
【小白吃透AI】大语言模型LLM超详细原理全集|通俗图解+训练流程+推理机制+优缺点+面试大全
📚 专栏:大模型入门到实战
💡 适用人群:编程小白、后端开发者、AI入门、面试刷题、想搞懂ChatGPT/DeepSeek原理的同学
🔥 博客特色:无数学公式、全大白话、全程流程图拆解、层层递进、从0基础认知 → 核心原理 → 训练机制 → 逐字推理 → 优缺点本质 → 工程落地全覆盖,看完彻底告别“只会用不会懂”!
✅ 阅读收获
-
彻底搞懂:LLM到底是什么,和传统程序有什么本质区别
-
吃透核心:Transformer、注意力机制、词嵌入、上下文窗口
-
理解全过程:预训练、微调、SFT、RLHF、推理生成
-
认清短板:幻觉、上下文丢失、知识截止时间的底层原因
-
掌握面试:覆盖90% LLM入门高频面试题
一、前言:为什么你必须搞懂LLM?
现在的 AI 对话、代码生成、智能问答、文案创作、知识库机器人、AI 自动化开发,底层全部依赖 LLM 大语言模型。
很多开发者小白长期处于「只会调用接口,完全不懂原理」的状态:
-
不知道 AI 为什么能看懂上下文
-
不知道 AI 为什么会一本正经胡说八道(幻觉)
-
不知道 AI 回答为什么是逐字吐出来的
-
分不清传统代码和大模型 AI 的本质区别
本文从零深度拆解,所有原理全部通俗化+逻辑图可视化,看完建立完整 LLM 知识体系。
二、什么是 LLM?(深度通俗定义)
2.1 官方定义
LLM(Large Language Model,大语言模型):是一种基于海量文本数据训练、超大规模神经网络参数、以 Transformer 为核心架构,具备自然语言理解、自然语言生成、逻辑推理、上下文对话能力的生成式人工智能模型。
