
VSCode + Cline + Continue + GLM5.2, 用AI助力代码学习。当你上瘾之日,就是你掏钱之时
目的:
现在日常工作中,已经完全离不开AI了,涵盖写文档,写代码,debug。偷懒点,日报,周报,年报,专利也可以丢给它总结下,给你整的明明白白。AI很强,可能能帮你完成99%的工作,但是它也没那么完美,需要你守好最后一公里。做个demo,它可能非常完美的胜任,但是想要做个稳定的产品,都需要人这个变量参与review。
AI从最初的对话式,到提示词工程,再到现在的Agent,日新月异。每个公司也都在探索AI的开发之路,即使马车拉蒸汽机也要干,不然就陷入落后就要被淘汰的焦虑。部门近期也有使用claude code + Qwen结合spec-kit进行SDD开发5kLoc的代码,能用,但是挖的坑又很难定位,人变成了真实物理世界和代码的转发层。代码reviw的速度,也跟不上他造代码的速度。这是一个系统性的工程化问题,可能后端的大模型能力不行,也可能是skill的能力规范不行,这都需要时间去解决。
或许AI淘汰程序员就在不久的将来,尽快学吧,至少还能做个AI的质检守门员,或者人人都做产品经理。
一、AI模型
科学上网,比较折腾,最主要是用国内的大模型也完全够用,价格便宜量大管饱。先爬后跑,先用再换,不求最好,但求能用。有条件的,也可以自己本地部署大模型,一般公司有保密需求的,或者追求性价比的,可以搞。
个人用户,简单点,就去一些AI聚合网站“token工厂”花钱买积分,买流量。能白嫖用一阵子,先体验一下,我注册了个硅基流动,送了16元的token,如下是他支持的所有AI大模型。
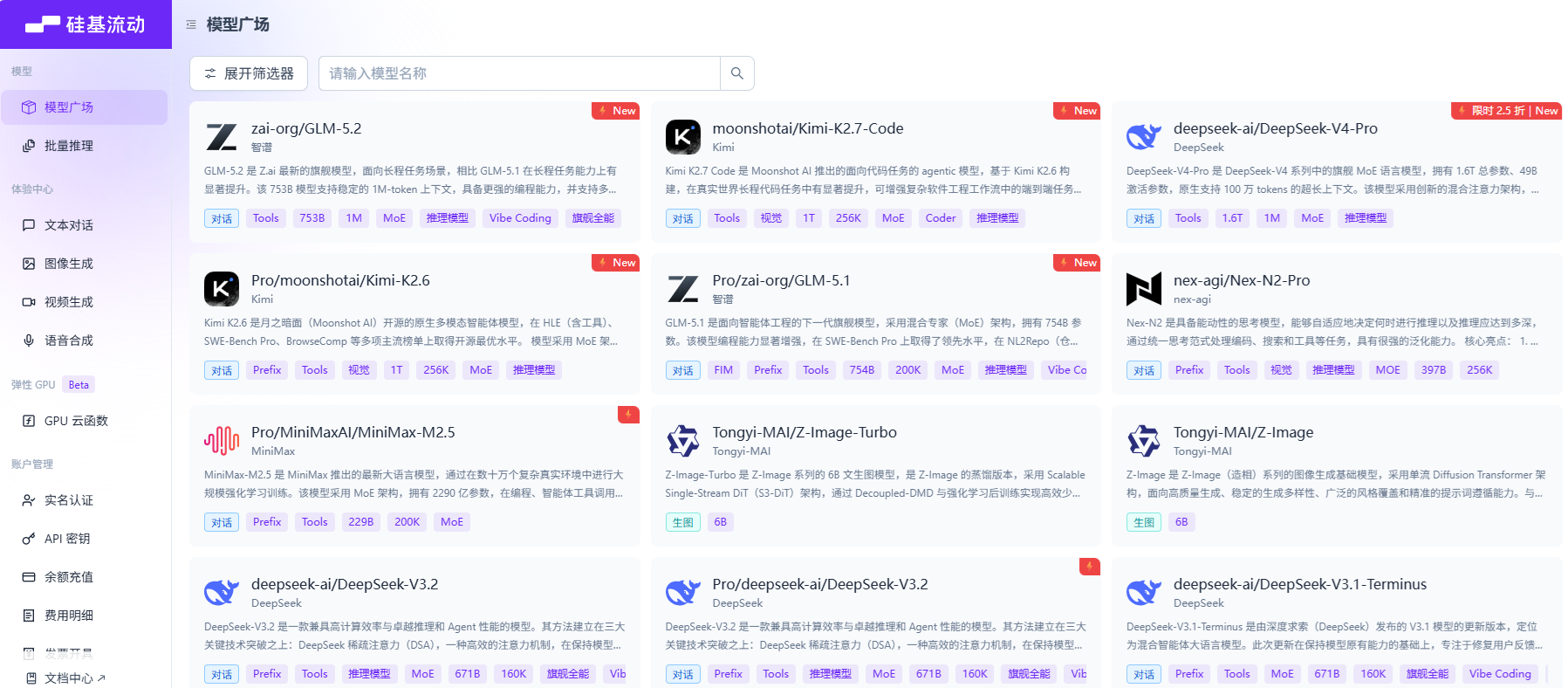
