
AI时代的知识图谱完全指南:从概念原理到企业落地的实战手册
AI时代的知识图谱完全指南:从概念原理到企业落地的实战手册
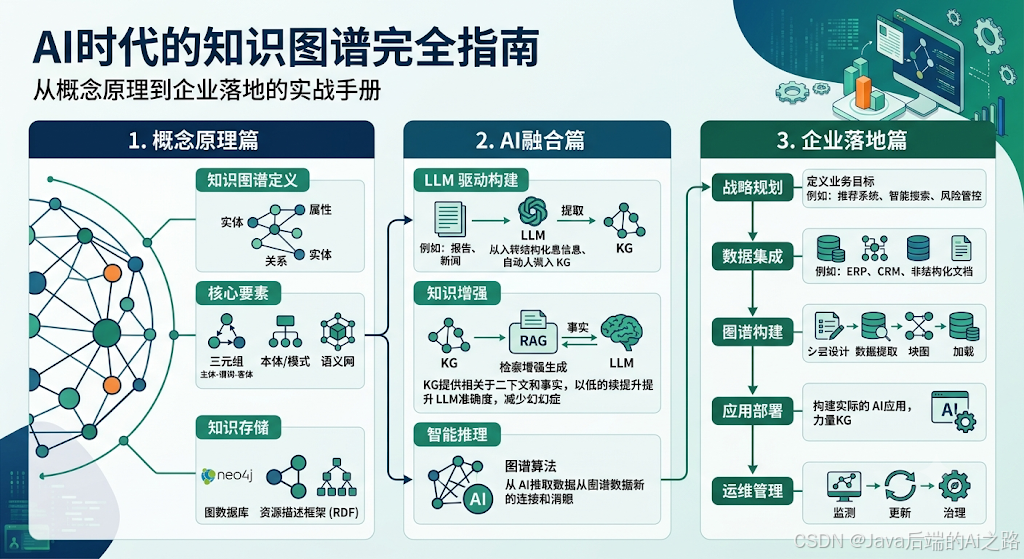
前言
当大模型在2024-2026年席卷整个AI行业时,一个被忽视的问题正在悄然浮现:大模型“幻觉”依然是企业级AI应用的最大拦路虎。
据相关研究显示,传统ChatGPT-4在临床问答上的准确率仅为37%,即使是最先进的DeepSeek-R1也仅能达到52%。但当引入基于知识图谱的GraphRAG框架后,准确率飙升至98%,幻觉率从63%骤降至1.7%。
这组数据揭示了一个关键事实:知识图谱正在从“技术冷门”走向“AI刚需”。
根据Gartner 2026年最新预测,超过60%的企业将集成知识图谱作为其AI基础设施的核心组件。图技术市场已突破50亿美元,年复合增长率超过26%,GraphRAG等新兴技术更是在多跳查询场景中实现了35-46%的性能提升。
本文将系统性地解析知识图谱的核心概念、关键技术栈、企业级落地实践,以及2026年最前沿的GraphRAG工程范式。无论你是准备面试的知识图谱工程师,还是寻求AI落地的企业技术负责人,都能在这里找到有价值的答案。
文章目录
一、大模型的四大知识困境:你正在经历哪一个
在深入知识图谱之前,我们需要先理解一个核心矛盾:文档里的知识是非结构化的,而业务逻辑是高度结构化的。
这个矛盾催生了大模型的四大知识困境:
1.1 场景一:大模型幻觉之痛
当业务人员问:“我们公司的A产品使用的芯片是哪个供应商提供的?”
传统RAG系统可能返回这样的答案:“根据我们的知识库,A产品使用的是XX公司的芯片,该芯片具有良好的性能表现。”
但业务人员真正想知道的是:芯片供应商→芯片型号→该型号的质量评级→历史供货稳定性→是否存在替代方案。
普通大模型只能回答“是什么”,无法回答“为什么”和“怎么样”。更可怕的是,大模型可能一本正经地胡说八道,把不存在的供应商说得头头是道。
根本原因:向量检索拿到的是相关文本片段,不是结构化的关系链。大模型得到的输入里,实体的完整关系网络根本没有被还原出来。
1.2 场景二:多跳推理翻车之痛
考虑这个金融风控场景:
“A公司是否涉及担保圈风险?”
真正危险的担保圈需要穿透3跳、5跳甚至更多层级才能发现闭环:
A公司 → 为B公司担保 → B公司 → 为C公司担保 → C公司 → 为A公司担保(形成闭环)
传统RAG系统面对这类问题几乎束手无策。它会召回和“A公司”、“担保”相关的若干段文本,可能是A公司的信用报告片段、某份合同的担保条款、某个新闻报道里提到的A公司与B公司的关联。大模型拿到这些碎片,努力拼凑一个回答,结论通常是:
“根据现有信息,A公司与B公司之间存在担保关系,建议进一步核查。”
这个回答有什么用?没有。它只说了一个已知事实,没有还原完整的担保网络,没有识别是否存在闭环,没有量化风险敞口,没有告诉你这个担保圈的规模。
根本原因:这不是RAG不够好,而是“分块检索”这种方式天然无法理解实体之间的逻辑关系。
1.3 场景三:知识散落之痛
在一家大型制造企业中,知识分散在无数个系统中:
- ERP系统存储物料信息
- MES系统记录工艺参数
- QMS系统管理质量标准
- 历史工单记录故障案例
- 维修手册描述解决方案
当设备发生故障时,维修人员需要登录五六个系统,切换无数标签页,才能拼凑出一个完整的故障诊断方案。更糟糕的是,这些系统之间的数据格式不统一,术语不统一,甚至连设备编号都没有关联。
核心矛盾:企业的业务逻辑是高度结构化的(设备-故障-原因-方案),但知识却是高度碎片化的(散落在无数文档、系统、邮件中)。
1.4 场景四:GraphRAG效果预期之痛
很多团队在听说GraphRAG是“银弹”后,兴冲冲地引入项目,却发现效果不如预期。
Gartner在2026年特别指出,60%的agentic analytics项目如果仅依赖MCP(Model Context Protocol)而缺乏一致的语义层,将在2028年前失败。GraphRAG虽好,但如果图谱构建质量差、多跳推理设计不当,反而可能引入更多噪声。
核心问题:GraphRAG不是万能药,它是需要精心设计的系统工程。
二、知识图谱:AI时代的知识基础设施
2.1 什么是知识图谱
知识图谱(Knowledge Graph)本质上是一种语义网络,用于表示真实世界中各种实体(人、公司、地点、产品、事件)及其之间的关系(合作、位于、生产、参与)。
2012年,Google正式提出知识图谱概念,旨在改善搜索引擎的语义理解能力。其核心思想是:将互联网上的信息构建成一张巨大的语义网络,让机器能够理解实体之间的关系,而不仅仅是关键词匹配。
核心公式:
知识图谱 = 结构化实体 + 语义化关系 + 多维属性 + 图推理能力
在技术实现上,知识图谱以三元组(Triple)的形式存储知识:
(头实体, 关系, 尾实体)
例如:
- (北京, 位于, 中国)
- (DeepSeek, 创始人, 梁文锋)
- (高血压, 合并, 糖尿病)
