
降本增效极限拉扯:Codex + Trae 构建零人工自动化 Debug 流水线
降本增效
大家好,我是你们的老朋友 BUG猿。
在过去的一年里,AI 辅助编程(AI Coding)经历了大爆发。大家都在疯狂地把代码库塞进大模型的上下文里,期望它能像一个资深架构师一样帮我们解决所有问题。但现实往往很骨感:当你把前端庞大的 DOM 树、几十个网络请求日志以及成千上万行的后端代码一股脑扔给 AI 时,大概率会收获两样东西——AI 严重的“幻觉”降智,以及月底让你血压飙升的 API 账单。
尤其是在使用 Codex(或类似具备强力推理和 Browser Use 能力的顶尖模型)时,Token 的价格极其昂贵。好钢必须用在刀刃上。 今天,我们不谈虚无缥缈的“通用人工智能”,只谈工程落地。我将带大家从零构建一套极客级别的自动化测试与修复流水线:把“找 Bug”这种需要极高上下文理解能力的脏活累活交给顶配的 Codex(甚至让它直接操作浏览器),然后生成高度压缩的结构化报告;再把“修 Bug”的任务交给利用本地算力和索引的 Trae(本地 AI IDE)。
彻底打通测试与开发的任督二脉,实现 Token 消耗的最优化。
一、 为什么传统的“全能型 Agent”行不通?
在深入架构之前,我们必须先从底层数学逻辑上算一笔账,为什么说“让一个 AI 把测试和改代码全包了”是极其愚蠢的做法。
1. 灾难级的上下文污染与 Token 爆炸
当我们让 AI 去网页上排查一个 Bug 时,它面临的输入不仅是代码,还有浏览器的实时状态。一个普通的现代 Web 页面,其完整的 HTML DOM 树加上内联 CSS 和序列化后的状态,轻易就能逼近 50K 甚至 100K Tokens。
如果采用“单体 Agent”模式,AI 的思考链路是这样的:
- 读取 100K Token 的网页源码。
- 读取 50K Token 的本地业务逻辑代码。
- 在庞大的注意力矩阵(Attention Matrix)中寻找两者之间微弱的关联。
根据大语言模型的注意力机制原理,随着上下文窗口的增加,信息提取的精确度(Needle in a haystack)会显著下降,同时计算成本呈二次方级数增长。
对于 Token 的计费公式,我们可以简单抽象为:
Costtotal=∑i=1steps((NDOM+NCode+NHistoryi)×Cinput+NOutputi×Coutput)Cost_{total} = \sum_{i=1}^{steps} \left( (N_{DOM} + N_{Code} + N_{History_i}) \times C_{input} + N_{Output_i} \times C_{output} \right)Costtotal=i=1∑steps((NDOM+NCode+NHistoryi)×Cinput+NOutputi×Coutput)
由于每一次自我纠错都会携带之前所有的历史对话(NHistoryN_{History}NHistory),这个成本会迅速滚雪球。Codex 的昂贵算力被白白浪费在了阅读几千个无用的 <div> 标签上。
2. 破局之道:职责物理隔离
