
Java 程序员第 33 阶段:整合 Sentinel 熔断降级:大模型接口高可用防护
在当今人工智能技术飞速发展的时代,大语言模型(LLM)已成为企业智能化转型的核心基础设施。从ChatGPT到Claude,从国内的文心一言、通义千问到DashScope,大模型API正在被广泛应用于智能客服、内容生成、知识库问答、代码辅助等各类业务场景。然而,在生产环境中调用这些大模型API时,开发者们面临着前所未有的高可用挑战。大模型接口的响应延迟具有高度不确定性,从几百毫秒到数十秒不等;Tok
Java 程序员第 33 阶段:整合 Sentinel 熔断降级:大模型接口高可用防护
概述
在当今人工智能技术飞速发展的时代,大语言模型(LLM)已成为企业智能化转型的核心基础设施。从ChatGPT到Claude,从国内的文心一言、通义千问到DashScope,大模型API正在被广泛应用于智能客服、内容生成、知识库问答、代码辅助等各类业务场景。然而,在生产环境中调用这些大模型API时,开发者们面临着前所未有的高可用挑战。
大模型接口的响应延迟具有高度不确定性,从几百毫秒到数十秒不等;Token消耗速率随输入复杂度波动剧烈,难以精确预算;各大厂商的API限流策略日趋严格,超出配额将面临请求被拒绝或额外计费。更棘手的是,第三方大模型服务并非完全可靠,网络抖动、服务端负载波动、模型冷启动等因素都可能导致请求失败。
正是这些挑战促使我们必须为大模型接口构建完善的防护机制。Sentinel作为阿里巴巴开源的流量控制与熔断降级组件,凭借其丰富的功能特性、优秀的性能表现以及与Spring生态的深度集成,成为保护大模型接口的理想选择。本文将深入探讨如何运用Sentinel构建大模型接口的高可用防护体系,涵盖熔断降级原理、限流算法、Spring Boot集成、规则持久化、监控告警等全方位技术细节。

第一章:大模型接口的高可用挑战
1.1 响应延迟的不确定性
大模型API的响应延迟与传统REST API有着本质区别。传统API如获取用户信息、提交订单等操作,响应时间通常在几十毫秒到几百毫秒之间,且波动范围相对可控。但大模型API的响应时间受到多重因素影响,呈现出高度不确定性。
计算资源依赖是大模型响应延迟的首要因素。大模型的推理过程需要消耗大量的GPU计算资源。当GPU资源紧张时,推理请求需要排队等待;模型需要重新加载时(冷启动),可能需要数秒甚至更长时间;批处理请求的大小也直接影响着响应速度。这些因素使得大模型API的响应延迟可能在200毫秒到60秒之间剧烈波动。
输入复杂度的影响同样不可忽视。简单的对话请求可能只需要几百毫秒即可完成,而涉及长文档分析、代码生成、复杂推理等任务时,模型需要处理更多的Token,消耗更多的计算资源,响应时间自然会大幅延长。这种不可预测性使得传统的固定超时策略难以应对。
网络传输因素虽然相对可控,但在跨地区调用大模型API时仍会造成显著延迟。从北京到美西服务器的单向网络延迟通常在150-250毫秒之间,而大模型生成的响应内容往往较大,可能达到数十KB甚至数百KB,下载这些内容也需要额外时间。
这种延迟不确定性给系统设计带来了严峻挑战。如果设置过短的超时时间,大量正常请求可能被误判为失败,引发不必要的重试和熔断;如果设置过长,当后端服务真正出现问题时,系统将长时间处于等待状态,用户体验严重下降。
1.2 Token消耗的难以预估
Token是大模型API计费的核心单位,准确预估和控制Token消耗对于成本管理至关重要。然而,Token消耗的动态性使得精确控制变得极为困难。
用户输入的不可控性是Token消耗难以预估的首要原因。用户在提问时可能输入简短的几个词,也可能粘贴整篇长文档。对于企业知识库问答场景,用户可能一次性提交数百页的技术文档;在代码辅助场景中,用户可能粘贴数千行的代码片段要求审查或修改。这种输入规模的巨大差异直接导致Token消耗的剧烈波动。
模型输出的非确定性进一步增加了Token管理的复杂度。大模型基于概率生成文本,相同的输入可能产生不同长度、不同详略程度的输出。有些回答可能只有几句话,而有些可能是一篇完整的分析报告或一段详尽的代码实现。即使设置了max_tokens参数限制输出的最大长度,实际输出仍可能在这个范围内波动。
上下文累积效应在多轮对话场景中尤为明显。为了保持对话的连贯性,开发者通常会将历史对话内容一并发送给模型。随着对话轮次的增加,上下文信息不断累积,Token消耗呈现线性甚至指数级增长。如果不加控制,可能在几轮对话后就达到模型的上下文长度上限(如GPT-4的128K Token),导致无法继续对话或需要截断历史信息。
Token消耗的不可预估性可能导致以下问题:月度账单远超预算、API调用因超限被拒绝、系统在高负载时性能急剧下降。因此,我们需要通过Sentinel的热点参数限流等功能来控制Token消耗的速率和总量。
1.3 API限流的严格约束
主流大模型厂商都实施了严格的API限流策略,这是出于保护服务稳定性和公平使用考虑。但对于依赖大模型能力构建业务的开发者而言,限流策略带来了显著的限制。
OpenAI的限流机制采用多维度策略。按请求速率(Requests per Minute, RPM)限制,不同订阅级别的账户有不同的RPM上限:Free用户每分钟仅3次调用,Pay-as-you-go用户根据套餐不同从60 RPM到3000 RPM不等;按Token速率(Tokens per Minute, TPM)限制,防止单个请求消耗过多计算资源;按并发数(DALL-E和ChatGPT模型有不同的并发限制)。超出限流时,API返回429状态码,要求客户端进行指数退避重试。
Anthropic的限流策略同样多维度。不同API端点有不同的速率限制,Claude 3系列模型的上下文窗口和生成Token数都有限制,高并发场景下会触发严格的限流机制。与OpenAI类似,超限后需要等待或升级套餐。
国内大模型厂商的限流各具特色。百度文心一言按照QPS(Queries Per Second)和日调用量进行限制;阿里通义千问根据模型类型和账户级别设置不同的调用配额;科大讯飞星火大模型也实施了多层次的限流策略。理解并遵守这些限流规则,对于构建稳定的大模型应用至关重要。
超出限流的后果包括:请求被直接拒绝返回429错误、账户被临时封禁、额外计费甚至法律风险。更糟糕的是,限流往往是突发性的——当系统因某个热点事件突然涌入大量请求时,限流可能被触发,导致原本正常的业务逻辑受损。
Sentinel的限流功能可以帮助我们在客户端层面实施主动流量控制,避免触发服务端限流;同时通过熔断降级机制,在检测到限流或异常时快速切换到降级策略,保证系统的整体可用性。
1.4 服务可用性的隐忧
除了上述可控因素外,大模型服务本身的可用性也是需要考虑的问题。第三方大模型服务虽然承诺了很高的SLA(服务等级协议),但在实际情况中仍可能出现各种问题。
服务端负载波动可能导致响应质量下降。当大量用户同时使用某热门模型时,服务端可能优先保证服务可用性而降低响应质量,具体表现为输出内容缩短、推理深度降低等。虽然这不算严格意义上的失败,但可能影响业务效果。
模型版本迭代可能带来兼容性问题。模型厂商会不断优化和升级模型,新版本可能在输出格式、行为特征上有所变化,需要客户端进行适配。在版本切换期间,可能出现短暂的兼容性问题。
区域性服务中断虽然罕见但后果严重。当某个区域的数据中心出现问题时,该区域的API服务可能完全不可用。如果业务部署没有考虑多区域容灾,可能导致服务中断。
基于以上分析,我们可以得出结论:大模型接口的高可用防护需要从流量控制、熔断降级、异常处理等多个维度进行综合设计。Sentinel提供了完整的解决方案,下面让我们深入了解其核心概念和工作原理。
第二章:Sentinel核心概念解析
2.1 资源:流量控制的最小单位
在Sentinel的世界里,资源(Resource)是流量控制的最小单位和核心概念。资源可以是任何需要保护的对象——一个URL、一段代码、一个方法调用,甚至是一段复杂的业务逻辑。只要通过Sentinel API将资源包装起来,Sentinel就能对其进行流量控制、熔断降级和系统自适应调节。
资源的定义方式非常灵活。在Spring Boot应用中,最常用的方式是通过@SentinelResource注解来定义资源:
@RestController
public class LLMController {
@GetMapping("/chat")
@SentinelResource(value = "chatApi",
blockHandler = "chatBlockHandler",
fallback = "chatFallback")
public String chat(@RequestParam String prompt) {
// 调用大模型API的业务逻辑
return llmService.chat(prompt);
}
// 限流处理逻辑
public String chatBlockHandler(BlockException e) {
return "请求过于频繁,请稍后再试";
}
// 降级处理逻辑
public String chatFallback(String prompt, Throwable t) {
return "服务暂时不可用,返回默认回复";
}
}
上述代码中,@SentinelResource注解的value属性指定了资源的名称(这里是"chatApi"),这个名称在Sentinel中是唯一的,用于标识和关联各种规则。当请求触发限流时,blockHandler指定的处理方法会被调用;当发生熔断降级或业务异常时,fallback指定的降级方法会被执行。
资源的粒度选择是一个重要的设计决策。较粗粒度的资源(如整个/chat接口)便于统一管理,但无法区分不同的调用来源;较细粒度的资源(如按用户ID或模型类型区分)可以实施更精细的控制策略,但管理复杂度也会上升。在大模型应用场景中,建议按以下维度设计资源粒度:
// 粗粒度:按接口级别
@SentinelResource(value = "llm:chat")
// 中粒度:按模型级别
@SentinelResource(value = "llm:chat:gpt-4")
@SentinelResource(value = "llm:chat:claude-3")
// 细粒度:按用户级别
@SentinelResource(value = "llm:chat:user:{userId}")
对于需要动态生成资源名称的场景,可以使用Sentinel的API直接定义:
try {
// entry方法尝试获取资源访问权限,如果被限流会抛出BlockException
Entry entry = SphU.entry("llm:chat:user:" + userId);
// 业务逻辑
String response = llmService.chat(prompt);
entry.exit();
} catch (BlockException e) {
// 限流处理
return "请求过于频繁";
}
2.2 规则:流量控制的核心配置
Sentinel中的规则定义了何时以及如何对资源进行流量控制。规则是独立于资源的可配置元素,支持运行时动态修改而无需重启应用。Sentinel支持多种类型的规则,分别用于不同的防护场景。
流量控制规则(FlowRule)是最常用的规则类型,用于限制资源的请求速率。FlowRule的核心属性包括:
FlowRule rule = new FlowRule("chatApi") // 资源名
.setGrade(RuleConstant.FLOW_GRADE_QPS) //限流依据:QPS或并发线程数
.setCount(100) // 阈值
.setControlBehavior(RuleConstant.CONTROL_BEHAVIOR_DEFAULT) // 控制行为
.setStrategy(RuleConstant.STRATEGY_DIRECT) // 流控策略
.setResourceType(RuleConstant.RESOURCE_TYPE_API); // 资源类型
Grade属性指定限流的维度,可以是QPS(每秒请求数)或并发线程数。当设置为QPS模式时,Sentinel使用滑动窗口算法统计每秒的请求数量;当设置为并发线程数模式时,Sentinel统计正在执行中的线程数量。
Count属性设置具体的阈值数值。结合Grade使用,表示"每秒钟最多允许100个请求"或"同时最多允许10个并发线程"。
ControlBehavior属性定义触达阈值时的处理行为:
- 直接拒绝(Default):请求直接被拒绝,返回BlockException
- 冷启动(Warm Up):系统预热阶段逐步提升阈值,避免冷启动时的突发流量压垮系统
- 匀速排队(Queue):请求匀速排队,多余的请求等待而不是直接拒绝
Strategy属性定义流控策略:
- 直接(Direct):资源本身的请求触发流控
- 关联(Associate):当前资源关联另一个资源,当关联资源触达阈值时,当前资源被限流
- 链路(Chain):根据调用链路入口进行限流
降级规则(DegradeRule)用于实现熔断降级功能。降级规则的核心属性包括:
DegradeRule rule = new DegradeRule("chatApi")
.setGrade(RuleConstant.DEGRADE_GRADE_RT) // 降级依据:RT、异常比例、异常数
.setCount(500) // 阈值
.setTimeWindow(10) // 熔断时长(秒)
.setMinRequestAmount(5) // 最小请求数
.setStatIntervalMs(1000) // 统计时长(毫秒)
.setSlowRatioThreshold(0.5); // 慢调用比例阈值
Grade属性定义触发降级的条件类型:
- 平均响应时间(RT):当资源的平均响应时间超过阈值时触发降级
- 异常比例(Ratio):当资源的异常请求比例超过阈值时触发降级
- 异常数量(Count):当资源的异常请求数量超过阈值时触发降级
TimeWindow属性定义熔断持续时长。当降级被触发后,在该时间窗口内,所有对该资源的请求都会被直接拒绝或执行降级逻辑。窗口结束后,进入半开状态,允许少量请求通过以探测服务是否恢复。
MinRequestAmount属性是一个重要的保护属性,防止系统处于波动状态时频繁触发降级。只有当请求数量达到该阈值后,才会开始统计异常比例或响应时间。这避免了对少量冷启动请求的误判。
2.3 插槽链:Sentinel的心脏
Sentinel的核心架构采用了插槽链(Slot Chain)模式,这是一条有序的处理器链,每个插槽(Slot)负责特定的功能职责。当一个请求进入Sentinel时,会依次经过这条链上的各个插槽,每个插槽有机会对请求进行处理、统计或拦截。
Sentinel默认的插槽链包含以下核心插槽:
NodeSelectorSlot是链路的第一个插槽,负责构建资源调用树中的节点。它根据资源名称选择或创建一个DefaultNode,每个资源对应一个DefaultNode。这个节点是后续统计信息的基础,所有的流量控制、降级判断都基于这个节点进行。
ClusterBuilderSlot负责构建集群节点信息。它会为每个资源创建一个ClusterNode,用于集群级别的统计和流控。当启用Sentinel的集群流控功能时,这些ClusterNode会发挥重要作用。同时,该插槽还会处理调用关系,识别当前资源是被哪个上游资源调用的。
FlowSlot是流量控制的核心插槽。它根据配置的FlowRule判断当前请求是否应该被限流。FlowSlot内部维护着一个FlowRuleChecker,负责比对请求特征与规则配置,做出允许或拒绝的判断。
DegradeSlot负责熔断降级的判断。它根据DegradeRule监控资源的实时指标,当满足降级条件时,将资源标记为降级状态。在降级状态下,该插槽会直接抛出DegradeException,绕过后续的业务逻辑。
SystemSlot实现系统自适应限流功能。它根据系统的负载状态(CPU使用率、RT、入口QPS等)自动调整保护策略,在系统即将过载时主动拒绝请求,保护系统不被压垮。
AuthoritySlot实现黑白名单访问控制功能。它根据配置的AuthorityRule判断请求是否来自授权的调用方,可以用于防止恶意爬虫或未授权访问。
插槽链的设计使得Sentinel具有极高的扩展性。开发者可以通过SlotChainBuilder接口自定义插槽链,添加自己需要的处理逻辑。例如,可以添加一个用于记录请求日志的CustomSlot,或添加一个用于加密敏感数据的SecuritySlot。
// 自定义插槽链示例
public class CustomSlotChainBuilder implements SlotChainBuilder {
@Override
public ProcessorSlotChain build() {
ProcessorSlotChain chain = new DefaultProcessorSlotChain();
chain.addLast(new NodeSelectorSlot());
chain.addLast(new ClusterBuilderSlot());
chain.addLast(new CustomLogSlot()); // 自定义日志插槽
chain.addLast(new FlowSlot());
chain.addLast(new DegradeSlot());
chain.addLast(new SystemSlot());
return chain;
}
}
2.4 链路降级:细粒度流量控制
链路降级(Chain Degradation)是Sentinel提供的一种细粒度流量控制能力,它允许开发者根据调用链路的来源实施不同的限流策略。这对于复杂的大模型应用场景尤为重要,因为同一个业务接口可能被不同的调用方以不同的频次和模式使用。
考虑这样一个场景:系统中有一个/chat接口,它底层调用了大模型API。这个接口可能被以下几种来源调用:
- 用户直接访问的前端页面
- 后台的定时任务(批量处理历史消息)
- 其他微服务(如智能客服系统)
不同的调用来源对接口的使用模式和重要性各不相同。前台用户的请求应该优先保障,响应时间要尽可能短;后台定时任务的请求可以适当限流或延迟处理;跨服务的调用可能有更高的突发流量。