这种结构化的表示方式,使得知识图谱能够:
- 精确表达实体间的语义关系
- 支持多跳推理和复杂查询
- 提供可解释的推理路径
- 实现知识的增量更新和扩展
2.2 知识图谱在AI时代的双重身份
知识图谱在AI时代扮演着两个关键角色:
外部可信知识底座
当大模型面对企业私有知识、专业领域术语和复杂推理任务时,知识图谱提供结构化、可解释、可追溯的事实依据。通过GraphRAG技术将图结构知识注入大模型生成流程,可以根治大模型“幻觉”问题。
复杂关系的天然表达
知识图谱是描述真实世界中各种实体及其关系的语义网络,以“节点+边”的三元组形式进行存储。这种表示方式天然适合表达:
- 组织架构与人际关系
- 供应链与产业链
- 金融交易与担保关系
- 疾病症状与诊疗方案
2.3 技术架构全景
一个完整的知识图谱系统通常包含四层架构:
┌─────────────────────────────────────────────────────────────┐
│ 应用层 │
│ 智能问答 | 决策支持 | 推荐系统 | 风险分析 | GraphRAG │
├─────────────────────────────────────────────────────────────┤
│ 计算层 │
│ 图算法 | 推理引擎 | 语义匹配 | 子图检索 | 路径发现 │
├─────────────────────────────────────────────────────────────┤
│ 存储层 │
│ Neo4j | NebulaGraph | JanusGraph | HugeGraph │
├─────────────────────────────────────────────────────────────┤
│ 知识抽取层 │
│ NER | 关系抽取 | 属性抽取 | 实体链接 | 知识融合 │
└─────────────────────────────────────────────────────────────┘
知识抽取层:从非结构化数据中提取实体、关系和属性,是知识图谱构建的基础。
存储层:使用图数据库存储三元组,支持高效的关联查询。
计算层:提供图遍历、路径发现、社区检测等图计算能力。
应用层:将知识图谱能力封装为各种业务应用。
三、核心原理:三个硬核知识点详解
3.1 三元组表示:知识的原子结构
专业解释
在知识图谱中,三元组(Triple)是表示知识的基本单元,由头实体(Head)、关系(Relation)和尾实体(Tail)组成,也记作 SPO(Subject-Predicate-Object)。
# Cypher示例:创建三元组
CREATE (beijing:City {name: "北京"})
CREATE (china:Country {name: "中国"})
CREATE (beijing)-[:LOCATED_IN {type: "位于"}]->(china)
大白话解读
可以把三元组想象成“主语-谓语-宾语”的句子结构:
- (小明的爸爸, 是, 老师) → 小明的爸爸是老师
- (这台机器, 生产于, 2023年) → 这台机器生产于2023年
- (高血压, 可能导致, 中风) → 高血压可能导致中风
生活案例
想象你在整理自己的社交圈:
(张三, 是李四的同事, 王五所在的部门)
(张三, 参加了, Python技术分享会)
(李四, 是王五的领导, 技术部)
当你问:“张三参加的那个分享会是谁组织的?”知识图谱可以通过三元组推理出答案,而传统数据库需要复杂的JOIN操作。
3.2 图数据库查询:Cypher与SPARQL
专业解释
知识图谱的查询语言主要有两种:
- Cypher:Neo4j图数据库的查询语言,使用 ASCII 艺术风格的模式匹配语法
- SPARQL:W3C标准RDF查询语言,类似SQL的结构化查询
Cypher核心语法示例
-- 匹配模式:(人)-[关系]->(地点)
MATCH (p:Person)-[:WORKS_AT]->(c:Company)
WHERE c.name = 'DeepSeek'
RETURN p.name, p.position
-- 多跳查询:查找3跳范围内的所有关联
MATCH path = (a:Person)-[*1..3]-(b:Person)
WHERE a.name = '张三'
RETURN path
-- 路径发现:查找最短关联路径
MATCH path = shortestPath((a:Person)-[*]-(b:Person))
WHERE a.name = '张三' AND b.name = '李四'
RETURN path
SPARQL核心语法示例
PREFIX ex: <http://example.org/>
SELECT ?person ?company
WHERE {
?person ex:worksAt ?company .
?company ex:name "DeepSeek" .
