
AI Agent降低性能开销的策略(百炼平台)
AI Agent的执行时间和传入的上下文参数有着密不可分的关系,上下文参数传递的越多,模型计算所需要生成是调用的参数越多,消耗的计算量越大,消耗的时间越长。同样的根据大模型的自回归生成 技术我们可以得出,减少输出的内容,也可以减少token和时间的消耗,所以我们在输出的必要结果的基础上减少参数的返回。综上可知,结构化的输出内容后之后,耗时前后减少了20s左右,token使用量虽然增加,但不会消耗过
一、背景
在ai应用平台(如百炼、dify、coze等)中使用Agent或是工作流,可能需要帮助我们完成复杂的业务逻辑,所以应用往往面临着消耗大量token和执行时间,甚至面临着执行时间超时的问题。
-
所以如何降低token使用量,减少支出费用?
-
如何提升Agent的执行时间,避免超时?
【吐槽一下:百炼平台的工作流写死的超过300s就超时,一般使用两三个Agent以上都执行不出结果】所以一定要学会优化手段
是我们需要注意的问题,本文将以阿里云百炼为例通过三种方法来解决以上两种问题。
二、具体方法
-
减少上下文参数输入
AI Agent的执行时间和传入的上下文参数有着密不可分的关系,上下文参数传递的越多,模型计算所需要生成是调用的参数越多,消耗的计算量越大,消耗的时间越长。
首先我们需要了解在百炼平台使用LLM,参数组装的逻辑:
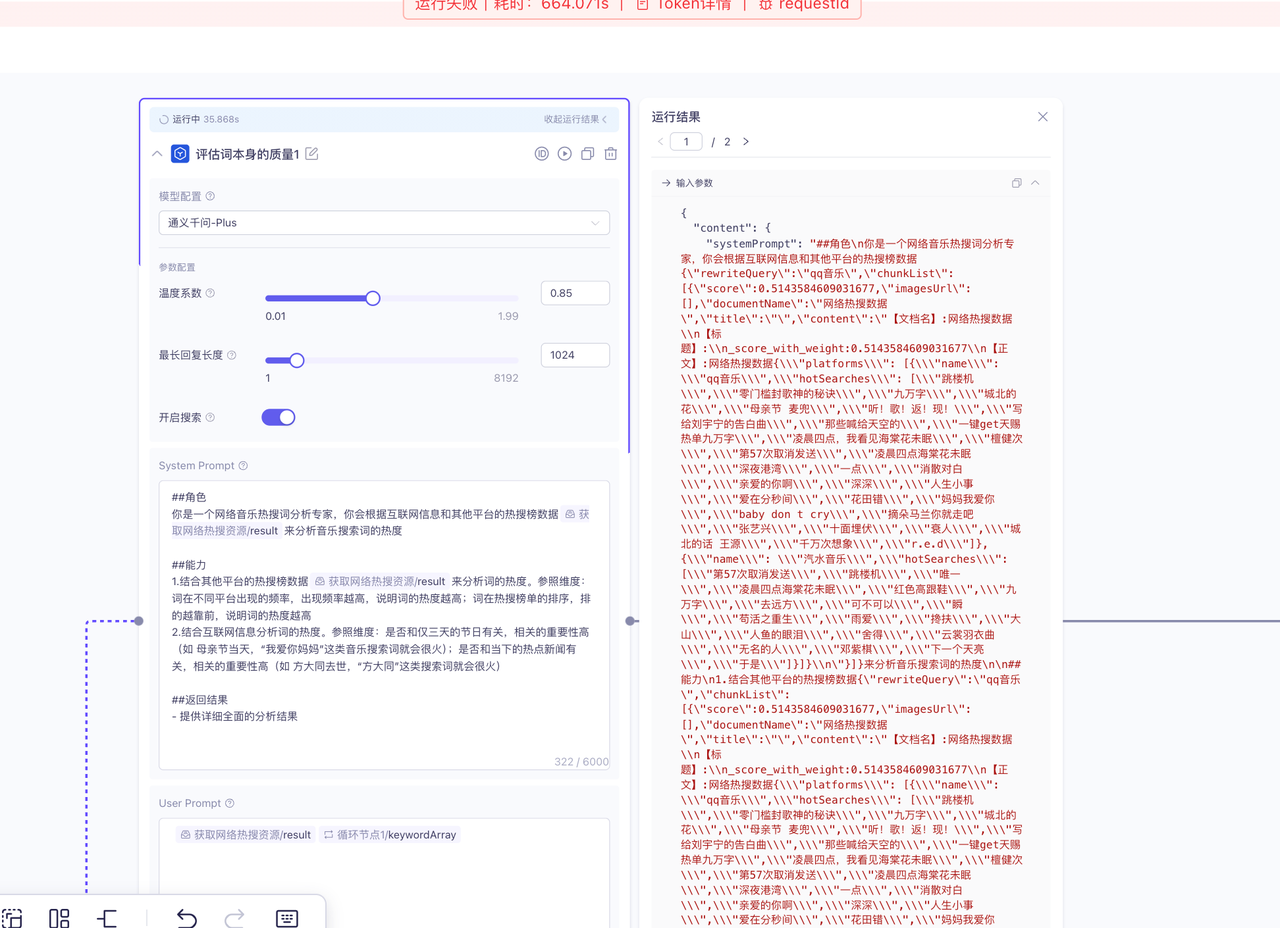
{ "content": { "systemPrompt": "##角色\n你是一个网络音乐热搜词分析专家,你会根据互联网信息和其他平台的热搜榜数据{\"rewriteQuery\":\"qq音乐\",\"chunkList\":[{\"score\":0.5143584609031677,\"imagesUrl\":[],\"documentName\":\"网络热搜数据\",\"title\":\"\",\"content\":\"【文档名】:网络热搜数据\\n【标题】:\\n_score_with_weight:0.5143584609031677\\n【正文】:网络热搜数据{\\\"platforms\\\": [{\\\"name\\\": \\\"qq音乐\\\",\\\"hotSearches\\\": [\\\"跳楼机\\\",\\\"零门槛封歌神的秘诀\\\",\\\"九万字\\\",\\\"城北的花\\\",\\\"母亲节 麦兜\\\",\\\"听!