通过Sentinel的链路降级功能,我们可以为不同的调用来源配置不同的限流规则:
@Configuration
public class SentinelConfig {
@PostConstruct
public void init() {
// 定义入口资源
ContextUtil.enter("user入口", "userOrigin");
ContextUtil.enter("task入口", "taskOrigin");
// 为用户入口配置较高的限流阈值
FlowRule userFlowRule = new FlowRule("chatApi")
.setGrade(RuleConstant.FLOW_GRADE_QPS)
.setCount(100) // 每秒100次
.setStrategy(RuleConstant.STRATEGY_CHAIN)
.setRefResource("user入口")
.as(FlowRule.class);
FlowRuleManager.loadRules(Collections.singletonList(userFlowRule));
// 为任务入口配置较低的限流阈值
FlowRule taskFlowRule = new FlowRule("chatApi")
.setGrade(RuleConstant.FLOW_GRADE_QPS)
.setCount(10) // 每秒10次
.setStrategy(RuleConstant.STRATEGY_CHAIN)
.setRefResource("task入口")
.as(FlowRule.class);
FlowRuleManager.loadRules(Arrays.asList(userFlowRule, taskFlowRule));
}
}
在上述配置中,我们定义了两种不同的入口上下文——user入口和task入口。对于来自user入口的调用,配置了每秒100次的限流阈值;对于来自task入口的调用,只配置了每秒10次的限流阈值。这样,当后台任务突发大量请求时,只会触发task入口的限流,不会影响前台用户的正常使用。
链路降级还可以用于实现更精细的降级策略。例如,当系统资源紧张时,可以优先保证核心业务流程的正常执行,而将非核心功能(如推荐建议、历史记录等)进行降级处理。
第三章:熔断器模式深度解析
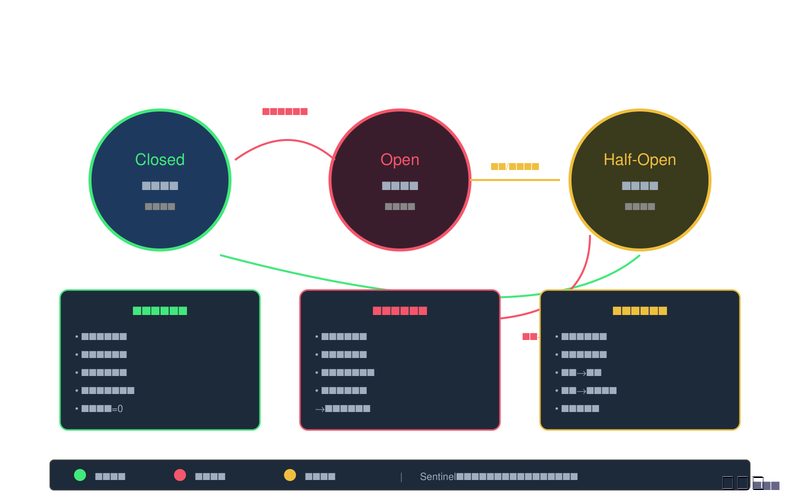
图2:熔断器工作状态图
3.1 熔断器模式概述
熔断器模式(Circuit Breaker Pattern)最初由Martin Fowler在其博客文章中提出,是一种旨在提高系统容错能力的软件设计模式。其核心思想类似于电路中的保险丝——当电流异常增大时,保险丝会熔断以保护电路不被损坏;在软件系统中,当检测到某个服务调用持续失败或响应超时,熔断器会"熔断",后续对该服务的调用将直接返回错误或降级响应,而不会继续尝试调用已经故障的服务。
熔断器模式解决了传统重试机制无法解决的一个核心问题:失败快速反馈。在传统重试机制中,当下游服务出现故障时,客户端会不断地发起重试请求。这些重试请求不仅无法获得有效响应,还会消耗宝贵的网络带宽和计算资源,更糟糕的是,它们可能会进一步加重下游服务的负载,形成恶性循环。熔断器模式通过在检测到故障后快速切断调用,让下游服务有喘息恢复的机会,同时也保护了本系统不被拖垮。
熔断器模式的工作原理可以通过以下类比来理解:假设你要给一个经常不接电话的朋友打电话。传统重试机制就像是不断地拨打,即使朋友一直不接,你也一直打下去,结果既浪费了你的时间,也打扰了别人的生活。而熔断器模式更像是智能电话策略——当你连续拨打几次都无人接听时,你会认为朋友可能不方便接电话或手机没电了,于是在接下来的一段时间内不再拨打。过了一段时间后,你可能会再试一次,如果这次接通了,你就恢复正常拨打;如果仍然无人接听,你就继续等待。通过这种方式,你既能确保在朋友方便时联系上他,又不会过度打扰。
3.2 熔断器的三种状态
Sentinel实现了一套完整的状态机模型来管理熔断器的生命周期。熔断器有三个稳定状态:关闭(Closed)、打开(Open)和半开(Half-Open),以及状态之间的转换机制。

关闭状态(Closed)是熔断器的默认状态。在此状态下,所有请求都能正常通过,熔断器像一位尽职的门卫,记录着每一次请求的成功与失败。当请求失败时,失败计数器会累加;当请求成功时,计数器会归零或按一定策略衰减。只要失败次数未超过设定的阈值,熔断器就保持关闭状态,允许所有请求继续访问目标服务。
当失败次数达到预设的阈值时,熔断器会从关闭状态转换为打开状态。转换的瞬间像是保险丝熔断,熔断器立即生效。在打开状态下,所有对该资源的请求都会被直接拒绝,客户端会收到降级响应而不是实际调用远程服务。这个状态的存在给了下游服务恢复的时间,避免在持续故障时还不断接受新请求。
经过一段预设的熔断时长后,熔断器会从打开状态转换到半开状态。半开状态是一种"试探"状态,熔断器会允许少量请求通过,看看下游服务是否已经恢复正常。这些试探性请求像是探路先锋,如果它们全部成功,熔断器就认为服务已经恢复,切换回关闭状态;如果它们失败,熔断器会重新切换回打开状态,并重新开始计时。
这种状态转换机制的关键在于:半开状态的超时设置不能太短,否则服务可能还没完全恢复就又开始接收大量请求;但也不能太长,否则会影响系统的正常响应速度。Sentinel允许开发者根据实际业务场景灵活配置这些时间窗口。
3.3 Sentinel熔断器的工作原理
Sentinel的熔断器通过DegradeSlot实现,其核心逻辑围绕两个关键组件展开:滑动窗口统计(Statictis)和熔断器状态机(CircuitBreaker)。
滑动窗口统计是Sentinel实现精确熔断判断的基础。Sentinel将时间划分为固定长度的窗口(默认是1秒),并维护一个环形数组来保存最近N个窗口的统计数据。当需要判断是否触发熔断时,Sentinel只需要汇总最近窗口的统计数据即可。
// 滑动窗口核心数据结构
public class LeapArray<T> {
private final int windowLength; // 单个窗口长度(毫秒)
private final int sampleCount; // 窗口数量
private final int interval; // 总时间跨度(= windowLength * sampleCount)
private final AtomicReferenceArray<T> array; // 环形数组
// 每个窗口统计的信息
public static class WindowWrap<T> {
private final long windowStart; // 窗口开始时间
private final long interval; // 窗口长度
private T value; // 窗口统计数据
}
}
Sentinel使用MetricFetcher来采集每次请求的结果,更新到对应的滑动窗口中。当一个请求完成时,无论是成功还是失败,都会触发指标更新。成功时增加成功计数,失败时增加失败计数,同时累加响应时间用于计算平均RT。
熔断器状态机是Sentinel管理熔断状态转换的核心组件。Sentinel为每个资源维护一个CircuitBreaker实例,这个实例封装了资源的熔断器逻辑:
public interface CircuitBreaker {
// 当前熔断器状态
State currentState();
// 请求是否应该被放行
boolean tryPass();
// 记录请求结果(成功或失败)
void recordSuccess(Exception e);
void recordFailure(Exception e);
// 状态转换回调
void stateChangeTransition(State preState, State newState);
}
Sentinel内置了两种熔断器实现:响应时间熔断器(ResponseTimeCircuitBreaker)和异常熔断器(ExceptionCircuitBreaker)。
响应时间熔断器根据平均响应时间判断是否触发熔断:
// 响应时间熔断器关键逻辑
public class ResponseTimeCircuitBreaker implements CircuitBreaker {
// 配置参数
private final double maxAllowedRt; // 最大允许响应时间
private final double slowRatioThreshold; // 慢调用比例阈值
private final int minRequestAmount; // 最小请求数
@Override
public boolean tryPass() {
// 检查当前状态
if (currentState() == State.OPEN) {
// 检查熔断时长是否已过
if (isCircuitBroken()) {
// 转换为半开状态
return false;
}
return false; // 仍在熔断中
}
return true; // 关闭状态,放行
}
@Override
public void recordSuccess(Exception e) {
// 成功计数更新
successCount.add(1);
// 在半开状态下,成功则关闭熔断器
if (currentState() == State.HALF_OPEN) {
fromHalfOpenToClose();
}
}
@Override
public void recordFailure(Exception e) {
// 失败计数更新
totalCount.add(1);
// 计算慢调用比例
double slowRatio = calculateSlowRatio();
// 判断是否需要触发熔断
if (slowRatio >= slowRatioThreshold && totalCount.get() >= minRequestAmount) {
fromCloseToOpen();
}
}
}
异常熔断器则根据异常比例或异常数量判断是否触发熔断:
// 异常熔断器关键逻辑
public class ExceptionCircuitBreaker implements CircuitBreaker {
// 配置参数
private final int minRequestAmount; // 最小请求数
private final double threshold; // 异常比例阈值或异常数阈值
private final Grade grade; // 基于比例还是数量
@Override
public void recordFailure(Exception e) {
totalCount.add(1);
if (isError(e)) {
errorCount.add(1);
}
// 判断是否需要熔断
if (grade == Grade.RATIO) {
double errorRatio = (double) errorCount.get() / totalCount.get();
if (errorRatio >= threshold && totalCount.get() >= minRequestAmount) {
fromCloseToOpen();
}
} else if (grade == Grade.COUNT) {
if (errorCount.get() >= threshold) {
fromCloseToOpen();
}
}
}
}
3.4 熔断策略的详细配置
在实际应用中,需要根据业务特性和服务质量要求精心配置熔断策略。以下是几种典型场景的配置建议:
对于大模型API的熔断配置,需要考虑大模型响应的固有延迟特性。传统的微服务RPC调用,正常RT可能在几十毫秒,而大模型API的正常RT可能在数秒甚至数十秒。因此,需要将RT阈值设置得足够宽松,避免将正常的慢响应误判为故障。
# 大模型API熔断配置示例
sentinel:
degrade:
rules:
# ChatGPT接口熔断规则
- resource: llm:chat:gpt-4
grade: 1 # 按平均响应时间
count: 30000 # 30秒(单位毫秒)
timeWindow: 60 # 熔断时长60秒
minRequestAmount: 10 # 至少10个请求才统计
slowRatioThreshold: 0.8 # 80%慢调用比例
# Claude接口熔断规则
- resource: llm:chat:claude-3
grade: 1
count: 25000 # 25秒
timeWindow: 60
minRequestAmount: 10
slowRatioThreshold: 0.8
# 异常比例熔断(备用)
- resource: llm:chat:common
grade: 2 # 按异常比例
count: 0.5 # 50%异常比例
timeWindow: 30 # 熔断30秒
minRequestAmount: 5
对于批量任务接口的熔断配置,需要考虑批量任务本身的特点。批量任务通常对延迟不敏感,但请求量大、耗时长,一旦失败影响面广。因此,批量任务的熔断策略应该更激进,在检测到问题时更快触发熔断,同时熔断时长可以设置得更长,给予系统充分的恢复时间。
# 批量任务熔断配置示例
sentinel:
degrade:
rules:
- resource: llm:batch:process
grade: 1
count: 60000 # 60秒
timeWindow: 300 # 熔断5分钟
minRequestAmount: 3 # 少量失败即触发
slowRatioThreshold: 0.6 # 60%慢调用
对于核心业务流程的熔断配置,需要采用更保守的策略。核心业务流程直接面向用户,影响用户体验和业务转化,因此应该设置较高的熔断阈值,尽量避免误触发;同时可以配置多级降级策略,在不同严重程度下采取不同的处理方式。
# 核心业务熔断配置示例
sentinel:
degrade:
rules:
- resource: llm:core:answer
grade: 1
count: 10000 # 10秒,相对宽松
timeWindow: 30
minRequestAmount: 20 # 更高的请求量要求
slowRatioThreshold: 0.9 # 90%慢调用才熔断
第四章:限流算法对比分析
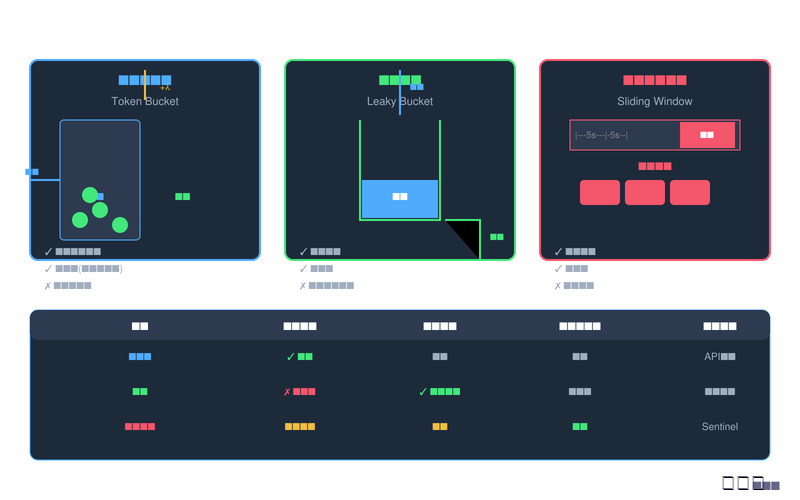
图3:限流算法对比图
4.1 令牌桶算法
令牌桶算法(Token Bucket)是目前应用最广泛的限流算法之一,其核心思想是:系统以固定速率向桶中添加令牌,桶的容量有上限;每个请求需要从桶中获取一个令牌才能被处理;如果桶为空,请求将被拒绝或等待。
令牌桶算法的工作原理可以通过以下步骤描述:
- 令牌生成:系统以恒定速率向桶中添加令牌。例如,每秒添加100个令牌,则添加间隔为10毫秒。
- 令牌存储:桶有最大容量,当桶已满时,新生成的令牌会被丢弃。因此,即使系统空闲了一段时间,桶中的令牌数也不会超过容量上限。
- 令牌消费:每个请求需要消耗一个令牌。当请求到达时,如果桶中至少有一个令牌,则取出令牌,请求被放行;如果桶为空,则请求被限流。
令牌桶算法的数学表达如下:设桶容量为B,令牌生成速率为λ(每秒生成λ个令牌)。当时间t=0时,桶中有M个令牌(M≤B)。在任意时刻t,桶中的令牌数N(t)满足:
N(t) = min(B, M + λ*t - consumed(t))
其中consumed(t)是时刻t之前已消费的令牌总数。
令牌桶算法的一个关键特性是允许一定程度的突发流量。考虑这样的场景:系统一直空闲,桶中已积累了大量令牌;当突然有大量请求到达时,这些请求可以一次性消耗桶中的令牌,获得突发处理能力。这种特性使得令牌桶算法非常适合用于保护大模型API——用户的请求模式往往是突发的,而大模型服务能够容忍一定程度的突发负载。
// 令牌桶算法模拟实现
public class TokenBucket {
private final double capacity; // 桶容量
private final double refillRate; // 令牌生成速率(每秒)
private double tokens; // 当前令牌数
private long lastRefillTime; // 上次补充时间
public TokenBucket(double capacity, double refillRate) {
this.capacity = capacity;
this.refillRate = refillRate;
this.tokens = capacity; // 初始为满桶
this.lastRefillTime = System.nanoTime();
}
public synchronized boolean tryConsume() {
refill();
if (tokens >= 1) {
tokens -= 1;
return true;
}
return false;
}
private void refill() {
long now = System.nanoTime();
double elapsed = (now - lastRefillTime) / 1_000_000_000.0; // 转换为秒
double newTokens = elapsed * refillRate;
tokens = Math.min(capacity, tokens + newTokens);
lastRefillTime = now;
}
}
4.2 漏桶算法
漏桶算法(Leaky Bucket)是另一种经典的限流算法,其核心思想与令牌桶相反:请求像水滴一样进入漏桶,桶底的孔以固定速率漏水;当桶满时,新进入的水滴会溢出(即请求被拒绝)。
与令牌桶的"有进有出"不同,漏桶算法的特点是输出速率恒定。无论有多少请求进入漏桶,从桶底流出的"水滴"(被处理的请求)速率始终是固定的。这种特性使得漏桶算法非常适合用于需要严格流量整形的场景,如金融交易系统、视频流媒体服务等。
