
【AI前沿】又整活了!三条AI前沿技术WaveSpeed、TransPixar、Gemini-Search
真是一日不见如过三秋!这几天 AI 界又出了几个较为重磅的消息。

前言
真是一日不见如过三秋!这几天 AI 界又出了几个较为重磅的消息。
-
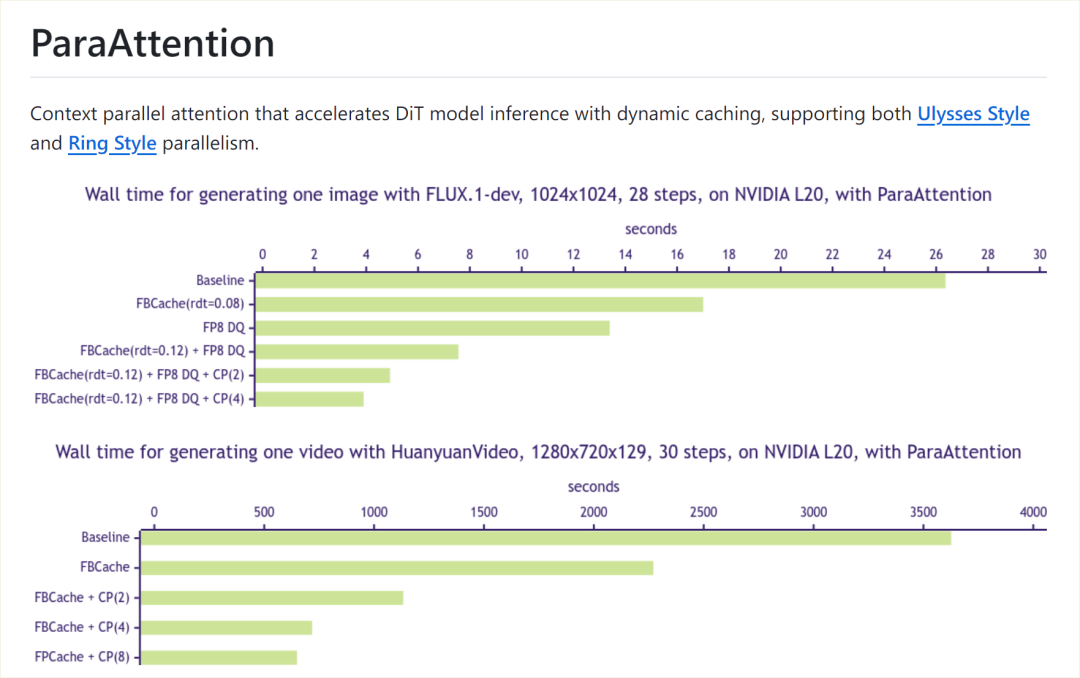
FLUX 加速技术 WaveSpeed,支持 ComfyUI,实测速度感人!
-
Adobe 发布和开源了TransPixar 可以生成透明背景视频素材
-
开源的 Gemini-Search,效果媲美官方的Google Research
作为实践和行动派的小编,跟大家同步这些信息的同时,也会帮大家实测一下,看是不是有其宣传的功效😎。
FLUX 加速技术 WaveSpeed
项目地址:
技术原理
具体的技术原理,大家可以到项目中看看。
我尝试整理资料,通俗解释一下,不一定准确哈~😂。
❝
一种让AI模型跑得更快的新技术,主要针对一类叫做“DiT模型”的AI,这种模型常用于生成图像和视频。想象一下,你在厨房里准备一道复杂的菜,这篇文章就像是教你如何更高效地完成它。「核心思想:让多个“厨师”一起做菜,并且学会偷懒。」
