
ChatGPT 风口下, Agent 究竟是什么?别再被这些概念搞混了!
本文厘清了Agent与普通LLM应用的本质区别,指出Agent是围绕目标持续推进任务的系统,具有目标导向、过程管理、状态记录和边界约束等特征。作者强调Agent不是简单的"能调工具的LLM",而是能根据观察结果动态决策、管理中间状态并在必要时与人交互的任务执行系统。文章还区分了workflow、Agent和multi-agent的概念层级,建议开发者应先明确任务契约和责任边界,再考虑技术实现。这种
本文深入探讨了 Agent 的概念及其与普通 LLM 应用的区别。作者指出,Agent 并非简单的“能聊天的 AI”或“能调工具的 LLM”,而是围绕目标持续推进任务的系统。Agent 的核心在于有目标、有过程、有状态、有边界,能够根据观察结果动态决策,并在必要时与人交互。文章还区分了 workflow、Agent 和 multi-agent 的概念,并强调在构建 Agent 系统时应先明确任务契约,再考虑技术实现。
很多人现在一边用 ChatGPT、Copilot、Claude,Codex 一边也在说 Agent。
但一到具体场景,概念就容易混。
有的人把“能聊天的 AI”叫 Agent,有的人把“能调工具的流程”叫 Agent,也有人把任何自动化 workflow 都叫 Agent。
这会带来一个问题:大家都在谈 Agent,但谈的可能根本不是同一件事。
这篇文章想做的,就是把边界校准一下。
Agent 不是“更会回答的聊天框”,也不只是“接了几个工具的 LLM”。它和普通 LLM 应用真正的区别,在于系统是不是围绕“完成任务”来设计,而不是围绕“一次回答”来设计。
Agent 到底是什么,和普通 LLM 应用有什么区别
先看一个很常见的场景。
你把一段会议纪要丢给 AI,说:
帮我总结一下这次会议。
大多数 LLM 应用都能做得不错。
它会给你一份结构还行的摘要,提炼几个重点,顺手列几个待办。
这类能力已经很有价值了。
但如果你把任务改成这样:
请基于会议纪要、Jira 列表和本周上线清单,整理出待办事项、风险项和跨团队依赖,补充缺失信息时可以去查知识库,所有涉及排期调整和责任归属的判断先标记“待人工确认”,最后输出一个可直接发项目群的行动清单。
这时候,问题就不再只是“总结得好不好”了。
系统还得处理很多额外的事:
- • 先读哪些材料
- • 需不需要补查外部信息
- • 中间结果怎么保存
- • 风险和待办怎么分类
- • 哪些地方可以自动判断
- • 哪些地方必须停下来等人确认
- • 最后输出成什么格式才算完成
这就开始接近 Agent 了。
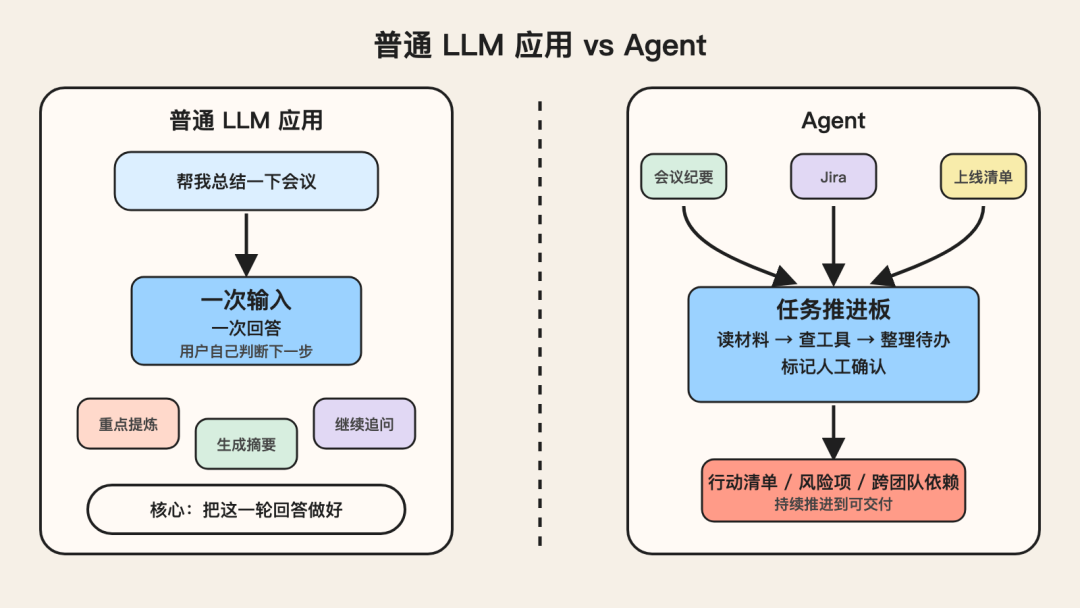
一、普通 LLM 应用,核心是一次回答
先别急着把 Agent 讲复杂。
我们先看“普通 LLM 应用”是什么。
大多数常见 AI 产品,其实都属于这一类。
它们的基本结构很像:
- • 给模型一段输入
- • 可能补一点固定上下文
- • 模型生成一个结果