2.2 小白终极通俗理解
传统程序:人写死规则,机器严格执行。
LLM 大模型:人喂海量数据,机器自己学习语言规律、知识、逻辑,最后学会“自主生成答案”。
2.3 LLM 和传统代码的本质区别(重点)
|
对比维度 |
传统程序(Java/Go/Python) |
LLM 大语言模型 |
|---|---|---|
|
工作逻辑 |
人工写死 if/else、逻辑、规则 |
从海量数据中自学规律,无硬编码规则 |
|
输出结果 |
固定、精准、无偏差 |
概率生成、灵活、但是可能出错 |
|
泛化能力 |
只能处理写好的场景 |
可以处理从未见过的新问题 |
|
智能程度 |
无智能,只是逻辑计算器 |
具备语义理解、联想、推理、创作能力 |
2.4 LLM 核心四大能力
-
NLU 自然语言理解:读懂人类意图、语义、情绪、上下文、歧义句
-
NLG 自然语言生成:自动生成通顺、连贯、符合逻辑的文本/代码
-
上下文记忆:多轮对话中关联前文,实现连贯聊天
-
通用推理:数学计算、逻辑分析、方案设计、排错、总结归纳
三、LLM 底层核心架构:Transformer 超详细拆解
所有现代 LLM(GPT、LLaMA、Qwen、DeepSeek、文心一言)全部基于 Transformer,没有 Transformer 就没有大模型。
3.1 Transformer 整体架构图
动态逻辑结构图(CSDN自动渲染)
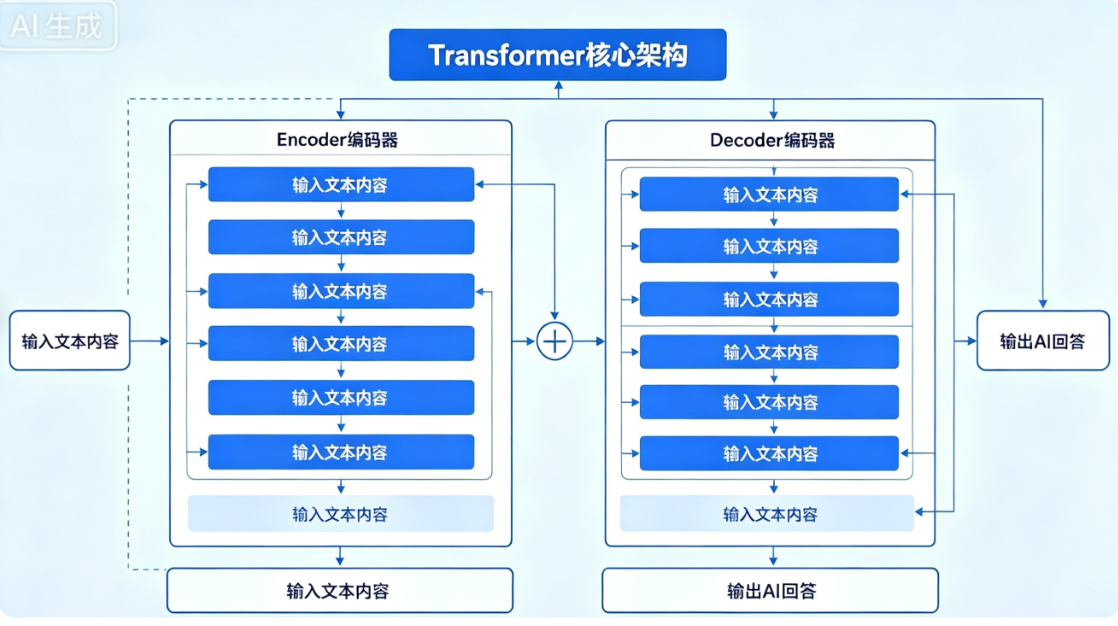