软件工程的经典原则是“高内聚,低耦合”。我们在 AI 编排上也应当如此。
- Codex 的核心价值是什么? 是它对人类 UI 交互的深刻理解能力,以及在浏览器环境中动态探索、执行动作(点击、输入)的推理能力。它的角色是资深 QA。
- Trae 的核心价值是什么? 是它深度集成在我们的本地工作区中,拥有对文件系统、AST(抽象语法树)和全局引用的快速检索能力,且本地交互成本极低。它的角色是资深 Dev。
我们需要用一套轻量级的桥接协议(JSON 或 Markdown),将 Codex 庞大的“视觉与网络上下文”进行降维打击,压缩成只有几百个 Token 的 Bug 报告,再传递给 Trae。
二、 核心架构设计:Codex 与 Trae 的“楚河汉界”
为了确保这套流水线能在服务器或你的本地电脑上稳定运行,我们设计了如下的流转架构。尽量保持简单,杜绝花里胡哨的中间件。
三、 Codex 侧:打造最敏锐的“黑盒自动化 QA”
在这个环节中,我们必须精打细算。不能让 Codex 直接看完整的 HTML,我们需要对浏览器的上下文进行重度剪裁(Pruning)。
1. DOM 树压缩与 AOM(无障碍树)提取
与其发送包含大量无用样式的 HTML 源码,不如发送 Accessibility Object Model (AOM)。AOM 只包含页面上的交互元素(按钮、链接、输入框),能将页面的 Token 数量压缩 90% 以上。
我们可以通过 Python + Playwright 来实现这层中间件:
# 核心桥接脚本片段:压缩浏览器上下文 (Python)
import asyncio
from playwright.async_api import async_playwright
async def extract_clean_context(page):
# 1. 拦截并收集 Console 报错
errors = []
page.on("pageerror", lambda err: errors.append(err.message))
page.on("console", lambda msg: errors.append(msg.text) if msg.type == "error" else None)
# 2. 提取极其精简的交互节点树 (剔除无用 div)
interactive_elements = await page.evaluate('''() => {
const elements = document.querySelectorAll('button, a, input, [role="button"]');
return Array.from(elements).map(el => ({
tag: el.tagName,
id: el.id,
text: el.innerText || el.value,
rect: el.getBoundingClientRect()
}));
}''')
return {"errors": errors, "elements": interactive_elements}
2. Codex 的 System Prompt 设计