- • 用户看结果,决定要不要继续问
它当然也可以很好用。
比如:
- • 写一封邮件
- • 总结一篇文章
- • 润色一段文案
- • 翻译一段内容
- • 解释一段代码
这些任务的共性是:
- • 边界相对清楚
- • 输入对象比较集中
- • 结果大多可以在一轮里交付
- • 失败成本通常不高
所以普通 LLM 应用最强的地方,不是“自己推进复杂任务”,而是“在一次交互里生成高质量内容”。
换句话说,它的核心是:
把这一轮回答做好。
这没有任何贬义。
很多工作到这一步就已经足够有价值了。
问题是,一旦任务开始变长、变多步、变动态,普通 LLM 应用就容易吃力。
二、Agent 的核心,不是会回答,而是会推进
Agent 和普通 LLM 应用最大的差别,不在 UI,也不在名字。
而在于系统到底围绕什么来设计。
如果系统围绕“一次回答”设计,它更像普通 LLM 应用。
如果系统围绕“完成任务”设计,它才开始接近 Agent。
所以我更愿意把 Agent 理解成一句话:
Agent 是一个围绕目标持续推进任务的系统。
这里有几个关键词。
1. 有目标,不只是有问题
普通 LLM 应用常常接收的是一个问题。
Agent 接收的更像一个任务目标。
它不只是“回答这个”,而是“把这件事推进到可交付状态”。
所以它通常需要更完整的任务契约:
- • Goal
- • Context
- • Scope
- • Constraints
- • Done
- • Human Check
- • Output
这也是上一篇文章里我为什么一直强调“先把工作说清楚”。
没有这个契约,Agent 很容易看起来很忙,实际上一直在猜。
2. 有过程,不只是有结果
普通 LLM 应用很关心最终输出。
Agent 还必须关心中间过程。
比如:
- • 现在做到哪一步了
- • 前一步拿到了什么观察结果
- • 下一步该调用什么工具
- • 某条信息是否可靠
- • 需不需要重试或改路径
在 Hello-Agents 里,这类过程被拆成了很多经典范式。
比如 ReAct 的核心循环是:
Thought -> Action -> Observation
也就是说,先思考,再行动,再看反馈,然后继续思考下一步。
这已经不是“一次生成一段文本”了。
这是在推进一个任务循环。
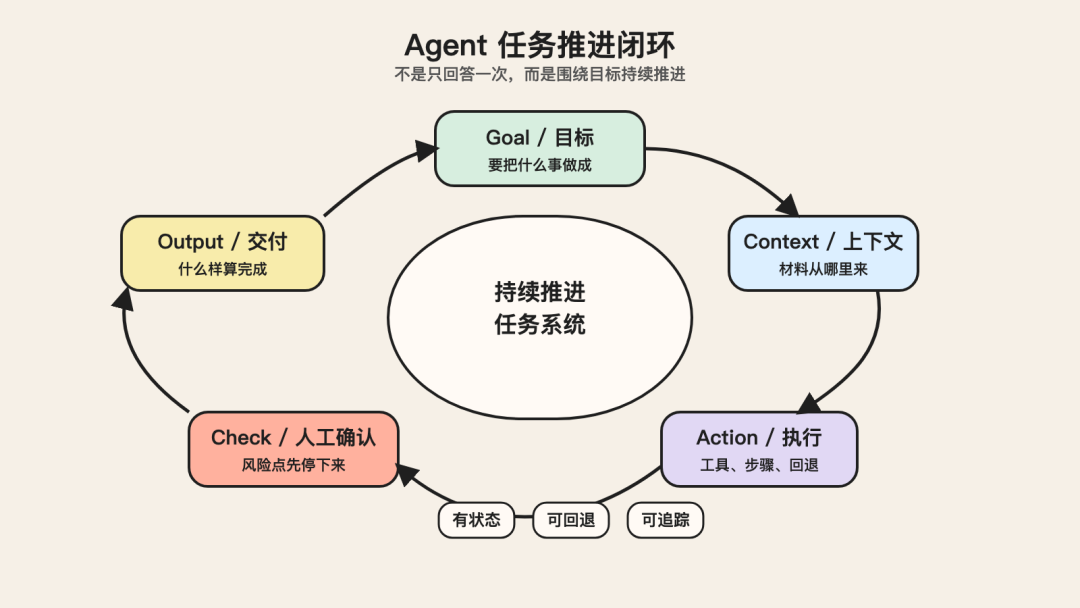
3. 有状态,不只是有上下文窗口
很多人会把“上下文很长”误认为“已经很像 Agent”。
其实不一样。
长上下文只是把更多材料塞给模型。
Agent 需要的是可管理的状态。
比如:
- • 已经读过哪些资料
- • 形成了哪些中间结论
- • 哪些任务已完成
- • 哪些风险待确认
- • 哪些步骤失败过
如果这些东西不能被系统记录、回看、接力,那它往往还只是一个增强版聊天框。
4. 有边界,不是什么都自动做
Agent 不是“越自动越好”。
真正成熟的 Agent,一定会把不能自动决定的地方写出来。
比如:
- • 涉及资源调配的结论,待人工确认