漏桶算法的工作原理如下:
- 请求入桶:请求到达时直接进入桶中等待处理。如果桶已满,请求被拒绝。
- 恒定输出:桶以固定速率向下漏出请求。无论桶中积累了多少请求,漏出的速率始终是恒定的。
- 队列缓冲:桶起到了缓冲队列的作用,吸收突发的请求流量,平滑输出。
漏桶算法的一个潜在问题是无法充分利用系统的处理能力。当系统负载较轻时,固定的输出速率可能导致资源浪费。此外,漏桶算法对于突发流量的处理不够友好——即使桶中有大量积压的请求,它们也只能按照固定速率被处理,不会因为请求堆积而加快处理速度。
// 漏桶算法模拟实现
public class LeakyBucket {
private final double capacity; // 桶容量
private final double leakRate; // 漏水速率(每秒漏出请求数)
private double water; // 当前水量(等待处理请求数)
private long lastLeakTime; // 上次漏水时间
public LeakyBucket(double capacity, double leakRate) {
this.capacity = capacity;
this.leakRate = leakRate;
this.water = 0;
this.lastLeakTime = System.nanoTime();
}
public synchronized boolean tryConsume() {
leak();
if (water < capacity) {
water += 1;
return true;
}
return false; // 桶已满,拒绝
}
private void leak() {
long now = System.nanoTime();
double elapsed = (now - lastLeakTime) / 1_000_000_000.0;
double leaked = elapsed * leakRate;
water = Math.max(0, water - leaked);
lastLeakTime = now;
}
}
4.3 滑动窗口算法
滑动窗口算法(Sliding Window)是令牌桶和漏桶的一种改进方案,它结合了两种算法的优点,同时提供了更精确的限流控制。
滑动窗口算法的核心思想是:将时间轴划分为连续的固定长度窗口,每个窗口维护自己的请求计数器;判断是否限流时,统计当前请求所在窗口及其前面若干窗口的总请求数。
假设我们使用滑动窗口限流,窗口长度为1秒,窗口数量为3个(即滑动窗口总长度为3秒),限流阈值为100 QPS。当一个请求到达时:
- 定位当前时间所属的窗口(窗口1)
- 统计窗口1 + 窗口2 + 窗口3的请求总数
- 如果总数 ≥ 100,请求被限流;否则,请求被放行,同时窗口1的计数器+1
滑动窗口算法的一个关键优势是统计精确。与令牌桶的"估算"式限流不同,滑动窗口统计的是真实的时间窗口内的请求数量,不存在累计误差问题。
Sentinel采用的就是滑动窗口算法作为其限流统计的基础。Sentinel将1秒划分为多个更小的窗口(默认是2个,即每个窗口500毫秒),通过LeapArray数据结构高效地管理这些窗口的统计数据。
// 滑动窗口算法核心逻辑(Sentinel实现简化)
public class SlidingWindow {
private final LeapArray<MetricBucket> array; // 环形数组存储窗口
public SlidingWindow(int windowLength, int sampleCount) {
this.array = new LeapArray<>(windowLength, sampleCount);
}
public long getTotalCount() {
// 获取当前窗口和滑动窗口内的所有请求数
return array.values().stream()
.mapToLong(MetricBucket::getPassCount)
.sum();
}
public boolean isPass() {
return getTotalCount() < threshold;
}
}
4.4 并发线程数限流
除了基于请求速率(QPS)的限流外,Sentinel还支持基于并发线程数的限流。这种限流方式不关注请求的发送速率,而是关注同时正在处理的请求数量。
并发线程数限流的核心思想是:每个请求处理都会占用一个线程资源;当并发处理的线程数达到阈值时,新到来的请求会被限流,等待已有请求处理完成。
这种限流方式特别适合用于保护资源消耗型服务。大模型API调用是典型的资源消耗型操作——每个请求都会占用网络连接、内存缓冲区,并可能导致后端GPU计算资源的使用。当并发请求过多时,系统资源会被耗尽,导致请求响应变慢甚至失败。通过并发线程数限流,可以确保同时处理的请求数量不超过系统的处理能力。
// 并发线程数限流配置示例
@Configuration
public class SentinelConfig {
@PostConstruct
public void init() {
FlowRule rule = new FlowRule("llm:chat:gpt-4")
.setGrade(RuleConstant.FLOW_GRADE_THREAD) // 基于并发线程数
.setCount(20) // 最多20个并发线程
.as(FlowRule.class);
FlowRuleManager.loadRules(Collections.singletonList(rule));
}
}
在上述配置中,我们设置了llm:chat:gpt-4资源的并发线程数阈值为20。当有超过20个请求同时在处理时,新请求将被限流。需要注意的是,这里的"并发线程数"指的是正在执行中的请求数量,而不是等待队列中的请求数量。
4.5 算法对比与选型建议

通过下表,我们可以清晰地对比三种限流算法的特性:
|
特性 |
令牌桶 |
漏桶 |
滑动窗口 |
|
突发流量处理 |
✓ 允许 |
✗ 不允许 |
部分允许 |
|
流量平滑度 |
中等 |
完全平滑 |
较好 |
|
实现复杂度 |
中等 |
较简单 |
简单 |
|
统计精度 |
估算(有误差) |
精确 |
精确 |
|
典型场景 |
API限流 |
金融交易 |
Sentinel |
针对大模型接口的特点,建议按以下方式选型:
ChatGPT/Claude等国际API:建议使用令牌桶算法。原因是这类API通常有较高的速率限制,且允许一定程度的突发流量。通过令牌桶算法,既能保护系统不被过载,又能让用户在需要时获得较好的响应体验。
sentinel:
flow:
rules:
- resource: llm:chat:gpt-4
grade: 1 # QPS限流
count: 500 # 每秒500请求
controlBehavior: 0 # 直接拒绝
国内大模型API(如文心、通义):建议使用滑动窗口算法。这类API通常有较为严格的QPS限制,需要精确控制请求速率。滑动窗口算法可以提供更精确的限流效果。
sentinel:
flow:
rules:
- resource: llm:chat:qwen
grade: 1 # QPS限流
count: 100 # 每秒100请求
controlBehavior: 0 # 直接拒绝
批量处理场景:建议使用漏桶算法或并发线程数限流。批量任务的特点是请求量大、延迟不敏感,但需要控制对系统资源的占用。通过漏桶或并发限流,可以确保批量任务以稳定的速率消耗系统资源。
sentinel:
flow:
rules:
- resource: llm:batch:process
grade: 2 # 并发线程数限流
count: 5 # 最多5个并发
第五章:Spring Boot集成Sentinel
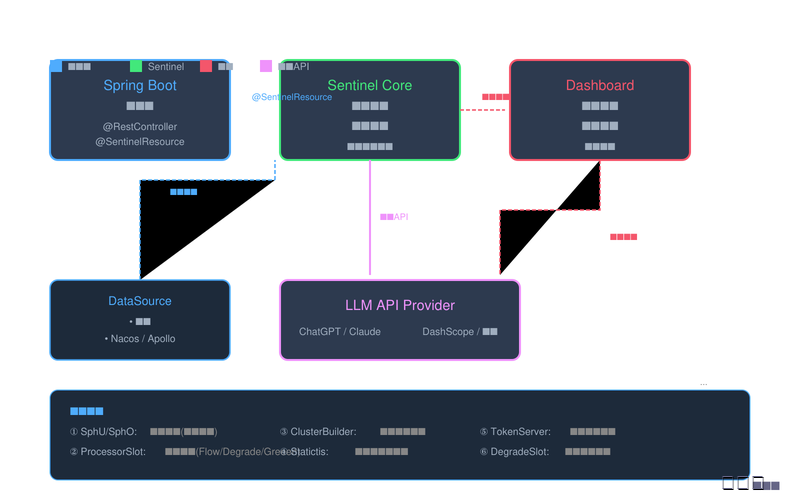
图4:Spring Boot集成Sentinel原理图
5.1 依赖配置与启动器
Spring Boot集成Sentinel非常便捷,通过添加Spring Boot Starter即可完成基础配置。Sentinel为Spring Boot 2.x和Spring Boot 1.x分别提供了不同的 starters,开发者需要根据项目使用的Spring Boot版本选择合适的依赖。
对于使用Spring Boot 2.x的项目,需要添加以下依赖:
<!-- Maven依赖配置 -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-spring-boot-starter</artifactId>
<version>1.8.6</version>
</dependency>
对于使用Spring Boot 1.x的项目,则需要使用:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-spring-boot1-starter</artifactId>
<version>1.8.6</version>
</dependency>
除了Starter依赖外,如果需要使用Sentinel的注解功能(如@SentinelResource),还需要添加注解处理依赖:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-annotation-aspectj</artifactId>
<version>1.8.6</version>
</dependency>
在application.yml或application.properties中,可以配置Sentinel的基本参数:
spring:
application:
name: llm-gateway-service
csp:
# Sentinel Dashboard地址
dashboard:
config:
addr: 127.0.0.1:8080
# 日志文件路径
log:
dir: ./logs/sentinel
# 日志开关
sentinel:
log:
switch: true
5.2 @SentinelResource注解详解
@SentinelResource注解是Sentinel与Spring Boot集成的核心,它用于定义资源并配置限流和降级处理逻辑。
@RestController
@RequestMapping("/api/llm")
public class LLMController {
@GetMapping("/chat")
@SentinelResource(
value = "llm:chat",
blockHandler = "chatBlockHandler",
fallback = "chatFallback",
exceptionsToIgnore = {BusinessException.class}
)
public ResponseEntity<String> chat(@RequestParam String prompt) {
return llmService.chat(prompt);
}
// 限流处理方法 - 参数和返回值必须与原方法一致
public ResponseEntity<String> chatBlockHandler(
String prompt,
BlockException e,
HttpServletRequest request) {
log.warn("触发限流: prompt={}, error={}", prompt, e.getMessage());
return ResponseEntity
.status(429)
.body("请求过于频繁,请稍后再试");
}
// 降级处理方法 - Throwable参数接收异常
public ResponseEntity<String> chatFallback(
String prompt,
Throwable throwable,
HttpServletRequest request) {
log.error("服务降级: prompt={}, error={}", prompt, throwable.getMessage());
return ResponseEntity
.status(503)
.body("服务暂时不可用,请稍后再试");
}
}
@SentinelResource注解的主要属性说明:
- value:资源名称,必须唯一。建议采用有意义的命名规范,如`模块:功能:具体资源`。
- blockHandler:限流/熔断时的处理方法名。该方法必须与原方法在同一个类中,参数列表必须包含原方法的所有参数,外加一个`BlockException`参数。
- blockHandlerClass:指定blockHandler所在的类。当处理逻辑较复杂或需要在多个Controller间共享时,可以将处理方法抽取到独立的类中。
- fallback:业务异常降级时的处理方法名。该方法的参数列表必须包含原方法的所有参数,外加一个`Throwable`参数。
- fallbackClass:指定fallback所在的类。
- exceptionsToIgnore:指定忽略的异常类型,这些异常不会触发fallback。
5.3 配置类与规则加载
除了通过Dashboard动态配置规则外,还可以通过Java配置类或配置文件静态加载规则。这种方式适合将规则与代码一起管理,通过版本控制系统进行追踪。
@Configuration
public class SentinelRulesConfig {
@PostConstruct
public void init() {
initFlowRules();
initDegradeRules();
initSystemRules();
}
/**
* 初始化流量控制规则
*/
private void initFlowRules() {
List<FlowRule> rules = new ArrayList<>();
// ChatGPT接口限流规则
FlowRule gptRule = new FlowRule("llm:chat:gpt-4")
.setGrade(RuleConstant.FLOW_GRADE_QPS)
.setCount(100) // 每秒100次
.setControlBehavior(RuleConstant.CONTROL_BEHAVIOR_DEFAULT)
.setStrategy(RuleConstant.STRATEGY_DIRECT)
.setResourceType(RuleConstant.RESOURCE_TYPE_API);
rules.add(gptRule);
// Claude接口限流规则
FlowRule claudeRule = new FlowRule("llm:chat:claude-3")
.setGrade(RuleConstant.FLOW_GRADE_QPS)
.setCount(80) // 每秒80次
.setControlBehavior(RuleConstant.CONTROL_BEHAVIOR_DEFAULT)
.setStrategy(RuleConstant.STRATEGY_DIRECT)
.setResourceType(RuleConstant.RESOURCE_TYPE_API);
rules.add(claudeRule);
// 批量处理限流规则(并发线程数)
FlowRule batchRule = new FlowRule("llm:batch:process")
.setGrade(RuleConstant.FLOW_GRADE_THREAD)
.setCount(5) // 最多5个并发
.setControlBehavior(RuleConstant.CONTROL_BEHAVIOR_DEFAULT)
.setStrategy(RuleConstant.STRATEGY_DIRECT)
.setResourceType(RuleConstant.RESOURCE_TYPE_API);
rules.add(batchRule);
FlowRuleManager.loadRules(rules);
}
/**
* 初始化熔断降级规则
*/
private void initDegradeRules() {
List<DegradeRule> rules = new ArrayList<>();
// 大模型API熔断规则(RT熔断)
DegradeRule llmRule = new DegradeRule("llm:chat:common")
.setGrade(RuleConstant.DEGRADE_GRADE_RT)
.setCount(30000) // 30秒
.setTimeWindow(60) // 熔断60秒
.setMinRequestAmount(10) // 至少10个请求
.setSlowRatioThreshold(0.8); // 80%慢调用触发
rules.add(llmRule);
// 异常比例熔断(备用)
DegradeRule exceptionRule = new DegradeRule("llm:chat:exception")
.setGrade(RuleConstant.DEGRADE_GRADE_EXCEPTION_RATIO)
.setCount(0.5) // 50%异常比例
.setTimeWindow(30) // 熔断30秒
.setMinRequestAmount(5); // 至少5个请求
rules.add(exceptionRule);
DegradeRuleManager.loadRules(rules);
}
/**
* 初始化系统自适应规则
*/
private void initSystemRules() {
List<SystemRule> rules = new ArrayList<>();
SystemRule rule = new SystemRule()
.setHighestSystemLoad(10.0) // 最高系统负载
