
构建一个视觉Transformer 模型
基于自我注意的 transformer 模型由 Vaswani 等人在 2017 年的论文 Attention Is All You Need 中首次提出,并已广泛用于自然语言处理。transformer 模型是 OpenAI 用于创建 ChatGPT 的模型。Transformer 不仅适用于文本,也适用于图像,基本上也适用于任何顺序数据。本文将介绍视觉transformer 模型如何构建。
文章目录
一、说明
基于自我注意的 transformer 模型由 Vaswani 等人在 2017 年的论文 Attention Is All You Need 中首次提出,并已广泛用于自然语言处理。transformer 模型是 OpenAI 用于创建 ChatGPT 的模型。Transformer 不仅适用于文本,也适用于图像,基本上也适用于任何顺序数据。本文将介绍视觉transformer 模型如何构建。
二、从头开始
在本教程中,我们将从头开始构建一个视觉转换器模型,并在 MNIST 数据集上进行测试,MNIST 数据集是一组手写数字,已成为机器学习中的标准基准。可以在此处找到包含教程中代码的笔记本。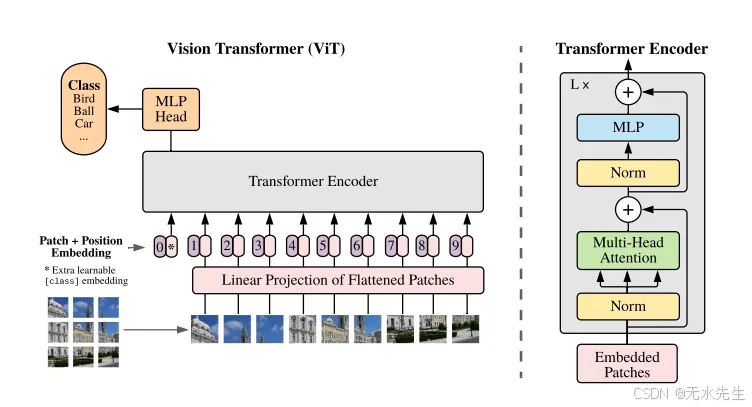
图 1:Vision Transformer 模型概述
2. 1 导入库和模块
import torch
import torch.nn as nn
import torchvision.transforms as T
from torch.optim import Adam
from torchvision.datasets.mnist import MNIST
from torch.utils.data import DataLoader
import numpy as np
我们将使用 PyTorch 构建我们的 vision transformer,因此我们需要导入库以及我们将在本教程中使用的其他库。
import torch
import torch.nn as nn
我们还需要在 torchvision.transforms 中导入,以便调整输入图像的大小并将其转换为张量。调整输入图像的大小是可选的。您只需要确保图像大小可以被补丁大小整除。
import torchvision.transforms as T
我们将使用 Adam 作为我们的优化器,因此我们需要从 torch.optim 导入它。
from torch.optim import Adam
我们将从 torchvision 导入本教程中使用的 MNIST 数据集。我们将使用 PyTorch 的 DataLoader 来帮助加载数据,因此我们也需要将其导入。
from torchvision.datasets.mnist import MNIST
from torch.utils.data import DataLoader
最后,我们需要导入 numpy,在创建位置编码时,我们将使用它来执行 sin 和 cosine。
import numpy as np
2.2 补丁嵌入
class PatchEmbedding(nn.Module):
def __init__(self, d_model, img_size, patch_size, n_channels):
super().__init__()
self.d_model = d_model # Dimensionality of Model
self.img_size = img_size # Image Size
self.patch_size = patch_size # Patch Size
self.n_channels = n_channels # Number of Channels
self.linear_project = nn.Conv2d(self.n_channels, self.d_model, kernel_size=self.patch_size, stride=self.patch_size)
# B: Batch Size
# C: Image Channels
# H: Image Height
# W: Image Width
# P_col: Patch Column
# P_row: Patch Row
def forward(self, x):
x = self.linear_project(x) # (B, C, H, W) -> (B, d_model, P_col, P_row)
x = x.flatten(2) # (B, d_model, P_col, P_row) -> (B, d_model, P)
x = x.transpose(1, 2) # (B, d_model, P) -> (B, P, d_model)
return x
创建 Vision Transformer 的第一步是将输入图像分割成 patch,并创建这些 patchs 的线性嵌入序列。我们能够通过使用 PyTorch 的 Conv2d 方法来实现这一点。
