
Day 8:手撸一个豆包!流式输出 + 工具调用 + Web聊天应用
文章摘要(150字以内): Java程序员宸一用Python实现了一个类似ChatGPT的Web聊天应用,核心是流式输出和工具调用功能。他通过Python的yield生成器实现流式响应,结合SSE协议推送分块数据,并解决了工具调用的难点——当AI返回工具调用请求时暂停流式,执行工具后继续生成响应。应用还包含SQLite持久化、多会话管理等完整功能,采用FastAPI构建后端,最终实现了一个具备打字
🤖 系列:Java 工程师转 AI Agent 3 个月学习计划
👤 作者:宸丶一 | 28 岁 Java 程序员,规划狂魔,周日肝了一整天
🎯 今日目标: 从 yield 生成器到完整 ChatGPT 风格的 Web 聊天应用
💬 个人格言: 代码改不改变世界我不知道,但先让我准时下班。
前言
大家好,我是宸一,一个28岁的Java程序员。
今天是第8天,周日,本来计划只学一个"流式输出",结果越写越上头,直接从 yield 生成器一路撸到了一个完整的 Web 聊天应用。
有侧边栏、有多会话管理、有流式打字效果、有工具调用、有 SQLite 持久化——本质上就是个迷你豆包。
先看成果: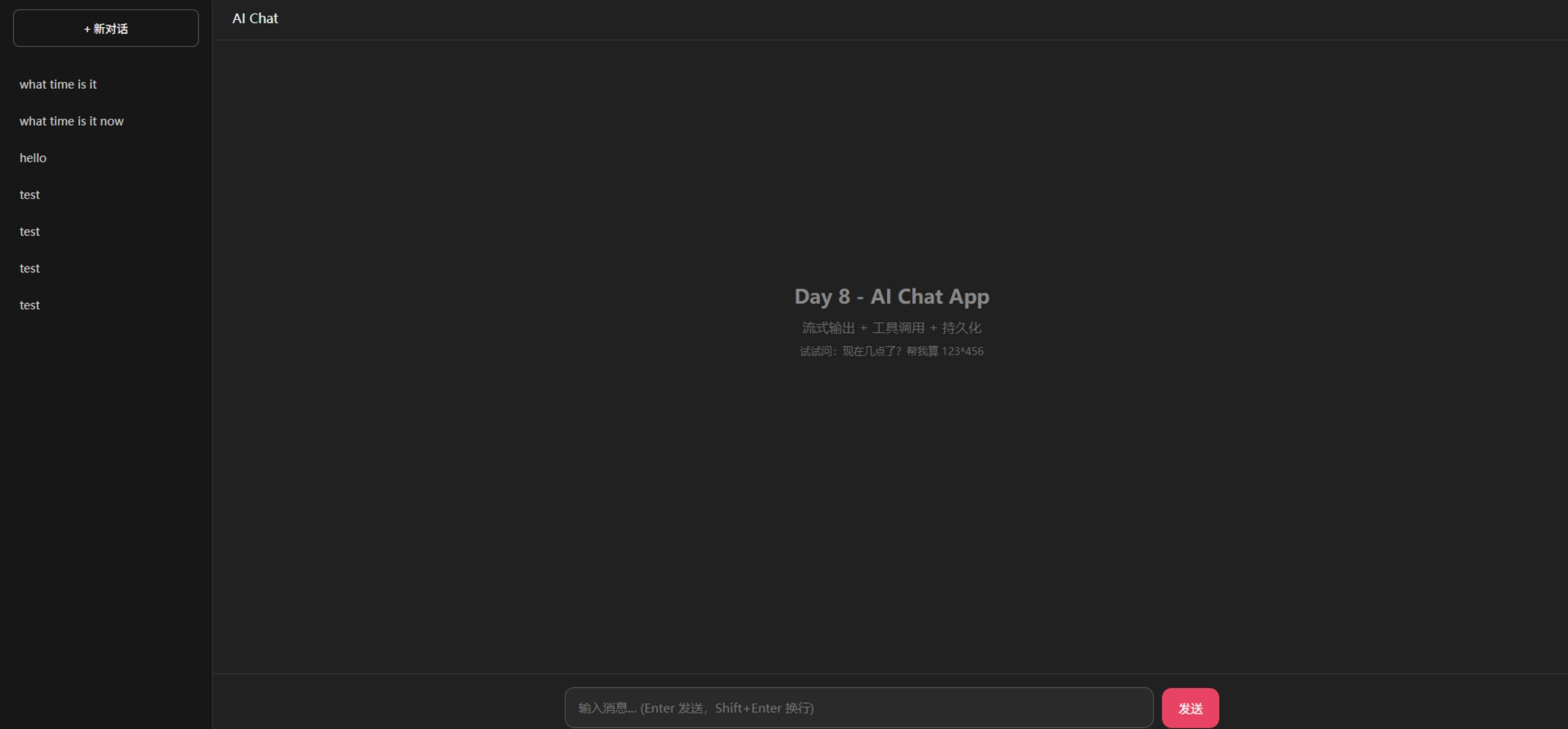
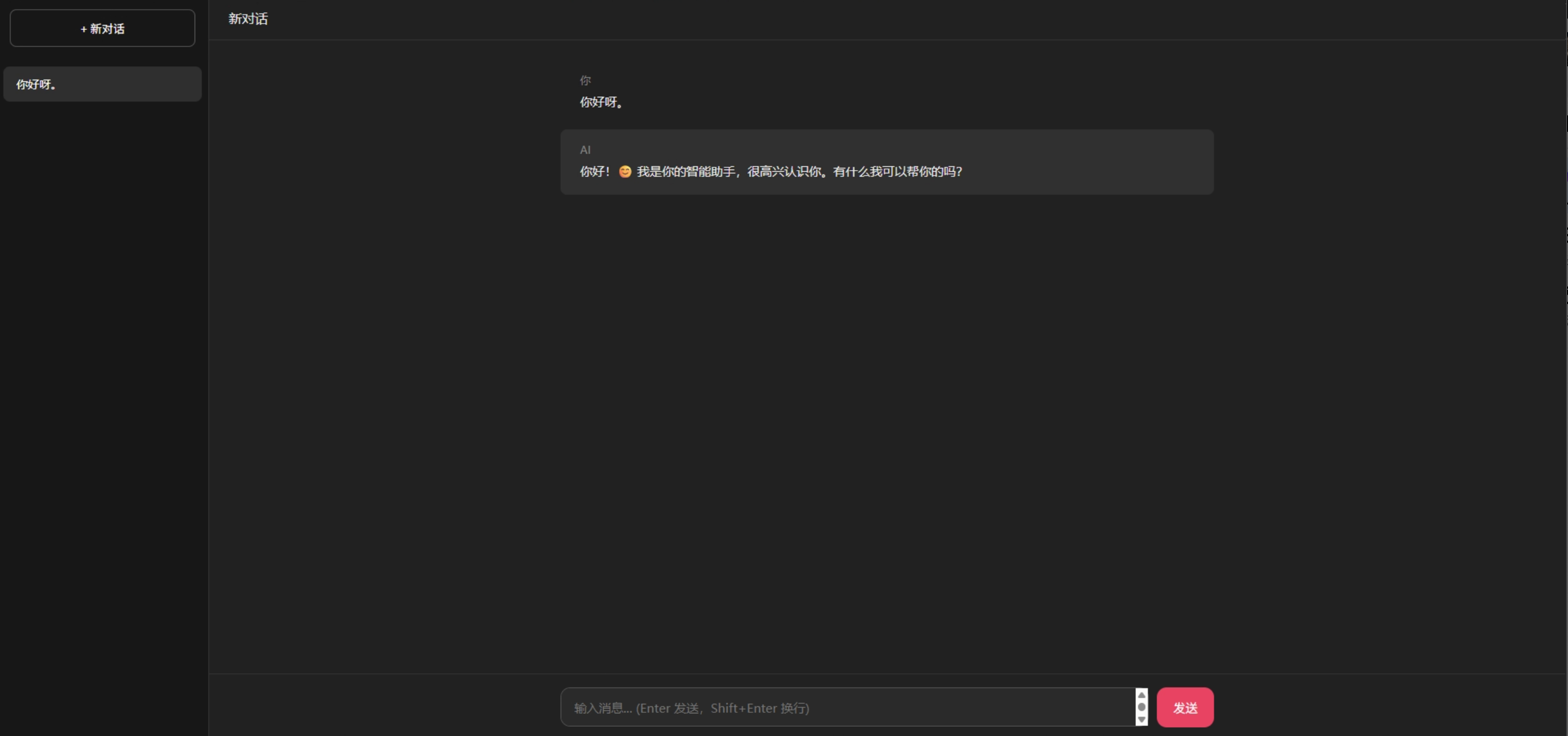
是的,一个 Java 后端用 Python 手撸了一个 AI 聊天应用。虽然 UI 简陋了点,但核心架构和 ChatGPT、豆包是一样的。
一、今日学习路线
从 yield 到完整 Web 应用,7 步走完。