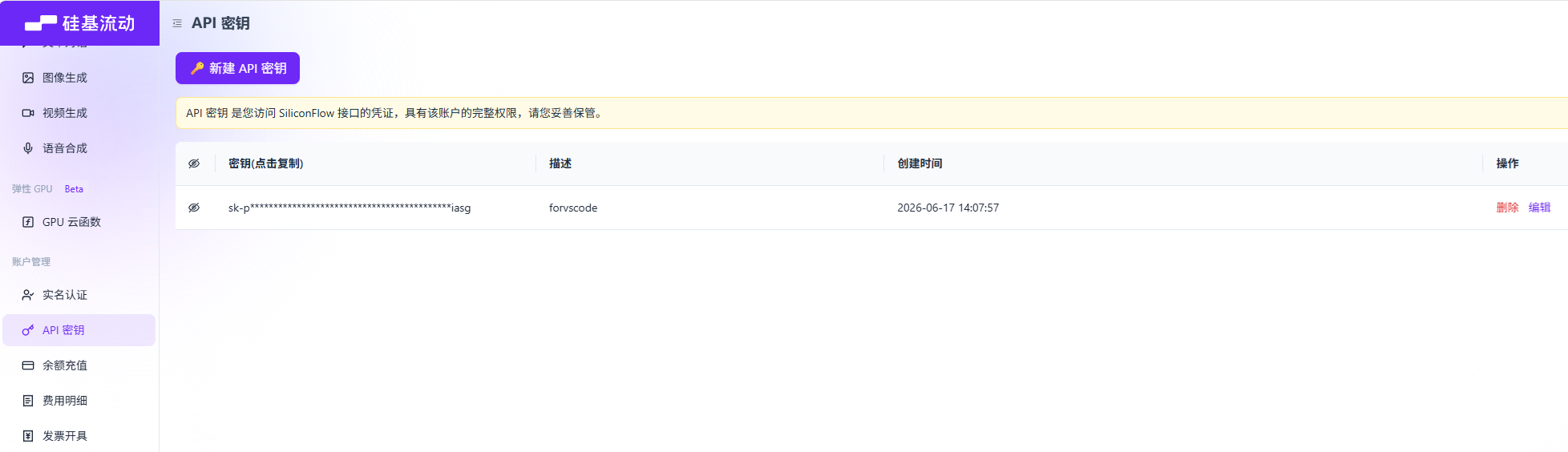
通过在网站上创建获取API密钥,其他工具就可以通过这个key调用AI模型。每个模型都有自己擅长的,选择自己喜欢的就行。或者找AI问下,我感觉比较鸡肋,因为我问的gemini 3.5-flash,chatgpt_5.5_instant,得到不一样的答案,千AI千面,AI也是存在认知差异。以下摘自硅基流动的介绍
1.1 deepseek-ai/DeepSeek-V4-Pro
DeepSeek-V4-Pro 是 DeepSeek-V4 系列中的旗舰 MoE 语言模型,拥有 1.6T 总参数、49B 激活参数,原生支持 100 万 tokens 的超长上下文。该模型采用创新的混合注意力架构,结合压缩稀疏注意力(CSA)与高度压缩注意力(HCA),在 1M 上下文下仅需 DeepSeek-V3.2 的 27% 单 token 推理 FLOPs 和 10% KV 缓存。模型还引入流形约束超连接(mHC)增强层间信号传播稳定性,并采用 Muon 优化器加速收敛。DeepSeek-V4-Pro 在超过 32T 高质量多样化 tokens 上预训练,后训练采用“领域专家独立培养 + 在线策略蒸馏统一整合”的两阶段范式。其最大推理强度模式 DeepSeek-V4-Pro-Max 在编程基准上取得顶尖表现,并在推理与 Agentic 任务上大幅缩小与领先闭源模型的差距,是目前最强的开源模型之一,支持 Non-think、Think High、Think Max 三种推理强度模式。
1.2 zai-org/GLM-5.2