Conv2d 方法获取输入图像,将它们分割成块,并提供大小等于模型宽度的线性投影。通过将 kernel_size 和 stride 设置为 patch size,我们可以确保补丁大小正确且没有重叠。
self.linear_project = nn.Conv2d(self.n_channels, self.d_model, kernel_size=self.patch_size, stride=self.patch_size)
在 forward 方法中,我们通过 linear_project/Conv2D 方法传递形状为 (B, C, H, W) 的输入,并接收形状为 (B, d_model, P_col, P_row) 的输出。
def forward(self, x):
x = self.linear_project(x) # (B, C, H, W) -> (B, d_model, P_col, P_row)
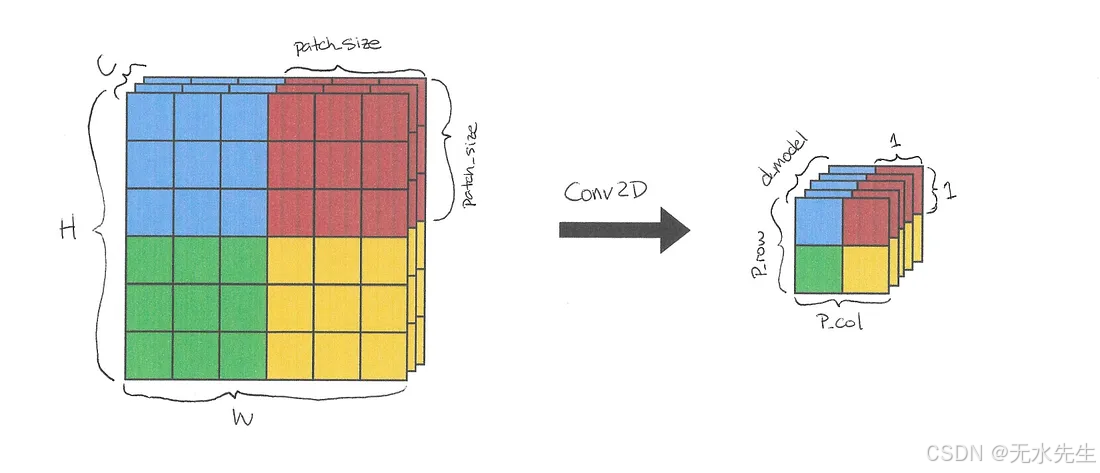
图 2:应用于单个图像的 Conv2D。每种颜色都表示元素属于哪个补丁
我们使用 flatten 方法将 patch 列和 patch 行维度合并为单个 patch 维度,得到的形状为 (B, d_model, P)
x = x.flatten(2) # (B, d_model, P_col, P_row) -> (B, d_model, P)
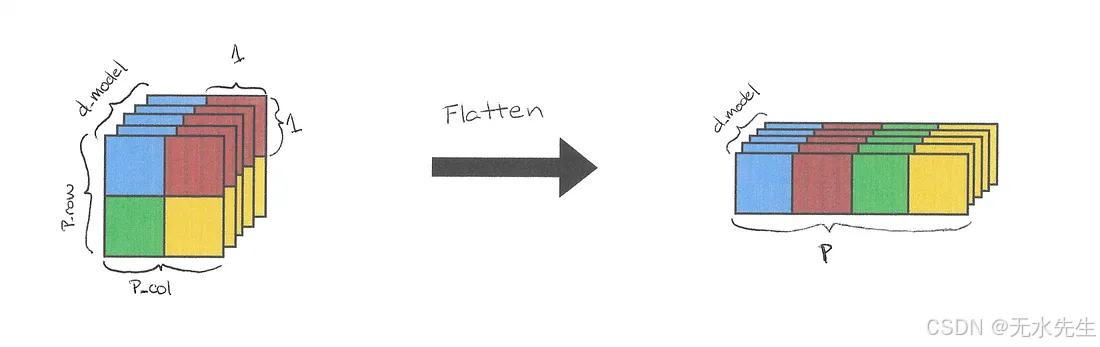
图 3:应用于 Conv2d 输出的 Flatten。
最后,我们使用 transpose 方法切换 d_model 和 patch 维度,以获得 (B, P, d_model) 的形状。
x = x.transpose(-2, -1) # (B, d_model, P) -> (B, P, d_model)
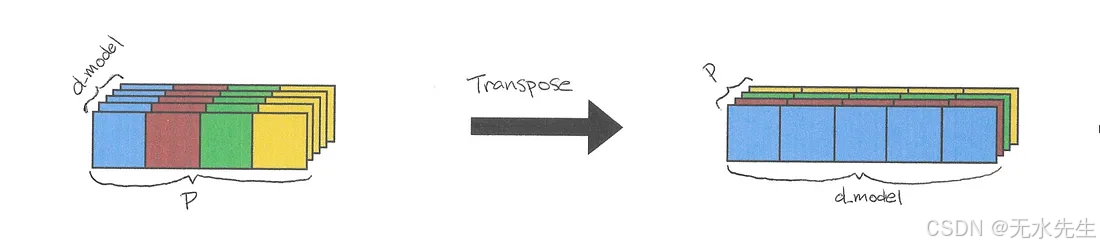
图 4:应用于展平输出的转置
这实际上是相当多的解读。查看本文,它从简单的展开(剪切图像)和在补丁上使用线性变换开始发展了这一步。
用二维卷积和补丁嵌入两个方法种,两种方法都有相同的结果,卷积运算符在显卡上提供更紧凑的表示和更高效的计算实现。
2.3 类标记和位置编码
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super().__init__()
self.cls_token = nn.Parameter(torch.randn(1, 1, d_model)) # Classification Token
# Creating positional encoding
pe = torch.zeros(max_seq_length, d_model)
for pos in range(max_seq_length):
for i in range(d_model):
if i % 2 == 0:
pe[pos][i] = np.sin(pos/(10000 ** (i/d_model)))
else:
pe[pos][i] = np.cos(pos/(10000 ** ((i-1)/d_model)))
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
# Expand to have class token for every image in batch
tokens_batch = self.cls_token.expand(x.size()[0], -1, -1)
# Adding class tokens to the beginning of each embedding
x = torch.cat((tokens_batch,x), dim=1)
# Add positional encoding to embeddings
x = x + self.pe
return x
Vision Transformer 模型使用标准方法,将可学习的分类标记添加到补丁嵌入中,以便执行分类。
self.cls_token = nn.Parameter(torch.randn(1, 1, d_model))
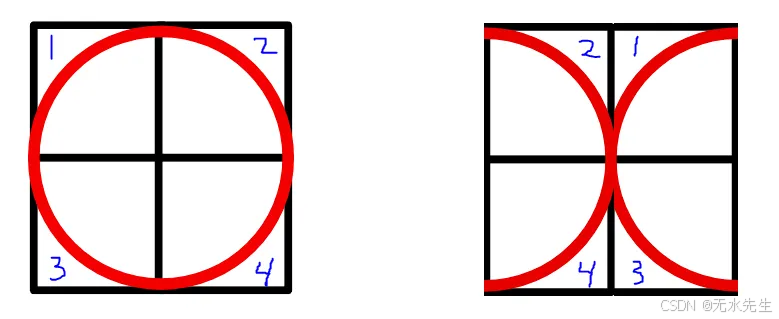
图 5:更改补丁顺序可以将 O 更改为 X
与像 LSTM 这样按顺序接受 embedding 的模型不同,transformer 并行接受 embedding。虽然这提高了速度,但 transformer 不知道 order sequence 应该是什么。这是一个问题,因为更改图像的补丁顺序很可能会改变图像的内容及其应该表示的内容。图 5 就是一个例子,它表明更改图像的补丁顺序可以将图像从 O 更改为更类似于 X 的值。为了解决这个问题,需要将位置编码添加到补丁嵌入中。每个位置编码对于它所代表的位置都是唯一的,这允许模型识别每个嵌入应该去的位置。为了将位置编码添加到嵌入中,它们必须具有相同的维度 d_model。我们使用图 6 中的方程来获得位置编码。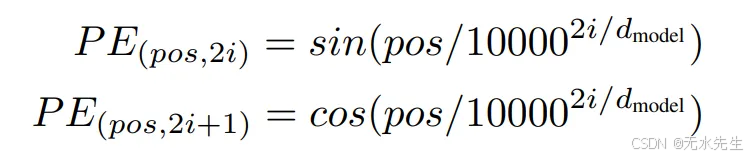