二、为什么需要流式输出?
2.1 普通模式 vs 流式模式
普通模式(Day 7):
用户发消息 → 等3秒 → 一大坨文字砸脸上
用户内心:"这破程序卡住了?"
流式模式(Day 8):
用户发消息 → "你" → "你好" → "你好," → 边打边看
用户内心:"它在思考了,在回答了!"
LLM 天生就是逐字生成的。 它并不是先想好完整答案再吐出来,而是每一步只预测下一个 token。所以流式输出 = 拿到一个 token 就立刻返回一个。
2.2 Python 生成器(yield)
流式输出的核心是 Python 的 yield 关键字。作为 Java 后端,你可以把它理解为 Iterator 的语法糖:
def generate_numbers():
for i in range(1, 6):
print(f" 正在生成第 {i} 个...")
yield i # 返回值 + 暂停,下次继续
# 调用后不执行,返回生成器对象
gen = generate_numbers()
next(gen) # → 1
next(gen) # → 2
# for 循环自动调用 next
for num in generate_numbers():
print(num)
| Java | Python |
|---|---|
Iterator<T> |
Generator |
hasNext() |
自动 StopIteration |
next() |
next() 或 for |
| 要写一个类实现接口 | 一个 yield 搞定 |
Python 的 yield 比 Java 简洁太多了。Java 要写一个类实现 Iterator 接口,Python 只要一个 yield 关键字。
三、SSE 协议 = 服务器推送
3.1 什么是 SSE?
SSE(Server-Sent Events)就是服务器持续往客户端推数据,连接不断开。
HTTP 普通请求:一问一答,答完断开
浏览器 → 请求 → 服务器 → 完整响应 → 断开
SSE:服务器持续推送
浏览器 → 请求 → 服务器 → chunk1 → 浏览器显示
→ chunk2 → 浏览器显示
→ chunk3 → 浏览器显示
→ [DONE] → 结束
Java 对照:SSE = Spring 的 SseEmitter。原理一模一样,只是 Python 写法不同。
3.2 FastAPI 实现 SSE
from fastapi.responses import StreamingResponse
@app.post("/chat/stream")
def chat_stream(request: ChatRequest):
def event_generator():
for token in llm_stream(request.message):
yield f'data: {{"content": "{token}"}}\n\n'
yield "data: [DONE]\n\n"
return StreamingResponse(
event_generator(),
media_type="text/event-stream" # SSE 的 MIME 类型
)
一行 StreamingResponse 就把生成器变成 HTTP 流。 Java 写 SseEmitter 要多少行?