.setQps(1000) // 最高QPS
.setAvgRt(5000) // 最高平均响应时间(ms)
.setMaxThread(200); // 最高并发线程数
rules.add(rule);
SystemRuleManager.loadRules(rules);
}
}
5.4 拦截器与全局过滤器
除了注解方式外,Sentinel还支持通过拦截器和全局过滤器与Spring MVC集成。这种方式更适合需要对所有请求进行统一流量控制的场景。
/**
* Sentinel全局过滤器配置
*/
@Configuration
public class SentinelFilterConfig {
@Bean
public FilterRegistrationBean<SentinelFilter> sentinelFilter() {
FilterRegistrationBean<SentinelFilter> registration = new FilterRegistrationBean<>();
registration.setFilter(new CommonFilter());
registration.addUrlPatterns("/*");
registration.setName("sentinelFilter");
registration.setOrder(Ordered.HIGHEST_PRECEDENCE + 100);
return registration;
}
}
/**
* 自定义Sentinel过滤器 - 实现更细粒度的URL级限流
*/
public class CustomSentinelFilter extends CommonFilter {
@Override
protected Route route(ServiceCombServiceInvoker invoker, ServiceInvocation invocation) {
// 根据URL生成资源名
String path = invocation.getPath();
String method = invocation.getMethod();
String resourceName = String.format("%s:%s", method, path);
try {
Entry entry = SphU.entry(resourceName);
// 请求被放行
invocation.put("sentinel-entry", entry);
} catch (BlockException e) {
// 请求被限流
throw new FlowLimitException("请求过于频繁");
}
return super.route(invoker, invocation);
}
}

第六章:热点参数限流与系统自适应限流
6.1 热点参数限流的概念与场景
热点参数限流(Hot Spot Parameter Flow Limiting)是Sentinel提供的一种高级流量控制能力,它可以对携带特定参数值的请求进行精细化限流。在大模型应用场景中,热点参数限流有着独特的应用价值。
考虑以下场景:用户的对话请求中可能包含一些"热点词汇"或"热点话题",这些词汇的请求量会显著高于普通词汇。例如,在新闻事件发生时,与该事件相关的讨论请求可能会激增;某些热门角色或IP的讨论也可能产生突发流量。通过热点参数限流,我们可以识别这些热点请求并实施差异化的限流策略。
另一个典型场景是Token消耗控制。大模型API的Token消耗与输入长度密切相关。对于输入较长的请求,应该采用更严格的限流策略,避免大量长请求耗尽Token配额。Sentinel支持基于参数值的限流规则,可以根据输入长度设置不同的阈值:
@Configuration
public class HotSpotParamConfig {
@PostConstruct
public void init() {
// 加载热点参数限流规则
List<HotSpotParamRule> rules = new ArrayList<>();
// 按Token消耗等级限流
HotSpotParamRule tokenRule = new HotSpotParamRule()
.setResource("llm:chat")
.setParamIdx(0) // 第一个参数(prompt)
.setGrade(RuleConstant.FLOW_GRADE_QPS)
.setCount(50) // 默认每秒50次
.setDurationSec(1)
.setParamFlowItemList(Arrays.asList(
// 短输入(<100字符):较高限额
new ParamFlowItem().setCount(100).setObject(new StringValue("short")),
// 长输入(>1000字符):较低限额
new ParamFlowItem().setCount(10).setObject(new StringValue("long"))
));
rules.add(tokenRule);
HotSpotParamRuleManager.loadRules(rules);
}
}
6.2 热点参数限流的实现原理
Sentinel的热点参数限流通过ParamFlowSlot实现。其工作原理如下:
- 参数提取:当请求进入`ParamFlowSlot`时,插槽会提取配置的热点参数索引对应的参数值。
- 参数分类:根据参数值,将请求归类到不同的参数项(ParamItem)。如果参数值匹配某个配置的项,则应用该项的限流阈值;否则应用默认阈值。
- 限流判断:对每个参数项,Sentinel维护独立的计数器。通过滑动窗口统计每个参数项的请求数量,判断是否超过阈值。
- 参数例外项:Sentinel支持配置参数例外项(ParamFlowItem),用于对特定参数值设置特殊的限流阈值。
// 热点参数限流核心逻辑
public class ParamFlowSlot extends AbstractLinkedProcessorSlot<DefaultNode> {
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node,
int count, Object[] args, Runnable prioritizedTicket,
boolean ascending) throws Throwable {
// 获取配置的热点参数规则
List<HotSpotParamRule> rules = HotSpotParamRuleManager.getRulesOfResource(resourceWrapper.getName());
if (rules == null || rules.isEmpty()) {
fireEntry(context, resourceWrapper, node, count, args, prioritizedTicket, ascending);
return;
}
// 遍历规则进行检验
for (HotSpotParamRule rule : rules) {
// 获取参数值
Object paramValue = extractParam(rule, args);
// 获取参数项
ParamFlowRule flowRule = findParamFlowRule(rule, paramValue);
// 检查限流
checkParameterFlow(resourceWrapper, context, rule, flowRule, paramValue, count);
}
fireEntry(context, resourceWrapper, node, count, args, prioritizedTicket, ascending);
}
private void checkParameterFlow(ResourceWrapper resourceWrapper, Context context,
HotSpotParamRule rule, ParamFlowRule flowRule,
Object paramValue, int count) throws BlockException {
// 如果没有匹配的特殊参数项,使用默认阈值
long appliedThreshold = flowRule != null ? flowRule.getCount() : rule.getCount();
// 从缓存获取或创建参数计数器
CacheMap<Object, AtomicLong> counterMap = getParamCounter(resourceWrapper, rule);
AtomicLong counter = counterMap.putIfAbsent(paramValue, new AtomicLong(0));
// 检查是否超限
if (counter.addAndGet(count) > appliedThreshold) {
throw new ParamFlowException(rule.getResource(), paramValue, rule);
}
}
}
6.3 系统自适应限流
系统自适应限流(System Adaptive Flow Limiting)是Sentinel根据系统当前负载状态自动调整保护策略的机制。与传统的静态限流规则不同,自适应限流能够根据系统的实时状况动态决定何时启动保护。
Sentinel支持以下几种系统自适应策略:
系统负载保护(System Load):当系统负载(Load)超过阈值时触发限流。这里的负载指的是操作系统级别的负载均值(Load Average),而不是CPU使用率。Load能够更准确地反映系统的整体压力状况——即使CPU使用率不高,如果大量请求在等待I/O或锁,Load也会升高。
// 系统负载保护配置
SystemRule rule = new SystemRule()
.setHighestSystemLoad(10.0) // 当Load超过10时触发
.build();
SystemRuleManager.loadRules(Collections.singletonList(rule));
平均响应时间保护(Average RT):当所有资源的平均响应时间超过阈值时触发限流。
SystemRule rule = new SystemRule()
.setAvgRt(5000) // 平均响应时间超过5秒时触发
.build();
QPS保护(QPS):当系统的总QPS超过阈值时触发限流。
SystemRule rule = new SystemRule()
.setQps(10000) // 系统总QPS超过10000时触发
.build();
并发线程数保护(Max Thread):当系统的总并发线程数超过阈值时触发限流。
SystemRule rule = new SystemRule()
.setMaxThread(500) // 并发线程数超过500时触发
.build();
系统自适应限流的触发逻辑采用"与"的关系——当任一条件满足时,系统保护就会启动。这确保了在各种可能的系统过载场景下都能提供保护。
6.4 限流策略与系统保护的结合
在大模型应用中,静态限流规则和自适应限流策略应该结合使用,以实现多层次的保护:
# 多层次限流配置示例
spring:
application:
name: llm-gateway
csp:
sentinel:
# 流量控制规则
flow:
rules:
# 静态QPS限流
- resource: llm:chat:gpt-4
grade: 1
count: 100
controlBehavior: 0
# 并发线程数限流
- resource: llm:chat:gpt-4
grade: 0
count: 20
# 熔断降级规则
degrade:
rules:
- resource: llm:chat:common
grade: 1
count: 30000
timeWindow: 60
minRequestAmount: 10
slowRatioThreshold: 0.8
# 系统自适应规则
system:
rules:
- highestSystemLoad: 10.0
avgRt: 10000
maxThread: 200
qps: 5000
这种多层保护的机制如下:
- 第一层:静态QPS限流 - 正常情况下,按照预设的QPS阈值进行限流
- 第二层:并发线程数限流 - 当系统并发压力增大时,控制同时处理的请求数
- 第三层:熔断降级 - 当大模型API响应变慢或失败增多时,触发熔断
- 第四层:系统自适应保护 - 当系统整体负载过高时,全面启动保护
第七章:熔断后的降级策略设计
7.1 降级策略的设计原则
降级策略的核心目标是在服务不可用时提供有损服务,而不是完全不可用。好的降级策略应该遵循以下原则:
快速响应:降级响应应该尽可能快,避免用户长时间等待。当检测到服务异常时,系统应该立即返回降级结果,而不是继续尝试调用已经不可靠的服务。
最小依赖:降级逻辑应该尽可能减少对外部系统的依赖。理想的降级方案是纯本地计算,不涉及网络调用。例如,返回预定义的默认回复、使用本地缓存的结果等。
分级处理:不同的异常情况应该采用不同的降级策略。轻微的性能下降可以返回稍慢的结果;严重的服务不可用应该返回简化的结果或友好的错误提示。
可观测性:降级触发时应该有完善的日志和监控记录,便于运维人员了解系统状态和排查问题。
7.2 返回缓存策略
对于大模型应用,返回缓存是最常用也是最有效的降级策略之一。当大模型服务不可用时,可以返回最近使用过的相似请求的结果。这种策略的前提是有足够大的缓存空间存储历史请求和回复。
@Service
public class LLMServiceWithCache {
private final LLMService originalService;
private final Cache<String, String> responseCache;
public LLMServiceWithCache(LLMService originalService) {
this.originalService = originalService;
// 配置缓存:最大10000条,最大1GB,TTL 1小时
this.responseCache = Caffeine.newBuilder()
.maximumSize(10000)
.maximumWeight(1024 * 1024 * 1024) // 1GB
.expireAfterWrite(Duration.ofHours(1))
.build();
}
public String chat(String prompt) {
try {
String response = originalService.chat(prompt);
// 缓存成功响应
responseCache.put(prompt, response);
return response;
} catch (Exception e) {
// 服务异常,尝试返回缓存
String cached = responseCache.getIfPresent(prompt);
if (cached != null) {
log.info("返回缓存响应: prompt={}", prompt.substring(0, Math.min(50, prompt.length())));
return "[缓存]" + cached;
}
// 没有缓存,尝试模糊匹配
cached = findSimilarResponse(prompt);
if (cached != null) {
log.info("返回相似缓存响应");
return "[相似缓存]" + cached;
}
// 缓存也没有,执行降级
throw new ServiceDegradedException("服务不可用且无缓存");
}
}
/**
* 模糊匹配相似问题
*/
private String findSimilarResponse(String prompt) {
// 简单的关键词匹配
String keywords = extractKeywords(prompt);
return responseCache.asMap().entrySet().stream()
.filter(e -> matchKeywords(keywords, e.getKey()))
.max(Comparator.comparingInt(e -> calculateMatchScore(keywords, e.getKey())))
.map(Entry::getValue)
.orElse(null);
}
}
缓存降级策略的关键设计点包括:
- 缓存容量规划:根据业务量预估缓存大小,避免内存溢出。对于大模型场景,每个响应可能占用数十KB甚至更多,需要合理控制缓存数量。
- 缓存键设计:使用Prompt的哈希值或规范化后的字符串作为键,避免存储重复内容。
- 缓存过期策略:设置合理的TTL,既能保证结果的时效性,又不会无限占用空间。
- 相似匹配:当精确匹配失败时,可以尝试模糊匹配相似的历史请求,提高降级成功率。
7.3 返回默认值策略
返回默认值是一种简单直接的降级策略。当服务不可用时,返回一个预设的默认回复。这种策略适合对结果精确度要求不高的场景,或者作为多层降级策略的最后一层。
@RestController
@RequestMapping("/api/llm")
public class LLMController {
/**
* 默认回复列表(按场景分类)
*/
private static final Map<String, String> DEFAULT_RESPONSES = Map.of(
"greeting", "您好,我现在比较忙碌,请稍后再试。",
"question", "抱歉,服务暂时不可用。请您稍后再试,或联系客服获取帮助。",
"complaint", "非常抱歉给您带来不便,我们会尽快处理您的问题。",