- • 涉及上线延期的判断,待负责人确认
- • 涉及客户信息的内容,禁止自动外发
这不是给 Agent 降级。
恰恰相反,这才说明系统开始进入真实工作流了。
因为真实工作从来不是“能不能生成”,而是“谁该负责什么”。
三、会调用工具,不等于就是 Agent
这是现在最容易混淆的一点。
很多产品只要接了搜索、数据库、浏览器、知识库,就会被说成“Agent 化了”。
但工具调用只是组件,不是结论。
判断是不是 Agent,更关键的是这几个问题:
- • 工具调用是不是围绕明确目标发生
- • 调用结果会不会影响下一步决策
- • 系统会不会根据观察结果调整路径
- • 中间状态有没有被保存和利用
- • 遇到高风险节点会不会停下来交给人
如果只是固定流程里插了一个“调用搜索工具”的步骤,它更像 workflow 加了 LLM。
如果系统能根据目标、观察和约束,动态决定下一步,再把结果带回任务循环里,它才更接近 Agent。
所以工具很重要。
但“会调工具”最多只能说明它具备了 Agent 的一部分能力。
还不能说明它已经是一个真正的 Agent 系统。
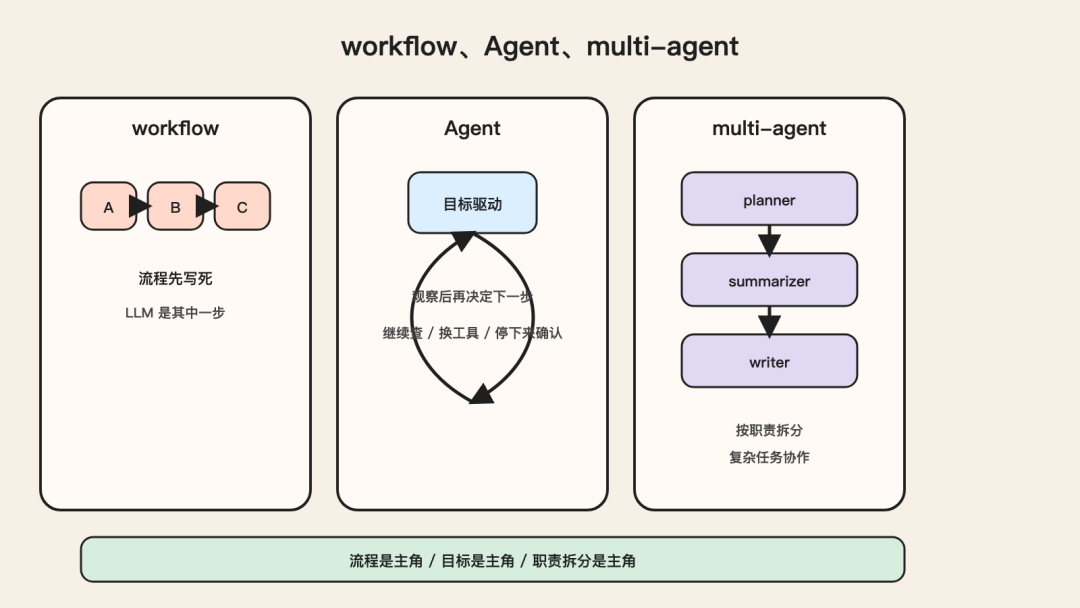
四、workflow、Agent、multi-agent,别混成一团
这几个词现在经常一起出现,但最好分开看。
1. workflow
workflow 更强调固定流程。
先做 A,再做 B,再做 C。
每一步做什么,通常在设计时就写好了。
LLM 可以在里面承担局部任务,比如分类、抽取、改写、总结。
这类系统很好用,也很重要。
Hello-Agents 的介绍里其实就提到了一类类似 Dify、Coze、n8n 的做法,本质上更接近“流程驱动的软件工程类 Agent”。
说白一点,它更像:
流程是主角,LLM 是流程里的一个能力模块。
2. Agent
Agent 更强调目标驱动和动态决策。
它不是完全没有流程,而是流程不再是唯一主角。
系统要允许模型根据观察结果决定下一步:
- • 是继续查
- • 还是先总结
- • 是换工具
- • 还是停下来请求人工确认
说白一点,它更像:
目标是主角,流程围着任务推进服务。
3. multi-agent
multi-agent 不是“更高级一点的 Agent”。
它只是把一个复杂任务,拆给多个职责更单纯的 Agent。
比如在 Hello-Agents 的 deep research 示例里,就拆成了:
- • 负责拆题的 planner
- • 负责阶段总结的 summarizer
- • 负责成稿输出的 report writer
这样做的原因不是“看起来更酷”,而是复杂任务已经不适合让一个单体 Agent 全包。
所以 multi-agent 的前提不是技术冲动,而是职责拆分真的带来收益。
五、普通 LLM 应用和 Agent,真正差在哪
如果只看表面,两者都可能有聊天框、都有模型、都能生成内容。
但如果从系统设计看,它们差别很大。
1. 面向的对象不同