图解白话解读:编码器负责「看懂问题、理解语义」,解码器负责「组织语言、生成答案」,两者配合完成LLM完整交互流程,当前主流LLM仅保留Decoder模块专注生成任务。
3.2 两大架构流派(面试高频)
-
Encoder+Decoder 架构:适合翻译、分类、文本匹配(如 T5)
-
纯 Decoder 架构:当前 LLM 主流!GPT、LLaMA、通义千问全部使用,专注文本生成、对话、推理,性能最优
3.3 核心灵魂:自注意力机制 Self-Attention(通俗深度讲解)
小白最难懂、但最重要的核心:注意力机制 = AI 的阅读理解能力。
人类读句子会自动关联前后文,AI 靠 Self-Attention 实现同样效果。
举个例子秒懂
句子:“小李摔坏了小王的电脑,他非常自责。”
人类一眼看懂:他 = 小李,不是小王。
注意力机制的工作:
-
自动计算每个字和其他字的关联权重
-
强化「他」和「小李」的关联
-
弱化无关字词干扰
注意力机制逻辑流程图
自注意力机制动态流程图
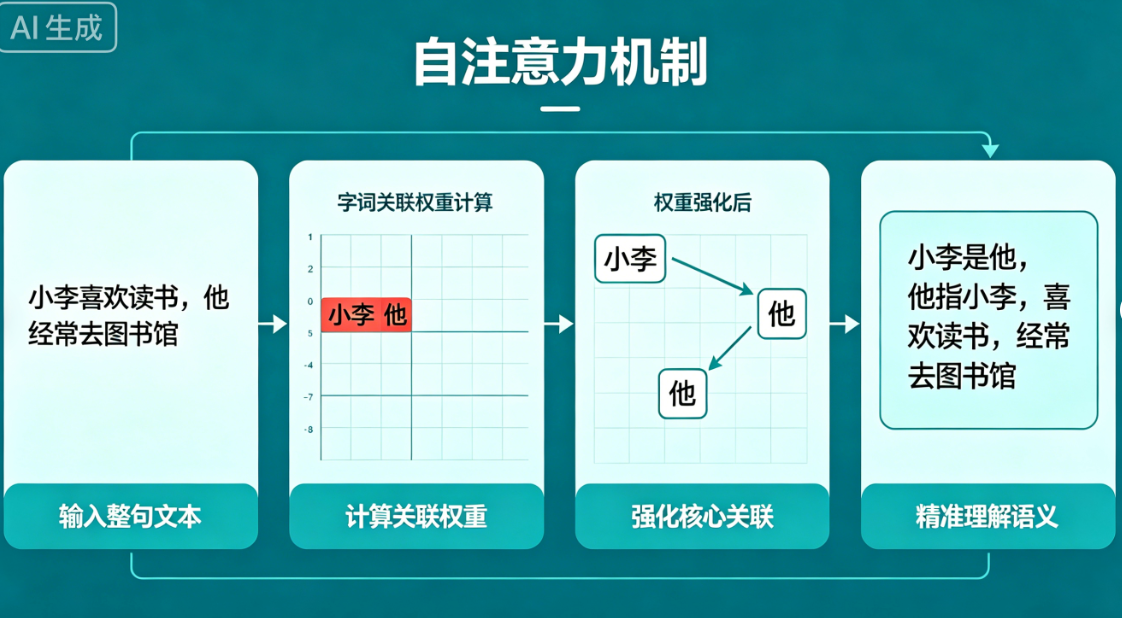
动态图解解读:AI会给句子中所有字词做关联打分,像人类阅读一样自动绑定指代关系、逻辑关系,重点聚焦核心语义,忽略无效干扰,这是AI能读懂长文本、复杂语句的核心关键。
为什么这是大模型的核心?
没有注意力机制,AI 只能一个字一个字孤立看,完全不懂上下文、不懂指代、不懂逻辑,和早期弱智机器人无区别。
3.4 多头注意力 Multi-Head Attention(进阶理解)
单头注意力:只能捕捉一种关联(比如主谓关系)
