
一文读懂 AI
这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。:科学家们发现统计效果很好后,扩大了语料库,加入了矩阵、向量计算(这不是本文重点,但可以是下一篇)和人工设计特征(早期有,后期减少),计算机硬件发展为该阶段的提供
- 2022年11月30日,OpenAI发布了ChatGPT,2023年3月15日,GPT-4引发全球轰动,让世界上很多人认识了ai这个词。如今已过去快两年半,AI产品层出不穷,如GPT-4、DeepSeek、Cursor、自动驾驶等,但很多人仍对AI知之甚少,尤其是“NLP”,“大模型”、“机器学习”和“深度学习”等术语让人困惑🤔。
- 对于普通人来说,AI是否会取代工作😨?网络上说除双一流以外学校搞不了AI又是什么情况😩?AI产业是否像以前一样互联网程序员一样?看一些科普视频,上来就是一顿“Attention”、“神经元”、“涌现现象”等术语,让人感觉是在介绍AI某个领域中的一个名词,本文将通俗易懂地解释AI,让什么都不懂的小白也能变成AI概念的糕手,糕手,糕糕手😎
一:区分AI技术与AI应用
神经网络是机器学习的一部分,这里作例子
-
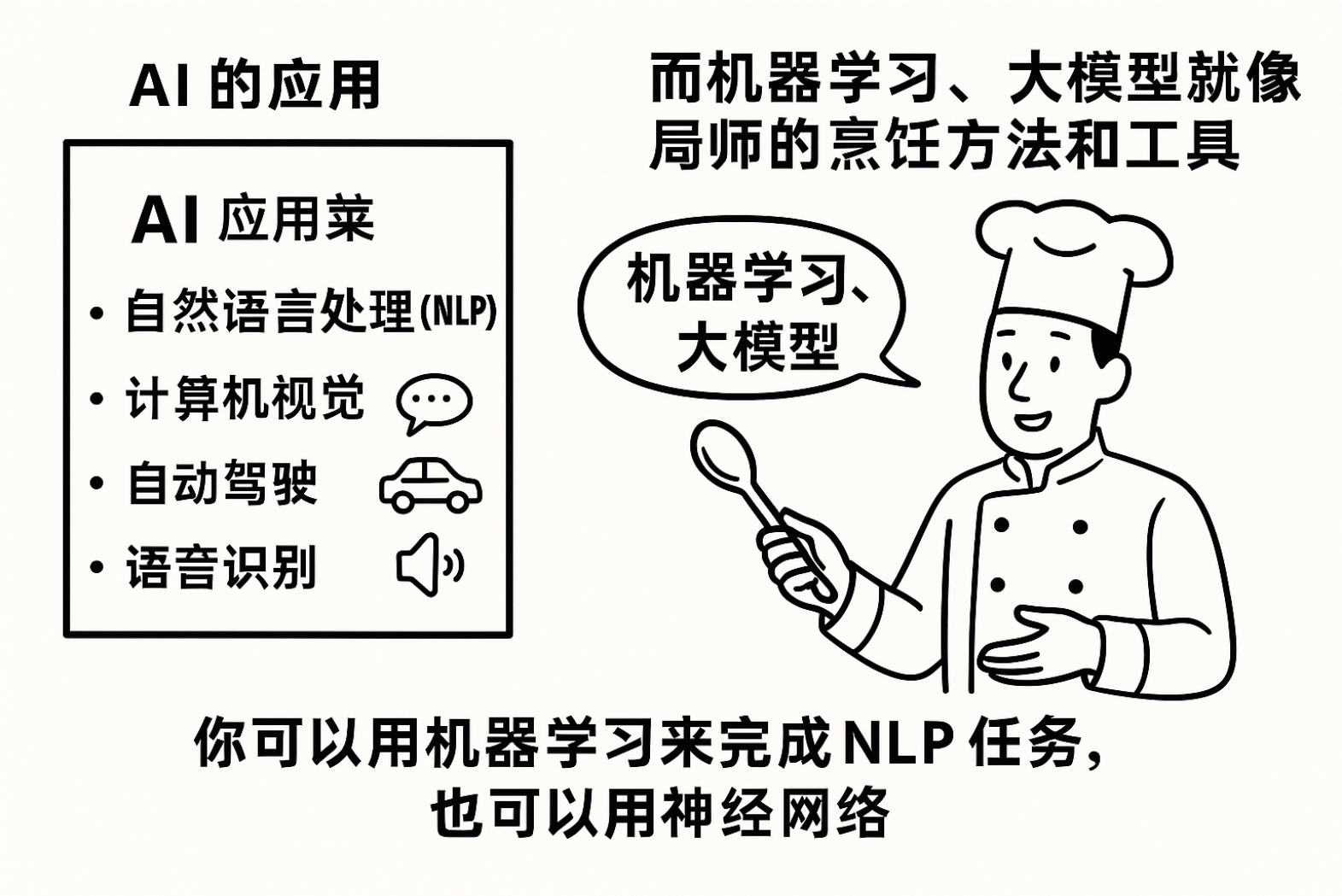
AI 的应用有:自然语言处理(NLP)、计算机视觉、自动驾驶、语音识别等。而机器学习、大语言模型等是实现这些应用的技术手段。
-
AI 的应用 就像是 餐馆的菜单,上面有不同的菜肴(如自然语言处理、计算机视觉等),这些菜肴是顾客需要的服务或产品。
而 **机器学习、大模型就像是 厨师的烹饪方法和工具,它们是实现这些菜肴所用的手段。**你可以用机器来完成 NLP 任务,也可以用神经网做。
二:ChatGPT、DeepSeek是什么东西?