"default", "抱歉,服务遇到了一些问题,请稍后再试。"
);
@GetMapping("/chat")
@SentinelResource(
value = "llm:chat",
blockHandler = "chatBlockHandler",
fallback = "chatFallback"
)
public ResponseEntity<String> chat(@RequestParam String prompt) {
return llmService.chat(prompt);
}
public ResponseEntity<String> chatFallback(
String prompt,
Throwable t,
HttpServletRequest request) {
// 根据Prompt内容选择合适的默认回复
String defaultResponse = selectDefaultResponse(prompt);
log.warn("触发降级返回默认回复: prompt={}, error={}", prompt, t.getMessage());
return ResponseEntity
.status(200) // 返回200,但内容是降级后的默认回复
.body(defaultResponse);
}
private String selectDefaultResponse(String prompt) {
String lowerPrompt = prompt.toLowerCase();
if (lowerPrompt.contains("你好") || lowerPrompt.contains("hi") || lowerPrompt.contains("hello")) {
return DEFAULT_RESPONSES.get("greeting");
}
if (lowerPrompt.contains("怎么") || lowerPrompt.contains("如何") || lowerPrompt.contains("??")) {
return DEFAULT_RESPONSES.get("question");
}
if (lowerPrompt.contains("差") || lowerPrompt.contains("投诉") || lowerPrompt.contains("不满")) {
return DEFAULT_RESPONSES.get("complaint");
}
return DEFAULT_RESPONSES.get("default");
}
}
7.4 快速失败策略
快速失败(Fail Fast)策略适用于对实时性要求高、不允许返回不可靠结果的场景。当检测到服务不可用时,立即返回错误,而不是等待超时后再返回错误。这种策略可以避免浪费用户时间,让用户立即获得反馈并决定是否重试。
public class FastFailLLMService implements LLMService {
private final LLMService originalService;
private final HealthChecker healthChecker;
public FastFailLLMService(LLMService originalService, HealthChecker healthChecker) {
this.originalService = originalService;
this.healthChecker = healthChecker;
}
@Override
public String chat(String prompt) {
// 快速失败:先检查服务健康状态
if (!healthChecker.isHealthy()) {
throw new ServiceUnavailableException("服务当前不可用,请稍后再试");
}
try {
return originalService.chat(prompt);
} catch (Exception e) {
// 标记服务为不健康
healthChecker.markUnhealthy();
throw e;
}
}
}
/**
* 健康检查器 - 维护服务健康状态
*/
@Component
public class HealthChecker {
private final AtomicBoolean healthy = new AtomicBoolean(true);
private final AtomicLong lastFailureTime = new AtomicLong(0);
private static final long RECOVERY_INTERVAL = 30_000; // 30秒后尝试恢复
public boolean isHealthy() {
if (healthy.get()) {
return true;
}
// 如果处于不健康状态,检查是否超时
if (System.currentTimeMillis() - lastFailureTime.get() > RECOVERY_INTERVAL) {
healthy.set(true);
return true;
}
return false;
}
public void markUnhealthy() {
healthy.set(false);
lastFailureTime.set(System.currentTimeMillis());
}
}
7.5 多级降级策略
在实际生产环境中,可以将多种降级策略组合成多级降级方案,根据不同的异常情况逐级尝试:
public class MultiLevelDegradedLLMService implements LLMService {
private final LLMService originalService;
private final Cache<String, String> responseCache;
private final DefaultResponseSelector responseSelector;
public MultiLevelDegradedLLMService(LLMService originalService) {
this.originalService = originalService;
this.responseCache = Caffeine.newBuilder().maximumSize(10000).build();
this.responseSelector = new DefaultResponseSelector();
}
@Override
public String chat(String prompt) {
try {
// 第一级:尝试正常调用
String response = originalService.chat(prompt);
// 缓存成功响应
responseCache.put(generateCacheKey(prompt), response);
return response;
} catch (DegradeException e) {
// 第二级:熔断中,尝试返回缓存
return tryFallback1(prompt);
} catch (TimeoutException e) {
// 第三级:超时,尝试返回缓存
return tryFallback2(prompt);
} catch (Exception e) {
// 第四级:其他异常,返回默认值
return tryFallback3(prompt);
}
}
/**
* 第二级降级:返回缓存响应
*/
private String tryFallback1(String prompt) {
String cached = responseCache.getIfPresent(generateCacheKey(prompt));
if (cached != null) {
log.info("降级1: 返回缓存响应");
return "[系统繁忙,返回缓存] " + cached;
}
// 没有精确缓存,尝试模糊匹配
cached = findSimilarResponse(prompt);
if (cached != null) {
return "[系统繁忙,返回相似缓存] " + cached;
}
// 缓存也没有,尝试第三级降级
return tryFallback2(prompt);
}
/**
* 第三级降级:返回简短回复
*/
private String tryFallback2(String prompt) {
String shortResponse = responseCache.getIfPresent("short:" + generateCacheKey(prompt));
if (shortResponse != null) {
log.info("降级2: 返回简短缓存响应");
return "[系统繁忙] " + shortResponse;
}
return tryFallback3(prompt);
}
/**
* 第四级降级:返回默认回复
*/
private String tryFallback3(String prompt) {
log.warn("降级3: 返回默认回复");
return responseSelector.selectDefaultResponse(prompt);
}
private String generateCacheKey(String prompt) {
// 简化为取前100字符的哈希
return String.valueOf(prompt.substring(0, Math.min(100, prompt.length())).hashCode());
}
}
第八章:规则持久化
8.1 规则持久化的必要性
在生产环境中,Sentinel的规则配置通常需要在多个应用实例之间保持一致。当通过Dashboard动态修改规则时,这些规则需要被同步到所有应用实例。同时,当应用重启时,动态修改的规则不应该丢失。这些需求都需要规则持久化的支持。
Sentinel支持两种规则同步模式:推模式(Push)和拉模式(Pull)。
8.2 推模式(Push Mode)
推模式是指Sentinel Dashboard将规则实时推送给应用实例。这种模式需要依赖配置中心(如Nacos、Apollo、ZooKeeper等)来实现规则的发布和订阅。
推模式的架构如下:
- 管理员在Dashboard上修改规则
- Dashboard将规则写入配置中心
- 配置中心通知所有订阅的应用实例
- 应用实例更新本地规则缓存
# Nacos作为配置中心的推模式配置
spring:
application:
name: llm-gateway
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
config:
server-addr: 127.0.0.1:8848
file-extension: yaml
csp:
sentinel:
# Nacos数据源配置
datasource:
ds:
nacos:
server-addr: 127.0.0.1:8848
data-id: ${spring.application.name}-sentinel-rules
group-id: DEFAULT_GROUP
data-type: json
rule-type: flow # flow/degrade/system/param-flow
// Nacos中存储的规则数据格式
[
{
"resource": "llm:chat:gpt-4",
"limitApp": "default",
"grade": 1,
"count": 100,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]
使用Nacos作为配置中心的推模式实现:
@Configuration
public class SentinelNacosConfig {
@Bean
public SentinelDataSourceBeanFactory FlowDataSource() {
// 配置Nacos数据源
NacosDataSourceProperties properties = new NacosDataSourceProperties();
properties.setServerAddr("127.0.0.1:8848");
properties.setDataId("llm-gateway-sentinel-rules");
properties.setGroupId("DEFAULT_GROUP");
properties.setDataType("json");
// 创建Flow规则数据源
NacosDataSource<List<FlowRule>> dataSource =
new NacosDataSource<>(properties, FlowRule.class, new Converter<String, List<FlowRule>>() {
@Override
public List<FlowRule> convert(String source) {
return JSON.parseArray(source, FlowRule.class);
}
});
// 注册到FlowRuleManager
FlowRuleManager.register2Property(dataSource.getProperty());
return dataSource;
}
}
推模式的优势是实时性高,规则变更可以立即生效;缺点是需要依赖额外的配置中心组件。
8.3 拉模式(Pull Mode)
拉模式是指应用实例定期从配置源(如文件、数据库)拉取规则并更新本地缓存。这种模式实现简单,不需要额外的配置中心组件,但实时性较差。
# 文件数据源配置(拉模式)
csp:
sentinel:
datasource:
# 流量规则文件
flow:
file:
file-path: /path/to/rules/flow-rule.json
data-type: json
rule-type: flow
# 降级规则文件
degrade:
file:
file-path: /path/to/rules/degrade-rule.json
data-type: json
rule-type: degrade
// flow-rule.json
[
{
"resource": "llm:chat:gpt-4",
"limitApp": "default",
"grade": 1,
"count": 100,
"strategy": 0,
"controlBehavior": 0
}
]
// degrade-rule.json
[
{
"resource": "llm:chat:common",
"limitApp": "default",
"grade": 1,
"count": 30000,
"timeWindow": 60,
"minRequestAmount": 10,
"slowRatioThreshold": 0.8
}
]
使用数据库作为数据源的拉模式实现:
@Configuration
public class SentinelDbConfig {
@Bean
public DataSource<String, List<FlowRule>> flowDataSource() {
// 使用DB规则管理器
DBDataSource<List<FlowRule>> dataSource = new DBDataSource<>(
() -> loadRulesFromDb(),
new Converter<List<FlowRule>, String>() {
@Override
public String convert(List<FlowRule> source) {
return JSON.toJSONString(source);
}
}
);
FlowRuleManager.register2DataSource(dataSource);
return dataSource;
}
private List<FlowRule> loadRulesFromDb() {
// 从数据库加载规则
List<FlowRule> rules = jdbcTemplate.query(
"SELECT * FROM sentinel_flow_rules WHERE enabled = 1",
(rs, rowNum) -> {
FlowRule rule = new FlowRule();
rule.setResource(rs.getString("resource"));
rule.setGrade(rs.getInt("grade"));
rule.setCount(rs.getDouble("count"));
rule.setStrategy(rs.getInt("strategy"));
rule.setControlBehavior(rs.getInt("controlBehavior"));
return rule;
}
);
return rules;
}
}
8.4 规则持久化的最佳实践
在实际生产环境中,建议采用以下策略:
- 规则分类管理:将静态规则(几乎不需要修改)通过配置文件管理,将动态规则(需要频繁调整)通过配置中心管理。
- 规则版本控制:在配置中心存储规则时,应该包含版本号信息,便于回滚和问题追溯。
- 规则校验:在Dashboard修改规则前,应该进行参数校验,避免配置错误的规则导致系统异常。
- 多数据源备份:对于关键业务,可以同时配置多个数据源,当一个数据源不可用时自动切换到备用数据源。
# 综合配置示例:Nacos + 文件备份
csp:
sentinel:
datasource:
# 优先使用Nacos
flow:
nacos:
server-addr: 127.0.0.1:8848