多头注意力:同时捕捉语法、语义、指代、逻辑、位置、情感等多重关系,让模型理解更全面。
四、LLM 必须掌握的核心前置概念(小白必懂)
4.1 Token 分词机制(一切的基础)
电脑不认识汉字、英文,LLM 不会直接读取文字,所有输入必须先变成 Token。
Token 通俗理解:AI 的最小阅读单位,可以是一个字、一个词、一个字母、一个标点。
示例:你好,大模型 → 被拆分为多个 Token 编号
4.2 词嵌入 Embedding
分词之后,文字会被转化为高维数字向量。
核心规则:语义越相似的内容,向量距离越近
-
“猫”和“猫咪”向量几乎重合
-
“猫”和“桌子”向量距离很远
这就是 AI 能理解语义、能联想、能类比的根本原因。
4.3 上下文窗口 Context Window
LLM 能记住的最大对话长度。
常见:4K、8K、32K、128K 上下文窗口
通俗理解:AI 的短期记忆内存,超过长度的内容会被遗忘,这就是长对话 AI 会失忆的底层原因。
五、LLM 完整生命周期:从空白模型到可用 AI(超详细)
很多小白不知道:我们用的大模型,需要经过 4 个阶段训练才能成型。
5.1 第一阶段:预训练 Pre-Train(筑基)
数据:全网海量文本、书籍、论文、代码、百科、网页
任务:持续学习「根据上文预测下一个字」
目标:学会语言语法、海量知识、基础逻辑、常识
结果:此时模型只会续写文本,不会对话、不懂人类指令
5.2 第二阶段:有监督微调 SFT(学会听话)
用大量「人类指令 + 标准回答」数据微调。
让模型学会:人类下达指令 → 输出对应答案
此时模型具备正常对话、问答、任务处理能力。