GLM-5.2 是 Z.ai 最新的旗舰模型,面向长程任务场景,相比 GLM-5.1 在长程任务能力上有显著提升。该 753B 模型支持稳定的 1M-token 上下文,具备更强的编程能力,并支持多种 thinking effort levels,以在性能和延迟之间进行灵活平衡。GLM-5.2 引入 IndexShare 架构优化,在 1M 上下文长度下将 per-token FLOPs 降低 2.9 倍,同时改进 MTP layer 以支持 speculative decoding,使 acceptance length 最高提升 20%。
1.3 Qwen/Qwen3.6-35B-A3B
Qwen3.6-35B-A3B 是通义千问团队推出的 Qwen3.6 系列大语言模型,采用混合专家(MoE)架构,拥有 350 亿总参数,每次推理仅激活约 30 亿参数,兼顾高效推理与优秀性能。模型支持思考与非思考双模式,可在快速响应与深度推理间灵活切换。
二、Cline插件
Cline 是一个能帮你干脏活累活的“独立 Agent 程序员”,擅长多文件修改,全自动执行及自主调试。
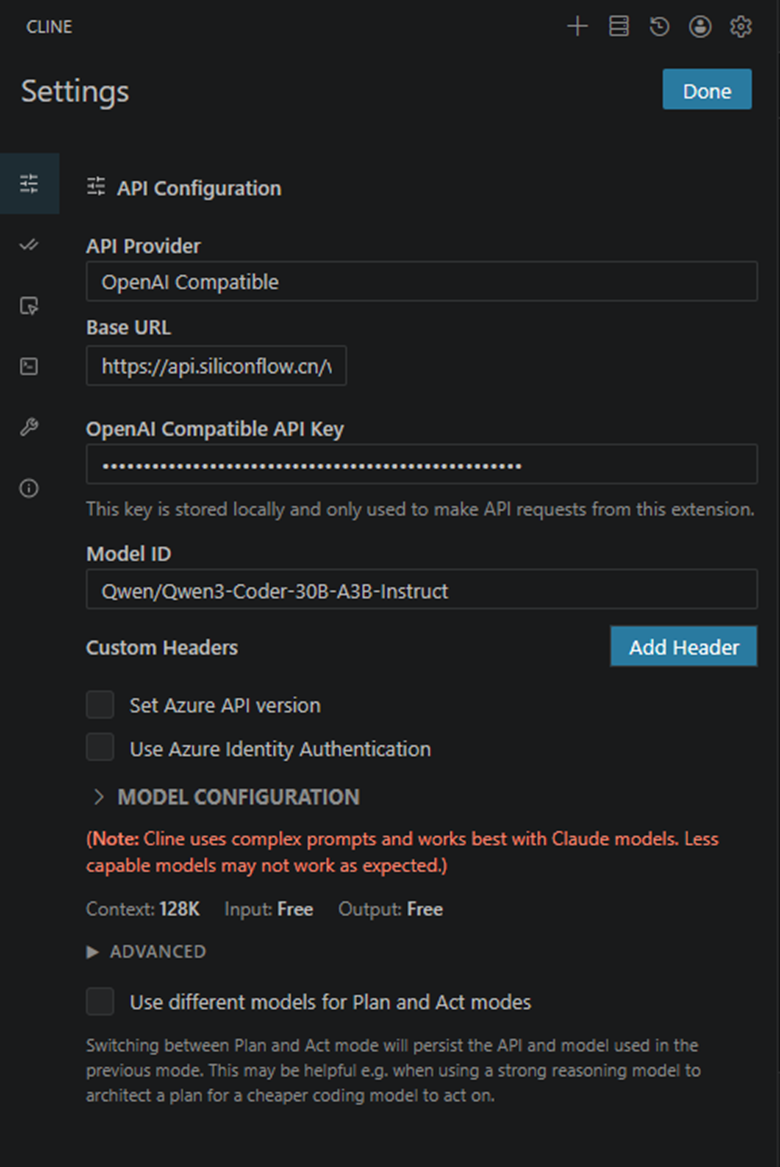
2.1 配置Cline
API Provider:选择 “OpenAI Compatible”
Base Url:https://api.siliconflow.cn/v1
API Key / Model ID:参考“章节一”,登录硅基流动获取
2.2 使用Cline
好树结好果,好铁铸好锅。现在的Agent Harness,支持多文件,多任务并发,简直就是token屠夫,普通的AI大模型完全扛不住,建议使用强模型。
测试使用DeepSeek-V4-Flash,Qwen3-Coder-30B-A3B-Instruct带不动,翻译个函数,他要读取多文件上下文,后面直接罢工摆烂了。就像我的破手机带不动王者一样,直接闪退。