data-id: ${spring.application.name}-flow-rules
group-id: DEFAULT_GROUP
data-type: json
rule-type: flow
# 文件作为备用
file:
file-path: /path/to/rules/flow-rule.json
data-type: json
rule-type: flow
# 降级后重试间隔
cold-interval: 30000
第九章:实战——保护ChatGPT/DashScope接口
9.1 项目背景与架构设计
假设我们正在构建一个企业级AI助手服务,该服务整合了多个大模型API,包括OpenAI的ChatGPT、阿里云的DashScope以及Anthropic的Claude。用户可以通过统一的API调用这些服务,系统会根据负载、可用性等因素自动选择或切换不同的模型提供商。
系统的技术架构如下:
用户请求 → API Gateway → 负载均衡 → LLM Gateway Service
↓
┌─────────────────────┼─────────────────────┐
↓ ↓ ↓
ChatGPT代理 DashScope代理 Claude代理
↓ ↓ ↓
OpenAI API 阿里云DashScope Anthropic API
LLM Gateway Service是我们需要重点保护的服务,它负责:
- 接收来自API Gateway的请求
- 调用不同的大模型API
- 处理响应并返回给上游
- 实现熔断降级、限流等保护逻辑
9.2 完整配置示例
9.2.1 Maven依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>llm-gateway</artifactId>
<version>1.0.0</version>
<packaging>jar</packaging>
<name>LLM Gateway Service</name>
<description>大模型网关服务</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.14</version>
</parent>
<properties>
<java.version>17</java.version>
<sentinel.version>1.8.6</sentinel.version>
</properties>
<dependencies>
<!-- Spring Boot Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Sentinel Spring Boot Starter -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-spring-boot-starter</artifactId>
<version>${sentinel.version}</version>
</dependency>
<!-- Sentinel Annotation AspectJ -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-annotation-aspectj</artifactId>
<version>${sentinel.version}</version>
</dependency>
<!-- Sentinel Web Servlet Filter -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-web-servlet</artifactId>
<version>${sentinel.version}</version>
</dependency>
<!-- Nacos Client (用于规则持久化) -->
<dependency>
<groupId>com.alibaba.nacos</groupId>
<artifactId>nacos-client</artifactId>
<version>2.2.0</version>
</dependency>
<!-- Caffeine Cache (用于降级缓存) -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.8</version>
</dependency>
<!-- OkHttp (用于HTTP调用) -->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.12.0</version>
</dependency>
<!-- JSON处理 -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.10.1</version>
</dependency>
<!-- Lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- Test -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
9.2.2 application.yml配置
server:
port: 8080
spring:
application:
name: llm-gateway
# Sentinel基础配置
csp:
sentinel:
# Dashboard地址
dashboard:
config:
addr: 127.0.0.1:8080
# 日志配置
log:
dir: ./logs/sentinel
switch: true
# API调用超时配置
api:
timeout: 60000 # 60秒
# 大模型API配置
llm:
providers:
chatgpt:
enabled: true
api-key: ${CHATGPT_API_KEY}
base-url: https://api.openai.com/v1
model: gpt-4
max-tokens: 4096
timeout: 60000
dashscope:
enabled: true
api-key: ${DASHSCOPE_API_KEY}
base-url: https://dashscope.aliyuncs.com/api/v1
model: qwen-turbo
timeout: 30000
claude:
enabled: true
api-key: ${CLAUDE_API_KEY}
base-url: https://api.anthropic.com
model: claude-3-sonnet-20240229
max-tokens: 4096
timeout: 60000
# Sentinel规则配置
sentinel:
# 流量控制规则
flow:
rules:
- resource: llm:chat:gpt-4
grade: 1 # QPS
count: 100
controlBehavior: 0 # 直接拒绝
strategy: 0
- resource: llm:chat:dashscope
grade: 1
count: 200
controlBehavior: 0
strategy: 0
- resource: llm:chat:claude
grade: 1
count: 80
controlBehavior: 0
strategy: 0
# 并发线程数限制
- resource: llm:chat:any
grade: 0 # 并发线程数
count: 50
controlBehavior: 0
strategy: 0
# 熔断降级规则
degrade:
rules:
- resource: llm:chat:gpt-4
grade: 1 # RT熔断
count: 45000 # 45秒
timeWindow: 60 # 熔断60秒
minRequestAmount: 5
slowRatioThreshold: 0.7
- resource: llm:chat:dashscope
grade: 1
count: 25000 # 25秒
timeWindow: 30
minRequestAmount: 5
slowRatioThreshold: 0.8
- resource: llm:chat:claude
grade: 1
count: 40000 # 40秒
timeWindow: 60
minRequestAmount: 5
slowRatioThreshold: 0.7
# 异常比例熔断(备用)
- resource: llm:chat:any
grade: 2 # 异常比例
count: 0.5 # 50%
timeWindow: 60
minRequestAmount: 10
# 系统自适应规则
system:
rules:
- highestSystemLoad: 8.0
avgRt: 30000
maxThread: 100
qps: 1000
# Nacos配置(用于规则持久化)
nacos:
server-addr: 127.0.0.1:8848
namespace: public
group: DEFAULT_GROUP
9.2.3 LLM服务接口定义
/**
* 大模型服务接口
*/
public interface LLMService {
/**
* 对话生成
* @param prompt 输入提示
* @param model 模型类型
* @return 生成的回复
*/
String chat(String prompt, String model);
/**
* 带上下文的对话生成
* @param messages 消息历史
* @param model 模型类型
* @return 生成的回复
*/
String chatWithContext(List<Message> messages, String model);
}
/**
* 消息对象
*/
@Data
public class Message {
private String role; // system, user, assistant
private String content; // 消息内容
private LocalDateTime timestamp;
public Message() {}
public Message(String role, String content) {
this.role = role;
this.content = content;
this.timestamp = LocalDateTime.now();
}
}
9.2.4 LLM服务实现
@Service
@Slf4j
public class LLMServiceImpl implements LLMService {
private final Map<String, LLMProvider> providers;
private final ResponseCacheService cacheService;
private final HealthCheckService healthCheck;
public LLMServiceImpl(
Map<String, LLMProvider> providers,
ResponseCacheService cacheService,
HealthCheckService healthCheck) {
this.providers = providers;
this.cacheService = cacheService;
this.healthCheck = healthCheck;
}
@Override
@SentinelResource(
value = "llm:chat",
blockHandler = "chatBlockHandler",
fallback = "chatFallback"
)
public String chat(String prompt, String model) {
// 健康检查
if (!healthCheck.isHealthy(model)) {
log.warn("模型 {} 当前不健康,尝试降级", model);
return tryFallback(prompt, model);
}
LLMProvider provider = providers.get(model);
if (provider == null) {
throw new IllegalArgumentException("不支持的模型: " + model);
}
try {
String response = provider.chat(prompt);
// 缓存成功响应
cacheService.cache(prompt, response);
return response;
} catch (Exception e) {
log.error("模型 {} 调用失败: {}", model, e.getMessage());
healthCheck.markUnhealthy(model);
throw e;
}
}
@Override
@SentinelResource(
value = "llm:chat:context",
blockHandler = "chatBlockHandler",
fallback = "chatFallback"
)
public String chatWithContext(List<Message> messages, String model) {
if (!healthCheck.isHealthy(model)) {
return tryFallback(messages, model);
}
LLMProvider provider = providers.get(model);
try {
String response = provider.chatWithContext(messages);
// 缓存
String key = generateContextKey(messages);
cacheService.cache(key, response);
return response;
} catch (Exception e) {
log.error("模型 {} 调用失败: {}", model, e.getMessage());
healthCheck.markUnhealthy(model);
throw e;
}
}
/**
* 限流处理
*/
public String chatBlockHandler(String prompt, String model, BlockException e) {
log.warn("触发限流: prompt={}, model={}, error={}",
prompt.substring(0, Math.min(50, prompt.length())), model, e.getMessage());
// 尝试返回缓存
String cached = cacheService.get(prompt);
if (cached != null) {
return "[请求繁忙,返回缓存] " + cached;
}
return "请求过于频繁,请稍后再试。";
}
/**
* 降级处理
*/
public String chatFallback(String prompt, String model, Throwable e) {
log.error("触发降级: prompt={}, model={}, error={}",
prompt.substring(0, Math.min(50, prompt.length())), model, e.getMessage());
// 多级降级
String cached = cacheService.get(prompt);
if (cached != null) {
return "[服务降级,返回缓存] " + cached;
}
return "抱歉,服务暂时不可用,请稍后再试。";
}
/**
* 降级尝试
*/
private String tryFallback(String prompt, String model) {
// 尝试缓存
String cached = cacheService.get(prompt);
if (cached != null) {
return "[降级] " + cached;
}
// 尝试其他健康模型
for (Map.Entry<String, LLMProvider> entry : providers.entrySet()) {
if (!entry.getKey().equals(model) && healthCheck.isHealthy(entry.getKey())) {
try {
return "[切换模型] " + entry.getValue().chat(prompt);
} catch (Exception e) {
log.warn("备用模型 {} 也不可用", entry.getKey());
}
}
}
throw new ServiceUnavailableException("所有模型服务暂时不可用");
}
private String generateContextKey(List<Message> messages) {
return messages.stream()
.map(Message::getContent)
.collect(Collectors.joining("|"))
.hashCode() + "";
}
}
9.2.5 LLM提供者实现
/**
* LLM提供者接口
*/
public interface LLMProvider {
/**
* 提供者名称
*/
String getName();
/**
* 是否启用
*/
boolean isEnabled();
/**
* 对话生成
*/
String chat(String prompt) throws Exception;