❞
「1. Context Parallel Attention (上下文并行注意力) - 多人协同做菜:」
-
「问题:」 传统的AI模型在生成图像或视频时,就像一个厨师按部就班地完成所有步骤,很耗时间。
-
「解决方法:」 把任务分解成小块,让多个“厨师”(可以理解为多个GPU,也就是电脑的处理器)同时进行。就好比切菜、炒菜、调味等步骤可以同时进行。
-
「具体做法:」 他们发明了一种叫做 “ParaAttention” 的技术,可以把模型中的关键部分(叫做“注意力层”)拆分,让不同的GPU并行计算。他们还提供了两种不同的拆分方法,叫做 “Ulysses Style” 和 “Ring Style”,可以根据不同的情况选择最快的方式。他们甚至能把这两种方式结合起来,达到更好的效果。
-
「简化理解:」 就像组建一个厨房团队,每个人负责一部分工作,一起更快地完成菜肴。
「2. First Block Cache (第一个模块缓存) - 聪明地偷懒:」
-
「问题:」 AI模型在生成图像或视频的过程中,有些计算可能是重复的,浪费时间。
-
「解决方法:」 他们受到一些“缓存”技巧的启发,发明了一种叫做 “FBCache” 的方法。这个方法会观察模型运行的“第一个步骤”(就像做菜的第一个准备工作),如果发现和上次很像,就直接跳过后面的很多重复步骤,直接使用上次的结果。
-
「形象比喻:」 就像你已经做了很多次炒鸡蛋了,如果这次发现鸡蛋和上次的差不多,你就可以直接跳过打鸡蛋、放油等步骤,直接用上次的经验。
-
「可调节的“偷懒”程度:」 你可以设置一个“阈值”,来决定多像的情况下才“偷懒”。阈值越高,偷懒越多,速度越快,但可能稍微影响最终效果。
出了 flux 模型,Huanyuan 也支持加速。
测试
项目作者提供了 ComfyUI 的使用方法,通过插件方式,即可达到加速效果。ComfyUI 插件地址:https://github.com/chengzeyi/Comfy-WaveSpeed
❝
以下数据仅为初测,我就不做更严谨的测试了,各位将就看看
❞
基准:
-
使用 FP8 FLUX 模型,
-
在模型都加载到内存开始测试,
-
步数为 28。
-
分辨率:1024 x1024
-
设备:4090
-
跑三次
提示语:
A 25 year old janese girl with dark long hair, she is wearing a orange tank top and a necklace. She is holding a white paper with the word "SJXZ 00" written on it in black letters. In the dark with dim light,
FLUX 原生:
用时 14.52 、15.73、 17.81,平均 16.02 秒
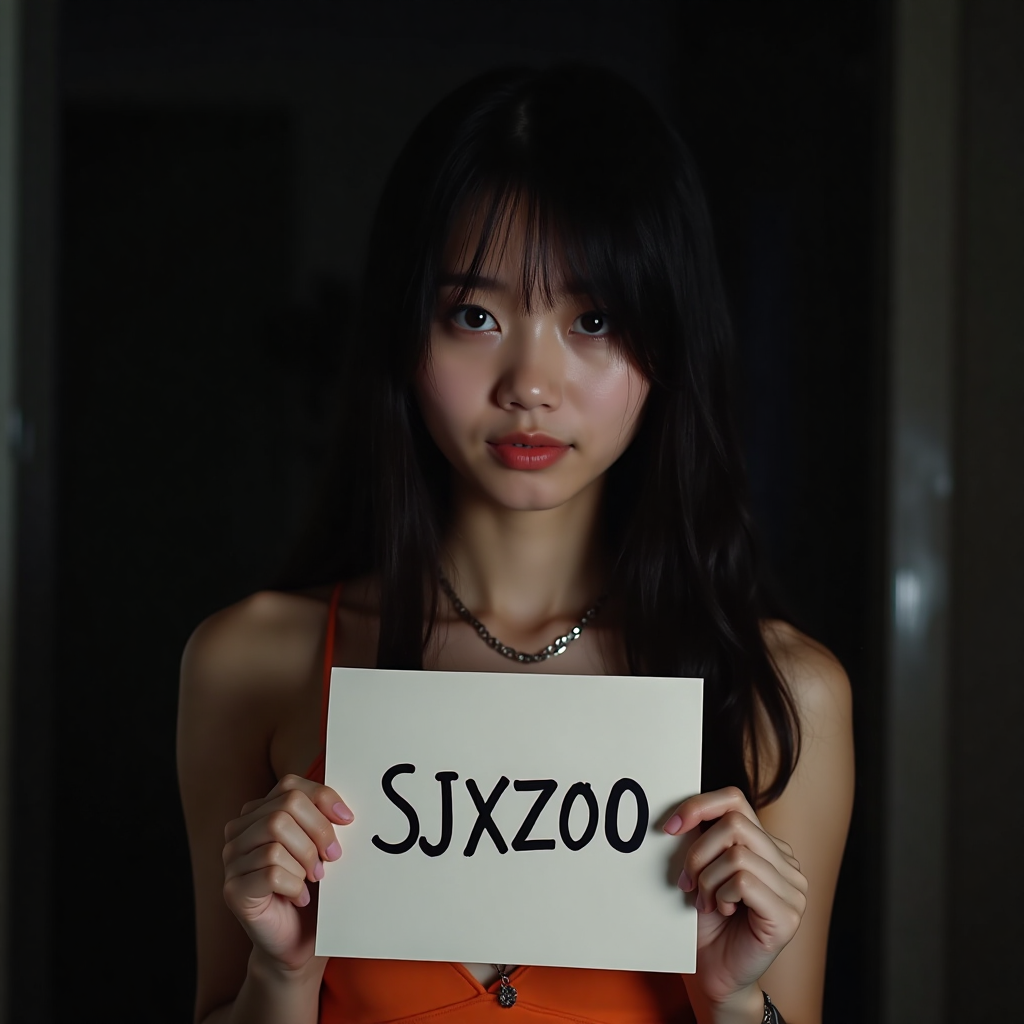
WaveSpeed 加速
用时 9.53 、9.77、 8.49,平均 9.26 秒!速度提升 「42%」,🤯。而且不同于 LoRA 加速,画质上看,是完全无损的,基本可以确定,这个方法可用!后面就需要多测试一些场景,已经跟其他第三方模型的兼容性了。
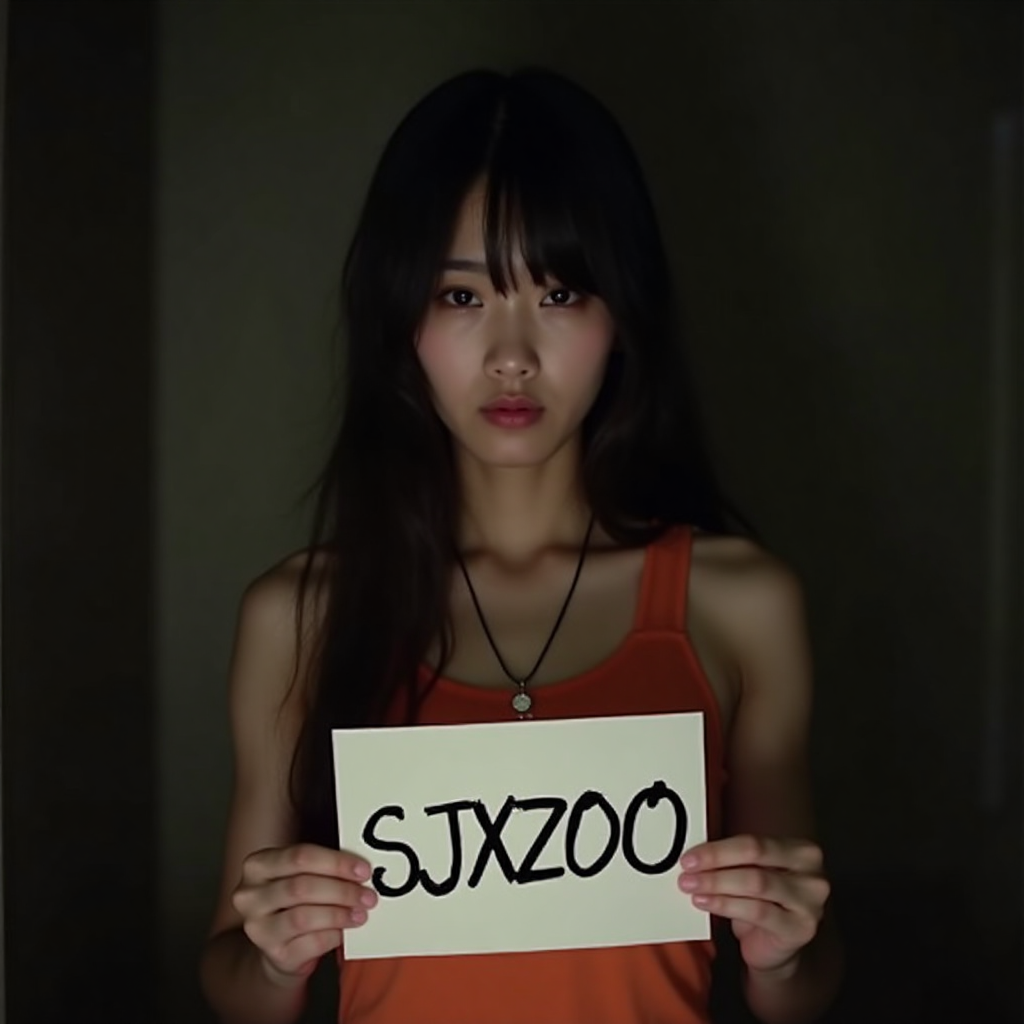
第三方模型
测试了一下最新的麦橘模型,质量也是很好的👍。
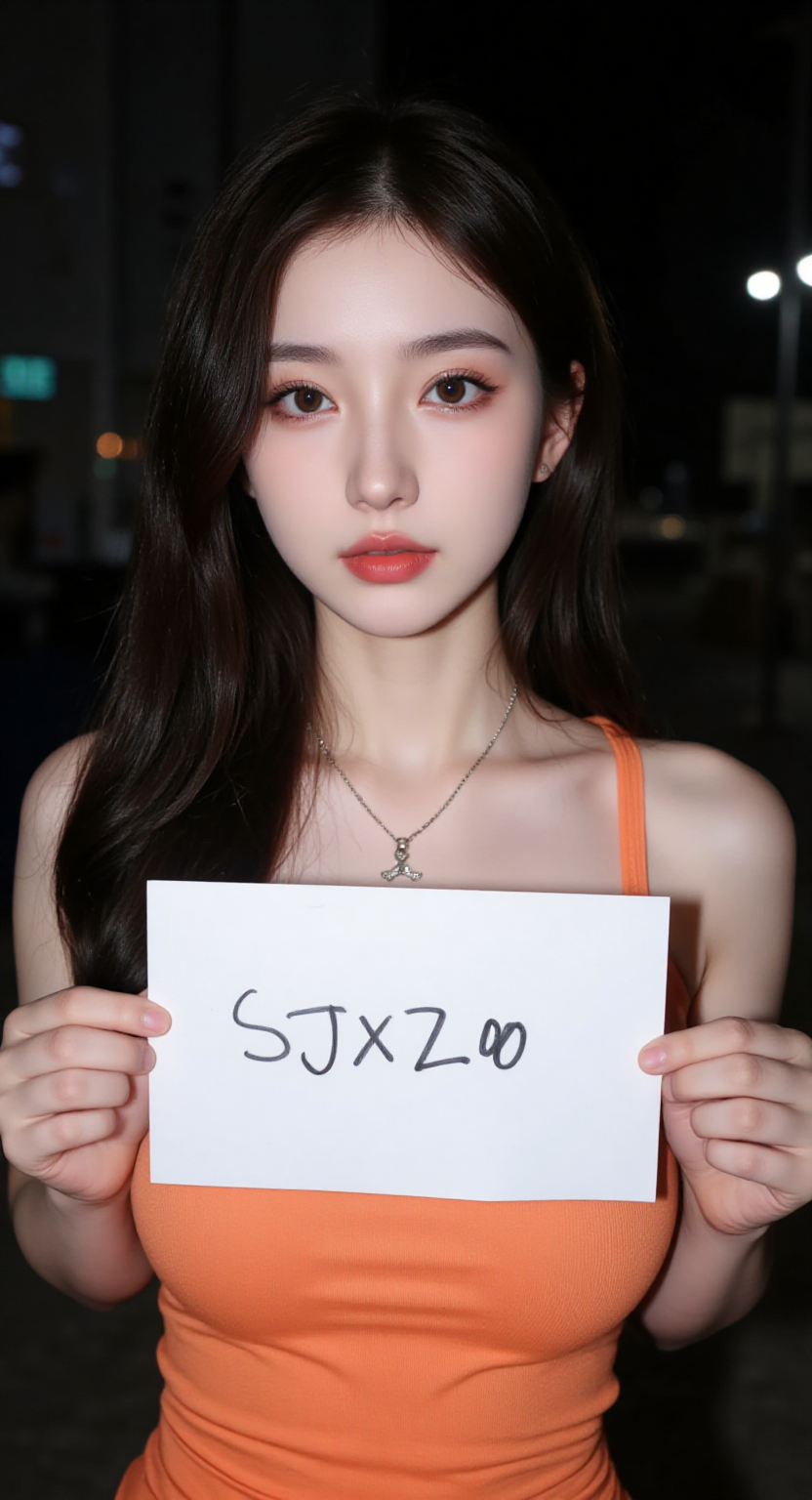
分辨率 1536 x 768 仅需 9.63 秒,而 2304 x 1152只需要 23.75 秒!