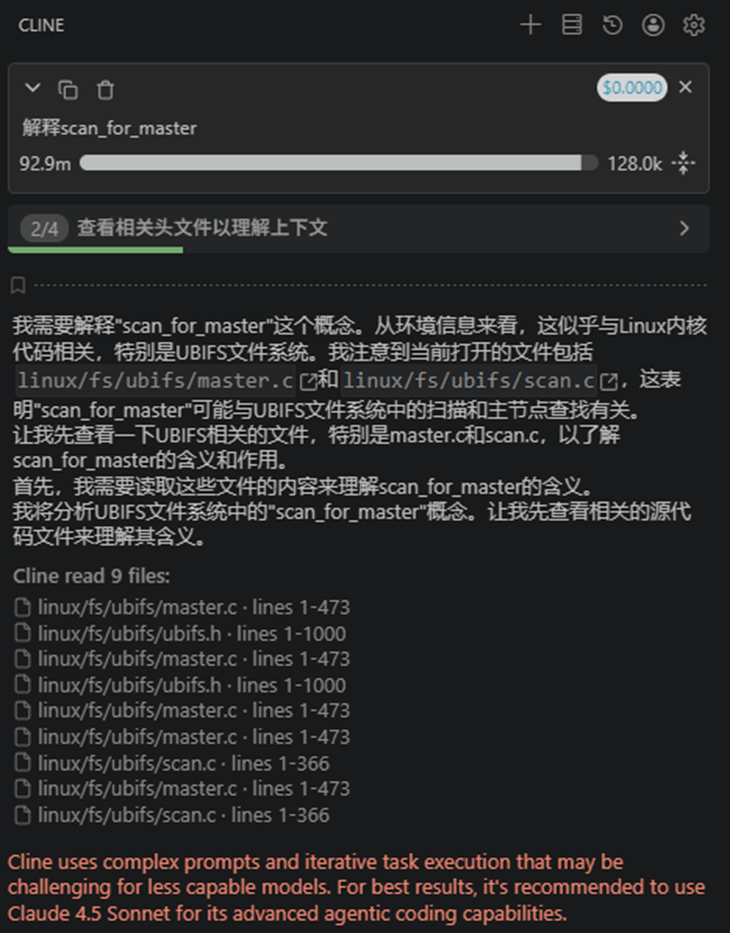
换了GLM-5.1,才完成答复。
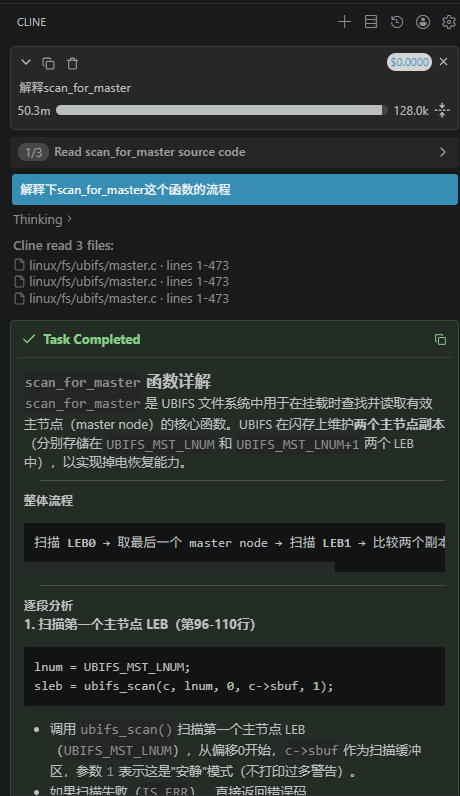
2.3 Token消耗
同一个问题,每个AI模型的消耗都是k tokes以上,deepseek确实是性价比之王,Qwen3没完成答复,消耗的却是最多的,像是个努力学习提高不了成绩的学生。
如果一个简单问题平均开销0.3元,平台送了16元,最多53个问题,日均53/22 = 2.4个,完全不够用。如果让他给我写个功能,估计一下就能吃干抹净,太费钱了。月费150,日均20+个估计勉强够用。

三、Continue插件
Continue 是配合你日常编码的“增强版 Copilot”,支持代码自动补全及代码修改。
3.1 配置Continue
修改config.yaml文件,指定AI模型
配置如下,可以指定多个模型,强模型用于chat,edit,弱模型用于autocomplete。
name: Modern SiliconFlow Config
version: 1.0.0
schema: v1
# ==========================================
# 1. 模型大仓库 (Models Pool)
# ==========================================
models:
# 用于日常对话和文件修改的常规模型
- id: ds-v4-flash
name: deepseek-ai/DeepSeek-V4-Flash
provider: siliconflow
model: deepseek-ai/DeepSeek-V4-Flash