-
我们已经知道AI有不同的应用,而ChatGPT与DeepSeek都是NLP领域的大型语言模型(Large Language Model, LLM)。(NLP中文意思:自然语言处理。不要忘了哦)
-
这又引出了新问题:NLP是什么?大型语言模型又是什么?
NLP是什么?
-
翻译人类语言让计算机听懂就是NLP,其中重点是听懂,而不是你说“吃饭了嘛”,计算机也说“吃饭了嘛”。计算机明白了你在问它吃没吃饭,于是计算机回答:我是机器不需要吃饭😅,或者我打算过一会儿再吃(充电)🔋。
很难想象,没思想的计算机怎么能听懂有思想的人说的话🤔,这其实是个困扰了几十年的问题。
| 阶段 | 时间范围 | 技术特点 | 代表方法/模型 | 应用举例 |
|---|---|---|---|---|
| 规则驱动阶段 | 1950s–1980s | 基于人工编写规则,语言学为主 | 句法规则、词典匹配 | 早期机器翻译、图灵测试 |
| 统计学习阶段 | 1990s–2010 | 依赖大规模语料,采用统计与概率模型 | N-gram、HMM、CRF | 情感分析、搜索引擎、拼写纠正 |
| 神经网络阶段 | 2010–2017 | 引入深度学习,提升语言理解建模能力 | Word2Vec、RNN、LSTM、Seq2Seq | 智能问答、语音识别 |
| 预训练大模型阶段 | 2018至今 | 采用Transformer架构,模型参数大规模增长 | BERT、GPT、T5、ChatGPT、DeepSeek等 | 多任务通用语言处理、对话系统 |
上面这表AI做的,时间范围可能有问题,但阶段没问题
-
规则驱动阶段:意思就是让机器明白主谓宾定状补、什么名词动词名词短语……但很显然,套一万个规则也难以让一台只会010101的机器明白你在说什么。
-
统计学习阶段:这时候,科学家们将统计学引入来解决问题。将人们日常对话收集成库(语料库),通过统计发现对话数据中的规律来实现计算机“理解”人说的话。
- 在第三小结,会构建一个简单的N-Gram模型,让你大概知道什么是模型与统计学习阶段是在干什么。所以先别急。
-
神经网络阶段:科学家们发现统计效果很好后,扩大了语料库,加入了矩阵、向量计算(这不是本文重点,但可以是下一篇)和人工设计特征(早期有,后期减少),计算机硬件发展为该阶段的提供算力支持。
-
预训练大模型阶段:
- 先说大模型,大模型就是有参数量大(亿级甚至千亿级)、数据量大、算力需求高特点的神经网络模型。
- 预训练:就像是一个体育比赛的人,不管这个人参与什么体育项目,先把体能练好了,再训练具体项目。
| 阶段 | 目的 | 数据类型 | 示例任务 |
|---|---|---|---|
| 预训练 | 学通用语言能力 | 无标注语料 | 预测遮盖词、下一个词等 |
| 微调 | 学任务特定能力 | 有标注数据 | 分类、翻译、问答等 |

大型语言模型是什么?