图 6:位置编码方程
pe = torch.zeros(max_seq_length, d_model)
for pos in range(max_seq_length):
for i in range(d_model):
if i % 2 == 0:
pe[pos][i] = np.sin(pos/(10000 ** (i/d_model)))
else:
pe[pos][i] = np.cos(pos/(10000 ** ((i-1)/d_model)))
self.register_buffer('pe', pe.unsqueeze(0))
在 forward 方法中,输入是多张图片的一批 patch 嵌入。例如,一个 32x32 的图像可以分解成 16 个 8x8 大小的块。在此max_seq_length需要为 16+1=17 才能创建足够的位置嵌入,每个 patch 一个,类 token 一个。
因此,我们需要使用 expand 函数,以便使用 self.cls_token 为批处理中的每个图像创建类令牌。当您一样,注意力模型会将有关整个序列的信息编码到序列中的每个标记中。由于每个标记都受其自身信息的影响,因此类标记会创建一个序列中所有标记的独立摘要。
def forward(self, x):
tokens_batch = self.cls_token.expand(x.size()[0], -1, -1)
然后,使用 torch.cat 方法将这些分类标记添加到每个 patch 嵌入的开头。
x = torch.cat((tokens_batch,x), dim=1)
位置编码在输出之前添加。
x = x + self.pe
return x
这是添加类标记之前和之后的数据外观:
左图:使用 Conv2D作将 32x32 MNIST 图像分成 16 个 8x8 补丁。右图:添加位置编码和类标记后的 16 个图像补丁,使用随机数据初始化。
请注意,我们使用 64 个内核初始化了 Conv2D作,每个内核每个补丁只占用一个像素,以免图像失真。深入解释 Conv2D 的文章链接得更远。
三、构建注意头
class AttentionHead(nn.Module):
def __init__(self, d_model, head_size):
super().__init__()
self.head_size = head_size
self.query = nn.Linear(d_model, head_size)
self.key = nn.Linear(d_model, head_size)
self.value = nn.Linear(d_model, head_size)
def forward(self, x):
# Obtaining Queries, Keys, and Values
Q = self.query(x)
K = self.key(x)
V = self.value(x)
# Dot Product of Queries and Keys
attention = Q @ K.transpose(-2,-1)
# Scaling
attention = attention / (self.head_size ** 0.5)
attention = torch.softmax(attention, dim=-1)
attention = attention @ V
return attention
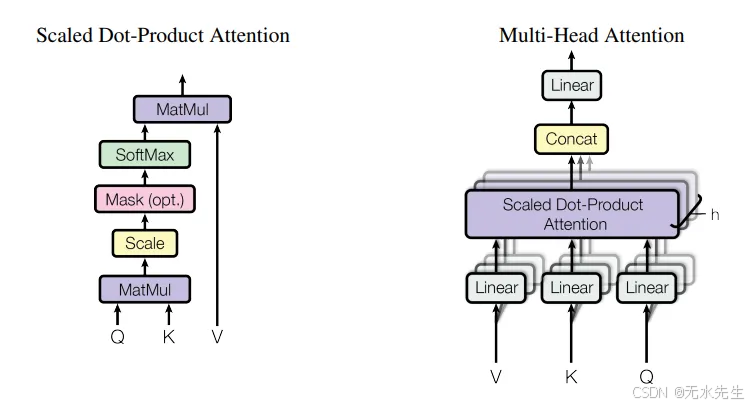
图 7:缩放的点积注意力图和多头注意力图
视觉转换器使用注意力,这是一种通信机制,允许模型专注于图像的重要部分。注意力分数可以使用图 8 中的方程计算。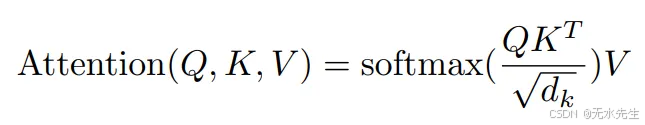
图 8:注意力方程
计算 attention 的第一步是获取 token 的 queries、key 和 value。令牌的查询是令牌要查找的内容,键是令牌包含的内容,值是令牌之间通信的内容。查询、键和值可以通过线性模块传递令牌来计算。
def forward(self, x):
# Obtaining Queries, Keys, and Values
Q = self.query(x)
K = self.key(x)
V = self.value(x)
我们能够通过获取 queries 和 key 的点积来获取序列中 token 之间的关系。
# Dot Product of Queries and Keys
attention = Q @ K.transpose(-2,-1)
我们需要缩放这些值以控制初始化时的方差,以便 Token 能够聚合来自多个其他 Token 的信息。缩放是通过将点积除以注意力头大小的平方根来应用的。
attention = attention / (self.head_size ** 0.5)