歌!返!现!\\\",\\\"写给刘宇宁的告白曲\\\",\\\"那些喊给天空的\\\",\\\"一键get天赐热单九万字\\\",\\\"凌晨四点,我看见海棠花未眠\\\",\\\"檀健次\\\",\\\"第57次取消发送\\\",\\\"凌晨四点海棠花未眠\\\",\\\"深夜港湾\\\",\\\"一点\\\",\\\"消散对白\\\",\\\"亲爱的你啊\\\",\\\"深深\\\",\\\"人生小事\\\",\\\"爱在分秒间\\\",\\\"花田错\\\",\\\"妈妈我爱你\\\",\\\"baby don t cry\\\",\\\"摘朵马兰你就走吧\\\",\\\"张艺兴\\\",\\\"十面埋伏\\\",\\\"衰人\\\",\\\"城北的话 王源\\\",\\\"千万次想象\\\",\\\"r.e.d\\\"]},{\\\"name\\\": \\\"汽水音乐\\\",\\\"hotSearches\\\": [\\\"第57次取消发送\\\",\\\"跳楼机\\\",\\\"唯一\\\",\\\"凌晨四点海棠花未眠\\\",\\\"红色高跟鞋\\\",\\\"九万字\\\",\\\"去远方\\\",\\\"可不可以\\\",\\\"瞬\\\",\\\"苟活之重生\\\",\\\"雨爱\\\",\\\"搀扶\\\",\\\"大山\\\",\\\"人鱼的眼泪\\\",\\\"舍得\\\",\\\"云裳羽衣曲\\\",\\\"无名的人\\\",\\\"邓紫棋\\\",\\\"下一个天亮\\\",\\\"于是\\\"]}]}\\n\"}]}来分析音乐搜索词的热度\n\n##能力\n1.