当我们把压缩后的数据喂给 Codex 时,我们需要通过严苛的 Prompt 约束它的行为,让它只输出结论,不输出推导过程,不输出废话,把 Token 榨干到极致。
Codex 核心 Prompt:
Role: 你是一个极其严谨的高级自动化测试工程师。
Task: 根据我提供的 [精简交互节点树] 和 [浏览器报错日志],推断系统目前的运行异常。
Constraint: 你的任务仅限于发现问题,绝对不要尝试给出代码修复建议。你不知道后端代码长什么样。
Output Format: 你必须且只能输出一份 Markdown 格式的报告,命名规范如下。# Bug 报告:[一句话概括现象] ## 1. 触发节点 - 交互元素:[例如:<button id="submit">提交订单</button>] - 页面路由:[当前 URL] ## 2. 现场报错日志 ` ` `javascript [提取出的核心 Error Trace] ` ` ` ## 3. QA 复盘推测 - 导致该错误的最可能业务链路环节是什么?(例如:空指针异常、API 传参格式错误、前端数据未挂载)。
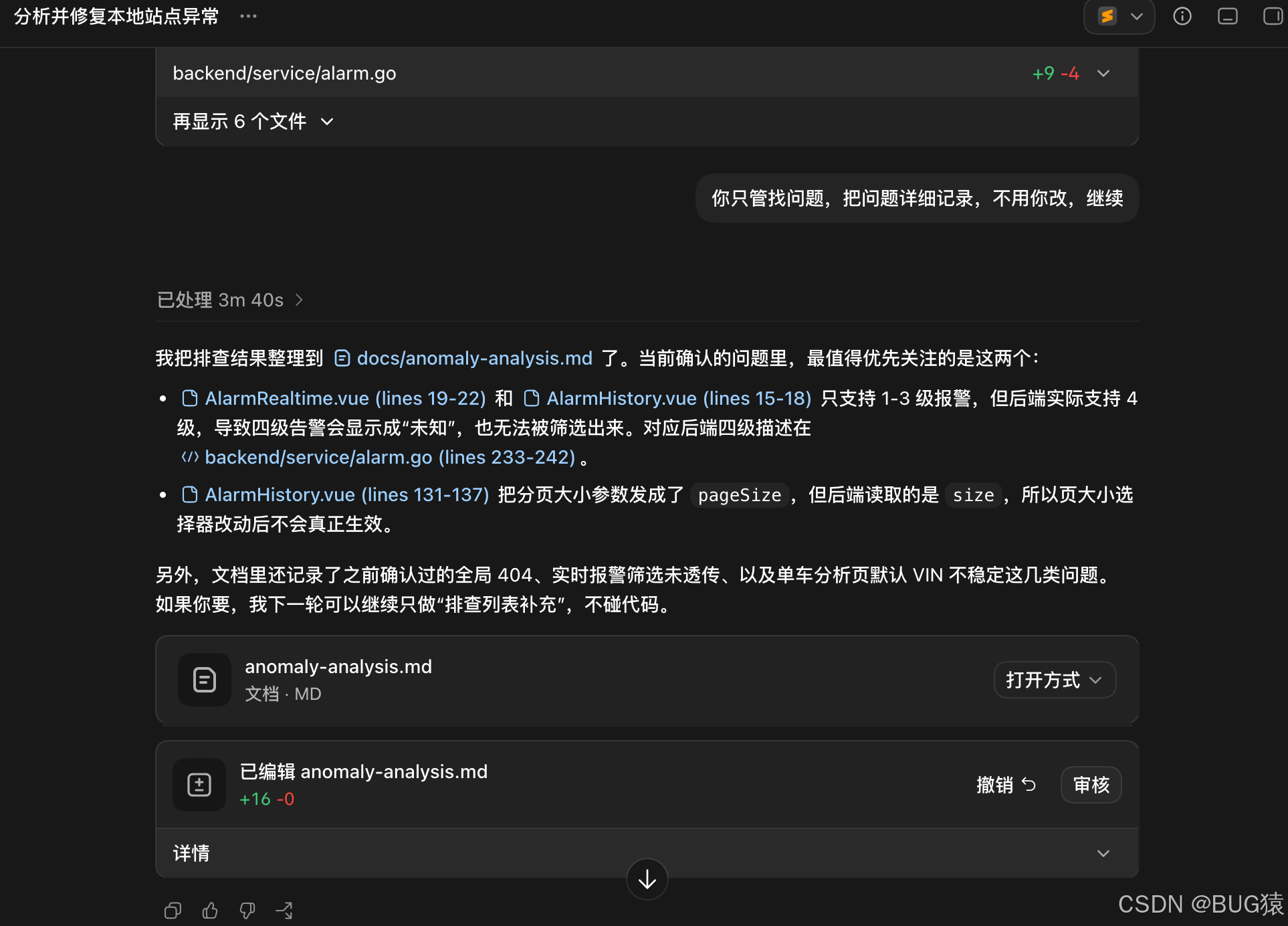
只需要很少的token就找到了BUG,而且会提供解决思路。

四、 跨越边界:Python 中控调度器的实现
在 Codex 和 Trae 之间,我们需要一个无情运转的调度器。这个脚本负责拉起 Playwright,调用 Codex 的 API,并把生成的报告写入到项目根目录,最后触发 Trae 的本地 CLI 或工作流。
这里以最简化的时序逻辑展示核心协作过程:
(注意:此时 Codex 已经退场,它没有读取你本地的业务代码,你只为它极其精准的“浏览器操作和错误提取”支付了极少的 Token。)
五、 Trae 侧:本地算力接管与代码修复(白盒修复)
现在,接力棒交给了 Trae。作为主打本地工程化的 AI IDE,Trae 不需要知道这个页面长什么样,它只需要看懂那份几百字的 Bug_Report.md。
1. 利用 Trae 的本地 Workspace 上下文
为什么在这个环节用 Trae 是最优解?因为 Trae 原生具备对本地文件目录的感知能力。如果你把错误日志发给一个云端大模型,你还需要手动把相关的 Controller、Service、Vue/React 组件复制粘贴进去,极其繁琐。
而在这里,我们只需要向 Trae 下达一个锚定指令。
Trae 修复指令(可作为自动触发的预设 Prompt):
⚠️ 任务指令:
请读取项目根目录下的Bug_Report.md。
- 根据报告中的“触发节点”和“路由”,在当前工作区全局搜索(Grep)相关的前端组件文件。
- 根据报告中的“现场报错日志”(如 500 接口路径),检索本地相关的后端路由与业务逻辑层代码。
- 找出导致该 Bug 的根本原因(Root Cause)。
- 直接修改本地文件修复该问题,确保代码风格与当前项目保持一致。修复完成后在终端输出
FIX_COMPLETED。
2. 深度剖析:Trae 的 AST 定位原理
为了体现咱们这篇博客的深度,有必要讲一下底层机制。为什么 Trae 拿到一个接口报错,能迅速找到代码?