apiKey: "sk-pqlmjsavtowcewqzfsohwrhfhhmyppijbysyohluwczwiasg"
roles:
- chat
- edit
# 用于深度思考、修复杂 Bug 的推理模型
- id: glm-5.2-reasoning
name: zai-org/GLM-5.2
provider: siliconflow
model: zai-org/GLM-5.2
apiKey: "sk-pqlmjsavtowcewqzfsohwrhfhhmyppijbysyohluwczwiasg"
roles:
- chat
# 专门用来做代码 Tab 补全的基座模型
- id: qwen-autocomplete
name: Qwen/Qwen2.5-Coder-1.5B-Base
provider: siliconflow
model: Qwen/Qwen2.5-Coder-1.5B-Base
apiKey: "sk-pqlmjsavtowcewqzfsohwrhfhhmyppijbysyohluwczwiasg"
roles:
- autocomplete
# ==========================================
# 2. 自动补全引擎 (Tab Autocomplete)
# ==========================================
tabAutocompleteModel:
id: qwen-autocomplete
provider: siliconflow
# 补全的高级控制选项
tabAutocompleteOptions:
disable: false
debounceMs: 150
maxPrefixLines: 25
maxSuffixLines: 25
timeoutMs: 4000
acceptSuggestionsBinding: ["tab"]
# ==========================================
# 3. 上下文提供者 (Context Providers)
# ==========================================
contextProviders:
- name: code
- name: docs
- name: terminal
- name: diff3.2 使用Continue
AI chat功能:集成到vscode中,和网页版差不多,需要贴完整的代码片段才能解释。不像cline给个名字,他直接自己去检索文件,理解上下文。当然continue也有agent模式,估计大同小异,也就不再浪费tokens了。
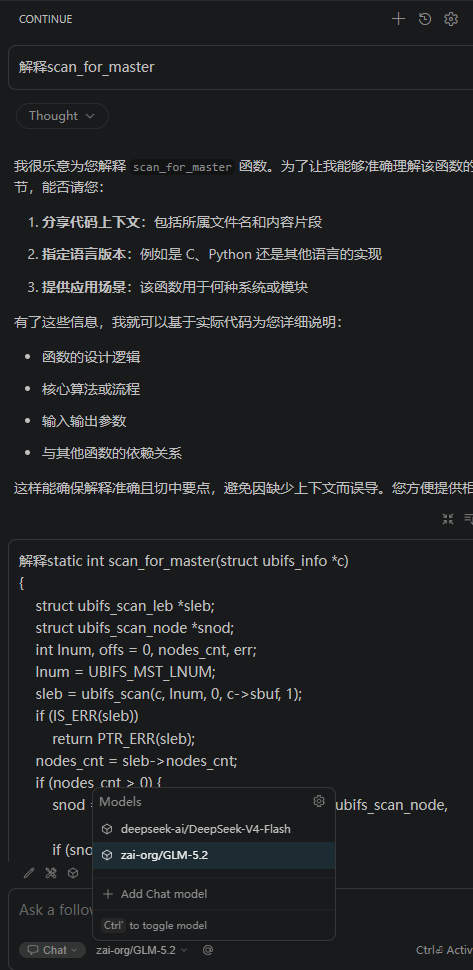
修改功能:用鼠标选中几行代码,按下 Ctrl + I,输入修改指令,可以选择对修改结果是否接受,适合局部的代码重构。
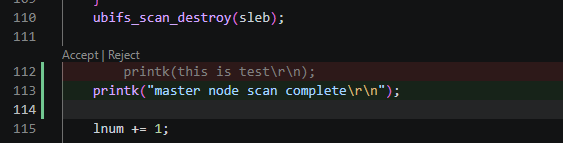
自动补全功能:显示灰色的提示代码,按tab键确认使用,适合日常编码提示。

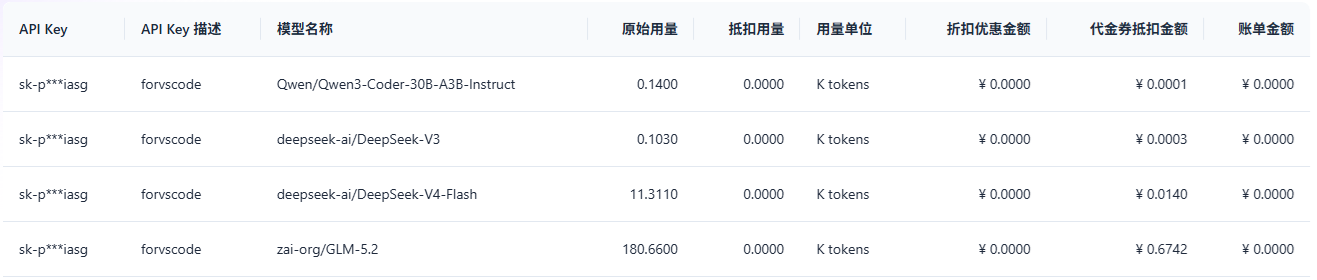
3.3 Token消耗
chat花了6毛钱,也用的挺快的,补全开销没看出来。等你上瘾,就好掏钱了。
四、Enjoy yourself

AtomGit AI 社区提供模型库、数据集、Agent、Token等资源
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)