
00-系列开篇-当上瘾设计遇见AI(系列二-上瘾模型的AI重构)
当上瘾设计遇见AI:产品行为模型的底层逻辑正在被重写
系列二:上瘾模型的AI重构——产品行为设计的进化 | 开篇总揽
从 Hook Model 到 AI-Hook Model,一套重新定义用户行为设计的完整框架。
本文你将获得
- 🧠 上瘾模型的AI重构视角解读框架(理论×产品双重视角)
- 📐 Hook Model 四环节的AI重写路径(含 ChatGPT、Cursor、Perplexity 案例拆解)
- 🎯 AI时代的上瘾模型完整框架(可直接用于产品设计评审)
- ⚠️ 传统上瘾设计在AI产品中的3个失效点(避坑指南)
- 📋 上瘾模型设计检查清单(20项,逐条自检)
- 🔗 从经典理论到AI产品落地的完整映射路径
引言:两种"上瘾",两种体验
凌晨一点,你躺在床上刷 Instagram。
一条 Reels 接着一条 Reels,手指机械地滑动。你知道该睡了,但就是停不下来。第二天醒来,你甚至不记得昨晚看了什么——只记得那种"被钩住"的感觉。
凌晨一点,你坐在电脑前用 Cursor 写代码。
本想改一个简单的 Bug,结果两个小时过去了,你不仅修好了 Bug,还重构了半个模块、写了测试用例、顺便把文档也补齐了。关掉编辑器的那一刻,你感到一阵兴奋:“这东西怎么这么上头?”
两种"上瘾",两种完全不同的体验。
前者是被动上瘾——你被产品设计"钩住"了。推送通知、无限滚动、可变奖励……每一个环节都经过精心设计,目标只有一个:让你停不下来。
后者是主动上瘾——AI 主动适应你,理解你的需求,甚至预测你的下一步。你不是被"钩住",而是被"赋能"了。
这两种上瘾背后的行为设计逻辑,正在发生根本性的变化。
Nir Eyal 的上瘾模型(Hook Model)是过去十年产品设计的圣经。但当 AI 成为产品的核心,这个模型正在被重写——AI 不只是让每个环节更高效,而是从根本上改变了用户行为的驱动机制。
这篇文章,就是这场重写的开始。
一、上瘾模型的经典框架回顾
1.1 Nir Eyal 的 Hook Model 四环节
上瘾模型由 Nir Eyal 在其著作《Hooked: How to Build Habit-Forming Products》中提出,用一个简洁的四环节闭环解释了为什么有些产品让人欲罢不能:
┌─────────────────────────────────────────────────────────────────┐
│ 经典 Hook Model 框架 │
│ │
│ ┌──────────┐ │
│ ┌────▶│ 触发 │────┐ │
│ │ │ Trigger │ │ │
│ │ └──────────┘ │ │
│ │ │ │ │
│ │ ▼ │ │
│ ┌──────────┐ ┌──────────┐ │
│ │ 投入 │ │ 行动 │ │
│ │Investment│◀─────────│ Action │ │
│ └──────────┘ └──────────┘ │
│ │ │ │
│ │ ▼ │
│ │ ┌──────────┐ │
│ └──────────────│ 回报 │ │
│ │ Reward │ │
│ └──────────┘ │
│ │
│ 核心公式:B = M × A × T (行为 = 动机 × 能力 × 触发) │
│ 理论基础:操作性条件反射 (Skinner, 1938) │
│ 心理机制:可变奖励的强化效应 │
└─────────────────────────────────────────────────────────────────┘
触发(Trigger):行为的起点。分为外部触发(推送通知、邮件、广告)和内部触发(无聊、孤独、焦虑等情绪)。当用户产生某种负面情绪时,产品成为"止痛药"。
行动(Action):用户为获得回报而采取的最小行为。Eyal 借鉴了 BJ Fogg 的行为模型:B = M × A × T(行为 = 动机 × 能力 × 触发)。要促成行动,必须同时具备足够的动机、足够低的能力门槛和有效的触发。
回报(Reward):行为后的反馈。关键洞察来自 B.F. Skinner 的操作性条件反射研究——可变奖励比固定奖励更能形成行为习惯。老虎机是最典型的例子:你永远不知道下一次拉动会得到什么,这种不确定性让人上瘾。
投入(Investment):用户在产品中的积累。存储的数据、建立的关系、培养的习惯……这些投入增加了转换成本,让用户"舍不得离开"。更重要的是,用户的投入会影响下一次触发——你发布的内容越多,就越期待收到通知。
1.2 为什么这个模型统治了十年?