}
大白话解读
如果把传统数据库比作“Excel表格”,那图数据库就是“思维导图”。
在Excel里,你要找一个员工的信息,需要知道他在哪一行;
在思维导图里,你只需要从一个节点出发,顺着连线就能找到所有关联信息。
生活案例
假设你在社交网络中查找“张三和李四的共同好友”:
-- 传统SQL:需要3次自连接
SELECT f1.friend_id
FROM friendships f1
JOIN friendships f2 ON f1.friend_id = f2.friend_id
WHERE f1.person_id = '张三' AND f2.person_id = '李四'
-- Cypher:直观的模式匹配
MATCH (zhang:Person {name: "张三"})-[:FRIEND]->(f:Person)<-[:FRIEND]-(li:Person {name: "李四"})
RETURN f.name
3.3 GraphRAG:知识增强检索的工程范式
专业解释
GraphRAG(Graph Retrieval-Augmented Generation)是将知识图谱与RAG技术深度融合的新范式,通过在传统向量检索的基础上引入知识图谱,将非结构化文本中隐式存在的实体和关系显式化、结构化。
2026年GraphRAG生态包含三大支柱:
- 全局社区摘要(微软GraphRAG):通过Leiden社区检测算法将图谱划分为层次化社区,生成社区摘要,支持全局性问题回答
- 图归因(Neo4j GraphRAG Toolkit):将检索到的子图结构作为上下文注入LLM,确保答案可追溯
- 多跳推理(LightRAG/PathRAG):通过图遍历连接分散信息,解决间接关联问题
技术架构对比
| 维度 | 传统RAG | GraphRAG |
|---|---|---|
| 知识表示 | 文本块(Chunk) | 实体-关系-实体(三元组) |
| 检索方式 | 向量相似度 | 图检索 + 向量检索 |
| 推理能力 | 单步匹配 | 多跳路径推理 |
| 可解释性 | 黑盒 | 可追溯推理路径 |
| 典型失效场景 | 跨文档关系问题 | 关系断裂(正在被解决) |
大白话解读
把知识图谱想象成一张“关系地图”:
- 传统RAG = 查字典(找到包含关键词的段落)
- GraphRAG = 看地图(看到实体之间的连接路径)
传统RAG告诉你“北京在河北旁边”,GraphRAG告诉你“北京→华北平原→河北省”,甚至能推导出“北京的空气污染可能影响河北”。
生活案例
当你问:“为什么这季度A产品客户投诉率上升?”
传统RAG回答:“根据投诉记录,A产品存在质量问题。”
GraphRAG回答:
A产品 → 使用 → B供应商芯片
B供应商 → 遭遇 → 火灾停产
导致 → 切换 → C供应商
C供应商芯片 → 存在 → 兼容性问题 → 引发 → 系统崩溃
四、核心优势对比:为什么知识图谱不可替代
4.1 知识图谱 vs 关系型数据库
| 评估维度 | 关系型数据库 | 知识图谱 |
|---|---|---|
| 数据模型 | 行与列的表格 | 节点与边的图结构 |
| 关系表达 | 外键(隐式) | 关系类型(显式) |
| 多跳查询 | JOIN复杂度随跳数指数增长 | 遍历复杂度O(k),k为路径长度 |
| 新增关系 | 可能需要schema迁移 | 无需迁移,直接添加边 |
| 适用场景 | 聚合统计、结构化数据 | 关系遍历、复杂关联分析 |
关键区别:在图数据库中,查找"Project X相关的同事的同事",查询结构不随跳数变化;在关系数据库中,每增加一跳就需要多一个JOIN。
4.2 知识图谱 vs 向量数据库+RAG
| 评估维度 | 向量RAG | 知识图谱+GraphRAG |
|---|---|---|
| 知识表示 | 文本块 | 结构化三元组 |
| 检索精度 | 语义相似度 | 关系路径匹配 |
| 多跳推理 | 弱 | 强 |
| 可解释性 | 低(黑盒向量) | 高(可见实体关系) |
| 幻觉抑制 | 一般 | 强(事实边界清晰) |
| 增量更新 | 易 | 中(需图更新) |
| 适用数据规模 | TB级 | GB~TB级 |
4.3 2026年GraphRAG三大工程范式对比
| 范式 | 代表框架 | 核心优势 | 适用场景 |
|---|---|---|---|
| 全局社区摘要 | 微软GraphRAG | 全局洞察、主题发现 | 大规模语料分析、研报生成 |
| 图归因 | Neo4j GraphRAG Toolkit | 事实准确、可追溯 | 企业知识库、医疗诊断 |
| 多跳推理 | LightRAG | 增量更新、轻量高效 | 实时问答、边缘部署 |
五、保姆级实战教程:从零构建知识图谱系统
5.1 环境准备
5.1.1 安装Neo4j图数据库
方式一:Docker部署(推荐)
# 拉取Neo4j镜像
docker pull neo4j:latest
# 启动Neo4j容器
docker run -d \
--name neo4j \
-p 7474:7474 \
-p 7687:7687 \
-v ~/neo4j/data:/data \
-v ~/neo4j/logs:/logs \
-v ~/neo4j/plugins:/plugins \
-e NEO4J_AUTH=neo4j/password123 \
neo4j:latest
# 验证启动
docker logs -f neo4j
访问 http://localhost:7474 即可进入Neo4j Browser界面。
方式二:本地安装
# macOS
brew install neo4j
brew services start neo4j
# Ubuntu/Debian
wget -O - https://debian.neo4j.com/neotechnology.gpg.key | sudo apt-key add -
echo 'deb https://debian.neo4j.com stable latest' | sudo tee /etc/apt/sources.list.d/neo4j.list
sudo apt-get update
sudo apt-get install neo4j
5.1.2 Python环境配置
# 创建虚拟环境
python -m venv kg-env
source kg-env/bin/activate # Linux/Mac
# kg-env\Scripts\activate # Windows
# 安装核心依赖
pip install neo4j python-dotenv langchain langchain-openai pymilvus sentence-transformers
5.2 Python连接Neo4j构建知识图谱
5.2.1 基础连接与实体创建
from neo4j import GraphDatabase
from dotenv import load_dotenv
import os
load_dotenv()
class KnowledgeGraphBuilder:
def __init__(self, uri, user, password):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def close(self):
self.driver.close()
def create_company_node(self, name, industry, founded_year):
"""创建公司节点"""
with self.driver.session() as session:
result = session.run("""
CREATE (c:Company {
name: $name,
industry: $industry,
founded_year: $founded_year,
created_at: datetime()
})
RETURN c
""", name=name, industry=industry, founded_year=founded_year)
return result.single()[0]
def create_person_node(self, name, position, company):
"""创建人物节点"""
with self.driver.session() as session:
result = session.run("""
CREATE (p:Person {
name: $name,
position: $position,
created_at: datetime()
})
WITH p
MATCH (c:Company {name: $company})
CREATE (p)-[:WORKS_AT {role: $position, since: date()}]->(c)
RETURN p
""", name=name, position=position, company=company)
return result.single()[0]
