
【论文笔记】【视频异常检测】【CVPR2024】Open-Vocabulary Video Anomaly Detection
动机
第一篇开放世界VAD(OVVAD),也就是训练阶段用已知异常,测试阶段投入未知异常。没有前人做过这项工作,于是这篇论文就去做了。
摘要是论文的精华,其中的内容分布决定了论文的重心。论文摘要8句话,前4句话都在说“OVVAD”(开放集VAD)的事情,后面3句话是对方法的介绍,最后一句话是标准的“我们做了实验”。
该论文第一个提出“OVVAD”,同时花了篇幅去描写,说明论文认为他们提的这个领域很新而且很重要。那么必然会在后面(比如引言部分)去详细解释为什么这“第一个”很重要(惯用手段,提出“第一个XXX”必须要解释为什么这“第一个”重要,不是随便什么第一个都能投论文)而从引言可以看出,论文对于OVVAD和方法的描述是六四开。
对于方法,论文摘要是这样说的:
1. “我们提出了一种将 OVVAD 任务解耦为两个互补子任务的模型:类别无关的异常检测与类别相关的异常分类,并对二者进行联合优化。”
2. “设计了一个语义知识注入模块,从大语言模型中引入语义知识以提升检测能力;同时设计了一个新颖的异常合成模块,借助大型视觉生成模型生成伪造的未见异常视频”
相关工作部分也得贴合OVVAD,先是从其他方法(弱监督VAD,半监督VAD)到开放集VAD的方法。
论文方法
1. 问题陈述
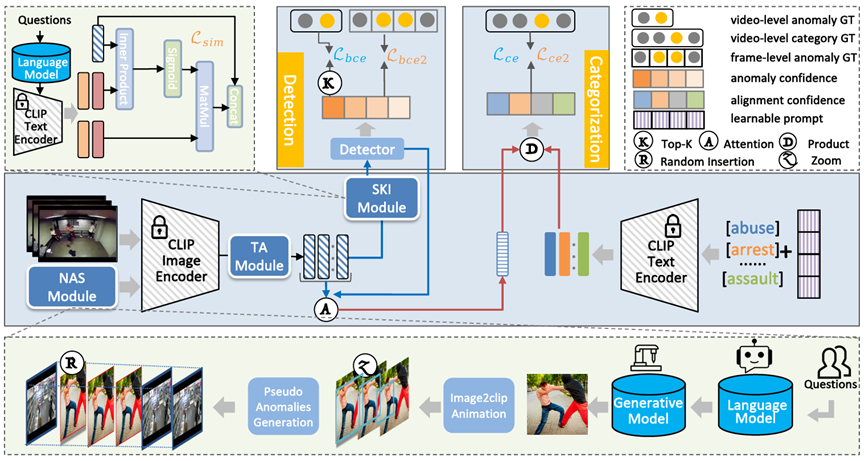
论文在问题陈述部分,是一套改进的“弱监督VAD”的问题陈述。
其他的弱监督VAD的论文一般会解释其任务为:“训练阶段给出正常样本和异常样本,异常样本的标注是视频级,目的是对每一帧给出异常分数”。
这篇论文的问题陈述结合了OVVAD的概念,在之前的基础上,加上了一句:“训练阶段存在测试阶段没见过的异常。”
2. TA模块
这个模块是用来提取时序信息的。为什么不用前人的提取时序信息的模块呢?论文认为前人的模块因为参数多,所以会在数据集上过拟合,对于未知类别泛化性弱。所以论文提出了一个没有参数的提取时序信息的方法
论文首先把所有视频帧用CLIP给提取特征得到,但是CLIP 提取的视频帧特征不带有时序关系,所以论文就想了一个办法来获取这个时序关系。
一个很简单的做法就是把当前帧的特征和前后帧相加就行了,这样这一帧就考虑到了其他帧的信息。
但是由于距离当前帧时间很久远的帧和当前帧的时序关系比较小,所以在相加的时候就要考虑权重。这个权重怎么获得呢?