Hook Model 之所以成为产品设计的"圣经",是因为它成功解释了过去十年最成功的一批产品:
| 产品 | 触发 | 行动 | 回报 | 投入 |
|---|---|---|---|---|
| 无聊、孤独 | 刷新 Feed | 社交信息、点赞 | 好友关系、内容发布 | |
| 记录生活、获得认可 | 发布照片 | 点赞、评论 | 粉丝、内容档案 | |
| TikTok | 无聊、娱乐需求 | 上滑观看 | 精准推荐的视频 | 观看历史、点赞收藏 |
| Twitter/X | 信息焦虑、表达欲 | 发推、刷推 | 转发、评论、热点 | 关注列表、推文历史 |
这些产品的共同特征是:它们都是"被动消费型"产品。用户被引导进入一个精心设计的行为闭环,在闭环中不断循环,形成习惯。
但 AI 产品的出现,正在改变这一切。
二、AI 如何重写上瘾模型的每个环节
当 AI 成为产品的核心,Hook Model 的每一个环节都在被重新定义。这不是简单的"效率提升",而是底层逻辑的重写。
2.1 触发的重写:从"外部触发"到"主动感知"
传统触发:等待用户产生内部触发(如无聊),或通过外部触发(如推送通知)来激活用户。这是一个"被动等待"或"主动打扰"的过程。
AI 触发:预测用户需求,在用户意识到自己需要之前就主动触发。这是一个"主动感知"的过程。
┌─────────────────────────────────────────────────────────────────┐
│ 触发机制的范式转变 │
│ │
│ 传统触发: │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 用户情绪 │────▶│ 外部触发 │────▶│ 用户行动 │ │
│ │ (被动) │ │ (推送) │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ ↑ │
│ └── 用户必须先产生情绪,或被推送"打扰" │
│ │
│ AI 触发: │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 行为预测 │────▶│ 主动感知 │────▶│ 精准触发 │ │
│ │ (AI分析) │ │ (预判) │ │ (建议) │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ ↑ │
│ └── AI 在用户意识到需求之前就主动建议 │
└─────────────────────────────────────────────────────────────────┘
案例:AI 编程助手的主动触发
当你在 Cursor 中写代码时,你不需要先"感到卡住"再去求助。AI 会监控你的编码模式,在你停顿超过一定时间、或在同一位置反复修改时,主动弹出建议:
┌──────────────────────────────────────────────────┐
│ function calculateTotal(items) { │
│ let total = 0; │
│ for (let i = 0; i < items.length; i++) { │
│ total += items[i].price; │
│ } │
│ // 你在这里停顿了 15 秒... │
│ │
│ ┌────────────────────────────────────────┐ │
│ │ 💡 建议使用 reduce 简化代码: │ │
│ │ return items.reduce((sum, item) => │ │
│ │ sum + item.price, 0); │ │
│ │ [Tab 接受] [Esc 忽略] │ │
│ └────────────────────────────────────────┘ │
│ } │
└──────────────────────────────────────────────────┘
这种触发不是"打扰",而是"赋能"。AI 不是在你不需要的时候推送广告,而是在你真正需要帮助的时候主动出现。
对比分析:
| 维度 | 传统触发 | AI 触发 |
|---|---|---|
| 触发时机 | 用户产生情绪后,或随机推送 | AI 预测用户需要时 |
| 触发精准度 | 低(群发推送) | 高(个性化预测) |
| 用户感知 | “被打扰” | “被理解” |
| 触发成本 | 低(技术简单) | 高(需要 AI 推理能力) |
| 触发效果 | 打开率低,易被屏蔽 | 接受率高,形成依赖 |
2.2 行动的重写:从"点击操作"到"意图表达"
传统行动:用户需要学习产品的操作界面,通过点击、滑动、输入等具体操作来完成任务。能力门槛主要来自"操作复杂度"。
AI 行动:用户只需表达意图,AI 负责将意图转化为具体操作。能力门槛从"操作复杂度"降低到"表达能力"。
┌─────────────────────────────────────────────────────────────────┐
│ 行动门槛的范式转变 │
│ │
│ 传统行动路径: │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 用户意图 │────▶│ 学习操作 │────▶│ 执行操作 │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │ │ │
│ └── 需要转化为 ──┘── 需要记忆 ──┘── 需要精确执行 │
│ 具体操作 操作步骤 多步操作 │
│ │
│ AI 行动路径: │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 用户意图 │────▶│ 自然表达 │────▶│ AI 执行 │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │ │ │
│ └── 直接表达 ──┘── 零学习成本 ──┘── AI 自动完成 │
│ 意图 说人话即可 复杂操作 │
└─────────────────────────────────────────────────────────────────┘
案例:ChatGPT vs 传统搜索
假设你想了解"如何优化 MySQL 查询性能":
传统搜索的行动路径:
- 打开搜索引擎
- 输入关键词"MySQL 查询优化"
- 浏览多个结果页面
- 点击进入某篇文章
- 在文章中寻找相关内容
- 可能需要打开多个标签页对比
- 自己整合信息
ChatGPT 的行动路径:
- 打开 ChatGPT
- 输入:“如何优化 MySQL 查询性能?”