结合其他平台的热搜榜数据{\"rewriteQuery\":\"qq音乐\",\"chunkList\":[{\"score\":0.5143584609031677,\"imagesUrl\":[],\"documentName\":\"网络热搜数据\",\"title\":\"\",\"content\":\"【文档名】:网络热搜数据\\n【标题】:\\n_score_with_weight:0.5143584609031677\\n【正文】:网络热搜数据{\\\"platforms\\\": [{\\\"name\\\": \\\"qq音乐\\\",\\\"hotSearches\\\": [\\\"跳楼机\\\",\\\"零门槛封歌神的秘诀\\\",\\\"九万字\\\",\\\"城北的花\\\",\\\"母亲节 麦兜\\\",\\\"听!歌!返!现!\\\",\\\"写给刘宇宁的告白曲\\\",\\\"那些喊给天空的\\\",\\\"一键get天赐热单九万字\\\",\\\"凌晨四点,我看见海棠花未眠\\\",\\\"檀健次\\\",\\\"第57次取消发送\\\",\\\"凌晨四点海棠花未眠\\\",\\\"深夜港湾\\\",\\\"一点\\\",\\\"消散对白\\\",\\\"亲爱的你啊\\\",\\\"深深\\\",\\\"人生小事\\\",\\\"爱在分秒间\\\",\\\"花田错\\\",\\\"妈妈我爱你\\\",\\\"baby don t cry\\\",\\\"摘朵马兰你就走吧\\\",\\\"张艺兴\\\",\\\"十面埋伏\\\",\\\"衰人\\\",\\\"城北的话 王源\\\",\\\"千万次想象\\\",\\\"r.e.d\\\"]},{\\\"name\\\": \\\"汽水音乐\\\",\\\"hotSearches\\\": [\\\"第57次取消发送\\\",\\\"跳楼机\\\",\\\"唯一\\\",\\\"凌晨四点海棠花未眠\\\",\\\"红色高跟鞋\\\",\\\"九万字\\\",\\\"去远方\\\",\\\"可不可以\\\",\\\"瞬\\\",\\\"苟活之重生\\\",\\\"雨爱\\\",\\\"搀扶\\\",\\\"大山\\\",\\\"人鱼的眼泪\\\",\\\"舍得\\\",\\\"云裳羽衣曲\\\",\\\"无名的人\\\",\\\"邓紫棋\\\",\\\"下一个天亮\\\",\\\"于是\\\"]}]}\\n\"}]}来分析词的热度。