加载 lora 也是可以加速的。
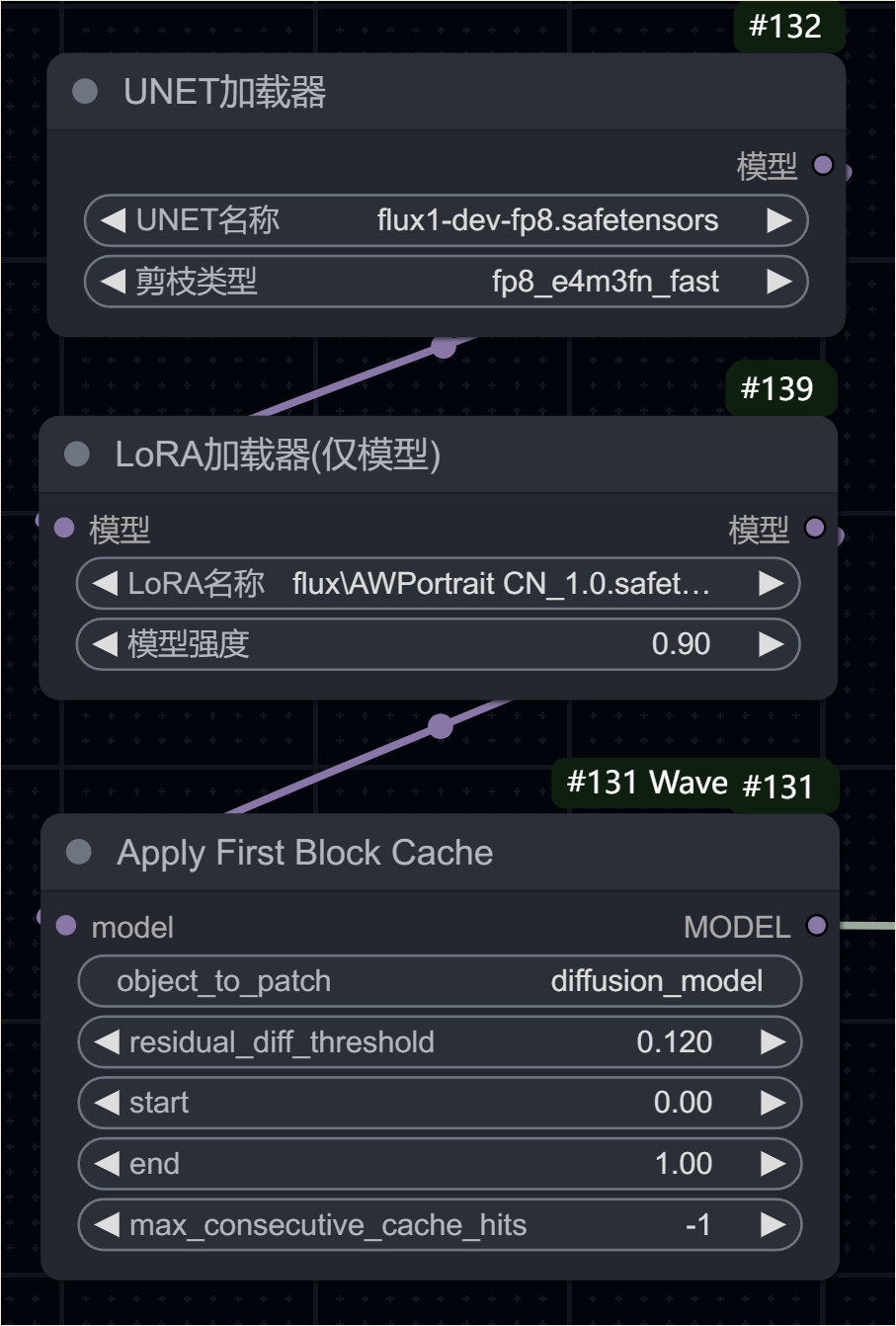

至于 Hunyuan 我就不测试了,各位看官可以看看!