3.3 SSE 数据格式
data: {"content": "你"}\n\n
data: {"content": "好"}\n\n
data: [DONE]\n\n
每个 data: 后面跟一个 JSON,\n\n 是事件分隔符。[DONE] 表示流结束。
四、真实 MiMo API 流式调用
前面用的都是假数据(mock),现在接入真实的大模型 API:
def mimo_stream(messages: list, tools: list = None):
body = {
"model": "mimo-v2-flash",
"messages": messages,
"stream": True, # 关键!开启流式
}
if tools:
body["tools"] = tools
# stream=True 告诉 requests 不要一次读完
response = requests.post(url, json=body, stream=True)
for line in response.iter_lines():
line = line.decode("utf-8")
if line.startswith("data: "):
data = line[6:]
if data == "[DONE]":
break
chunk = json.loads(data)
content = chunk["choices"][0]["delta"].get("content", "")
if content:
yield content
和 Day 1 的区别:
- Day 1:
response = requests.post(...)→ 等完整响应 - Day 8:
stream=True+iter_lines()→ 边收边显示
五、流式 + 工具调用(核心难点!)
这是今天最难的部分。普通流式只需要拼接文本,但加上工具调用就复杂了:
普通流式:
chunk1="你" chunk2="好" → 直接拼显示
带工具调用的流式:
chunk1="让我查一下时间"
chunk2={tool_call: get_current_time} ← 需要停下来!
→ 执行工具,拿到结果
→ 把结果发回 API,继续流式
chunk3="现在是 16:07"
5.1 MiMo API 的工具调用格式
经过调试发现,MiMo API 的 tool_call 是完整一个 chunk 发过来的:
// 第1个 chunk:AI 开始说话
{"choices": [{"delta": {"content": "我来帮你查看"}, "finish_reason": null}]}
// 第2个 chunk:工具调用(完整的一个 chunk,不是分多个!)
{"choices": [{"delta": {"tool_calls": [{"index": 0, "id": "call_xxx", "function": {"name": "get_current_time", "arguments": "{}"}}]}, "finish_reason": null}]}
// 第3个 chunk:结束标记
{"choices": [{"delta": {}, "finish_reason": "tool_calls"}]}
5.2 核心代码
def stream_with_tools(messages, tools, max_rounds=3):
for round_num in range(max_rounds):
# 调用 API
response = requests.post(url, json=body, stream=True)
text_content = ""
tool_calls_map = {}
has_tool_calls = False
for line in response.iter_lines():
# 解析 chunk...
if content:
yield {"type": "text", "content": content}
if tool_calls:
has_tool_calls = True
# 收集工具调用信息
# 如果有工具调用
if has_tool_calls and finish_reason == "tool_calls":
# 执行工具
for tc in tool_calls_map.values():
result = execute_tool(tc["name"], tc["arguments"])
yield {"type": "tool_call", "name": tc["name"]}
yield {"type": "tool_result", "result": result}
# 工具结果加入消息历史
continue # 继续下一轮
else:
return # 正常结束
关键逻辑:检测到 tool_call → 执行工具 → 结果发回 API → 继续流式。最多循环 3 轮。
实测效果:
文字 → "我来帮你查看当前时间。"
工具 → get_current_time() → "2026年06月07日 16:07:10"
文字 → "现在是 **2026年6月7日,星期六,16:07:10**。"
六、SQLite 持久化 + 会话管理
6.1 数据库设计
作为 Java 后端,看到这个设计秒懂:
-- 会话表
CREATE TABLE sessions (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL DEFAULT '新对话',
created_at TEXT NOT NULL,
updated_at TEXT NOT NULL
);
-- 消息表
CREATE TABLE messages (
id INTEGER PRIMARY KEY AUTOINCREMENT,
session_id INTEGER NOT NULL,
role TEXT NOT NULL, -- user / assistant / tool
content TEXT,
tool_calls TEXT, -- JSON 格式的工具调用
tool_call_id TEXT,
created_at TEXT NOT NULL,
FOREIGN KEY (session_id) REFERENCES sessions(id)
);
Java 对照:
@Entity class Session → sessions 表
@Repository → ChatDatabase 类
@Service ChatService → PersistentChat 类
@RestController → FastAPI @app.post
SseEmitter → StreamingResponse
JdbcTemplate → sqlite3.connect()
6.2 踩坑:SQLite 连接冲突
写 save_message 的时候踩了个坑:
def save_message(self, ...):
with sqlite3.connect(self.db_path) as conn:
conn.execute("INSERT INTO messages ...")