def create_relationship(self, from_entity, to_entity, relationship_type, properties=None):
"""创建实体间关系"""
with self.driver.session() as session:
query = f"""
MATCH (a {{name: $from_name}})
MATCH (b {{name: $to_name}})
CREATE (a)-[r:{relationship_type} {{$props}}]->(b)
RETURN a.name, type(r), b.name
"""
result = session.run(query,
from_name=from_entity,
to_name=to_entity,
props=properties or {})
return list(result)
# 使用示例
kg = KnowledgeGraphBuilder(
uri="bolt://localhost:7687",
user="neo4j",
password="password123"
)
# 创建公司
kg.create_company_node("DeepSeek", "人工智能", 2023)
kg.create_company_node("OpenAI", "人工智能", 2015)
# 创建人物并建立关系
kg.create_person_node("梁文锋", "创始人", "DeepSeek")
kg.create_person_node("Sam Altman", "CEO", "OpenAI")
# 创建公司间关系
kg.create_relationship("DeepSeek", "OpenAI", "COMPETES_WITH", {"field": "LLM"})
kg.create_relationship("DeepSeek", "中国", "LOCATED_IN", {})
kg.close()
5.2.2 批量导入知识图谱
from neo4j import GraphDatabase
import json
class BatchKnowledgeImporter:
def __init__(self, uri, user, password):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def import_from_json(self, json_file):
"""从JSON文件批量导入知识"""
with open(json_file, 'r', encoding='utf-8') as f:
data = json.load(f)
with self.driver.session() as session:
# 使用单个事务批量写入
with session.begin_transaction() as tx:
for item in data.get('entities', []):
tx.run("""
MERGE (e:Entity {
name: $name,
type: $entity_type
})
SET e += $properties
""", name=item['name'],
entity_type=item.get('type', 'Unknown'),
properties=item.get('properties', {}))
# 创建关系
for rel in item.get('relations', []):
tx.run("""
MATCH (a:Entity {name: $from_name})
MATCH (b:Entity {name: $to_name})
MERGE (a)-[r:RELATES_TO {type: $rel_type}]->(b)
""", from_name=item['name'],
to_name=rel['target'],
rel_type=rel['type'])
tx.commit()
# 示例JSON数据
sample_data = {
"entities": [
{
"name": "高血压",
"type": "疾病",
"properties": {"症状": ["头晕", "头痛"], "严重程度": "慢性"},
"relations": [
{"target": "ACEI类药物", "type": "可用药物"},
{"target": "糖尿病", "type": "常见合并症"}
]
},
{
"name": "卡托普利",
"type": "药物",
"properties": {"剂型": "片剂", "规格": "25mg"},
"relations": [
{"target": "高血压", "type": "适应症"},
{"target": "ACEI类药物", "type": "属于"}
]
}
]
}
# 导入数据
importer = BatchKnowledgeImporter("bolt://localhost:7687", "neo4j", "password123")
# importer.import_from_json('medical_knowledge.json')
5.3 图算法实战
5.3.1 路径查询
class GraphQuery:
def __init__(self, uri, user, password):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def find_shortest_path(self, start_node, end_node):
"""查找两个实体间的最短路径"""
with self.driver.session() as session:
result = session.run("""
MATCH path = shortestPath(
(a {name: $start})-[*]-(b {name: $end})
)
RETURN path, length(path) as hops
""", start=start_node, end=end_node)
return list(result)
def find_all_paths(self, start_node, end_node, max_hops=5):
"""查找所有路径(限制跳数)"""
with self.driver.session() as session:
result = session.run("""
MATCH path = (a {name: $start})-[*1..%d]-(b {name: $end})
RETURN path, length(path) as hops
ORDER BY hops
LIMIT 20
""" % max_hops, start=start_node, end=end_node)
return list(result)
def find_related_entities(self, entity_name, depth=2):
"""查找关联实体"""
with self.driver.session() as session:
result = session.run("""
MATCH (center {name: $name})-[*1..%d]-(related)
WITH related, count(*) as weight
RETURN related.name as entity,
labels(related)[0] as type,
weight
ORDER BY weight DESC
""" % depth, name=entity_name)
return list(result)
# 使用示例
query = GraphQuery("bolt://localhost:7687", "neo4j", "password123")
# 查询最短路径
paths = query.find_shortest_path("张三", "某供应商")
print(f"最短路径跳数: {paths[0]['hops']}")
# 查询关联实体
related = query.find_related_entities("A公司", depth=3)
print("3跳范围内的关联实体:")
for item in related:
print(f" - {item['entity']} ({item['type']}) - 关联权重: {item['weight']}")
5.3.2 PageRank与重要性分析
-- 在Neo4j中执行PageRank
CALL gds.pageRank.write({
nodeProjection: '*',
relationshipProjection: '*',
writeProperty: 'pageRankScore',
dampingFactor: 0.85,
maxIterations: 20
})
-- 查询最重要的节点
MATCH (n)
WHERE n.pageRankScore IS NOT NULL
RETURN n.name as entity, n.pageRankScore as importance