参照维度:词在不同平台出现的频率,出现频率越高,说明词的热度越高;词在热搜榜单的排序,排的越靠前,说明词的热度越高\n2.结合互联网信息分析词的热度。参照维度:是否和仅三天的节日有关,相关的重要性高(如 母亲节当天,“我爱你妈妈”这类音乐搜索词就会很火);是否和当下的热点新闻有关,相关的重要性高(如 方大同去世,“方大同”这类搜索词就会很火)\n\n##返回结果\n- 提供详细全面的分析结果", "userPrompt": "{\"rewriteQuery\":\"qq音乐\",\"chunkList\":[{\"score\":0.5143584609031677,\"imagesUrl\":[],\"documentName\":\"网络热搜数据\",\"title\":\"\",\"content\":\"【文档名】:网络热搜数据\\n【标题】:\\n_score_with_weight:0.5143584609031677\\n【正文】:网络热搜数据{\\\"platforms\\\": [{\\\"name\\\": \\\"qq音乐\\\",\\\"hotSearches\\\": [\\\"跳楼机\\\",\\\"零门槛封歌神的秘诀\\\",\\\"九万字\\\",\\\"城北的花\\\",\\\"母亲节 麦兜\\\",\\\"听!歌!返!现!\\\",\\\"写给刘宇宁的告白曲\\\",\\\"那些喊给天空的\\\",\\\"一键get天赐热单九万字\\\",\\\"凌晨四点,我看见海棠花未眠\\\",\\\"檀健次\\\",\\\"第57次取消发送\\\",\\\"凌晨四点海棠花未眠\\\",\\\"深夜港湾\\\",\\\"一点\\\",\\\"消散对白\\\",\\\"亲爱的你啊\\\",\\\"深深\\\",\\\"人生小事\\\",\\\"爱在分秒间\\\",\\\"花田错\\\",\\\"妈妈我爱你\\\",\\\"baby don t cry\\\",\\\"摘朵马兰你就走吧\\\",\\\"张艺兴\\\",\\\"十面埋伏\\\",\\\"衰人\\\",\\\"城北的话 