
Codex 被放到更重要的位置后,开发者选 AI 编程工具要先看任务层级
Business Insider 报道提到,AI 公司正在进入彼此的产品领域,AI 编程工具、应用生成、Agent 产品的边界正在变得重叠。Reuters 报道称,OpenAI 正计划把 ChatGPT 改造成更像“superapp”的综合入口,新的方向会更突出 Codex、AI agents、图像生成以及外部服务集成。AI 进入开发流程,不代表把人拿掉,而是让人从重复劳动中抽出来,去做判断、验证
- 这次热点真正值得开发者关注的,不是“又出了新功能”
最近关于 ChatGPT 的一个变化,开发者应该认真看一下。
Reuters 报道称,OpenAI 正计划把 ChatGPT 改造成更像“superapp”的综合入口,新的方向会更突出 Codex、AI agents、图像生成以及外部服务集成。
如果只从普通用户角度看,这像是 ChatGPT 的一次产品改版。
但从开发者角度看,它更像一个信号:AI 编程工具正在从“问答窗口”进入“开发工作流”。
过去很多人用 AI 写代码,大概是这样:
复制一段代码给 AI
问它哪里有问题
让它给修改建议
自己复制回来
手动测试
这种方式虽然低效,但风险也相对低。
因为 AI 没有直接进入你的仓库,没有改文件,没有跑命令,也没有参与 PR。
现在不一样了。
OpenAI 的 Codex 页面已经把 Codex 定位为 coding agent,用来帮助开发者 build and ship。OpenAI 也提到,Codex 可以理解大型代码库、使用工具、修改代码、运行测试,并为人工 review 准备工作。
这意味着开发者要面对的问题不再是:
AI 能不能写代码?
而是:
AI 应该在开发流程里做到哪一步?
哪些任务能交给它?
哪些任务只能让它辅助?
哪些任务必须人工主导?
这才是现在 CSDN 开发者真正该关心的问题。
- 不要先问工具强不强,先问任务属于哪一层
很多人在选 AI 编程工具时,第一反应是问:
Codex、Claude Code、Cursor、Copilot,到底哪个更强?
这个问题并不是完全没价值,但顺序错了。
更合理的顺序应该是:
我现在的任务属于哪一层?
这个任务能不能验证?
AI 改错后能不能回滚?
是否需要 review?
是否涉及权限、支付、数据库、部署等高风险模块?
同样叫“写代码”,任务差异非常大。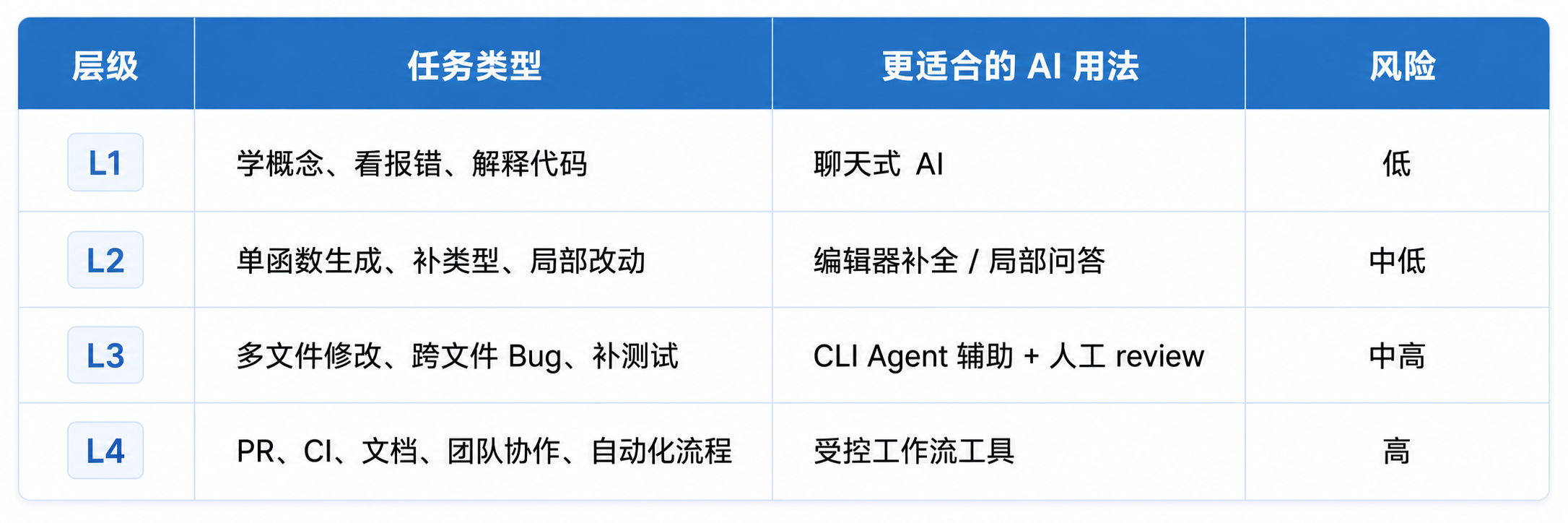
这张表的核心不是限制 AI,而是防止用错工具深度。
一个新手只是想理解报错,没必要一上来用 CLI Agent。
一个团队想把 AI 接进 PR 流程,也不能只靠聊天式问答。
不同层级,应该对应不同工具、不同权限和不同审核方式。
- L1:学习问答,聊天式 AI 通常够用
第一层最适合新手,也最容易被忽略。
比如:
- 解释一段代码;
- 看懂 Python、JavaScript、Java 报错;
- 理解 SQL 查询为什么不对;
- 让 AI 用简单例子解释闭包、递归、Promise;
- 让 AI 帮你拆学习路线。
这类任务的共同点是:AI 不需要改项目。
它只需要解释、举例、拆步骤。
你不需要给它仓库权限,也不需要让它执行命令。
一个适合新手的 Prompt 可以这样写:
我正在学习 JavaScript。
请解释下面这段代码为什么报错。
要求:
1. 先用一句话说明错误原因。
2. 再逐行解释代码执行过程。
3. 不要直接给最终答案,先给排查思路。
4. 最后给一个最小修改示例。
这个阶段最重要的是“理解”,不是“自动完成”。
所以 L1 不建议一上来就用 Agent。
因为 Agent 会引入文件读取、命令执行、权限、上下文管理等复杂因素,对学习问答来说反而是负担。
- L2:局部补全,关键是你自己能看懂、能测试、能撤回
第二层开始进入真实代码修改。
典型任务包括:
- 写一个工具函数;
- 补 TypeScript 类型;
- 改一小段判断逻辑;
- 给函数补测试样例;
- 增加注释;