ORDER BY importance DESC
LIMIT 20
def pagerank_analysis(self):
"""执行PageRank分析"""
with self.driver.session() as session:
# 调用gds.pageRank算法(需要安装GDS插件)
result = session.run("""
CALL gds.pageRank.stream({
nodeQuery: 'MATCH (n) RETURN id(n) as id',
relationshipQuery: 'MATCH (a)-[r]->(b) RETURN id(a) as source, id(b) as target'
})
YIELD nodeId, score
WITH gds.util.asNode(nodeId) as node, score
WHERE node.name IS NOT NULL
RETURN node.name as entity, score
ORDER BY score DESC
LIMIT 20
""")
return list(result)
5.3.3 社区发现
-- 使用Leiden算法进行社区检测
CALL gds.leiden.write({
nodeProjection: '*',
relationshipProjection: '*',
writeProperty: 'community',
includeIntermediateCommunities: true
})
-- 分析社区结构
MATCH (n)
WHERE n.community IS NOT NULL
WITH n.community as community_id, collect(n.name) as members
RETURN community_id, size(members) as size, members
ORDER BY size DESC
LIMIT 10
def community_detection(self):
"""社区发现与成员查询"""
with self.driver.session() as session:
# 社区发现
session.run("""
CALL gds.leiden.write({
nodeProjection: '*',
relationshipProjection: '*',
writeProperty: 'community'
})
""")
# 查询各社区成员
result = session.run("""
MATCH (n)
WHERE n.community IS NOT NULL
WITH n.community as community_id, count(*) as size
ORDER BY size DESC
LIMIT 10
MATCH (m) WHERE m.community = community_id
RETURN community_id, size, collect(m.name) as members
""")
communities = []
for record in result:
communities.append({
'community_id': record['community_id'],
'size': record['size'],
'members': record['members'][:5] # 只显示前5个成员
})
return communities
5.4 Text2Cypher实战
Text2Cypher是将自然语言转换为Cypher查询的技术,是构建智能问答系统的关键能力。
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
class Text2CypherConverter:
def __init__(self, neo4j_driver, openai_api_key):
self.driver = neo4j_driver
self.llm = OpenAI(api_key=openai_api_key)
def get_schema_context(self):
"""获取图谱schema信息"""
with self.driver.session() as session:
# 获取所有节点类型
node_types = session.run("""
MATCH (n)
UNWIND labels(n) as label
RETURN DISTINCT label, count(*) as count
ORDER BY count DESC
""")
# 获取所有关系类型
rel_types = session.run("""
MATCH ()-[r]->()
RETURN DISTINCT type(r) as type, count(*) as count
ORDER BY count DESC
""")
schema = {
'node_types': [dict(r) for r in node_types],
'rel_types': [dict(r) for r in rel_types]
}
# 获取示例节点
samples = session.run("""
MATCH (n)
WITH labels(n)[0] as type, collect(n.name)[0..3] as samples
RETURN type, samples
""")
schema['samples'] = [dict(r) for r in samples]
return schema
def convert(self, user_question, schema_context=None):
"""将自然语言问题转换为Cypher查询"""
if schema_context is None:
schema_context = self.get_schema_context()
prompt = f"""你是一个Neo4j图数据库Cypher查询生成专家。
图谱Schema信息:
- 节点类型:{schema_context['node_types']}
- 关系类型:{schema_context['rel_types']}
- 示例节点:{schema_context['samples']}
请根据用户的问题生成Cypher查询语句。
注意:
1. 节点使用 `:Label {{name: '实体名'}}` 格式匹配
2. 关系使用 `-[:RELATION_TYPE]->` 或 `-[:RELATION_TYPE*1..3]->` 格式
3. 使用$参数化查询防止注入
4. 如果问题涉及数值条件,使用 WHERE 子句
5. 如果问题需要聚合,使用 WITH 和 collect/sum/count 等函数
用户问题:{user_question}
请只返回Cypher查询语句,不要包含其他解释:"""
response = self.llm.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "你是一个Neo4j Cypher查询生成专家。"},
{"role": "user", "content": prompt}
],
temperature=0
)
cypher_query = response.choices[0].message.content.strip()
# 移除可能的markdown代码块标记
cypher_query = cypher_query.replace('```cypher', '').replace('```', '')
return cypher_query
def execute_query(self, cypher_query):
"""执行生成的Cypher查询"""
with self.driver.session() as session:
result = session.run(cypher_query)
return [dict(record) for record in result]
def ask(self, question):
"""完整问答流程"""
cypher = self.convert(question)
results = self.execute_query(cypher)
return {
'question': question,
'cypher': cypher,
'results': results
}
# 使用示例
converter = Text2CypherConverter(
neo4j_driver=GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "password123")),
openai_api_key=os.getenv("OPENAI_API_KEY")
)
# 自然语言问答
result = converter.ask("DeepSeek的创始人是谁?他还在哪些公司工作过?")
print(f"生成的Cypher: {result['cypher']}")