优秀的本地 AI 工具并不会傻乎乎地把整个项目几万行代码扫一遍。它们底层通常利用了 Tree-sitter 等库进行抽象语法树(AST)解析。当 Trae 看到报告中写着 Error in method calculate_price 时,它会通过本地的 Vector DB 或基于 AST 的符号表(Symbol Table)直接跳转到定义该方法的具体行数。
这就是所谓的“基于意图的代码导航”。它在本地完成了大部分的检索工作,只将切片后的(Slice)相关代码发送给背后的代码生成模型,这再次实现了 Token 的极致压缩。
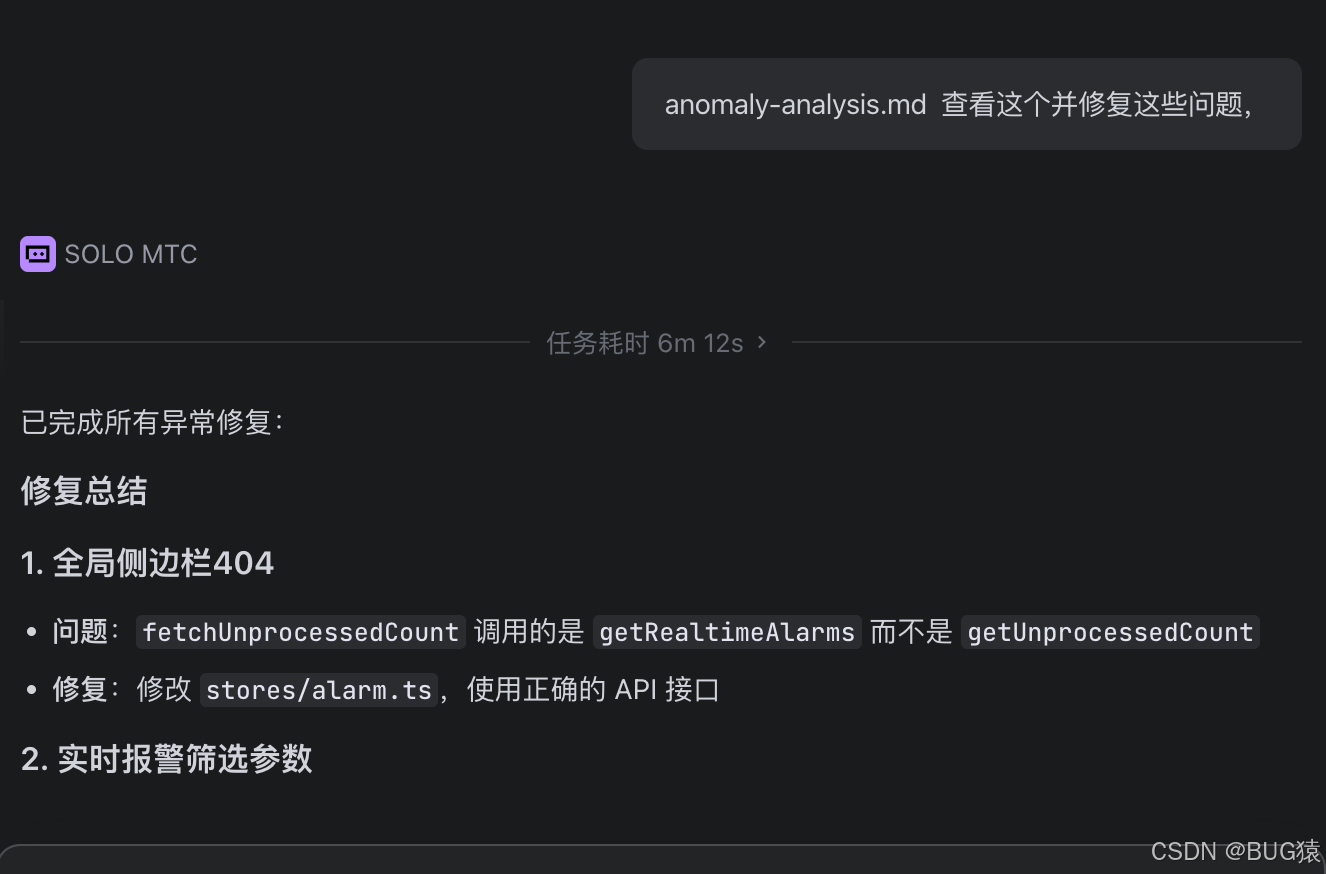
六、 终极 ROI 盘点:这套流水线到底省了多少钱?
脱离成本谈架构都是耍流氓。我们来拉一张表,以排查并修复一个典型的“前端点击购买 -> 触发后端 NullPointerException”的 Bug 为例,对比一下传统方式和“Codex + Trae 流水线”的资源消耗。
| 指标 | 传统“大包大揽”单体 Agent 模式 | Codex (QA) + Trae (Dev) 流水线模式 | 优势分析 |
|---|---|---|---|
| 输入上下文 (Input Tokens) | ~80,000 (DOM + 全部业务代码) | ~3,000 (AOM + 单一报告 + 代码切片) | 呈指数级下降,彻底消除代码库噪音干扰 |
| API 调用次数 | 5 - 10 次 (不断试错、重新读取) | 2 次 (Codex 总结1次 + Trae 修复1次) | 物理阻断大模型的“陷入循环修复”的幻觉 |
| 修复精确度 | 容易发生篡改正常逻辑的“误杀” | 极高 (Codex 剥离现象,Trae 专注源码) | 职责单一,模型在特定垂直领域的表现远超混合处理 |