self.touch_session(session_id) # ← 这里又开了一个连接!
conn.commit()
save_message 开了一个连接,touch_session 又开一个,两个连接同时写同一个数据库 → 死锁!
修复:内联更新,一个连接搞定。
def save_message(self, ...):
with sqlite3.connect(self.db_path) as conn:
conn.execute("INSERT INTO messages ...")
conn.execute("UPDATE sessions SET updated_at = ? ...") # 内联
conn.commit()
教训:Java 里用连接池自动管理,Python 的 sqlite3 要手动注意连接生命周期。
七、完整 Web 应用
最后一步,把所有东西组装成一个 Web 应用:
@app.post("/api/sessions/{session_id}/chat")
def chat(session_id: int, req: ChatRequest):
def event_generator():
for event in chat_service.chat(session_id, req.message):
yield f"data: {json.dumps(event)}\n\n"
yield "data: [DONE]\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
前端用原生 HTML/JS,核心是 fetch + ReadableStream 读取 SSE:
const response = await fetch('/api/sessions/1/chat', {
method: 'POST',
body: JSON.stringify({message: msg})
});
const reader = response.body.getReader();
while (true) {
const {done, value} = await reader.read();
if (done) break;
// 解析 SSE 事件,实时更新页面
}
功能清单:
- ✅ ChatGPT 风格的聊天界面
- ✅ 流式打字效果
- ✅ 多会话管理(新建、切换、删除)
- ✅ 对话持久化(SQLite,关了再开还在)
- ✅ 工具调用(时间查询、计算器)
八、文件依赖关系
shared_config.py ← 全局 API 配置(API Key、模型)
↓
05_streaming_tool_agent.py ← 流式 + 工具调用核心
↓
06_persistent_chat.py ← 持久化 + 会话管理
↓
07_chat_web_app.py ← Web 应用(复用上面两个)
九、Day 8 总结
9.1 今日收获
Day 8 = 流式输出 + 工具调用 + 持久化 + Web 应用
yield 生成器:Python 版 Iterator,但简洁 10 倍
SSE 协议: 服务器推送 = Java 的 SseEmitter
流式 API: requests(stream=True) + iter_lines()
工具调用: 流式中检测 tool_call → 执行 → 继续
SQLite: Python 版 JDBC,手动注意连接冲突
Web 应用: FastAPI + 原生 HTML = 迷你豆包
9.2 最大的感受
今天是从"会用"到"能做东西"的转折点。
前7天学的都是零散的知识点:API调用、Agent概念、RAG、LangChain…
今天第一次把它们组装成了一个完整的、能跑的、有界面的应用。
虽然 UI 简陋,虽然功能简单,但核心架构和 ChatGPT、豆包是一样的:
- 流式输出 ✅
- 工具调用 ✅
- 多轮对话 ✅
- 持久化 ✅
- Web 界面 ✅
一个 Java 后端用 Python 手撸了一个 AI 聊天应用,这感觉还挺爽的。
📊 系列进度:Day 8 / 90
📅 学习节奏: 周日大肝,从 yield 到完整 Web 应用
🎯 下一阶段: 接入更多工具、优化 UI、部署上线

AtomGit AI 社区提供模型库、数据集、Agent、Token等资源
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)