5.3 第三阶段:奖励模型训练 RM(学会好坏)
让模型学习区分:什么回答优质、什么回答垃圾、什么回答有害。
5.4 第四阶段:RLHF 人类反馈强化学习(变聪明、对齐人类)
基于人类打分反馈,强化优质回答、抑制劣质回答、杜绝违规内容。
最终效果:回答更通顺、更安全、更符合人类价值观、更贴合需求。
完整训练流程图
LLM完整训练生命周期动态流程图
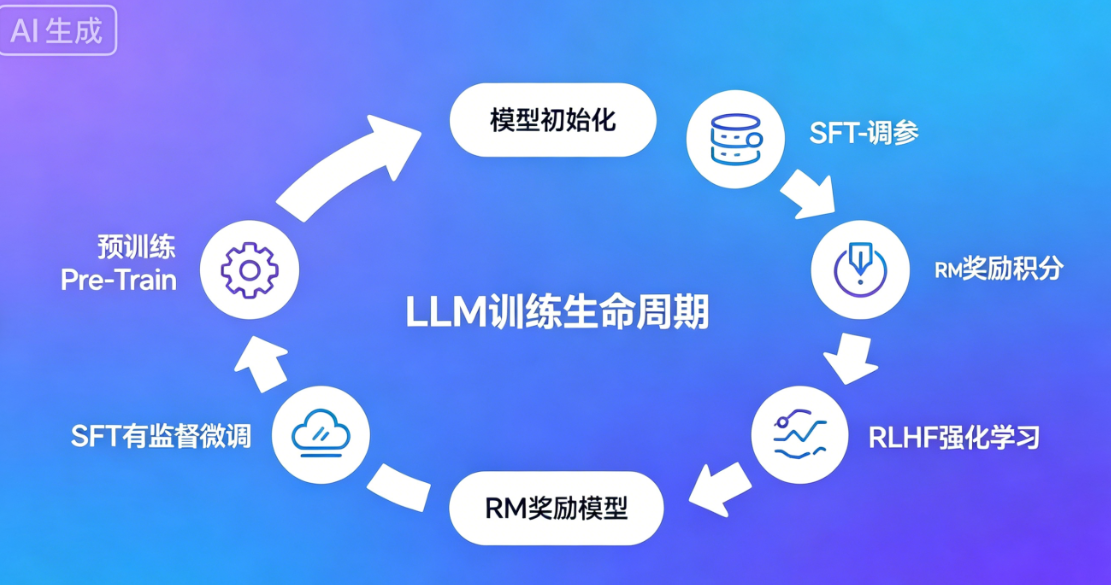
流程通俗解读:从空白模型到商用大模型,循序渐进完成「学知识→学指令→辨好坏→优回答」四个核心阶段,缺一不可,这也是原生预训练模型无法直接对话的原因。
六、LLM 推理全过程:你提问到 AI 回答的完整细节(逐帧拆解)
很多人以为 AI 是一次性写完答案,实际上是逐字概率生成。
6.1 完整推理流程
LLM逐字推理生成全过程动态动图逻辑
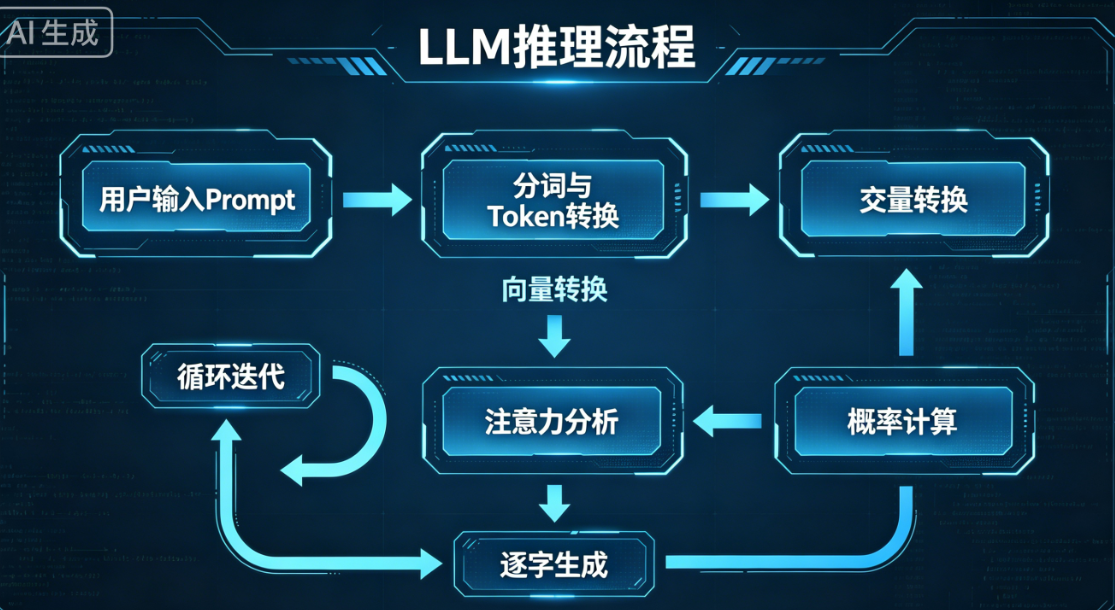
动态核心解读(秒懂逐字卡顿):AI回答是循环迭代生成,每一个字都要重新计算全局上下文和概率,不是提前预存文案,这就是网页端AI逐字跳动输出、有卡顿感的底层原因。
6.2 核心重点:为什么 LLM 会“卡顿逐字输出”?
每一个字,都是一次完整的神经网络计算,不是提前写好的文案!
每输出一个字,都要重新带入全文上下文,重新计算注意力、重新算概率。
七、LLM 核心参数详解(开发者必须懂)
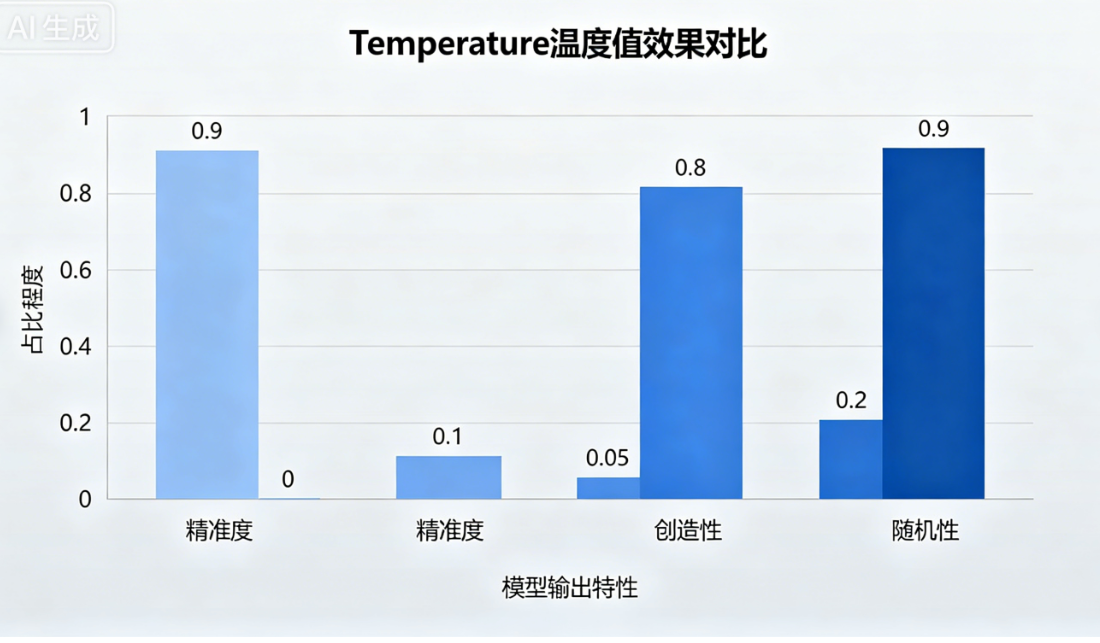
7.1 温度值 Temperature
-