/**
* 带上下文的对话生成
*/
String chatWithContext(List<Message> messages) throws Exception;
}
/**
* ChatGPT提供者实现
*/
@Component
@ConditionalOnProperty(name = "llm.providers.chatgpt.enabled", havingValue = "true")
public class ChatGPTProvider implements LLMProvider {
private final String apiKey;
private final String baseUrl;
private final String model;
private final int maxTokens;
private final int timeout;
private final OkHttpClient httpClient;
public ChatGPTProvider(
@Value("${llm.providers.chatgpt.api-key}") String apiKey,
@Value("${llm.providers.chatgpt.base-url}") String baseUrl,
@Value("${llm.providers.chatgpt.model}") String model,
@Value("${llm.providers.chatgpt.max-tokens}") int maxTokens,
@Value("${llm.providers.chatgpt.timeout}") int timeout) {
this.apiKey = apiKey;
this.baseUrl = baseUrl;
this.model = model;
this.maxTokens = maxTokens;
this.timeout = timeout;
this.httpClient = new OkHttpClient.Builder()
.connectTimeout(timeout, TimeUnit.MILLISECONDS)
.readTimeout(timeout, TimeUnit.MILLISECONDS)
.writeTimeout(timeout, TimeUnit.MILLISECONDS)
.build();
}
@Override
public String getName() {
return "chatgpt";
}
@Override
public boolean isEnabled() {
return true;
}
@Override
@SentinelResource(value = "llm:chat:gpt-4", fallback = "chatFallback")
public String chat(String prompt) throws Exception {
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("model", model);
requestBody.put("messages", Collections.singletonList(
Map.of("role", "user", "content", prompt)
));
requestBody.put("max_tokens", maxTokens);
Request request = new Request.Builder()
.url(baseUrl + "/chat/completions")
.addHeader("Authorization", "Bearer " + apiKey)
.addHeader("Content-Type", "application/json")
.post(RequestBody.create(
JSON.toJSONString(requestBody),
MediaType.parse("application/json")
))
.build();
try (Response response = httpClient.newCall(request).execute()) {
if (!response.isSuccessful()) {
throw new HttpResponseException(
response.code(),
"ChatGPT API返回错误: " + response.body().string()
);
}
String responseBody = response.body().string();
Map<String, Object> result = JSON.parseObject(responseBody);
List<Map<String, Object>> choices = (List<Map<String, Object>>) result.get("choices");
if (choices == null || choices.isEmpty()) {
throw new Exception("ChatGPT返回为空");
}
return (String) ((Map<String, Object>)choices.get(0).get("message")).get("content");
}
}
@Override
public String chatWithContext(List<Message> messages) throws Exception {
List<Map<String, String>> chatMessages = messages.stream()
.map(m -> Map.of("role", m.getRole(), "content", m.getContent()))
.collect(Collectors.toList());
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("model", model);
requestBody.put("messages", chatMessages);
requestBody.put("max_tokens", maxTokens);
Request request = new Request.Builder()
.url(baseUrl + "/chat/completions")
.addHeader("Authorization", "Bearer " + apiKey)
.addHeader("Content-Type", "application/json")
.post(RequestBody.create(
JSON.toJSONString(requestBody),
MediaType.parse("application/json")
))
.build();
try (Response response = httpClient.newCall(request).execute()) {
if (!response.isSuccessful()) {
throw new HttpResponseException(response.code(), "API错误");
}
String responseBody = response.body().string();
Map<String, Object> result = JSON.parseObject(responseBody);
List<Map<String, Object>> choices = (List<Map<String, Object>>) result.get("choices");
return (String) ((Map<String, Object>)choices.get(0).get("message")).get("content");
}
}
public String chatFallback(String prompt, Throwable t) {
throw new DegradeException("ChatGPT服务降级", t);
}
}
/**
* DashScope提供者实现
*/
@Component
@ConditionalOnProperty(name = "llm.providers.dashscope.enabled", havingValue = "true")
public class DashScopeProvider implements LLMProvider {
private final String apiKey;
private final String baseUrl;
private final String model;
private final int timeout;
private final OkHttpClient httpClient;
public DashScopeProvider(
@Value("${llm.providers.dashscope.api-key}") String apiKey,
@Value("${llm.providers.dashscope.base-url}") String baseUrl,
@Value("${llm.providers.dashscope.model}") String model,
@Value("${llm.providers.dashscope.timeout}") int timeout) {
this.apiKey = apiKey;
this.baseUrl = baseUrl;
this.model = model;
this.timeout = timeout;
this.httpClient = new OkHttpClient.Builder()
.connectTimeout(timeout, TimeUnit.MILLISECONDS)
.readTimeout(timeout, TimeUnit.MILLISECONDS)
.build();
}
@Override
public String getName() {
return "dashscope";
}
@Override
public boolean isEnabled() {
return true;
}
@Override
@SentinelResource(value = "llm:chat:dashscope", fallback = "chatFallback")
public String chat(String prompt) throws Exception {
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("model", model);
requestBody.put("input", Map.of("prompt", prompt));
Request request = new Request.Builder()
.url(baseUrl + "/services/aigc/text-generation/generation")
.addHeader("Authorization", "Bearer " + apiKey)
.addHeader("Content-Type", "application/json")
.post(RequestBody.create(
JSON.toJSONString(requestBody),
MediaType.parse("application/json")
))
.build();
try (Response response = httpClient.newCall(request).execute()) {
if (!response.isSuccessful()) {
throw new HttpResponseException(response.code(), "DashScope API错误");
}
String responseBody = response.body().string();
Map<String, Object> result = JSON.parseObject(responseBody);
Map<String, Object> output = (Map<String, Object>) result.get("output");
return (String) output.get("text");
}
}
@Override
public String chatWithContext(List<Message> messages) throws Exception {
List<Map<String, String>> chatMessages = messages.stream()
.map(m -> Map.of("role", m.getRole(), "content", m.getContent()))
.collect(Collectors.toList());
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("model", model);
requestBody.put("input", Map.of("messages", chatMessages));
Request request = new Request.Builder()
.url(baseUrl + "/services/aigc/text-generation/generation")
.addHeader("Authorization", "Bearer " + apiKey)
.addHeader("Content-Type", "application/json")
.post(RequestBody.create(
JSON.toJSONString(requestBody),
MediaType.parse("application/json")
))
.build();
try (Response response = httpClient.newCall(request).execute()) {
String responseBody = response.body().string();
Map<String, Object> result = JSON.parseObject(responseBody);
Map<String, Object> output = (Map<String, Object>) result.get("output");
return (String) output.get("text");
}
}
public String chatFallback(String prompt, Throwable t) {
throw new DegradeException("DashScope服务降级", t);
}
}
9.2.6 控制器层
@RestController
@RequestMapping("/api/v1/llm")
@Slf4j
public class LLMController {
private final LLMService llmService;
public LLMController(LLMService llmService) {
this.llmService = llmService;
}
/**
* 简单对话
*/
@GetMapping("/chat")
@SentinelResource(
value = "api:chat",
blockHandler = "blockHandler",
fallback = "fallback"
)
public ResponseEntity<ChatResponse> chat(
@RequestParam String prompt,
@RequestParam(defaultValue = "chatgpt") String model) {
long startTime = System.currentTimeMillis();
String response = llmService.chat(prompt, model);
long latency = System.currentTimeMillis() - startTime;
return ResponseEntity.ok(ChatResponse.builder()
.code(200)
.message("success")
.data(ChatResponse.ChatData.builder()
.answer(response)
.model(model)
.latency(latency)
.build())
.build());
}
/**
* 带上下文的对话
*/
@PostMapping("/chat/context")
@SentinelResource(
value = "api:chat:context",
blockHandler = "blockHandler",
fallback = "fallback"
)
public ResponseEntity<ChatResponse> chatWithContext(
@RequestBody ChatRequest request) {
long startTime = System.currentTimeMillis();
List<Message> messages = request.getMessages().stream()
.map(m -> new Message(m.getRole(), m.getContent()))
.collect(Collectors.toList());
String response = llmService.chatWithContext(messages, request.getModel());
long latency = System.currentTimeMillis() - startTime;