透明背景视频生成 TransPixar
项目介绍
项目地址:https://github.com/wileewang/TransPixar 体验地址:https://huggingface.co/spaces/wileewang/TransPixar
「TransPixar」,它的目标是让现有的文本生成视频的AI模型,也能够生成带有**「透明通道 (alpha channel)」** 的视频。这种带有透明通道的视频格式叫做 「RGBA」。

01.gif
「为什么透明度很重要?」
-
「视觉特效 (VFX):」 透明度是电影、游戏等领域制作特效的关键。它可以让不同的视觉元素自然地叠加在一起,比如把爆炸的火焰叠加到背景画面上,或者让一个虚拟的角色看起来像是真实地站在场景中。
-
「更丰富的创意表达:」 有了透明度,创作者可以制作出更具层次感和想象力的视频内容。
「TransPixar 是怎么做的?」
TransPixar 并没有从零开始创建一个全新的AI模型,而是巧妙地在现有的优秀模型基础上进行改进。你可以把它想象成给一个原本只会画普通画的画家,教他如何画出带有透明效果的图层。
文章中提到了以下几个关键点:
-
「基于现有模型优化:」 TransPixar 基于一种叫做 「diffusion transformer (DiT)」 的AI模型架构。这意味着它利用了现有模型的优点。
-
「加入“透明”指令:」 TransPixar 在模型中引入了专门处理**「透明度」**的指令,就像告诉画家“这里需要画成半透明的”。这些指令可以理解为 「alpha-specific tokens」。
-
「精细微调:」 他们使用了一种叫做 「LoRA-based fine-tuning」 的技术来训练模型,让模型学会如何同时生成正常的彩色画面(RGB)和透明度信息(alpha channel),并且保证两者高度一致。这就像训练画家,让他画出的透明部分恰好对应着画面上的物体,不会出现错位。
-
「优化“注意力”机制:」 模型在生成视频时,会“注意”到画面中的不同部分。TransPixar 对这种“注意力”机制进行了优化,确保模型在生成透明效果时,能够关注到正确的区域,比如物体的边缘和轮廓。
「TransPixar 的优势:」
-
「保留原有能力:」 TransPixar 不仅能生成带有透明度的视频,还能像原来的模型一样生成正常的彩色视频。就像教会画家新技能,但不会让他忘记原本的画法。
-
「透明度和画面高度一致:」 由于是同时生成彩色和透明度信息,TransPixar 生成的视频,其透明部分与画面内容高度匹配,看起来非常自然。
-
「对少量数据也能有效:」 训练生成透明视频的AI模型需要大量的带有透明度标注的数据,而这类数据并不多。TransPixar 的方法即使在训练数据有限的情况下,也能取得不错的效果。
「实际应用:」
有了 TransPixar 这样的技术,未来我们可以更方便地使用AI生成各种带有精美透明特效的视频,比如:
-
「制作更酷炫的视觉特效:」 轻松生成带有真实感烟雾、火焰、水花等特效的视频。
-
「创建互动性更强的虚拟内容:」 比如,在虚拟现实或增强现实场景中,可以生成能够与其他元素自然融合的透明物体。

01.gif
实测效果
提示语:
Gold coins scattered throughout the sky, along with five colored ribbons, shimmering with golden light
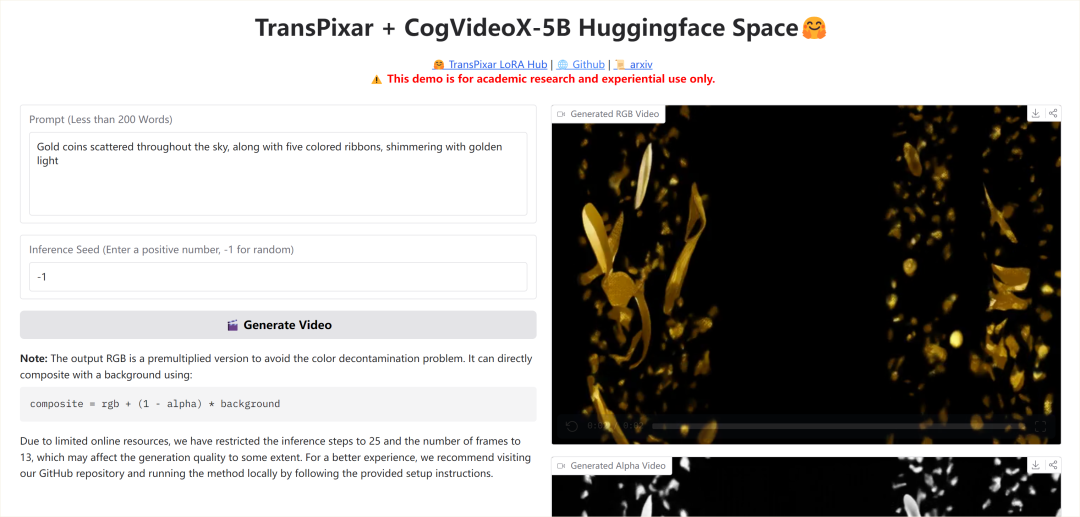
至于合成效果嘛,我还没测试,分辨率可能有点低,作为辅助素材,应该是没问题的。
❝
让我惊讶的是,作为闭源大户Adobe 这次很大方地开源了这个技术(当然,背后有中国团队!)!