然后,我们需要在缩放的点积上应用软最大值。
attention = torch.softmax(attention, dim=-1)
最后,我们需要获取 soft max 和 values 矩阵之间的点积。这实质上是在相应的 token 之间传递信息。
attention = attention @ V
return attention
四、构建多头注意头
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
self.head_size = d_model // n_heads
self.W_o = nn.Linear(d_model, d_model)
self.heads = nn.ModuleList([AttentionHead(d_model, self.head_size) for _ in range(n_heads)])
def forward(self, x):
# Combine attention heads
out = torch.cat([head(x) for head in self.heads], dim=-1)
out = self.W_o(out)
return out
多头注意力只是并行运行多个自我注意力头并将它们组合起来。我们可以通过将 attention head 添加到模块列表中来实现这一点。
self.heads = nn.ModuleList([AttentionHead(d_model, self.head_size) for _ in range(n_heads)])
传递 input 并连接结果。
def forward(self, x):
# Combine attention heads
out = torch.cat([head(x) for head in self.heads], dim=-1)
然后,我们需要将输出传递给另一个线性模块。
out = self.W_o(out)
return out
五、transformer编码器
class TransformerEncoder(nn.Module):
def __init__(self, d_model, n_heads, r_mlp=4):
super().__init__()
self.d_model = d_model
self.n_heads = n_heads
# Sub-Layer 1 Normalization
self.ln1 = nn.LayerNorm(d_model)
# Multi-Head Attention
self.mha = MultiHeadAttention(d_model, n_heads)
# Sub-Layer 2 Normalization
self.ln2 = nn.LayerNorm(d_model)
# Multilayer Perception
self.mlp = nn.Sequential(
nn.Linear(d_model, d_model*r_mlp),
nn.GELU(),
nn.Linear(d_model*r_mlp, d_model)
)
def forward(self, x):
# Residual Connection After Sub-Layer 1
out = x + self.mha(self.ln1(x))
# Residual Connection After Sub-Layer 2
out = out + self.mlp(self.ln2(out))
return out
transformer 编码器由两个子层组成:第一个子层执行多头注意力,第二个子层包含一个多层感知器。多头注意力子层执行令牌之间的通信,而多层感知器子层允许令牌单独“思考”传达给它们的内容。
层归一化是一种优化技术,可跨其特征独立地对批次中的每个输入进行归一化。对于我们的模型,我们将通过每个子层开头的 layer norm 模块传递我们的输入。
# Sub-Layer 1 Normalization
self.ln1 = nn.LayerNorm(d_model)
# Sub-Layer 2 Normalization
self.ln2 = nn.LayerNorm(d_model)
MLP 将由两个线性层组成,中间有一个 GELU 层。使用 GELU 代替 RELU,因为它没有 RELU 在零时不可微分的限制。
# Encoder Multilayer Perception
self.mlp = nn.Sequential(
nn.Linear(width, width*r_mlp),
nn.GELU(),
nn.Linear(width*r_mlp, width)
)
在编码器的 forward 方法中,输入在执行多头注意之前通过第一层归一化模块。原始输入将添加到执行多头注意的输出中,以创建残差连接。
然后,在输入到 MLP 之前,它通过另一个层归一化模块传递。通过将 MLP 的输出添加到第一个残差连接的 out 来创建另一个残差连接。