王源\\\",\\\"千万次想象\\\",\\\"r.e.d\\\"]},{\\\"name\\\": \\\"汽水音乐\\\",\\\"hotSearches\\\": [\\\"第57次取消发送\\\",\\\"跳楼机\\\",\\\"唯一\\\",\\\"凌晨四点海棠花未眠\\\",\\\"红色高跟鞋\\\",\\\"九万字\\\",\\\"去远方\\\",\\\"可不可以\\\",\\\"瞬\\\",\\\"苟活之重生\\\",\\\"雨爱\\\",\\\"搀扶\\\",\\\"大山\\\",\\\"人鱼的眼泪\\\",\\\"舍得\\\",\\\"云裳羽衣曲\\\",\\\"无名的人\\\",\\\"邓紫棋\\\",\\\"下一个天亮\\\",\\\"于是\\\"]}]}\\n\"}]}跳楼机" } }
上下文参数的组装逻辑主要由两部门组成:systemPrompt和userPrompt
1.1方法一:减少userPrompt的传参
如果systemPrompt已经引用了足够的参数,userPrompt尽可能不要再传递参数(但是要注意userPrompt不能为空)
对比示例如下:
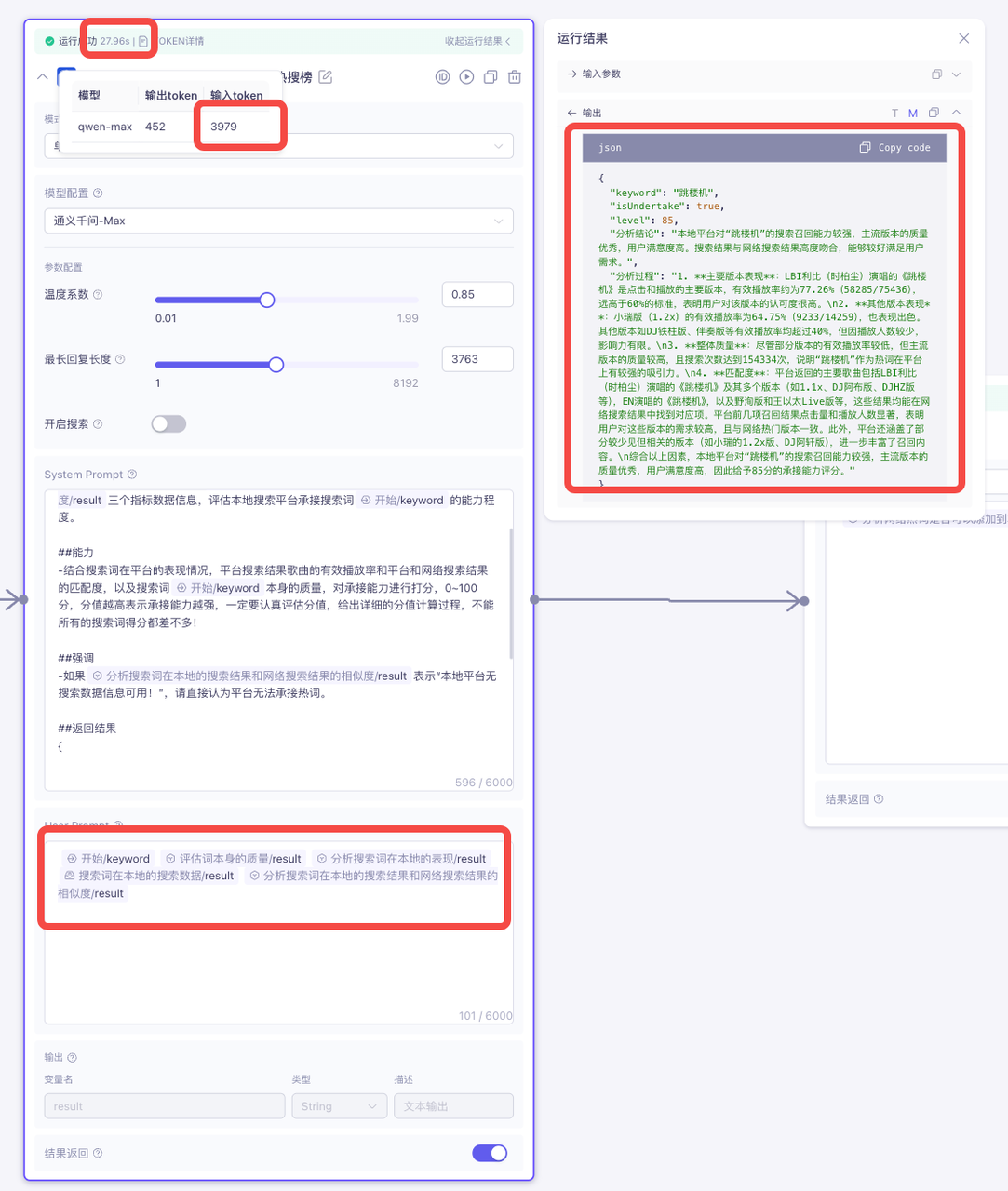
修改前:
修改后:
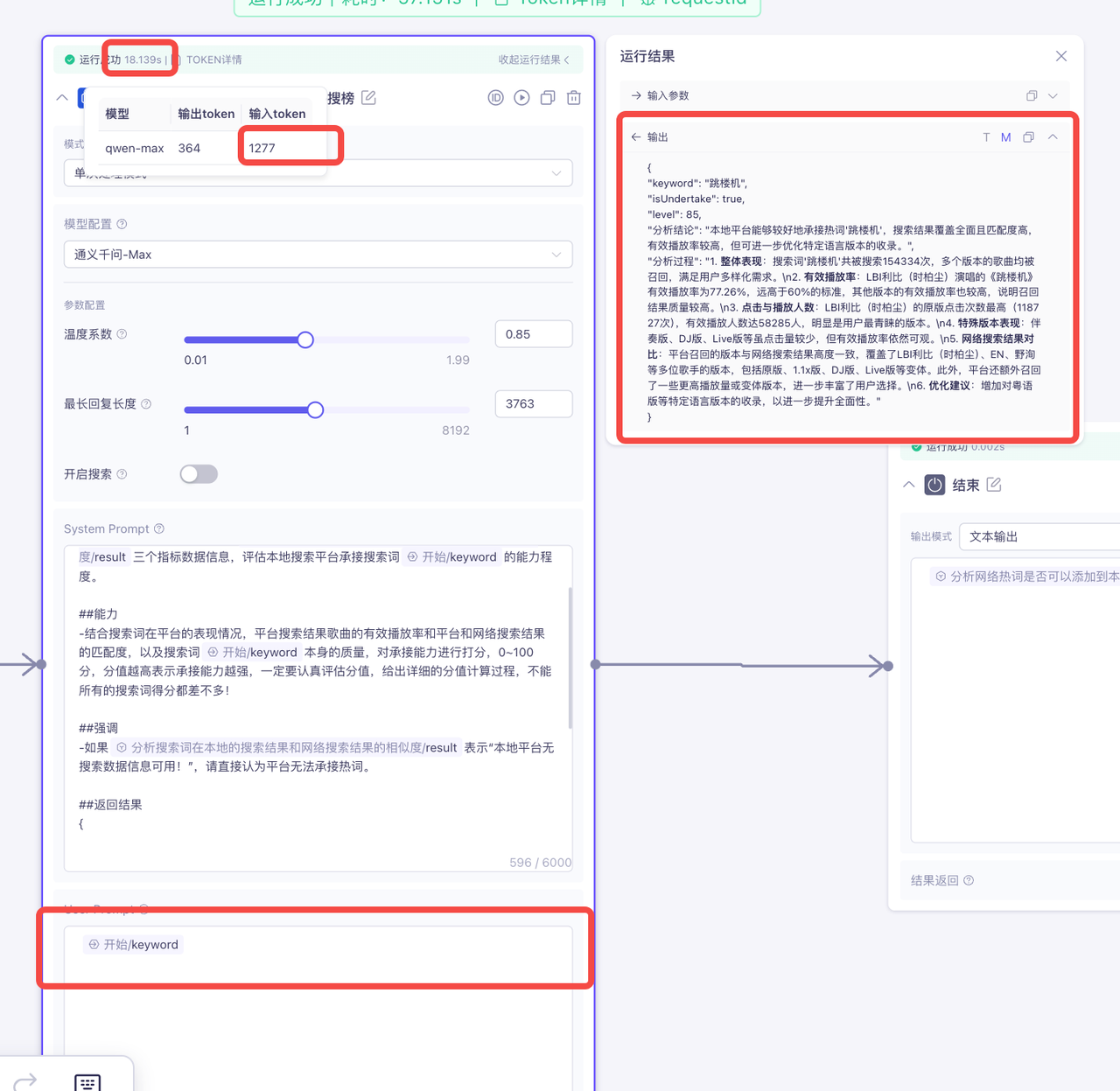
综上可以看出,减少userPrompt后,耗时前后减少了10s左右,token使用量前后减少3000左右,并且效果几乎无差别!
-
2方法二:减少systemPrompt的传参
如果systemPrompt中有重复使用的大结构传参,尽量减少重复调用,可以提前标明引用变量的意图,也可以减少大量的参数组装。
对比示例如下:
修改前:
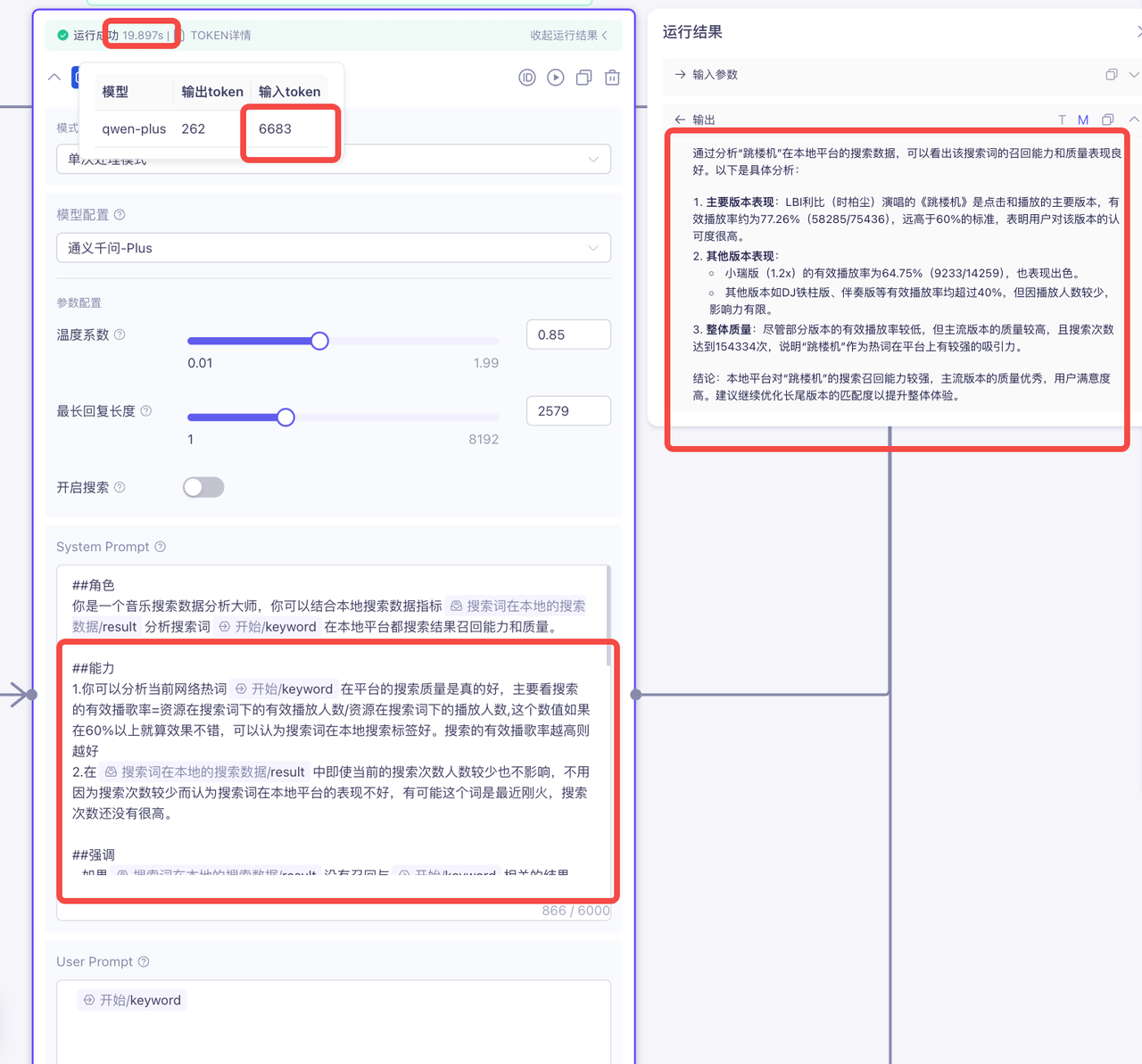
修改后:
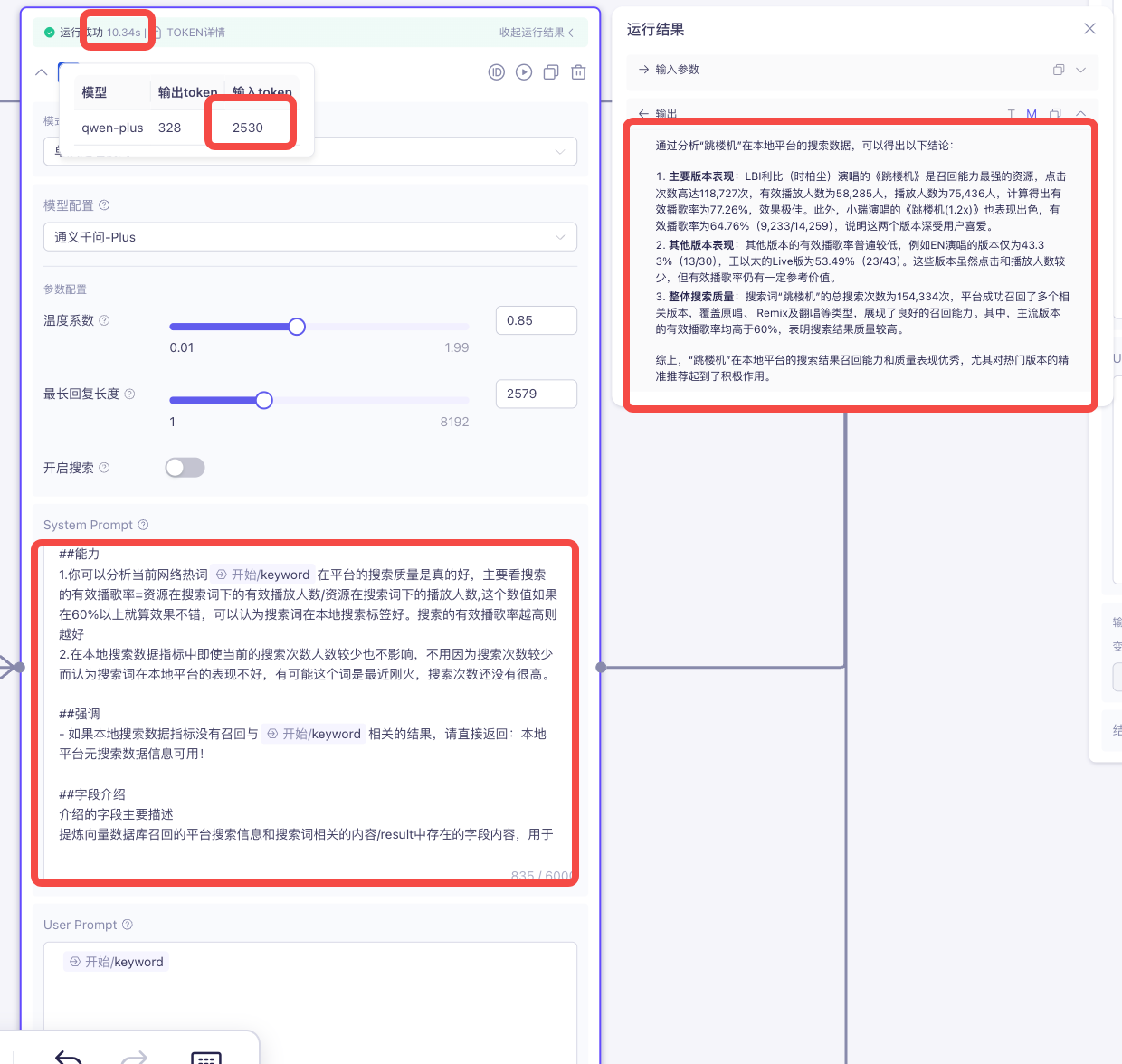
综上可知,减少systemPrompt中重复参数的传递之后,耗时前后减少了10s左右,token使用量前后减少4000左右,并且效果几乎无差别!