❞
Gemini-Search 的开源方案
Google Research,是 google 推出的可以联网搜索的 AI应用,
❝
有些网友戏称:在 Google Research面前,Perplexity 就像个玩具!😂
❞

确实,用过他的人都有惊掉下巴的感叹!

无奈,将近 20 美元的订阅费,我是暂时用不起了,所以,今天介绍平替产品:Gemini-Search。项目地址:https://github.com/ammaarreshi/Gemini-Search
本地部署
项目中有详细介绍,这里简单列一下:
-
克隆存储库:
git clone https://github.com/ammaarreshi/Gemini-Search.git cd Gemini-Search -
安装依赖项:
npm install -
.env在根目录中创建文件:GOOGLE_API_KEY=your_api_key_here -
启动开发服务器:
npm run dev -
打开浏览器并导航至:
http://localhost:3000
对了,需要付费版的 Gemini API,免费版的不行,因为需要调用搜索接口。
❝
注意:因为使用搜索接口,会产生费用,按照 google 的计费规则,约每次 0.25 刀!
❞
我给出了命题 webgl 的新技术趋势,他会根据命题,进行互联网搜索,然后整理成答案。
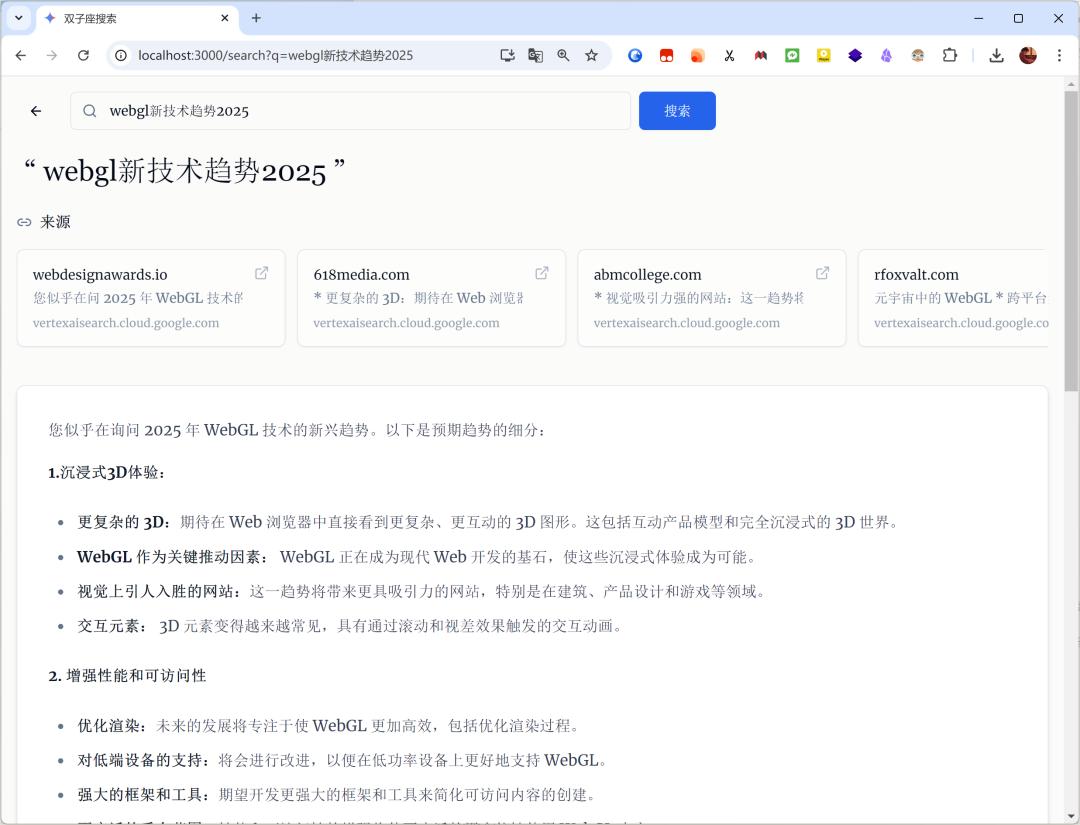
另一个命题:# 研究AI生成3D的技术和趋势
同样结合互联网,给出了一些简介!