print(f"查询结果: {result['results']}")
5.5 GraphRAG知识增强检索实战
from neo4j import GraphDatabase
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Milvus
from langchain.text_splitter import RecursiveCharacterTextSplitter
class GraphRAGRetriever:
def __init__(self, neo4j_uri, neo4j_user, neo4j_password):
self.driver = GraphDatabase.driver(neo4j_uri, auth=(neo4j_user, password))
self.embeddings = OpenAIEmbeddings()
# 初始化向量数据库
# self.vectorstore = Milvus(embedding_function=self.embeddings)
def retrieve_subgraph(self, query, max_hops=2):
"""检索与查询相关的子图"""
with self.driver.session() as session:
# 1. 找到查询中涉及的实体
# 这里简化处理,实际应用中需要用NER识别实体
entities = self._extract_entities_from_query(query)
# 2. 扩展子图
subgraph_data = []
for entity in entities:
result = session.run("""
MATCH (start {name: $entity_name})
CALL apoc.path.subgraphAll(start, {
maxLevel: $max_hops
})
YIELD nodes, relationships
RETURN nodes, relationships
""", entity_name=entity, max_hops=max_hops)
subgraph_data.append(list(result))
return self._format_subgraph(subgraph_data)
def hybrid_retrieve(self, query, top_k=5):
"""混合检索:向量 + 图检索"""
# 向量检索
# vector_results = self.vectorstore.similarity_search(query, k=top_k)
# 图检索
subgraph = self.retrieve_subrieve(query)
return {
'vector_results': [], # vector_results,
'graph_context': subgraph
}
def generate_answer(self, query, retrieved_context):
"""基于检索上下文生成答案"""
from openai import OpenAI
context_prompt = f"""
基于以下检索到的知识图谱信息回答问题。
检索到的子图信息:
{retrieved_context['graph_context']}
用户问题:{query}
请基于以上信息给出准确、可解释的回答。
"""
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "你是一个基于知识图谱的智能助手。"},
{"role": "user", "content": context_prompt}
]
)
return response.choices[0].message.content
# Neo4j需安装APOC插件以支持apoc.path.subgraphAll
# 在neo4j.conf中添加:dbms.security.procedures.unrestricted=apoc.*
5.6 知识图谱的持续构建与更新
class IncrementalKnowledgeUpdater:
"""增量更新知识图谱"""
def __init__(self, neo4j_driver):
self.driver = neo4j_driver
def add_new_entity(self, entity_data):
"""添加新实体"""
with self.driver.session() as session:
session.run("""
MERGE (e:Entity {
name: $name,
type: $entity_type
})
ON CREATE SET
e.created_at = datetime(),
e.source = $source
ON MATCH SET
e.updated_at = datetime()
SET e += $properties
""", **entity_data)
def update_entity_properties(self, entity_name, new_properties):
"""更新实体属性"""
with self.driver.session() as session:
session.run("""
MATCH (e {name: $name})
SET e += $properties,
e.updated_at = datetime()
""", name=entity_name, properties=new_properties)
def add_new_relationship(self, from_entity, to_entity, rel_type, properties=None):
"""添加新关系"""
with self.driver.session() as session:
session.run("""
MATCH (a {name: $from_entity})
MATCH (b {name: $to_entity})
MERGE (a)-[r:RELATES_TO {type: $rel_type}]->(b)
SET r += $properties,
r.created_at = datetime()
""", from_entity=from_entity,
to_entity=to_entity,
rel_type=rel_type,
properties=properties or {})
def detect_conflicts(self, entity_name):
"""检测知识冲突"""
with self.driver.session() as session:
result = session.run("""
MATCH (e {name: $name})
OPTIONAL MATCH (e)-[r1]-(v1)
WITH e, count(DISTINCT v1) as connected_count,
count(DISTINCT type(r1)) as relation_types
WHERE connected_count = 0 OR relation_types = 0
RETURN e.name as entity,
'isolated' as conflict_type,
'实体无任何关系,可能需要补充关联' as suggestion
UNION
MATCH (e {name: $name})
WITH e, e.property1 as p1
MATCH (other {name: $name, property1: p1})
WHERE id(e) <> id(other)
RETURN e.name as entity,
'duplicate' as conflict_type,
'可能存在重复实体' as suggestion
""", name=entity_name)
return list(result)
def sync_with_external_source(self, source_name, sync_function):
"""同步外部数据源"""
with self.driver.session() as session:
# 获取外部数据
external_data = sync_function()
for item in external_data:
self.add_new_entity(item)
# 记录同步状态
session.run("""
MERGE (s:SyncSource {name: $source})
SET s.last_sync = datetime()
""", source=source_name)
六、常用场景列举:知识图谱的六大落地领域
6.1 金融风控:担保圈与欺诈检测
场景痛点:
- 担保信息分散在贷款合同、工商披露、司法公告等不同数据源
- 真正危险的担保圈需要穿透3-5跳甚至更多层级才能发现闭环
- 企业的担保关系不断变化,风控结论随时面临失效
解决方案:构建企业担保关系图谱,实现:
- 自动识别"一人多企"的空壳公司集群