就通过当前帧和前后帧之间的时间距离来,就是当前帧比如是第 帧,那么它和第
帧的时间距离就是
。
然后定义一个超参数 作为衰减量,衰减量越低,就代表越要把和当前帧时间长的帧考虑进来。所以论文中定义了一个adjacency matrix如下,用来表示前后帧位置信息:
而为了获取权重,就是和为1,常见的做法是 softmax,即 ,而且softmax还有让小的越小,大的越大的优势,更适合这个任务。
然后把这个结果作为权重,对加权之后得到
对每一帧,都可以计算一个 ,考虑到不同帧计算的结果的数量级可能有较大差异,论文把每个计算结果统一做了一下归一化
,就得到了论文中的这个公式:
这样,每个clip提取的特征就获取了上下文信息。
3. SKI模块
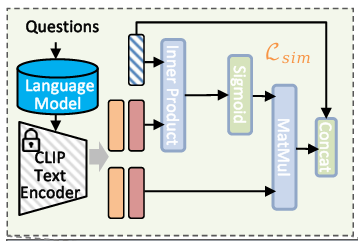
为了让模型也具备“常识”去判断异常,论文首先用大语言模型(LLM)生成一系列与正常场景和异常场景相关的词汇(并非随便生成,而是基于提示词获取常见场景如“街道”、“公园”、异常场景如“爆炸”、“火光”),再用 CLIP 的文本编码器把它们转成与视觉特征同维度的向量。
就是说论文自定义了一个词表,然后用大模型
生成了一堆词汇之后用CLIP提取了这些词的特征
:(就是论文的这个公式)
所以其实可以认为这里的词特征全是预定义的,不是训练可得(修正)的。
然后这个词特征就会和之前提取的那个特征 进行拼接,这样一来,每一帧就既有文本信息,又有位置信息了。但是这样预定义的词特征可以直接拿来用吗?如果可以的话,那么任何提取到的特征,都可以拼接这样一个预定义的
从而获得文本特征。
也不是说不行,不过肯定有更好的解决方法吧。没错,那就是把 和
结合起来,更新
使得对于不同的特征
有不同的
,这样更符合现实。这个更新后的
就叫做
怎么更新呢?就是说怎么把 和
结合起来呢?一个万能通法:加权。不过这里论文的操作只是说和“加权”很相似,并不是真的加权,更像是一种“筛选”。
比如说,之前预定义的 这个特征中包含“打、砸、抢”三个词特征,但是当前视频帧只有“打、砸”这俩个语义信息,那么就要让“打、砸”的“权重”高,“抢”的权重低。所以,这个时候不用 softmax,而是用 sigmoid 是最好的。
先简单地把 和
做一个余弦相似(
),然后sigmoid取得“权重”(
),最后把权重赋给
完成筛选。如果短语过多,那么最后的值可能过大,所以除以短语总数
来平滑,就得到了论文里的这个公式:
将更新后的词特征 与原始帧特征拼接之后,送入检测器,以此融合视觉与语义信息,提升异常识别效果。
4. NAS模块

这部分很好懂,就是人为设计Prompt之后给到大模型,让大模型生成异常场景描述,然后基于这个描述让AIGC生成一堆视频帧,然后把这堆视频帧按照时间顺序拼接成视频片段之后,随机插入到原视频中,这样就获得了“未知异常”。
为什么用AIGC生成伪异常呢?因为论文说,AIGC生成水平很强,和现实差不多(但是方法中展示的图,这俩人手都粘一块儿了,脸都扭曲成异型了,确实算新型异常,就是太不现实。笔者认为:不如用UBNormal数据集的异常插进去,或者自己用诸如WatchDog等虚拟软件等人为制作一点异常)
5. 目标函数
5.1 训练阶段 - 不用之前AIGC生成的伪标签
论文提出的方法要做两件事:检测异常、检测类别。
在检测异常方面,在不使用之前AIGC生成的伪标签的前提下,就和一般的WVAD方法差不多:为每一帧计算了异常分数之后取 TOP-K 计算交叉熵损失
在检测类别方面,论文用了一个transformer的检测器,对每个类别输出了一个置信分数 ,然后把这个置信分数用softmax输出成权重之后,给原来的
加权:
这个加权后的特征被用来和类别词向量 做点积,最后和真正的类别词向量算交叉熵损失,以期让模型能分辨出正常和异常的类别。
5.2 训练阶段 - 使用之前AIGC生成的伪标签
由于是手动生成的数据,所以可以做全监督。在检测异常方面,论文依旧采用交叉熵损失 ,只不过使用的标签是帧级的全监督的标签。
在检测类别方面,和之前的区别仅仅只是GT多了AIGC生成的未知类别。于是最终损失函数(目标函数)如下:

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)