
Mistral Leanstral 1.5:定理证明进入平民时代
2026-07-04
如果你不是做形式化验证的,可能对 Leanstral 没什么感觉。没事,看完这篇你再决定要不要关注。
Mistral AI 这周发布了 Leanstral 1.5,Apache-2.0 开源,119B 参数、6B 激活的 MoE 架构。看参数你可能觉得"又是一个大模型",但这东西跟 ChatGPT 那种聊天模型完全是两个物种。
它干的事是——证明数学定理。
而且不是随便证明几个小学数学题。miniF2F 基准被它刷满了,Putnam 数学竞赛的题目它解了 587/672 道。Putnam 竞赛是什么水平?这么说吧,能在 Putnam 拿奖的人,数学系的教授会主动发博士邀请。
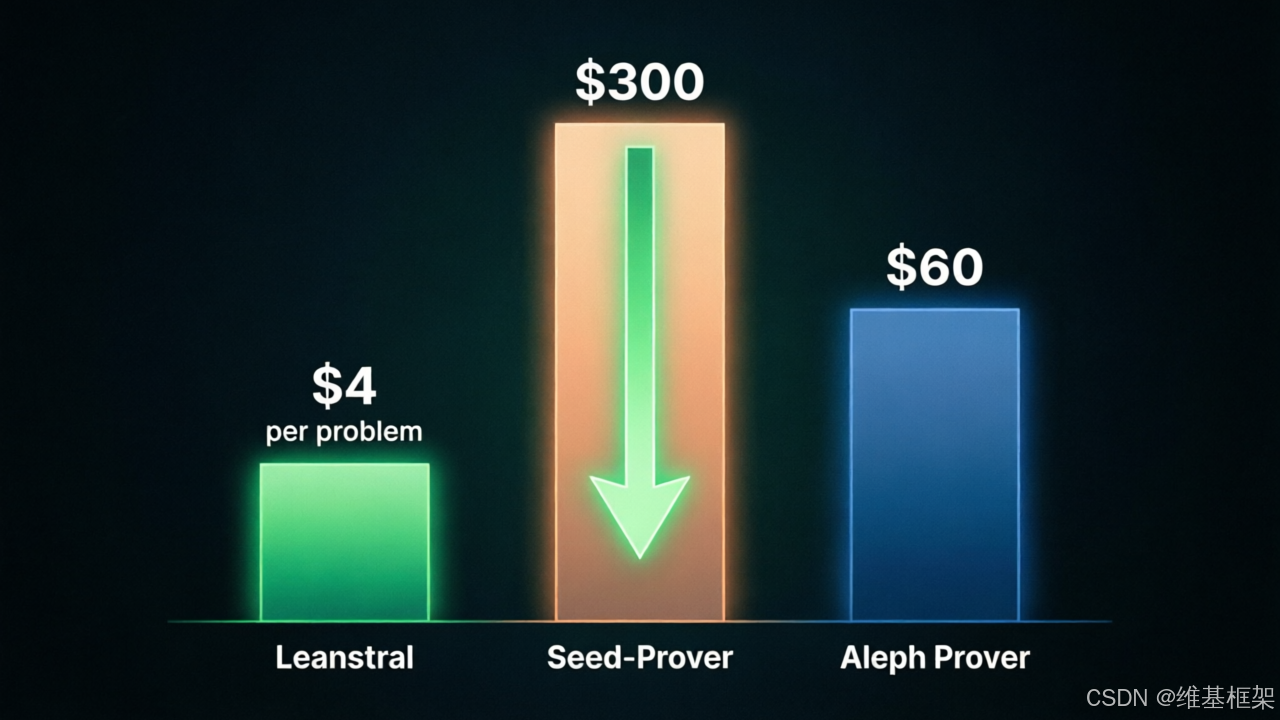
更关键的是成本:每道题约 4 美元。
揉了好几次眼睛确认这个数字。Seed-Prover 1.5 跑同样的题,每道要 300 美元起步——10 个 H20 天的预算。Aleph Prover 更贵,54 到 68 美元一道。Leanstral 把成本砍了两个数量级。
这不叫进步,这叫改写游戏规则。
一个不聊天的 AI
我原本以为 Leanstral 也是个聊天机器人——毕竟 Mistral 之前的模型都是对话式的。后来看了它的工作方式才发现完全不是一回事。
Leanstral 的操作方式更像一个开发者在裸文件系统上工作:它直接编辑 .lean 文件,运行 bash 命令,用 Lean 语言服务器实时检查目标状态和类型信息。如果证明出错,它不会说"抱歉,我重新试试",而是直接打开编辑器、定位错误行、修改、重新编译。
怎么说呢,有那种在终端前坐了八小时的 senior engineer 的味了。
Mistral 的博客里提到了一个 AVL 树的案例。Leanstral 为一个真实的 AVL 树实现证明了 O(log n) 时间复杂度的上界。这不是那种教科书上的伪代码——是真的有内存分配、有 Monad 封装、有控制流交错的实现代码。
它怎么做的?用了 270 万 Token、22 次上下文压缩。每次压缩后继续推理、编辑文件、重新验证。单调递增的性能曲线从 50k Token 时的 44 道题一路爬到 4M Token 时的 587 道题。
关键看 test-time scaling:随着推理预算增加,Leanstral 的解题数平滑上升,没有出现收益递减的拐点。这对整个形式化验证领域来说是个好消息——证明定理这件事,砸更多的算力确实能解决更难的问题。
代码验证:不是纸上谈兵
Mistral 做了一件事我觉得特别扎实:他们建了一个自动化流水线,用 Aeneas 把 Rust 代码翻译成 Lean,然后让 Leanstral 自动推断代码的意图并生成正确性属性。
在 57 个开源仓库上跑了这个流水线后,结果出来了。标记了 47 个违反属性,其中 11 个指向真实 bug。5 个是之前从未报告过的漏洞。
揉了揉眼睛再确认了一遍。不是,一个定理证明器,去抓 Rust 代码里的 bug,还抓到了从未公开过的漏洞?
