∣∑t=1∣oi∣{min[πθπθoldA^i,t,clip()A^i,t]−βDKL[πtheta∣πref]},(3)\mathcal J_{GRPO}(\theta)=\mathbb E[q\sim P(Q),\{o_i\}^G_{i=1}\sim\pi_{old}(O|q)]\frac{1}{G}\sum^G_{i=1}\frac{1}{|o_i|}\sum^{|o_i|}_{t=1}\{min[\frac{\pi_{\theta}}{\pi_{\theta_{old}}}\hat A_{i,t},clip()\hat A_{i,t}]-\beta \mathbb D_{KL}[\pi_{theta}|\pi_{ref}]\},\tag{3}JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πold(O∣q)]G1i=1∑G∣oi∣1t=1∑∣oi∣{min[πθoldπθA^i,t,clip()A^i,t]−βDKL[πtheta∣πref]},(3)
其中 ϵ\epsilonϵ 和 β\betaβ 是超参数,A^i,t\hat A_{i,t}A^i,t 是基于每个组内输出的相对奖赏计算的优势,将在以下小节中详细介绍。GRPO 利用组相对方式计算优势,这与奖赏模型的比较性质非常吻合,因为奖赏模型通常在同一问题的输出比较数据集上进行训练。还要注意,GRPO 不是在奖赏中添加 KL 惩罚,而是通过将训练策略和参考策略之间的 KL 散度直接添加到损失中进行正则化,从而避免使 A^i,t\hat A_{i,t}A^i,t 的计算复杂化。
与 (2) 中使用的 KL 惩罚项不同,我们使用以下无偏估计量来估计 KL 散度:
DKL[πθ∣∣πref]=πref(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)−logπref(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)−1,(4)\mathbb D_{KL}[\pi_{\theta}||\pi_{ref}]=\frac{\pi_{ref}(o_{i,t}|q,o_{i,<t})}{\pi_{\theta}(o_{i,t}|q,o_{i,<t})}-log\frac{\pi_{ref}(o_{i,t}|q,o_{i,<t})}{\pi_{\theta}(o_{i,t}|q,o_{i,<t})}-1,\tag{4}DKL[πθ∣∣πref]=πθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−logπθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−1,(4)
这能保证是正数。
4.1.2 Outcome Supervision RL with GRPO
正式来说,对于每个问题 qqq,从旧策略模型 πθold\pi_{\theta_{old}}πθold 中抽样出一组输出 {o1,o2,⋅⋅⋅,oG}\{o_1, o_2, · · · , o_G\}{o1,o2,⋅⋅⋅,oG}。然后使用奖赏模型对输出进行评分,从而相应地产生 GGG 个奖赏 r={r1,r2,⋅⋅⋅,rG}\textbf r = \{r_1,r_2, · · · ,r_G\}r={r1,r2,⋅⋅⋅,rG}。随后,通过减去组平均值并除以组标准差来对这些奖赏进行归一化。结果监督在每个输出 oio_ioi 结束时提供标准化奖赏,并将输出中所有token的优势 A^i,t\hat A_{i,t}A^i,t 设为标准化奖励,即 A^i,t=r~i=ri−mean(r)std(r)\hat A_{i,t}=\tilde r_i=\frac{r_i-mean(\textbf r)}{std(\textbf r)}A^i,t=r~i=std(r)ri−mean(r),然后通过最大化公式(3)中定义的目标来优化策略。
4.1.3 Process Supervision RL with GRPO
4.1.4 Iterative RL with GRPO

4.2 Training and Evaluating DeepSeekMath-RL
我们基于 DeepSeekMath-Instruct 7B 进行 RL。RL 的训练数据是来自 SFT 数据、与 GSM8K 和 MATH 相关的思维链格式问题,其中包含约 144K 个问题。我们排除其他 SFT 问题,以调查 RL 对整个 RL 阶段缺乏数据的基准的影响。我们构建了以下奖赏模型的训练集。我们基于 DeepSeekMath-Base 7B 训练我们的初始奖赏模型,学习率为 2e-5。对于 GRPO,我们将策略模型的学习率设置为 1e-6。KL 系数为 0.04。对于每个问题,我们采样 64 个输出。最大长度设置为 1024,训练 batch size 为 1024。策略模型在每个探索阶段后仅进行一次更新。我们在 DeepSeekMath-Instruct 7B 之后的基准上评估 DeepSeekMath-RL 7B。对于 DeepSeekMath-RL 7B,GSM8K 和具有思路链推理的 MATH 可视为域内任务,而所有其他基准可视为领域外任务。
表 5 展示了在英文和中文基准测试中,开源和闭源模型使用思路链推理和工具集成推理的性能。我们发现:1)DeepSeekMath-RL 7B 使用思维链推理在 GSM8K 和 MATH 上分别达到了 88.2% 和 51.7% 的准确率。这个性能超过了 7B 到 70B 范围内的所有开源模型,也超过了大多数闭源模型。2)至关重要的是,DeepSeekMath-RL 7B 只在 GSM8K 和 MATH 的思维链格式指令调优数据上进行训练,从 DeepSeekMath-Instruct 7B 开始。尽管其训练数据范围有限,但它在所有评估指标上都优于 DeepSeekMath-Instruct 7B,展示了强化学习的有效性。
5.Discussion

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐


 1
1 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)