趋近于 0(精准模式):结果固定、精准、严谨、适合代码、解题、知识库问答,无随机发散
-
趋近于 1(创造模式):随机度高、创造性强、适合写文案、写小说、头脑风暴,答案更丰富
温度值效果对比动态示意图
7.2 Top-P / Top-K 采样
控制模型选词范围,避免出现离谱、乱码、不通顺的内容。
7.3 Max Tokens 最大生成长度
限制回答最大字数,防止无限生成、超时、资源占用过高。
八、LLM 四大缺陷底层原理(彻底搞懂幻觉、失忆、时效性)
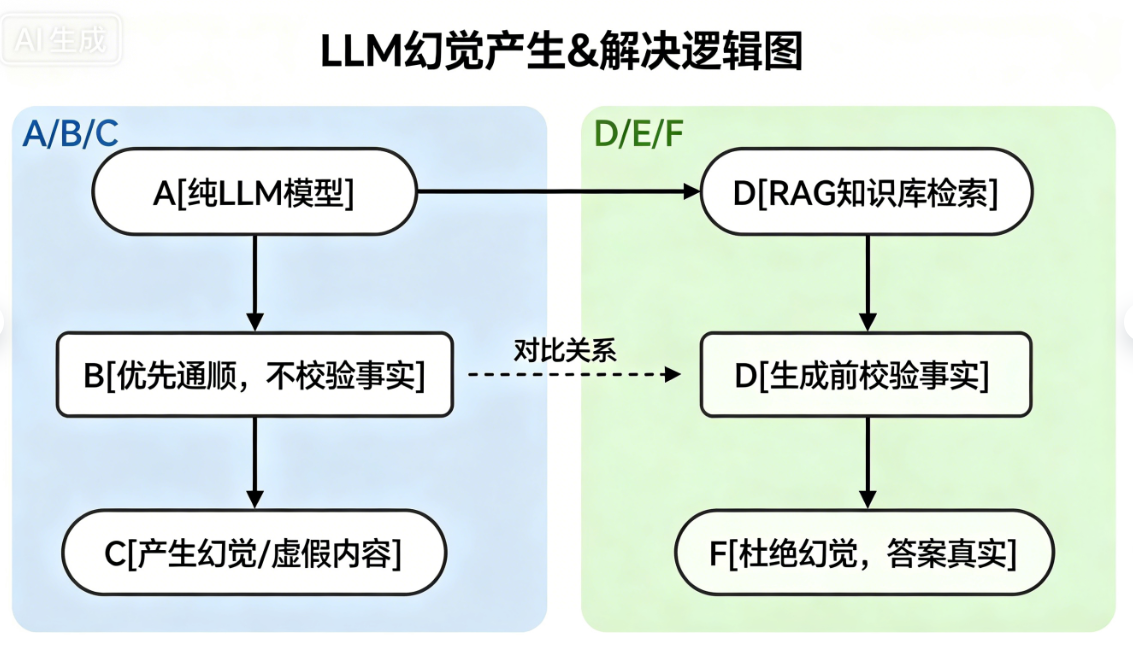
8.1 幻觉问题(最经典)
现象:一本正经编造不存在的论文、数据、案例、接口。
底层原因:LLM 没有记忆数据库、没有检索能力,只会根据概率生成通顺文本,不判断真假。
解决方案:RAG检索增强生成(联网/知识库检索,兜底真实数据)
LLM幻觉产生&解决逻辑图
8.2 知识截止时间
模型只学习训练数据截止前的内容,无法知道最新新闻、新技术、新数据。
8.3 上下文失忆
对话内容超过上下文窗口,早期对话直接被丢弃,导致 AI 忘记前文。
8.4 容易被误导
LLM 只会顺着用户话术生成,不会主动纠错,容易被诱导生成错误内容。
九、LLM 企业级落地场景(开发者实战方向)
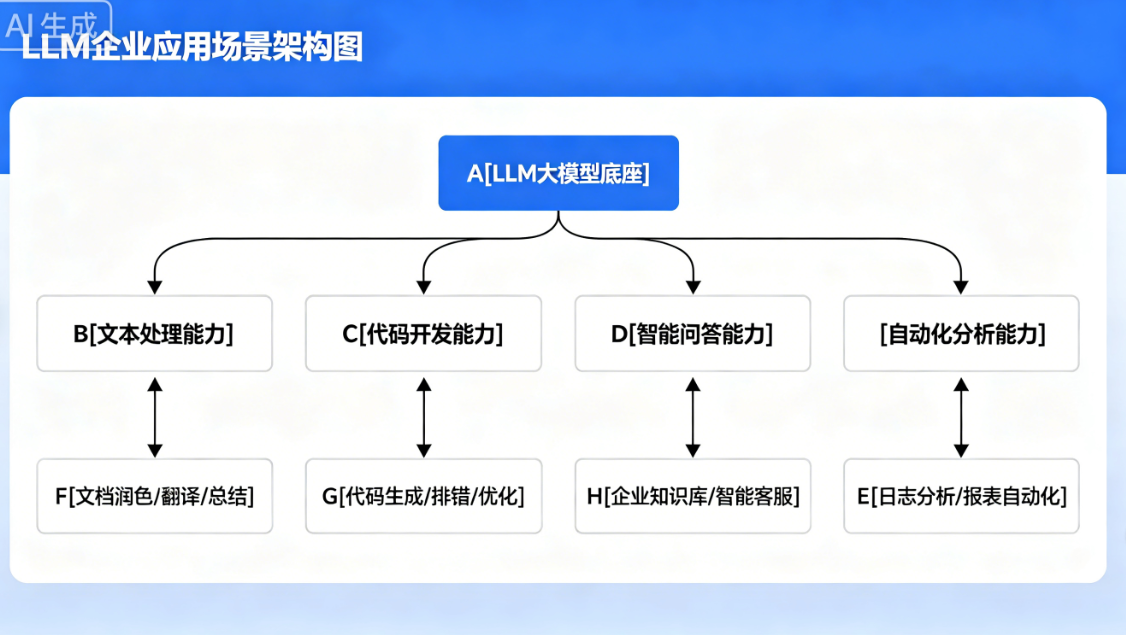
-
智能问答机器人:客服、知识库、企业内部问答
-
AI 代码助手:代码生成、纠错、注释、重构、SQL生成
-
文档智能处理:总结、润色、翻译、改写、提取要点
-
RAG 知识库系统:私有文档问答、企业AI助手
-