- 你应该已经知道了,大型语言模型是一种大模型。
三:一个基础NLP模型实现:N-Gram模型
-
-Gram 模型是一种基于统计的语言模型,其核心思想是:一个词(或字)出现的概率,只依赖于它前面的 n−1n-1n−1 个词(或字),用来解决已知的上下文生成合理的文本问题。
-
工作原理:
- 将文本序列拆分为连续的 N 个词(或字)的组合,称为“N-Gram”。
- 通过统计语料中各个 N-Gram 出现的频率,估计下一个词(或字)出现的概率。
-
计算公式
-
模型流程
- 收集语料
- 切分为 N-Gram
- 统计每种 N-Gram 出现频率
- 根据频率计算概率
- 根据历史词语预测下一个词

from collections import defaultdict, Counter
import random
# 第一步:创建语料库
corpus = [
"我早上去了图书馆",
"我早上听了一节英语课",
"我中午看了一部电影",
"我中午睡了一会儿",
"我晚上写了一篇作文",
"我晚上复习了功课",
]
# 第二步:分词函数(按字分词,这里只是按照字符分词)
def split_words(text):
return [char for char in text]
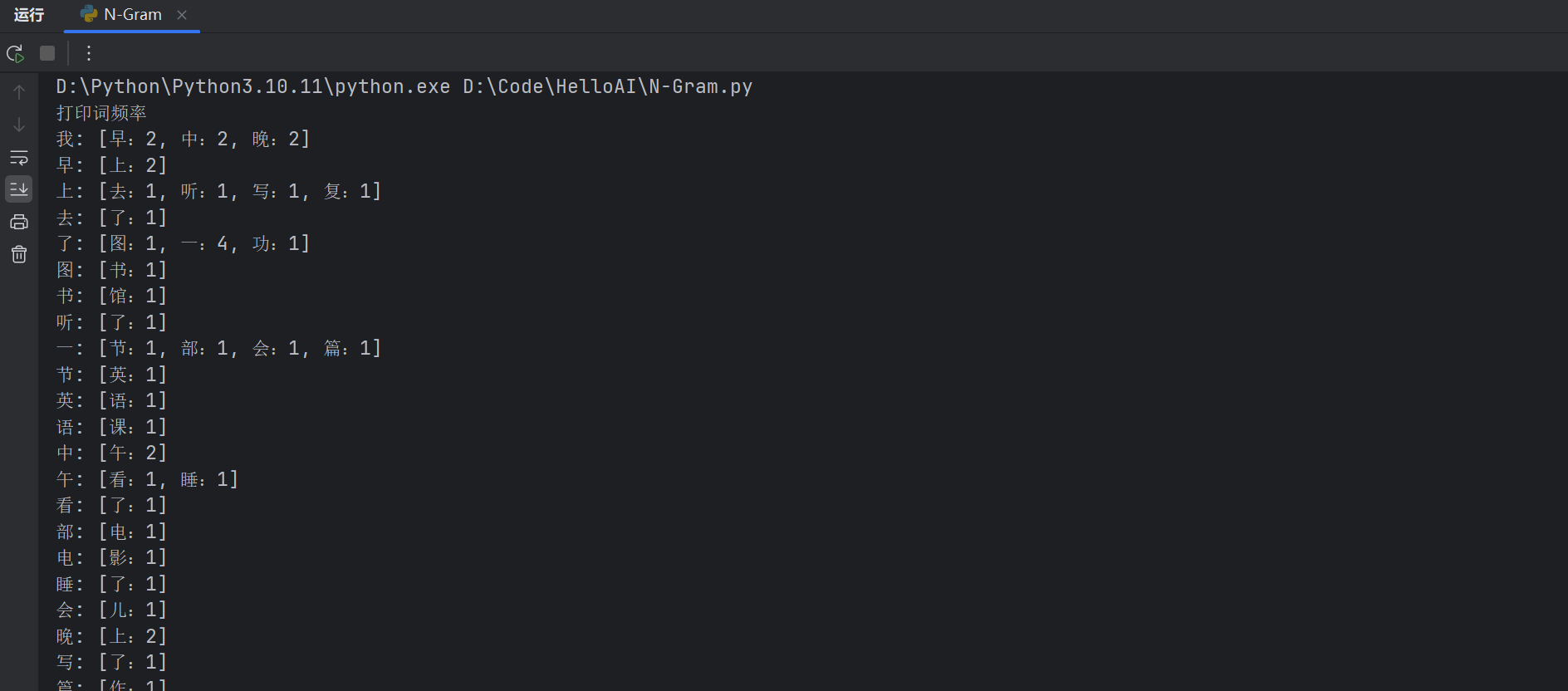
# 第三步:统计Bigram词频(Bigram 是一个N-Gram 模型中的特例,其中N=2,即考虑连续的两个词或字符的组合。)
bigram_freq = defaultdict(Counter)
for sentence in corpus:
words = split_words(sentence)
for i in range(len(words) - 1):
first, second = words[i], words[i+1]
bigram_freq[first][second] += 1
# 打印词频率
# print("打印词频率")
# for first, counter in bigram_freq.items():
# freq_list = [f"{second}:{freq}" for second, freq in counter.items()]
# print(f"{first}: [{', '.join(freq_list)}]")
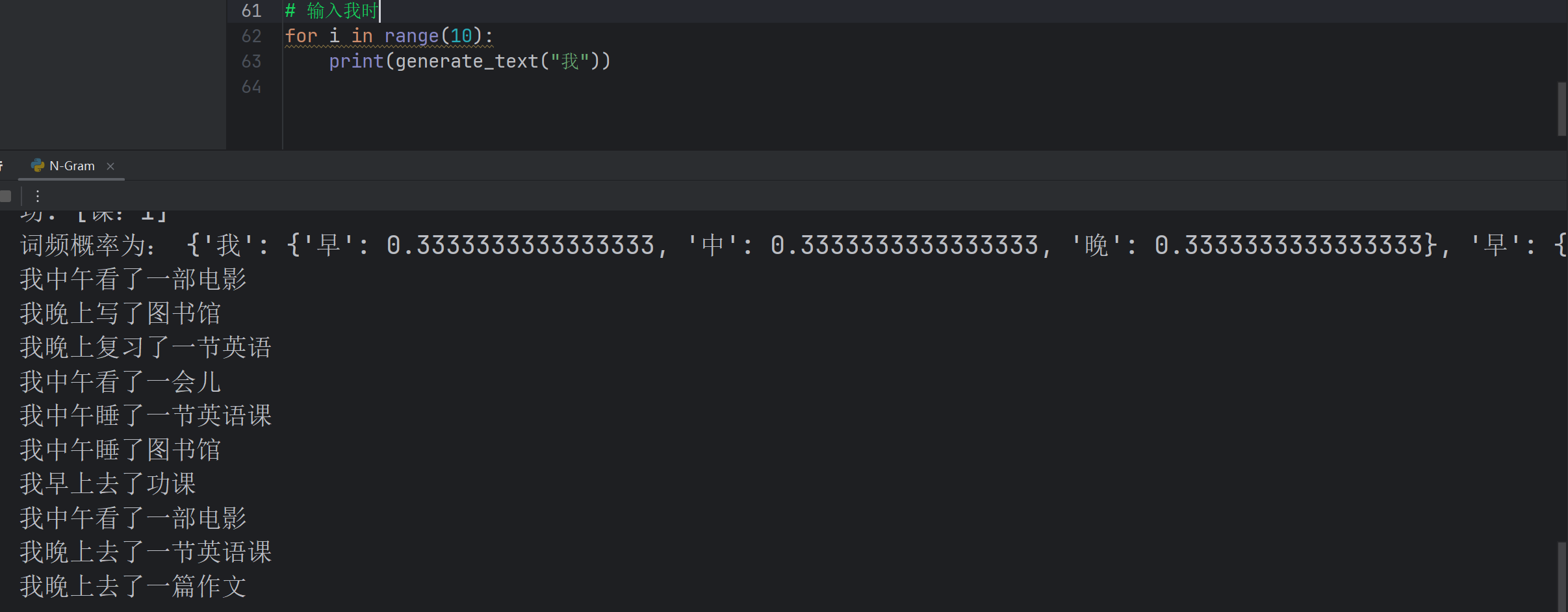
# 第四步:计算Bigram概率(转为概率分布)
bigram_prob = {}
for first, counter in bigram_freq.items():
total = sum(counter.values())