残差连接用于帮助防止梯度消失问题,方法是创建一条路径,使渐变不受阻碍地反向传播回原始输入。
def forward(self, x):
# Residual Connection After Sub-Layer 1
out = x + self.mha(self.ln1(x))
# Residual Connection After Sub-Layer 2
out = out + self.mlp(self.ln2(out))
return out
六、Vision-transformer
class VisionTransformer(nn.Module):
def __init__(self, d_model, n_classes, img_size, patch_size, n_channels, n_heads, n_layers):
super().__init__()
assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, "img_size dimensions must be divisible by patch_size dimensions"
assert d_model % n_heads == 0, "d_model must be divisible by n_heads"
self.d_model = d_model # Dimensionality of model
self.n_classes = n_classes # Number of classes
self.img_size = img_size # Image size
self.patch_size = patch_size # Patch size
self.n_channels = n_channels # Number of channels
self.n_heads = n_heads # Number of attention heads
self.n_patches = (self.img_size[0] * self.img_size[1]) // (self.patch_size[0] * self.patch_size[1])
self.max_seq_length = self.n_patches + 1
self.patch_embedding = PatchEmbedding(self.d_model, self.img_size, self.patch_size, self.n_channels)
self.positional_encoding = PositionalEncoding( self.d_model, self.max_seq_length)
self.transformer_encoder = nn.Sequential(*[TransformerEncoder( self.d_model, self.n_heads) for _ in range(n_layers)])
# Classification MLP
self.classifier = nn.Sequential(
nn.Linear(self.d_model, self.n_classes),
nn.Softmax(dim=-1)
)
def forward(self, images):
x = self.patch_embedding(images)
x = self.positional_encoding(x)
x = self.transformer_encoder(x)
x = self.classifier(x[:,0])
return x
在创建我们的 vision transformer 类时,我们首先需要确保输入图像可以均匀地分割成大小为 patch_size 的块,并且模型的维度可以被注意力头的数量整除。
assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, "img_size dimensions must be divisible by patch_size dimensions"
assert d_model % n_heads == 0, "d_model must be divisible by n_heads"
我们还需要计算位置编码的最大序列长度,该长度等于补丁数加 1。通过将输入图像的高度和宽度的乘积除以色块大小的高度和宽度的乘积,可以找到色块的数量。
self.n_patches = (self.img_size[0] * self.img_size[1]) // (self.patch_size[0] * self.patch_size[1])
self.max_seq_length = self.n_patches + 1
Vision Transformer 还需要能够拥有多个编码器模块。这可以通过将编码器层列表放在 sequential wrapper 中来实现。
self.encoder = nn.Sequential(*[TransformerEncoder(self.d_model, self.n_heads) for _ in range(n_layers)])