- • 普通 LLM 应用:一次输入,一次输出
- • Agent:一个要被推进到完成的任务
2. 组织方式不同
- • 普通 LLM 应用:围绕回答组织上下文
- • Agent:围绕目标组织步骤、状态、工具和检查点
3. 失败处理不同
- • 普通 LLM 应用:回答不好就重问
- • Agent:要能重试、回退、换路径,或者把问题交还给人
4. 产物定义不同
- • 普通 LLM 应用:最终回答最重要
- • Agent:最终回答重要,但中间轨迹、状态、依据、待确认点也都是产物
5. 责任边界不同
- • 普通 LLM 应用:更多是“辅助你想”
- • Agent:已经开始“替你做一段事”,所以必须把责任边界写清楚
所以我现在越来越不喜欢一种说法:
“Agent 就是能调工具的 LLM。”
这句话太窄了。
更准确一点的说法应该是:
Agent 是一个以目标为中心,能结合上下文、步骤、工具、状态和人工检查,持续推进任务的系统。
六、为什么这件事值得现在讲清楚
因为如果概念不校准,后面很多讨论都会跑偏。
你会发现:
- • 有人在优化 prompt,其实问题是任务契约没写清
- • 有人在堆工具,其实问题是没有状态和回退设计
- • 有人在追 multi-agent,其实单 Agent 还没跑通
- • 有人在做 demo,其实离真实交付还差 review gate 和责任边界
所以“Agent 到底是什么”不是一个名词题。
它其实是一个工程判断题。
你怎么定义 Agent,决定了你后面会怎么搭系统、怎么选框架、怎么接工具、怎么设计人机分工。
七、如果你刚开始学 Agent,先别急着堆框架
我自己的建议还是很朴素。
先别急着比较谁家框架更强,也别一上来就做 multi-agent。
先拿一个真实任务,问自己 7 个问题:
- • Goal 是什么
- • Context 从哪来
- • Scope 到哪停
- • Constraints 有哪些
- • Done 怎么判断
- • Human Check 放在哪
- • Output 要交付成什么
如果这 7 个问题答不出来,做出来的大概率还是“看起来很像 Agent”的 demo。
如果这 7 个问题答出来了,哪怕系统很简单,它也已经开始具备 Agent 的骨架了。
这也是我觉得 Hello-Agents 这套教程真正有价值的地方。
它不是只教你怎么让模型更会说。
它是在带你从“会用 LLM”往“会搭任务系统”走。
而这一步,才是 Agent 学习真正的开始。
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
市场对这一职业的高度认可,直接体现在薪资待遇上。
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


AtomGit AI 社区提供模型库、数据集、Agent、Token等资源
更多推荐


 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)