bigram_prob[first] = {second: count / total for second, count in counter.items()}
# print("词频概率为:", bigram_prob)
# 第五步:根据前缀生成下一个字
def predict_next_char(prev_char):
if prev_char not in bigram_prob:
return None
candidates = list(bigram_prob[prev_char].items())
chars, probs = zip(*candidates)
return random.choices(chars, probs)[0]
# 第六步:输入前缀,生成文本
def generate_text(start_char, length=10):
result = [start_char]
current = start_char
for _ in range(length - 1):
next_char = predict_next_char(current)
if not next_char:
break
result.append(next_char)
current = next_char
return ''.join(result)
# 示例
print(generate_text("我"))
- 代码不难,不懂问AI就好了。
- https://github.com/Qiuner/HelloAI ,这里会陆续复现几个ai发展的经典模型
每个词后面出现词次数
出现词次数转化为概率与给定一个词后生成的连续文本
- 可以看到,出现了我早晨去了功课这样不存在词库的句子
- 实际要做的更多
尾与推荐
- N-Gram模型是不是让你觉得非常简单?简单就对了,**这是1913年提出的模型,在1950年被引入NLP。**而现在是2025年,AI已经过Word2Vec 、RNN、 HMM、Transformer、BERT、GPT……等模型,且上面这些只是AI中NLP领域的。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。
掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码或者点击以下链接都可以免费领取【保证100%免费】


GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐


 11
11 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)