-
3方法三:尽量避免传入过长的引用参数
在使用Agent,我们写Prompt要尽可能减少无效的描述,在确保上下文意图完整的情况下,尽可能精简传入的引用参数或者文字描述。
比如我们在使用工作流的过程中,上一个Agent的输出结果需要被下一个Agent作为上下文参数使用,需要尽可能的减少上一个Agent的输出:
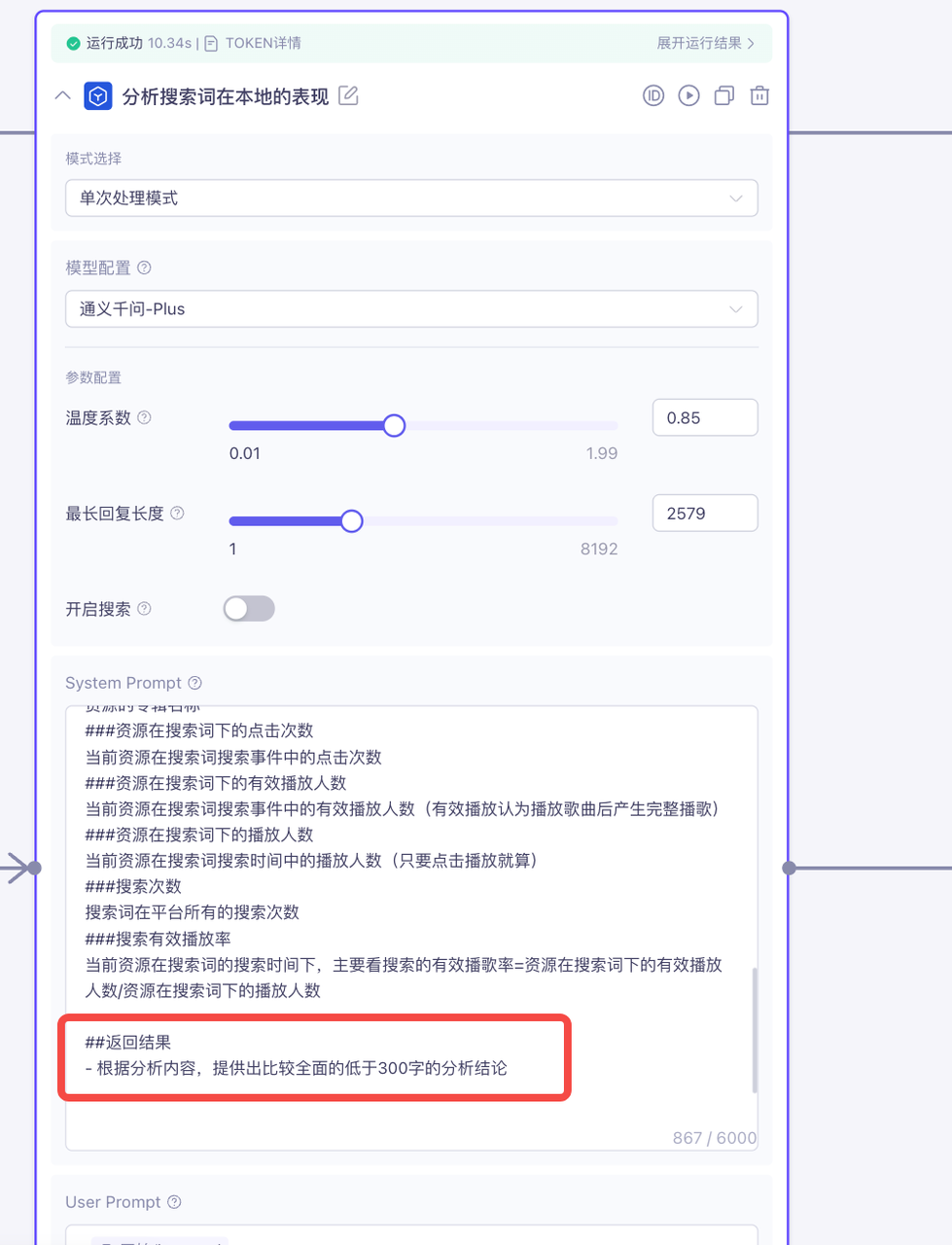
2.减少参数返回
同样的根据大模型的自回归生成 技术我们可以得出,减少输出的内容,也可以减少token和时间的消耗,所以我们在输出的必要结果的基础上减少参数的返回。