return ResponseEntity.ok(ChatResponse.builder()
.code(200)
.message("success")
.data(ChatResponse.ChatData.builder()
.answer(response)
.model(request.getModel())
.latency(latency)
.build())
.build());
}
/**
* 批量对话
*/
@PostMapping("/chat/batch")
@SentinelResource(
value = "api:chat:batch",
blockHandler = "blockHandler",
fallback = "fallback"
)
public ResponseEntity<BatchChatResponse> batchChat(
@RequestBody BatchChatRequest request) {
List<BatchChatResponse.BatchResult> results = new ArrayList<>();
for (BatchChatRequest.BatchItem item : request.getItems()) {
try {
String response = llmService.chat(item.getPrompt(), request.getModel());
results.add(BatchChatResponse.BatchResult.builder()
.id(item.getId())
.answer(response)
.success(true)
.build());
} catch (Exception e) {
results.add(BatchChatResponse.BatchResult.builder()
.id(item.getId())
.answer(null)
.success(false)
.error(e.getMessage())
.build());
}
}
return ResponseEntity.ok(BatchChatResponse.builder()
.code(200)
.message("success")
.data(results)
.build());
}
/**
* 限流处理
*/
public ResponseEntity<ChatResponse> blockHandler(
String prompt,
String model,
BlockException e,
HttpServletRequest request) {
log.warn("触发限流: prompt={}, model={}, error={}",
prompt.substring(0, Math.min(50, prompt.length())), model, e.getMessage());
return ResponseEntity.status(429).body(ChatResponse.builder()
.code(429)
.message("请求过于频繁,请稍后再试")
.build());
}
/**
* 降级处理
*/
public ResponseEntity<ChatResponse> fallback(
String prompt,
String model,
Throwable e,
HttpServletRequest request) {
log.error("触发降级: model={}, error={}", model, e.getMessage());
return ResponseEntity.status(503).body(ChatResponse.builder()
.code(503)
.message("服务暂时不可用,请稍后再试")
.build());
}
}
/**
* 请求/响应对象
*/
@Data
public class ChatRequest {
private List<MessageDTO> messages;
private String model = "chatgpt";
@Data
public static class MessageDTO {
private String role;
private String content;
}
}
@Data
@Builder
public class ChatResponse {
private int code;
private String message;
private ChatData data;
@Data
@Builder
public static class ChatData {
private String answer;
private String model;
private long latency;
}
}
@Data
@Builder
public class BatchChatRequest {
private List<BatchItem> items;
private String model = "chatgpt";
@Data
@Builder
public static class BatchItem {
private String id;
private String prompt;
}
}
@Data
@Builder
public class BatchChatResponse {
private int code;
private String message;
private List<BatchResult> data;
@Data
@Builder
public static class BatchResult {
private String id;
private String answer;
private boolean success;
private String error;
}
}
9.3 Sentinel Dashboard配置
完成代码实现后,还需要通过Sentinel Dashboard进行运行时规则配置和监控。
9.3.1 流量控制规则配置
登录Sentinel Dashboard后,按照以下步骤配置流量控制规则:
- 导航到"流控规则"页面
- 点击"新增流控规则"
- 配置以下参数:
- 资源名:填写@SentinelResource中定义的值,如llm:chat:gpt-4
- 来源:默认default
- 阈值类型:选择QPS或并发线程数
- 单机阈值:根据预估负载设置,如100
- 流控模式:选择直接
- 流控效果:选择直接拒绝或冷启动
9.3.2 熔断降级规则配置
- 导航到"降级规则"页面
- 点击"新增降级规则"
- 配置以下参数:
- 资源名:填写需要熔断的资源名
- 熔断策略:选择RT(平均响应时间)、比例异常或异常数
- 熔断阈值:根据大模型API特性设置,如30000(30秒)
- 熔断时长:如60秒
- **最小请求数:如5`
- 慢调用比例:如0.7(70%)
9.3.3 热点参数规则配置
对于需要根据输入长度进行差异化限流的场景:
- 导航到"热点规则"页面
- 点击"新增热点规则"
- 配置参数索引和例外项:
- 资源名:llm:chat
- 参数索引:0(第一个参数prompt)
- 参数类型:String
- 单机阈值:50
- 例外项配置:
- 值:short(短输入),阈值:100
- 值:long(长输入),阈值:10
9.3.4 系统规则配置
- 导航到"系统规则"页面
- 点击"新增系统规则"
- 配置系统级保护阈值:
- 最高系统负载:8.0
- 最大并发线程数:100
- 最高QPS:1000
- 平均响应时间:30000(毫秒)
9.4 监控与告警配置
9.4.1 实时监控
Sentinel Dashboard提供了丰富的实时监控能力:
- 簇点链路:查看所有被Sentinel保护的资源及其调用关系
- 实时监控:查看各资源的QPS、响应时间、通过率等指标的实时数据
- 机器列表:查看所有接入Dashboard的应用实例
9.4.2 告警配置
Sentinel支持通过以下方式进行告警:
- 控制台告警:当触发限流或降级时,Dashboard会显示告警信息
- 日志告警:Sentinel支持配置告警日志输出到指定文件
<!-- 告警日志配置 -->
<appender name="SENTINEL_ALERT" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>./logs/sentinel/sentinel-alert.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>./logs/sentinel/sentinel-alert.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss} %-5level %msg%n</pattern>
</encoder>
</appender>
<logger name="com.alibaba.csp.sentinel" level="INFO" additivity="true">
<appender-ref ref="SENTINEL_ALERT"/>
</logger>
- 自定义告警:通过Sentinel的Handler接口实现自定义告警逻辑
@Component
public class SentinelAlertHandler extends SentinelHandler<Staticts> {
@Override
public void handle(Staticts staticts) {
// 判断是否触发告警条件
if (shouldAlert(staticts)) {
sendAlert(staticts);
}
}
private boolean shouldAlert(Staticts staticts) {
// 例如:连续5秒QPS超过100
return staticts.getQps() > 100 &&
staticts.getBlockQps() > 0;
}
private void sendAlert(Staticts staticts) {
// 发送告警通知(钉钉/飞书/邮件等)
alertService.send(
AlertChannel.DINGTALK,
String.format("Sentinel告警:资源 %s 触发限流", staticts.getResource())
);
}
}
第十章:Sentinel Dashboard配置详解
10.1 Dashboard安装与启动
Sentinel Dashboard是一个独立的Web应用,提供了可视化的规则配置和监控界面。
10.1.1 下载与启动
# 下载最新版本的Sentinel Dashboard
wget https://github.com/alibaba/Sentinel/releases/download/1.8.6/sentinel-dashboard-1.8.6.jar
# 启动Dashboard(默认端口8080)
java -jar sentinel-dashboard-1.8.6.jar
# 自定义端口启动
java -Dserver.port=9000 -jar sentinel-dashboard-1.8.6.jar
# 启动时指定认证(生产环境建议启用)
java -Dserver.port=9000 \
-Dcsp.sentinel.dashboard.auth.username=admin \
-Dcsp.sentinel.dashboard.auth.password=admin123 \
-jar sentinel-dashboard-1.8.6.jar
10.1.2 客户端接入
应用需要添加Sentinel客户端依赖,并配置Dashboard地址:
csp:
sentinel:
dashboard:
addr: 127.0.0.1:9000 # Dashboard地址
# 心跳发送间隔(默认10秒)
heartbeat:
interval: 10000
# 日志文件路径
log:
dir: ./logs/sentinel
10.2 Dashboard核心功能
10.2.1 簇点链路
簇点链路页面展示了所有被Sentinel保护的资源,以及资源之间的调用关系。通过这个页面,可以:
- 查看当前应用的所有受保护资源
- 了解资源的调用来源和调用目标
- 快速定位高流量资源
- 一键跳转配置流控或降级规则
10.2.2 流控规则
流控规则页面支持以下操作:
- 查看规则:列出所有已配置的行车控制规则
- 新增规则:添加新的流控规则
- 修改规则:编辑现有规则
- 删除规则:移除不再需要的规则
- 查询规则:根据资源名查询特定规则
流控规则支持批量导入导出(JSON格式),便于规则的备份和迁移。
10.2.3 降级规则
降级规则页面提供熔断降级规则的配置和管理:
- 支持RT熔断、异常比例熔断、异常数熔断三种策略
- 可视化展示熔断器的当前状态
- 查看熔断触发的历史记录
10.2.4 热点规则
热点规则页面用于配置热点参数限流:
- 支持配置参数索引和参数类型
- 支持配置参数例外项
- 支持按参数值设置不同的限流阈值
10.2.5 系统规则
系统规则页面提供系统级自适应限流配置:
- 系统负载阈值配置
- 最高QPS配置
- 平均响应时间阈值配置
- 并发线程数阈值配置
10.2.6 机器列表
机器列表页面展示所有接入Dashboard的应用实例:
- 查看实例的健康状态
- 查看实例的版本信息
- 查看实例的实时指标
- 支持手动下线异常实例
10.3 规则推送与同步
10.3.1 动态规则推送
Sentinel Dashboard支持将规则动态推送到应用实例。当在Dashboard上修改规则后,规则会立即生效,无需重启应用。
动态推送支持两种机制:
- HTTP推送:Dashboard通过HTTP请求将规则推送给应用实例
- 配置中心推送:通过Nacos、Apollo等配置中心实现规则推送
10.3.2 规则同步策略
对于使用Nacos等配置中心的场景,Sentinel支持将Dashboard上配置的规则同步到配置中心:
# Nacos规则同步配置
csp:
sentinel:
dashboard:
config:
server-addr: 127.0.0.1:8848
# 规则同步到Nacos
rule:
nacos:
server-addr: 127.0.0.1:8848
namespace: public
group: sentinel-rules
data-id-prefix: ${spring.application.name}
总结
本文深入探讨了如何运用Sentinel构建大模型接口的高可用防护体系。我们从大模型接口面临的高可用挑战出发,详细分析了响应延迟不确定性、Token消耗难以预估、API限流严格约束以及服务可用性隐忧等核心问题。
在此基础上,我们深入剖析了Sentinel的核心概念,包括资源、规则、插槽链和链路降级等关键要素。熔断器模式的深度解析帮助读者理解了关闭→打开→半开的状态转换机制,以及Sentinel如何通过滑动窗口实现精确的熔断判断。
限流算法的对比分析让我们清楚令牌桶、漏桶和滑动窗口三种算法各自的优缺点和适用场景,为实际应用中的算法选型提供了指导。
Spring Boot集成Sentinel的详细讲解,包括依赖配置、注解使用、规则加载和过滤器集成,为读者提供了完整的集成方案。热点参数限流和系统自适应限流的介绍,进一步丰富了流量控制的手段。
降级策略设计章节给出了多种实用的降级方案——缓存降级、默认值降级、快速失败降级以及多级降级组合,为读者提供了完整的降级策略设计思路。规则持久化章节则解决了生产环境中规则管理的难题。
最后一章的实战部分,通过保护ChatGPT和DashScope接口的完整配置示例,将前述所有知识点串联起来,形成了完整的解决方案闭环。
通过本文的学习,读者应该能够:
- 理解大模型接口面临的高可用挑战及其防护策略
- 掌握Sentinel的核心概念和工作原理
- 熟练使用Sentinel实现流量控制、熔断降级和系统自适应
- 设计合理的降级策略和规则持久化方案
- 在生产环境中部署和维护Sentinel防护体系
大模型接口的高可用防护是一个持续演进的过程,需要根据业务特点和技术发展不断调整优化。希望本文能为读者的实践提供有价值的参考。
────────────────────────────────────────────────────────────
参考资源:
- [Sentinel官方文档](https://sentinelguard.io/zh-cn/docs/introduction.html)
- [Sentinel GitHub仓库](https://github.com/alibaba/Sentinel)
- [熔断器模式详解](https://martinfowler.com/bliki/CircuitBreaker.html)
- [令牌桶算法原理](https://en.wikipedia.org/wiki/Token_bucket)
附:配套技术图解
Sentinel熔断降级架构图
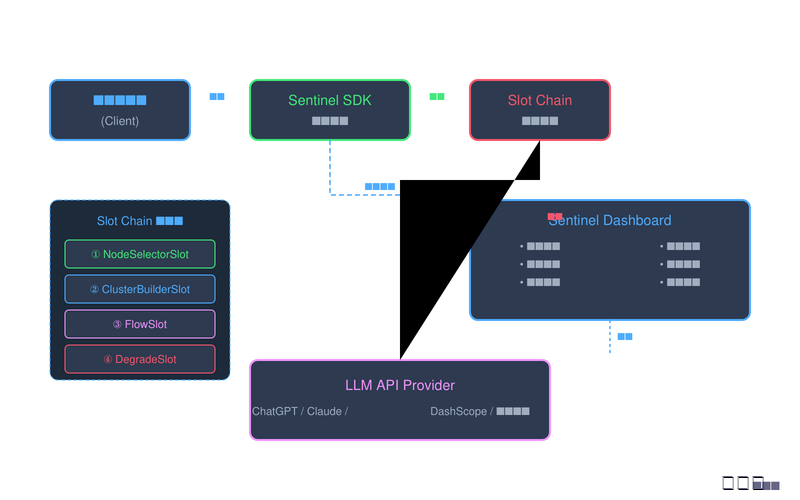
图1:Sentinel熔断降级架构图
熔断器工作状态图
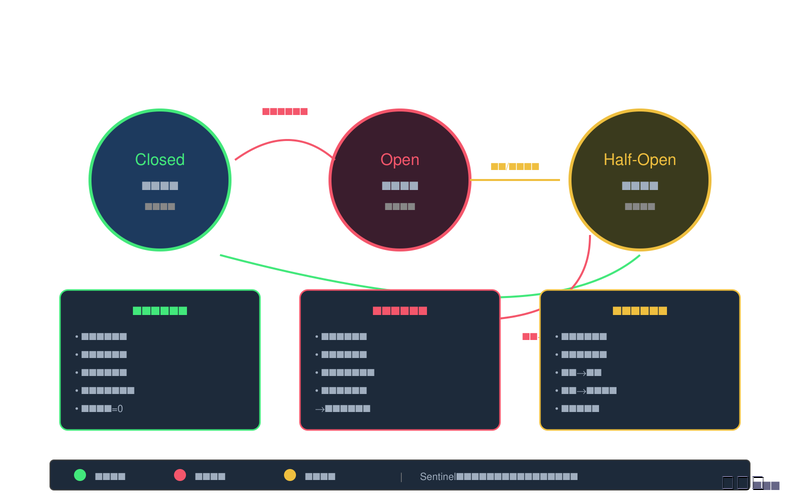
图2:熔断器工作状态图
限流算法对比图
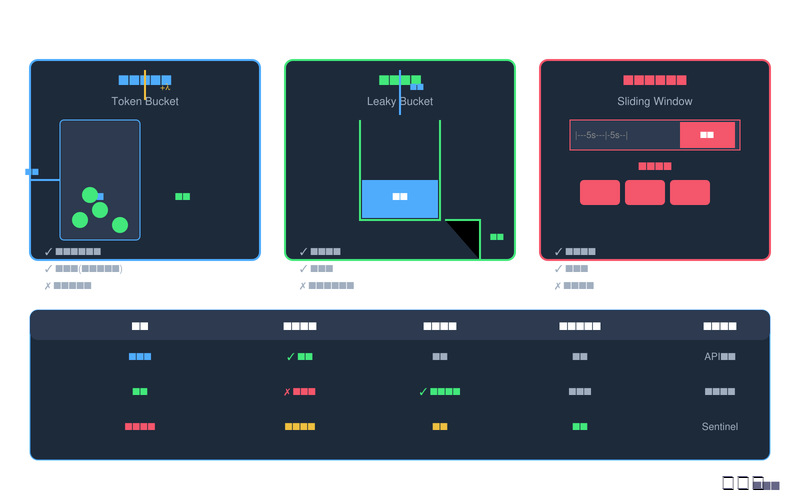
图3:限流算法对比图(令牌桶/漏桶/滑动窗口)
Spring Boot集成Sentinel原理图
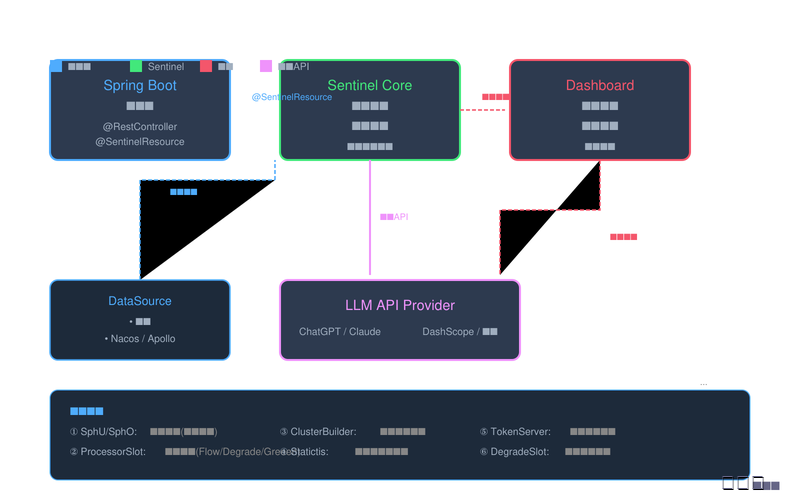
图4:Spring Boot集成Sentinel原理图

AtomGit AI 社区提供模型库、数据集、Agent、Token等资源
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)