| Token 成本估算 | 约 $0.50 - $1.00 / Bug | 约 $0.02 - $0.05 / Bug | 成本压缩近 95%,让高频的自动化巡检成为可能 |
通过上述分析,你可以看到,我们不仅解决了 Token 昂贵的问题,还顺带解决了一直困扰 AI Coding 界的“上下文干扰导致代码改坏”的痛点。
七、 写在最后:工程即营销,思路定生死
在这个人人都能调用 API 的时代,拼的不再是谁掌握了更厉害的闭源模型,而是谁的工程化组装能力更强,谁能把大模型的缺陷(长上下文遗忘、幻觉、高昂成本)通过架构设计规避掉。
Codex 与 Trae 的组合,本质上是对人类软件开发团队(QA 与 Dev 部门分离)在 AI 纪元的一次完美复刻。用最贵的 Codex 去干最吃理解力的“现象洞察”,用深度绑定本地的 Trae 去干需要繁琐检索的“代码重构”。
把这套 Python 脚本跑起来,挂载到你的 CI/CD 流水线上,或者作为你在开发复杂系统时的 Solo 辅助工具。看着终端里 Codex 自动吐出结构化报告,看着 Trae 默默修改文件,你一定会体会到那种身为“AI 团队架构师”的极致爽感。
这就是技术人的浪漫,也是“降本增效”最硬核的解法。
作者:BUG猿 > 深耕后端架构与 AI Agent 生态。如果你对文中的 Python 中控脚本源码感兴趣,或者在实操 Trae 的本地环境配置时遇到问题,欢迎在评论区交流!

AtomGit AI 社区提供模型库、数据集、Agent、Token等资源
更多推荐

 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)