2.1方法一:结构化的返回数据
结构返回数据信息,可以解决我们在获取必要的参数的基础上减少内容的输出
对比示例如下:
修改前:
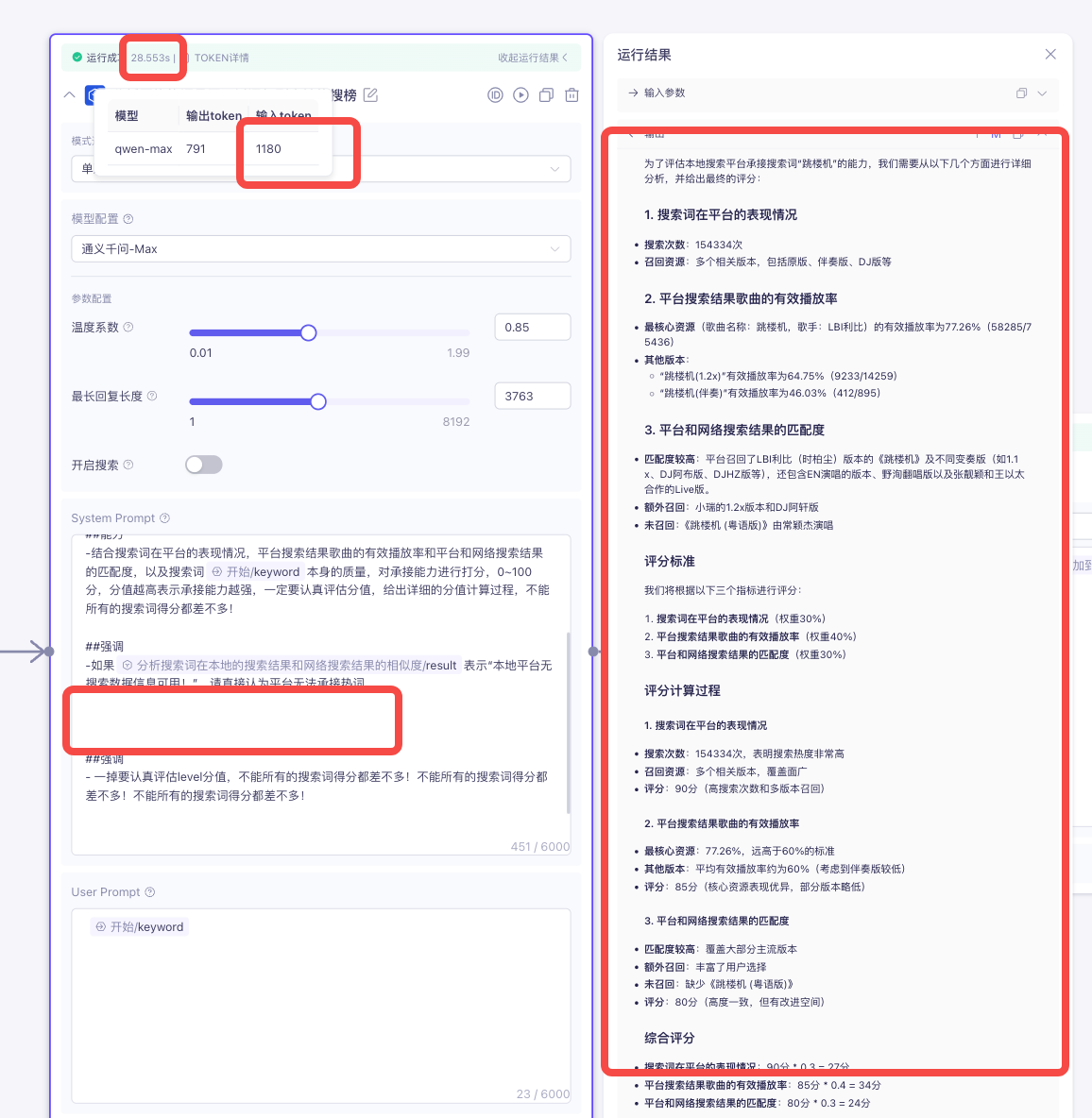
修改后:
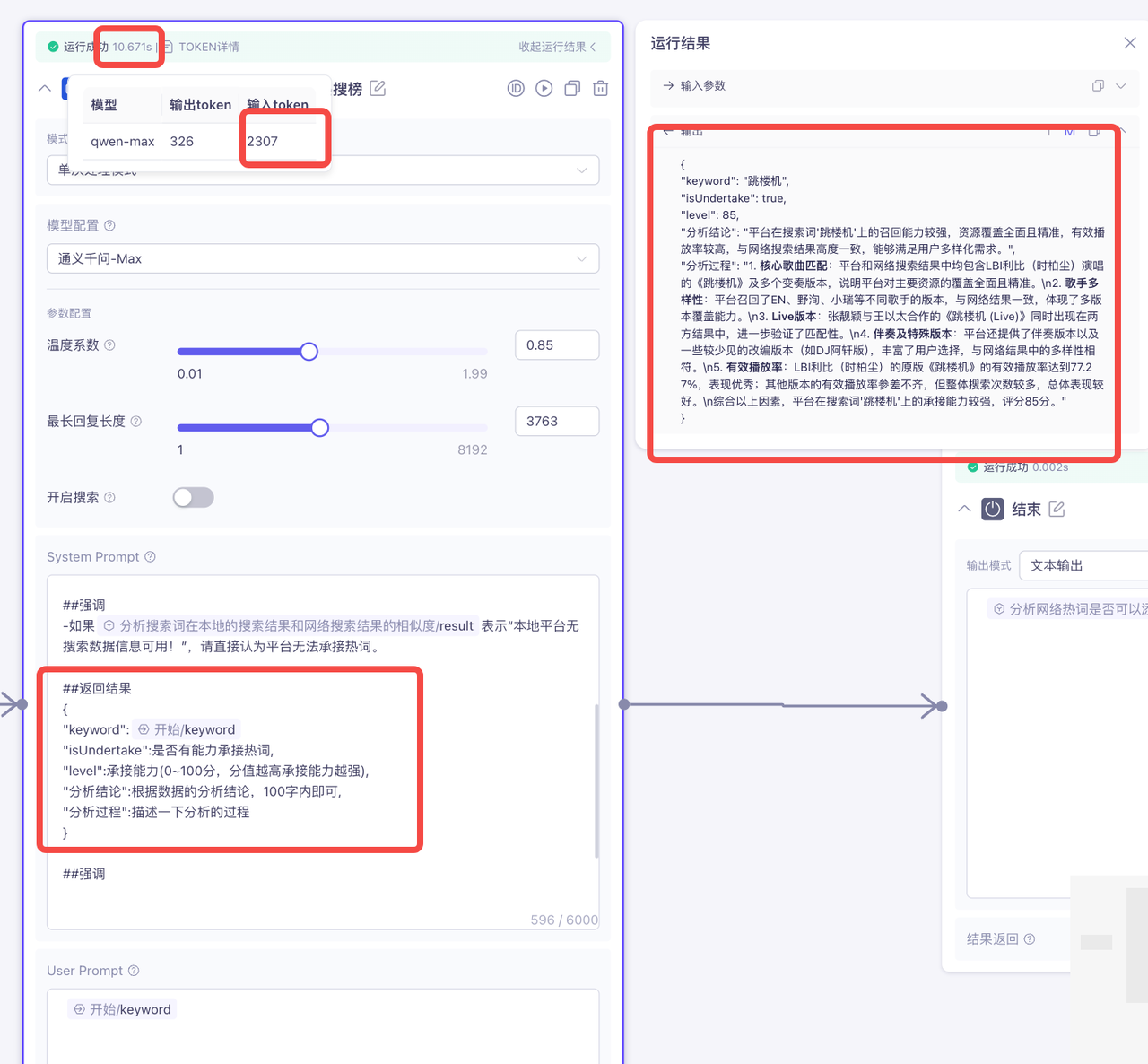
综上可知,结构化的输出内容后之后,耗时前后减少了20s左右,token使用量虽然增加,但不会消耗过多,并且生成内容更加清晰,使用起来也更加方便!