智能自动化:需求分析、日志分析、报表生成、自动复盘
-
多模态应用:图文理解、OCR解析、图片内容问答
LLM企业应用场景架构图
十、LLM 高频面试题(2026最新完整版)
面试1:LLM 的核心原理是什么?
大语言模型基于 Transformer 架构与自注意力机制,通过海量文本预训练学习语言规律与知识,通过 SFT、RLHF 对齐人类指令,依靠逐字概率预测实现通用语言生成与推理能力。
面试2:注意力机制的作用?
捕捉文本上下文关联关系,让模型理解长句子语义、指代关系、逻辑关系,是大模型具备阅读理解能力的核心。
面试3:为什么 LLM 会产生幻觉?
LLM 无真实感知、无数据库检索,仅基于统计概率生成通顺文本,优先保证语句通顺,不保证事实真实,因此会编造虚假内容。
面试4:预训练、SFT、RLHF 的区别?
-
预训练:学知识、学语言、学逻辑
-
SFT:学指令,学会听懂人类需求
-
RLHF:优化回答质量、对齐人类偏好、提升安全性
面试5:温度值参数的作用?
控制模型生成随机性与创造性,温度越低越精准稳定,越高越发散创新。
十一、全文终极总结(小白速记)
LLM 的本质就是:以 Transformer 注意力机制为核心,通过海量数据自学语言与知识,依靠概率逐字生成文本,经过多阶段对齐优化,最终具备理解、对话、推理、创作能力的通用人工智能底座。
所有 AI 应用,万变不离其宗!
💖 码字不易,点赞+收藏+关注!

AtomGit AI 社区提供模型库、数据集、Agent、Token等资源
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)