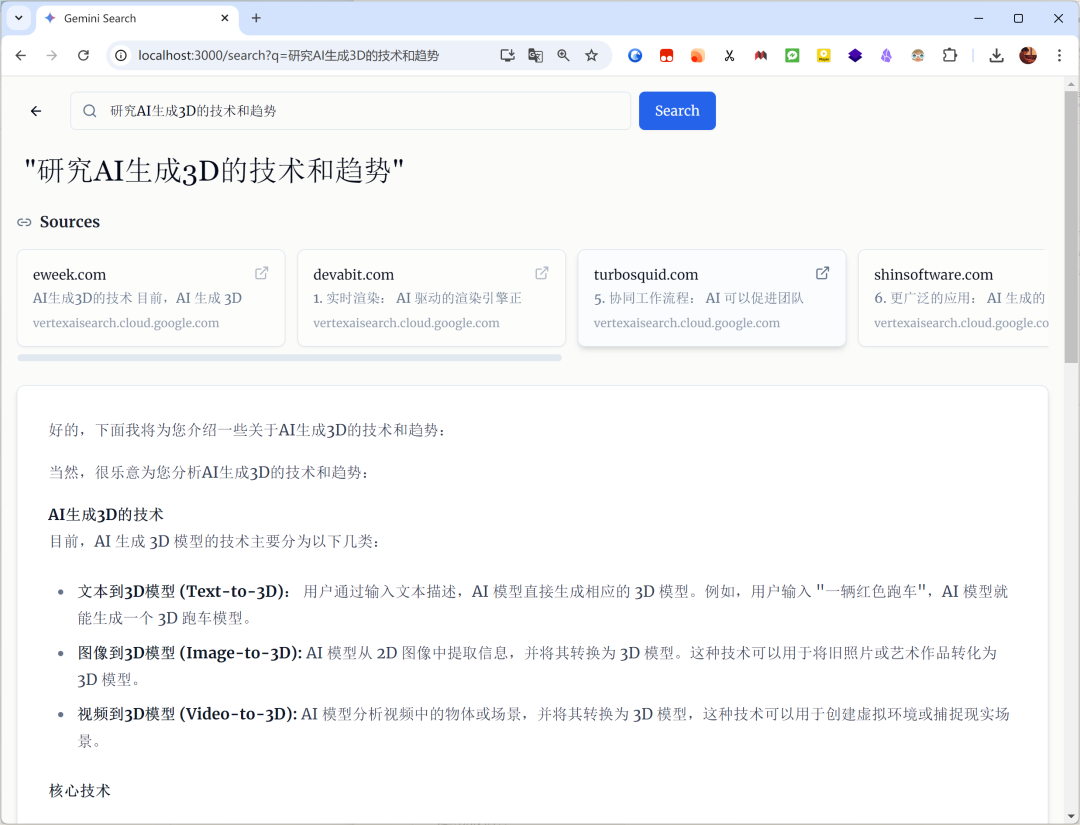
但是,至于效果是否等同于 Google 的 deep search,我囊中羞涩,就不做对比了,各位可以试试!
好,今天就介绍这些,祝大家周末愉快!!
「更多 AI 辅助设计和设计灵感趋势,请关注公众号(设计小站):sjxz 00。」
本文转自 https://mp.weixin.qq.com/s/wNVaShZehh4dMaYVa2ZKyw,如有侵权,请联系删除。
写在最后
SD全套资料,包括汉化安装包、常用模型、插件、关键词提示手册、视频教程等都已经打包好了,无偿分享,有需要的小伙伴可以自取。



感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!
三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
请添加图片描述
若有侵权,请联系删除

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐


 32
32 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)