- 改一个局部 UI 展示逻辑。
这类任务可以用编辑器补全,也可以把局部代码贴给 AI 让它辅助。
但是这里有一个常见误区:
局部代码看起来对,不代表项目整体没问题。
比如 AI 给你写了一个 formatPrice 函数:
function formatPrice(value: number): string {
return `¥${value.toFixed(2)}`
}
看起来没问题,但真实项目里可能还有这些情况:
value可能是null;- 后端返回的是字符串;
- 多语言环境不一定用人民币;
- 某些页面不需要保留两位小数;
- 旧代码依赖的是另一个格式。
所以 L2 的核心判断标准是: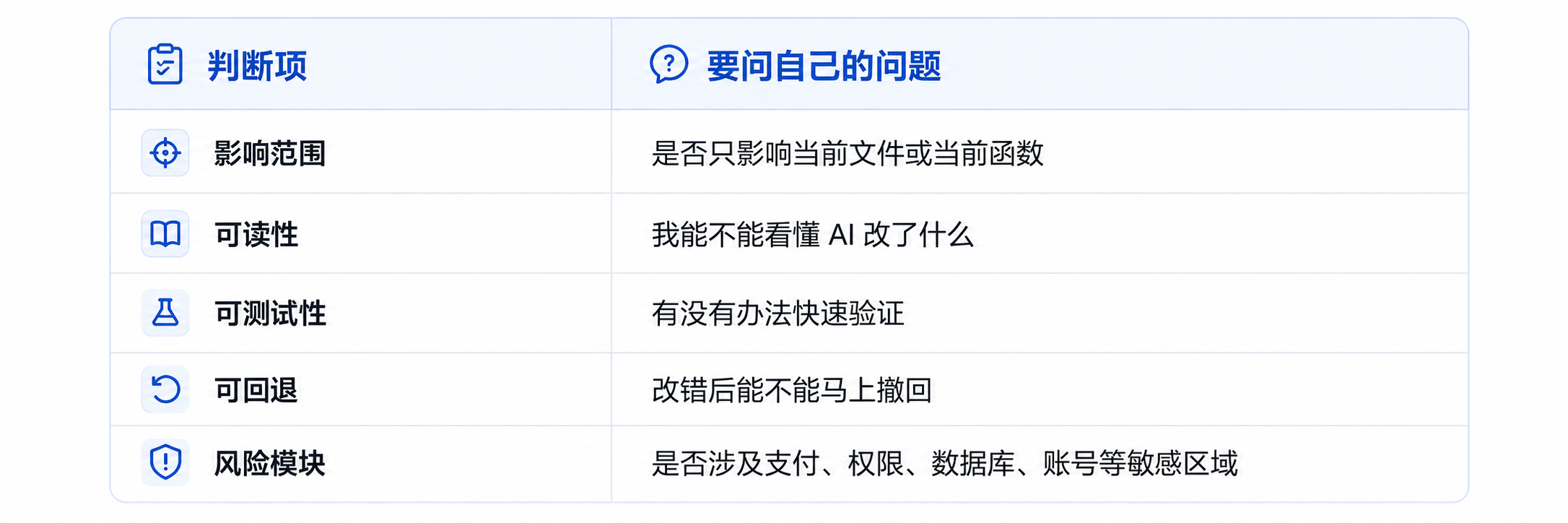
一个适合 L2 的 Prompt 可以这样写:
请只修改下面这个函数,不要改动其他逻辑。
目标:
1. 处理 value 为 null 或 undefined 的情况。
2. 保持原有返回格式。
3. 给出 3 个测试用例。
4. 说明这个修改可能影响哪些调用方。
注意这里的关键词是“只修改”“测试用例”“影响哪些调用方”。
这能限制 AI 不要顺手重构。
- L3:多文件修改,必须看 diff、跑测试、做 review
第三层是很多开发者真正容易踩坑的地方。
比如:
- 修一个跨文件 Bug;
- 同步前后端字段;
- 改一个页面涉及多个组件;
- 增加接口参数并同步类型;
- 补测试;
- 调整配置文件。
这类任务开始需要 AI 理解项目上下文,也可能涉及多个文件。
Codex、Claude Code 这类工具在这个层级会更有价值,但也更容易带来风险。
关于 AI coding tools 的工程问题研究显示,Claude Code、Codex、Gemini CLI 这类工具常见问题包括 API、集成、配置、终端问题和命令失败;研究还提到,超过 67% 的 bugs 与功能相关,API/集成/配置错误也是重要根因。
这说明什么?