- 实时预警关联担保风险
- 量化风险敞口
典型案例:EasyCash基于NebulaGraph构建实时风险图谱,覆盖10亿+节点、190亿+边,关键风控查询响应时间从3秒降至毫秒级。
6.2 医疗临床:诊疗决策支持
场景痛点:
- 医疗数据分散在HIS、LIS、PACS等多个系统
- 诊断结果、检验报告、影像资料之间缺乏语义关联
- 新药上市后需要快速让医生了解使用方法
解决方案:构建疾病-症状-药物-基因多维知识网络,实现:
- 症状自动关联潜在疾病及用药方案
- 药物相互作用风险提示
- 相似历史病例推荐
典型案例:某三甲医院临床辅助决策系统使住院医师用药错误率下降35%,检查项目漏检率下降28%。
6.3 企业合规:智能审计与风险预警
场景痛点:
- 合规规则分散在各类政策文件中
- 人工审计效率低、易遗漏
- 风险事件发现滞后
解决方案:构建法规-条款-案例知识图谱,实现:
- 自动审查项目资料的合规性
- 识别异常关联和潜在风险
- 生成审计报告
典型案例:国网上海经研院110千伏输变电工程评审从数小时缩短至4分30秒,200+审查点全覆盖,准确率达80%。
6.4 工业制造:设备运维与质量追溯
场景痛点:
- 维修知识分散在工单、故障报告、维修手册中
- 设备型号增多后知识维护成本高
- 质量问题追溯困难
解决方案:构建设备-故障-原因-方案知识图谱,实现:
- 故障代码自动推荐维修方案
- 秒级正向和逆向质量追溯
- 预测性维护
典型案例:某大型装备制造企业设备平均维修时间缩短25%,紧急停机次数下降40%。
6.5 法律判例:类案推送与法条关联
场景痛点:
- 法官需要查找类似判例辅助裁判
- 法律条文之间的关联复杂
- 判决书信息提取困难
解决方案:构建案件-法条-裁判要点知识图谱,实现:
- 相似案例智能推送
- 裁判要点关联分析
- 法律条文引用网络
6.6 GraphRAG智能文档助手
场景痛点:
- 企业内部文档检索效率低
- 跨文档关联信息难以发现
- 传统RAG无法回答全局性问题
解决方案:构建文档知识图谱+GraphRAG系统,实现:
- 全局性问题回答(如"这份报告的核心主题是什么")
- 多跳关联推理
- 可追溯的答案来源
七、面试官高频面试题
7.1 简述知识图谱的构建过程及其主要步骤
参考答案:
知识图谱的构建过程主要包括以下几个阶段:
-
知识抽取:从非结构化或半结构化数据中提取实体、关系和属性
- 实体识别(NER):使用BiLSTM-CRF、BERT等模型识别文本中的人名、地名、机构名等实体
- 关系抽取(RE):识别实体之间的语义关系,如"位于"、"任职于"等
- 属性抽取:从文本中抽取实体的属性信息
-
知识融合:将来自不同来源的知识进行整合
- 实体对齐:识别不同数据源中指代同一实体的表达
- 实体消歧:消除同一实体名称的歧义
- 冲突检测与解决:处理不同来源知识的冲突
-
知识加工:对知识进行推理和补全
- 知识推理:基于已有知识推导出新的知识
- 质量评估:检查知识的准确性、完整性
- 知识补全:补充缺失的知识
-
知识存储:选择合适的存储方式
- 图数据库:Neo4j、NebulaGraph等
- RDF存储:支持语义查询
- 混合存储:图+向量
7.2 知识图谱与关系型数据库的核心区别是什么
参考答案:
| 维度 | 关系型数据库 | 知识图谱 |
|---|---|---|
| 数据模型 | 二维表格 | 图结构(节点+边) |
| 关系表达 | 外键约束(隐式) | 关系类型(显式) |
| 多跳查询 | JOIN复杂度O(n^k) | 遍历复杂度O(k) |
| 关系类型 | 单一外键关系 | 多种关系类型 |
| Schema | 刚性,预定义 | 灵活,可扩展 |
| 查询语言 | SQL | Cypher/SPARQL |
| 适用场景 | 聚合统计、结构化CRUD | 关系分析、推理查询 |
核心区别:知识图谱将关系作为一等公民(First-Class Citizen),使得多跳关系查询和复杂关系推理变得自然高效。
7.3 请解释什么是GraphRAG,它解决了传统RAG的哪些问题
参考答案:
GraphRAG(Graph Retrieval-Augmented Generation)是将知识图谱与RAG技术深度融合的新范式。
解决传统RAG的问题:
-
语义断裂问题:传统RAG把完整概念切到不同块里,关键信息丢失;GraphRAG通过三元组保持知识完整性
-
关系丢失问题:传统RAG忽略实体间的因果、时序关系;GraphRAG显式建模关系,支持多跳推理
-
多跳推理问题:传统RAG无法处理"A影响B,B影响C,A对C的影响"这类问题;GraphRAG通过图遍历实现
-
全局性问题:传统RAG难以回答"这份文档的主题是什么";GraphRAG通过社区摘要提供全局视野
-
幻觉问题:传统RAG依赖向量相似度可能引入噪声;GraphRAG基于结构化知识生成,降低幻觉风险
7.4 什么是实体消歧?如何实现
参考答案:
实体消歧(Entity Disambiguation)是解决同名实体不同含义的技术。
典型案例:
- "苹果"可能是水果、公司(Apple)、电影
- 需要根据上下文判断具体指代
实现方法:
-
基于知识库的方法:利用Wikipedia、Freebase等知识库计算语义相似度
-
基于上下文的方法:
- 构建实体的上下文向量表示
- 计算候选实体与查询上下文的相似度
-
基于图的方法:
- 构建词语共现网络
- 利用PageRank等算法计算词语重要性
-
深度学习方法:
- 使用BERT等预训练模型
- 端到端学习消歧
7.5 知识图谱嵌入(Knowledge Graph Embedding)的作用是什么
参考答案:
知识图谱嵌入将实体和关系映射到低维向量空间,主要作用包括:
-
知识表示学习:将离散的符号知识转化为连续的向量表示,便于计算机处理
-
知识补全:通过向量空间的距离和相似性度量,预测缺失的关系
- 链接预测:如 TransE、DistMult、RotatE等模型
-
下游任务支持:
- 推荐系统:实体嵌入作为特征
- 问答系统:问题-答案匹配
- 语义搜索:向量相似度检索
-
计算效率:向量运算比图遍历更高效,适合大规模知识图谱
7.6 在实际项目中如何评估知识图谱的质量
参考答案:
知识图谱质量评估通常从以下维度进行:
-
准确性:
- 人工抽样验证
- 与权威数据源对比
- 使用标注数据集评估抽取模型
-
完整性:
- 实体覆盖率:关键实体是否被覆盖
- 关系覆盖率:重要关系是否被抽取
- 属性填充率:实体属性是否完整
-
一致性:
- 类型一致性:实体类型是否符合定义
- 关系一致性:是否存在矛盾的关系
- 数值一致性:属性值是否在合理范围
-
时效性:
- 知识更新频率
- 新增知识的及时性
-
可用性:
- 查询响应时间
- 支撑业务场景的效果
- 用户满意度
7.7 如何处理知识图谱中的缺失关系数据
参考答案:
处理缺失关系数据的方法包括:
-
基于规则的方法:
- 利用预定义规则推导关系
- 适用于具有明确模式的知识
-
基于嵌入的方法:
- TransE:h + r ≈ t
- TransR:实体和关系在不同的语义空间
- 利用向量距离预测缺失关系
-
基于路径的方法:
- 挖掘实体间的路径信息
- 利用路径特征预测关系
- Path Ranking Algorithm (PRA)
-
基于神经网络的方法:
- 图神经网络(GNN)
- 图注意力网络(GAT)
- 结合多源信息进行关系预测
-
主动学习:
- 识别高置信度缺失关系
- 人工标注补充训练数据
7.8 你为什么选择应聘知识图谱工程师岗位
参考答案(示例):
我选择应聘知识图谱工程师岗位,主要基于以下考虑:
技术兴趣:
- 知识图谱是连接数据与智能的桥梁,具有广阔的应用前景
- 涉及NLP、图数据库、机器学习等多个技术领域,具有挑战性
- 知识图谱能够解决实际问题,如改善大模型的幻觉问题
职业发展:
- GraphRAG等新技术正在快速发展,处于行业上升期
- 企业对知识图谱的需求日益增长,就业前景好
- 技术栈横跨多个领域,有利于构建全面的技术能力
个人优势:
- 对图论和关系建模有浓厚兴趣
- 具备NLP和数据处理的相关经验
- 善于从复杂数据中提炼结构化知识
价值创造:
- 知识图谱能够真正帮助企业解决数据孤岛问题
- 通过知识组织优化,可以提升AI系统的准确性和可解释性
- 希望将技术能力转化为实际的业务价值
八、企业级实战指导
8.1 技术选型决策树
项目需求评估
│
├─ 数据规模 < 100万节点
│ └─ 推荐:Neo4j社区版 / SQLite
│
├─ 数据规模 100万 ~ 10亿节点
│ ├─ 追求生态成熟 → Neo4j企业版
│ └─ 追求高性能 → NebulaGraph / TigerGraph
│
└─ 数据规模 > 10亿节点
└─ 推荐:NebulaGraph分布式版 / Amazon Neptune
│
├─ 需要语义推理
│ └─ RDF数据库 + SPARQL + 推理引擎
│
└─ 需要向量检索
└─ Neo4j向量索引 / Milvus + Neo4j混合架构
8.2 质量控制策略
三元组抽取质量控制:
class TripleQualityControl:
def __init__(self, llm):
self.llm = llm