Vision Transformer 模型的最后一部分是 MLP 分类头。它由一个线性层和一个 soft-max 层组成。
self.classifier = nn.Sequential(
nn.Linear(self.d_model, self.n_classes),
nn.Softmax(dim=-1)
)
在 forward 方法中,输入图像首先通过 patch 嵌入层,以将图像拆分为补丁,并获取这些补丁的线性嵌入序列。然后,它们通过位置编码层以添加分类标记和位置编码,然后再通过编码器模块。然后,分类标记通过分类 MLP 来确定图像的类别。
def forward(self, images):
x = self.patch_embedding(images)
x = self.position_embedding(x)
x = self.encoder(x)
x = self.classifier(x[:,0])
return x
我们已经完成了模型的构建。现在我们需要训练和测试它。
七、训练过程
7.1 参数配置
d_model = 9
n_classes = 10
img_size = (32,32)
patch_size = (16,16)
n_channels = 1
n_heads = 3
n_layers = 3
batch_size = 128
epochs = 5
alpha = 0.005
7.2 加载 MNIST 数据集
transform = T.Compose([
T.Resize(img_size),
T.ToTensor()
])
train_set = MNIST(
root="./../datasets", train=True, download=True, transform=transform
)
test_set = MNIST(
root="./../datasets", train=False, download=True, transform=transform
)
train_loader = DataLoader(train_set, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_set, shuffle=False, batch_size=batch_size)
7.3 开始训练
下面的代码使用 MNIST 训练集训练我们的 VisionTransformer 类,显示了整个 epoch 的平均损失。在 colab 上的 Tesla T4 GPU 上使用整个 epoch 进行训练只需不到一分钟。要更好地了解 PyTorch 优化器以及以下代码中发生的情况,请查看以下优化器:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using device: ", device, f"({torch.cuda.get_device_name(device)})" if torch.cuda.is_available() else "")
transformer = VisionTransformer(d_model, n_classes, img_size, patch_size, n_channels, n_heads, n_layers).to(device)
optimizer = Adam(transformer.parameters(), lr=alpha)
criterion = nn.CrossEntropyLoss()
for epoch in range(epochs):
training_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = transformer(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
training_loss += loss.item()
print(f'Epoch {epoch + 1}/{epochs} loss: {training_loss / len(train_loader) :.3f}')
八、测试
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = transformer(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f’\nModel Accuracy: {100 * correct // total} %')
九、结果
使用这个模型,我们能够在 5 个 epoch 的 MNIST 数据集训练中实现 ~ 92% 的准确率。此示例演示了 self-attention 可以用作深度卷积网络的替代品。请继续阅读,了解如何将 Vision Transformer 与文本相结合。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)