说明 AI 编程工具不是“只要模型强就行”。
它还受到工具调用、命令执行、配置、上下文、终端环境影响。
所以 L3 任务必须有边界。
可以给 AI 这样的任务描述:
请修复用户列表筛选条件失效的问题。
约束:
1. 只分析和用户列表筛选相关的文件。
2. 不要重构无关代码。
3. 不要修改登录、权限、支付、数据库迁移相关文件。
4. 先列出可能影响的文件和调用链。
5. 给出最小修改方案。
6. 修改后必须说明需要运行哪些测试。
7. 输出变更摘要、风险点和回滚方式。
L3 至少要保留四道工程边界:
- 看 diff:AI 改了哪些文件,必须逐项看。
- 跑测试:不能只看 AI 的解释,要跑单测或关键路径测试。
- 人工 review:尤其是跨文件修改,必须有人确认。
- 可回滚:最好在独立分支上改,避免直接污染主分支。
L3 的原则是:
AI 可以帮你改,但不能替你负责。
- L4:团队工作流,不要绕过 Git、CI 和权限
第四层是团队级工作流。
典型场景包括:
- AI 根据 issue 生成 PR;
- AI 自动补测试;
- AI 更新文档;
- AI 参与 review;
- AI 和 CI/CD 联动;
- AI 在多个分支或 worktree 中处理任务。
这类能力听起来很强,但必须有制度。
Business Insider 报道提到,AI 公司正在进入彼此的产品领域,AI 编程工具、应用生成、Agent 产品的边界正在变得重叠。这对开发团队意味着:工具会越来越多,但选择成本也会更高。
团队接入 AI 编程工具前,建议先检查下面这些项: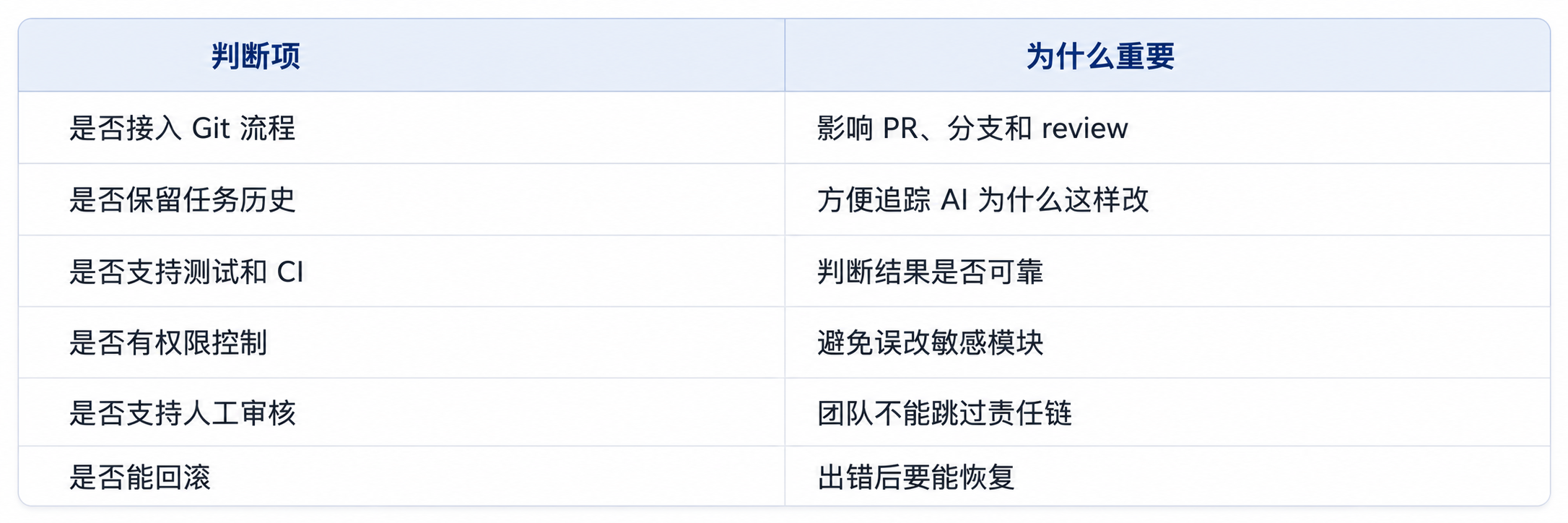
果团队没有测试、没有 review、没有权限边界,就不建议直接进入 L4。
一个团队级 AI 编程工具真正该做的,不是绕过工程制度,而是融入工程制度。
- 一个简单的 AI 编程任务分层函数
如果你想把 AI 编程请求做成内部工具,可以先写一个简单的任务分层逻辑。
下面是伪代码示例:
from enum import Enum
class ToolLevel(str, Enum):
CHAT = "chat"
COMPLETION = "completion"
AGENT_ASSISTED = "agent_assisted"
HUMAN_LED = "human_led"
class RiskLevel(str, Enum):
LOW = "low"
MEDIUM = "medium"
HIGH = "high"
def classify_task(task: dict) -> tuple[ToolLevel, RiskLevel, list[str]]:
task_type = task.get("task_type")
files_count = task.get("files_count", 0)
touches_sensitive_area = task.get("touches_sensitive_area", False)
has_tests = task.get("has_tests", False)
requires_command = task.get("requires_command", False)
warnings = []
if touches_sensitive_area:
warnings.append("涉及敏感模块,必须人工主导")
return ToolLevel.HUMAN_LED, RiskLevel.HIGH, warnings
if task_type in ["explain_code", "read_error", "learn_concept"]:
return ToolLevel.CHAT, RiskLevel.LOW, warnings
if files_count <= 1 and task_type in ["write_function", "add_type", "add_comment"]:
if not has_tests:
warnings.append("建议补充测试或手动验证")
return ToolLevel.COMPLETION, RiskLevel.MEDIUM, warnings
if files_count > 1:
warnings.append("多文件修改必须查看 diff")
warnings.append("修改后必须运行测试")
if requires_command:
warnings.append("执行命令前需要人工确认")
return ToolLevel.AGENT_ASSISTED, RiskLevel.HIGH, warnings
return ToolLevel.CHAT, RiskLevel.MEDIUM, ["无法明确分类,默认保守处理"]
这个函数不复杂,但思路很重要:
- 不同任务进入不同 AI 使用层级;
- 敏感模块默认人工主导;
- 多文件任务默认高风险;
- 没有测试时提醒人工验证;
- 不能分类时保守处理。
这比“所有任务都交给 Agent”安全得多。
- 输出给开发者的建议,最好固定成结构化格式
如果你要把这个逻辑接入团队工具,可以让系统输出固定 JSON:
{
"recommended_level": "agent_assisted",
"risk_level": "high",
"allowed_actions": [