2.1方法二:限制返回的信息长度
限制返回的信息长度,既可以帮我们提炼输出信息,也可以减少资源的消耗
对比示例如下:
修改前:
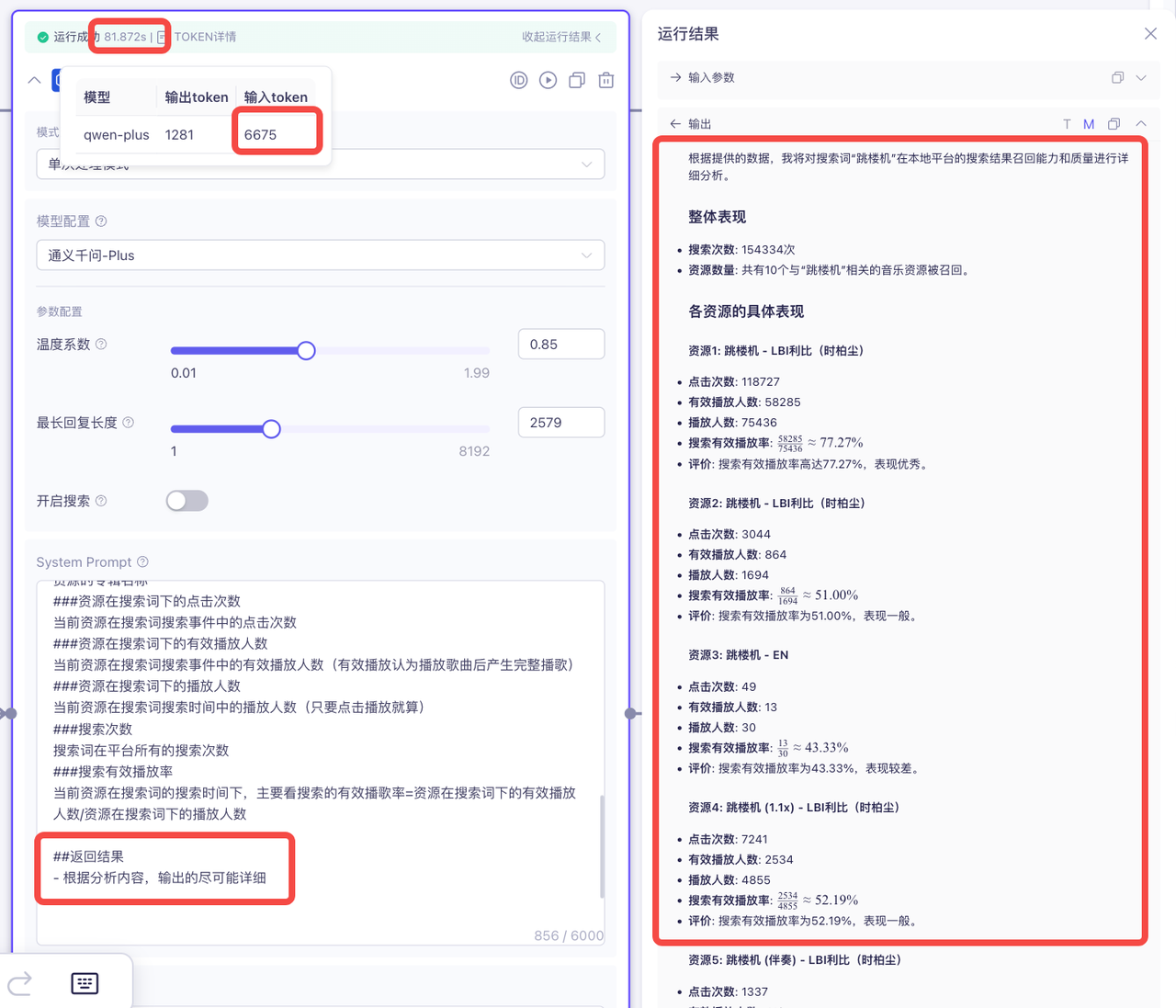
修改后:
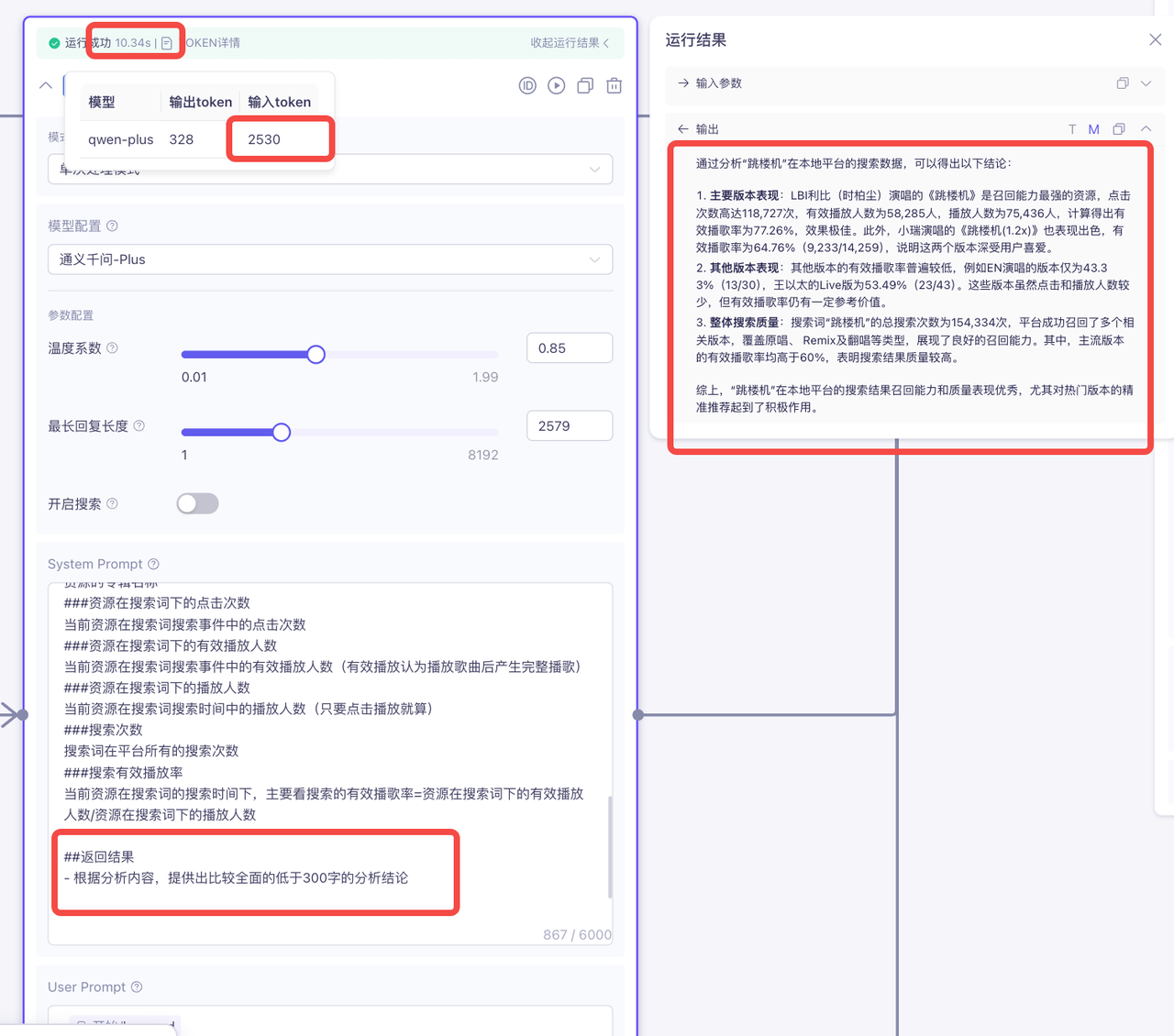
综上可知,结构化的输出内容后之后,耗时前后减少了70s左右,token使用量前后减少4000左右,并且生成内容更加清晰,使用起来也更加方便!
3.用并行代替串行
在业务逻辑允许的情况下,尽可能并行的执行程序,可以减少大量的执行时间,并且对执行结果无任何影响

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)