def validate_triple(self, triple):
"""验证三元组的有效性"""
head, relation, tail = triple
# 1. 格式校验
if not all([head, relation, tail]):
return False, "三元组格式不完整"
# 2. 合理性校验
prompt = f"""
判断以下三元组是否合理:
头实体:{head}
关系:{relation}
尾实体:{tail}
如果合理返回"合理",如果不合理说明原因。
"""
response = self.llm.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
if "合理" in result:
return True, "验证通过"
else:
return False, result
def multi_model_voting(self, triples, models):
"""多模型投票保真"""
all_results = []
for model in models:
results = [self.extract_triples(text, model=model) for text in texts]
all_results.append(results)
# 统计一致性
final_triples = []
for i, triple in enumerate(all_results[0]):
votes = sum(1 for r in all_results if r[i] == triple)
if votes >= len(models) / 2:
final_triples.append(triple)
return final_triples
质量评估指标:
| 指标 | 定义 | 计算方式 |
|---|---|---|
| 准确率 | 抽取正确的三元组/总抽取数 | TP/(TP+FP) |
| 召回率 | 抽取正确的三元组/应抽取数 | TP/(TP+FN) |
| F1值 | 准确率和召回率的调和平均 | 2PR/(P+R) |
| 实体对齐率 | 正确对齐的实体对/总实体对 | 匹配数/总数 |
| 关系完整率 | 完整关系数/理论关系数 | 实际关系/理论关系 |
8.3 GraphRAG工程化落地路径
阶段一:知识图谱基础建设(4-8周)
- 需求分析与本体设计
- 数据源接入与清洗
- 知识抽取流水线搭建
- 图数据库部署与导入
- 基础查询接口开发
阶段二:GraphRAG能力集成(4-6周)
- 向量索引构建
- 图检索与向量检索融合
- LLM生成能力集成
- Prompt工程优化
- 基础问答界面开发
阶段三:生产优化与治理(持续)
- 性能监控与优化
- 质量评估与反馈
- 增量更新机制
- 领域适配微调
- 全链路可观测性建设
8.4 持续更新与治理
class KnowledgeGovernance:
"""知识治理框架"""
def __init__(self, neo4j_driver):
self.driver = neo4j_driver
def monitor_quality(self):
"""监控知识图谱质量"""
with self.driver.session() as session:
# 孤立节点检测
orphans = session.run("""
MATCH (n)
WHERE NOT (n)--()
RETURN count(n) as orphan_count
""")
# 关系分布
rel_dist = session.run("""
MATCH ()-[r]->()
WITH type(r) as rel_type, count(*) as cnt
RETURN rel_type, cnt
ORDER BY cnt DESC
""")
# 实体分布
entity_dist = session.run("""
MATCH (n)
UNWIND labels(n) as label
RETURN label, count(*) as cnt
ORDER BY cnt DESC
""")
return {
'orphan_nodes': list(orphans),
'relation_distribution': list(rel_dist),
'entity_distribution': list(entity_dist)
}
def detect_stale_knowledge(self, threshold_days=30):
"""检测过时知识"""
with self.driver.session() as session:
result = session.run("""
MATCH (n)
WHERE n.updated_at < datetime() - duration({{days: {}}})
RETURN n.name as entity, n.updated_at as last_update
ORDER BY last_update
""".format(threshold_days))
return list(result)
def trigger_refresh(self, entity_name):
"""触发知识刷新"""
# 标记为待更新
with self.driver.session() as session:
session.run("""
MATCH (n {name: $name})
SET n.needs_refresh = true,
n.refresh_requested = datetime()
""", name=entity_name)
8.5 生产环境避坑指南
坑点一:图谱规模预估不足
- 问题:上线后发现查询延迟过高
- 解决:在设计阶段进行容量评估,预留扩展空间
坑点二:抽取质量忽视
- 问题:图谱中大量错误三元组导致业务不可用
- 解决:建立严格的质量评估流程,引入人工审核
坑点三:增量更新缺失
- 问题:图谱构建后无法更新,业务价值快速衰减
- 解决:从一开始就设计增量更新机制
坑点四:Schema设计不合理
- 问题:后期查询效率低或难以扩展
- 解决:充分进行业务调研,预留扩展字段
坑点五:性能测试不充分
- 问题:生产环境性能严重下降
- 解决:模拟真实业务量进行压测
8.6 2026年前沿趋势与未来展望
趋势一:知识图谱与大模型的深度融合
- Text2Cypher能力持续增强
- 知识增强微调(Knowledge-Enhanced Fine-tuning)
- 大模型作为外部记忆体
趋势二:动态知识图谱
- 实时数据驱动的知识更新
- 事件图谱(Event Graph)与时序推理
- 主动学习与持续学习
趋势三:多模态知识图谱
- 图文音视多模态实体统一建模
- 跨模态关系推理
- 多模态RAG
趋势四:可解释AI的核心基础设施
- Gartner预测:语义层和知识图谱将成为Agentic AI的基础设施
- 知识图谱提供XAI所需的可追溯性和可解释性
- Context Graph与Knowledge Graph协同
趋势五:标准化与生态融合
- 本体标准化(FHIR、OMOP、SNOMED CT等)
- 跨平台知识共享
- 与Agent系统的深度集成
九、总结
知识图谱作为AI时代的知识基础设施,正在从“技术冷门”走向“行业刚需”。无论是根治大模型幻觉,还是实现复杂关系推理,知识图谱都展现出了不可替代的价值。
2026年,GraphRAG已经成为企业级AI应用的标准配置。通过本文的讲解,你应该已经掌握了:
- 核心概念:三元组表示、图数据库查询、GraphRAG原理
- 实战技能:Neo4j操作、图算法、Text2Cypher、GraphRAG实现
- 工程思维:技术选型、质量控制、生产优化
- 面试准备:8道高频面试题及参考答案
知识图谱的学习是一个持续的过程。建议你:
- 动手实践:从Neo4j开始,构建自己的小规模知识图谱
- 深入场景:选择一个感兴趣的行业领域进行深耕
- 关注前沿:跟踪GraphRAG、知识图谱嵌入等领域的最新进展
- 工程落地:尝试将知识图谱能力集成到实际项目中
希望本文能够帮助你系统性地掌握知识图谱的核心知识,为你的学习和工作带来帮助。
参考来源:
- Gartner: “Knowledge Graphs: The Healthcare & Life Science CIO’s Path to AI Precision and Data Value” (January 2026)
- Microsoft GraphRAG: https://github.com/microsoft/graphrag
- Neo4j Text2Cypher Guide (2026)
- 《2026年RAG技术全景演进》- 腾讯云开发者社区
- 《GraphRAG开源生态全景》- 腾讯云开发者社区
- 《大模型搭建知识图谱实战指南》- BetterYeah
声明:本文为原创文章,如需转载,请联系作者获得授权,并注明出处。

AtomGit AI 社区提供模型库、数据集、Agent、Token等资源
更多推荐

 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)