"read_related_files",
"suggest_patch",
"generate_tests"
],
"blocked_actions": [
"auto_commit",
"modify_payment_module",
"run_deploy_command"
],
"required_checks": [
"review_diff",
"run_unit_tests",
"human_review"
],
"rollback_required": true
}
这种输出比一句“可以用 AI”更有价值。
它明确告诉开发者:
- AI 可以做什么;
- AI 不能做什么;
- 人必须检查什么;
- 是否需要回滚方案。
这才是工程化的 AI工具选择。
- 传统开发方式 vs AI 辅助方式
AI 进入开发流程,不代表把人拿掉,而是让人从重复劳动中抽出来,去做判断、验证和责任承担。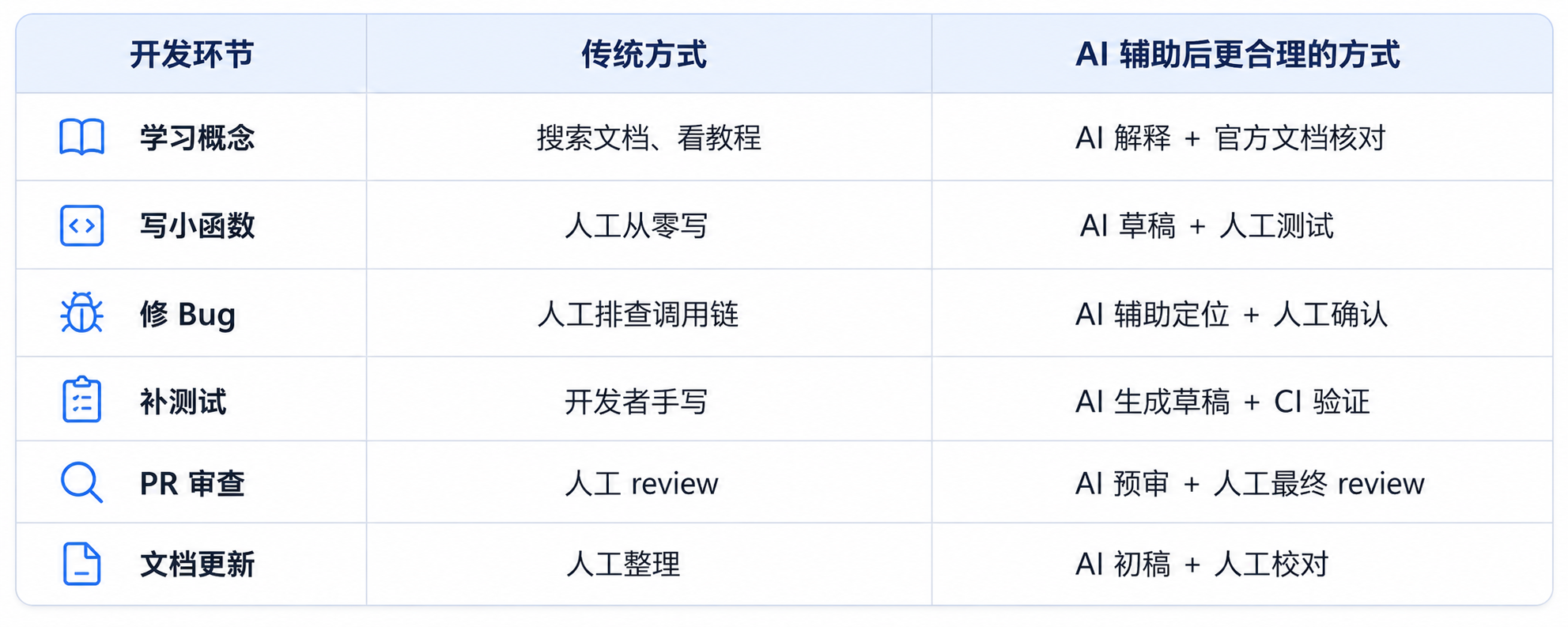
关键不是“让 AI 全自动”,而是把 AI 放到合适的位置。
- 开发者最该避免的 5 个坑
坑 1:把能跑当成没问题
代码能跑,只说明当前路径没炸。
边界条件、异常处理、权限逻辑、数据一致性仍然要检查。
坑 2:让 AI 顺手重构
很多 bug 本来只需要小改,但 AI 可能顺手重构一大片。
这会增加 review 成本,也增加新 bug 风险。
坑 3:跳过 diff
AI 的总结不等于真实改动。
必须看 diff。
坑 4:没有测试就合并
没有测试,至少也要有手动验证清单。
尤其是多文件修改,不能只凭 AI 解释。
坑 5:没有回滚方案
AI 进入团队流程后,最怕出了问题无法恢复。
分支、提交、回滚路径必须提前想好。
- 结论:AI 编程工具不是越强越好,而是越匹配越好
ChatGPT 正在向综合入口发展,Codex 也被放到更重要的位置。
AI 编程工具会越来越像开发工作流的一部分,这是趋势。
但开发者不能只看“谁最强”。
真正要看的是:
- 当前任务属于哪一层;
- 是否需要读多个文件;
- 是否能跑测试;
- 是否必须看 diff;
- 是否需要人工 review;
- 是否涉及敏感模块;
- 出错后能不能回滚。
如果你只是学习问答,聊天式 AI 够用。
如果你只是局部补全,编辑器辅助就很合适。
如果你要做多文件修改,可以考虑 Agent,但必须有 diff、测试和 review。
如果你要接团队工作流,权限、CI、日志和回滚必须先设计好。

AtomGit AI 社区提供模型库、数据集、Agent、Token等资源
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)