对,就是这么回事。
其中一个案例是某个 Rust 并发库里的内存排序问题。代码本身通过了 Rust 的编译器检查,但 Leanstral 的 Lean 证明发现了在某些内存序下的竞态条件——Rust 的类型系统不会报这个错,因为它在语义层面是"正确"的,但实际运行时的内存可见性约束没有满足。

这让我想到一个问题:形式化验证的"黄金时代"是不是真的来了?
形式验证的平民化
以前的形式化验证是什么画风?你得有数学博士学历、花几个月写一个证明、跑在超级计算机上。Coq、Isabelle、Lean 这些工具的学习曲线——讲真——比学一门编程语言陡峭十倍。
但 Leanstral 的思路完全不一样:它不是在"用人话写证明",而是在"用工程手段做证明"。它把证明当成了一个编程任务来处理——编辑、编译、调试、再编辑。
这直接降低了门槛。
你想让它证明一个函数的功能正确性?把函数代码给它,说一句"帮我证明这个是对的",它就自己开干。不需要你手写复杂的归纳假设或者引理——这些都可以由模型自动推断。
讲真,如果这个方向继续演进,未来代码审查的标准可能从"有没有写单元测试"变成"有没有形式化证明"。
很多人觉得这不现实——但目前 Leanstral 1.5 已经在 57 个仓库上跑通了自动化验证。不是学术界那种精心挑选的 demo 数据集,而是 GitHub 上随便找的开源项目。
技术细节
技术上,Leanstral 1.5 过了一个三阶段训练流程:中间训练(mid-training)→ 监督微调 → 基于 CISPO 的强化学习。
CISPO 是啥?可以理解为一种专门针对形式化证明的奖励模型——它不是看模型输出的文本是否"像人话",而是看模型生成的证明是否能通过 Lean 的类型检查。二元结果:通过或没通过。没有任何模糊空间。
这个设计很聪明。形式化验证有一个天然的优势:正确性是可判定的。数学证明要么对要么错,不存在"看起来差不多对了"的中间状态。这意味着强化学习的奖励信号是 100% 可靠的——没有人工标注的噪声,没有偏好对齐的偏差。
它也解释了为什么 Leanstral 的 test-time scaling 这么漂亮。在 chat 模型里,随着推理时间增加,输出质量往往会遇到瓶颈——因为语言任务的"正确性"本身就是模糊的。但形式证明是确定的——砸更多的算力去搜索更大的证明空间,就有更高的概率找到正确的路径。
说实话,我越来越觉得形式化验证才是 LLM 最被低估的应用场景。不是写诗,不是画图,而是证明东西是对的还是错的。
行了,今天就到这。我要去试试用 Leanstral 证明我的排序算法是不是真的稳定。
关于维基框架
维基框架(Wiki Framework)是一套面向复杂业务场景的轻量级开发框架,支持多语言、多协议、多部署形态。适用于企业级应用开发、微服务架构、云原生部署等场景。
官网:framewiki.com
Gitee:gitee.com/wiki-framework
GitHub:github.com/wiki-framework
示例项目:gitee.com/cdkjframework/framewiki-example
📄 许可证:MulanPSL-2.0(木兰宽松许可证,第2版)

AtomGit AI 社区提供模型库、数据集、Agent、Token等资源
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)