- 阅读整合后的答案
行动步骤从 7 步减少到 3 步,认知负荷大幅降低。
对比分析:
| 维度 | 传统行动 | AI 行动 |
|---|---|---|
| 行动形式 | 点击、滑动、输入 | 自然语言表达 |
| 学习成本 | 需要学习界面操作 | 零学习(说人话即可) |
| 认知负荷 | 高(需要自己整合信息) | 低(AI 整合并呈现) |
| 行动精度 | 取决于操作熟练度 | 取决于意图表达清晰度 |
| 行动效率 | 多步操作,耗时较长 | 单步表达,即时响应 |
2.3 回报的重写:从"可变奖励"到"个性化惊喜"
传统回报:基于 Skinner 的操作性条件反射,通过"可变奖励"制造不确定性,让用户持续期待。老虎机是最典型的例子——你永远不知道下一次会得到什么。
AI 回报:基于对用户的深度理解,提供"个性化惊喜"——不是随机的不确定性,而是精准超出用户预期的价值交付。
┌─────────────────────────────────────────────────────────────────┐
│ 回报机制的范式转变 │
│ │
│ 传统回报(可变奖励): │
│ │
│ 回报价值 │
│ ▲ │
│ │ ★ ★ ★ │
│ │ ★ ★ │
│ │ ★ │
│ │──────────────────────────────▶ 时间 │
│ │
│ 随机分布,用户不知道下一个回报是什么 │
│ 期待来自"不确定性" │
│ │
│ AI 回报(个性化惊喜): │
│ │
│ 回报价值 │
│ ▲ │
│ │ ★ ★ ★ │
│ │ ★ ★ ★ │
│ │ ★ ★ ★ │
│ │ ★ ★ ★ │
│ │──────────────────────────────▶ 使用深度 │
│ │
│ 随使用深度递增,AI 越来越懂你 │
│ 期待来自"被理解" │
└─────────────────────────────────────────────────────────────────┘
案例:AI 推荐系统的进化
传统推荐:基于协同过滤,推荐"和你相似的人也喜欢"的内容。这种推荐是"统计学的"——它知道和你相似的人群喜欢什么,但不知道你此刻真正想要什么。
AI 推荐:基于对用户上下文的深度理解,推荐"你此刻最需要"的内容。这种推荐是"个性化的"——它理解你的当前任务、历史偏好、甚至情绪状态。
| 维度 | 传统推荐 | AI 推荐 |
|---|---|---|
| 推荐依据 | 群体行为数据 | 个体上下文理解 |
| 推荐精度 | 中等(群体平均) | 高(个体定制) |
| 惊喜来源 | 随机发现 | 精准超预期 |
| 用户感知 | “还行,挺准的” | “天啊,它怎么知道我需要这个” |
2.4 投入的重写:从"数据存储"到"能力进化"
传统投入:用户在产品中积累数据、建立关系、培养习惯。这些投入增加了转换成本——“我舍不得离开,因为我已经在这里投入了太多”。
AI 投入:用户的使用本身就是"训练数据"。使用越多,AI 越懂你,体验越好。投入不再是"存储",而是"进化"。
┌─────────────────────────────────────────────────────────────────┐
│ 投入机制的范式转变 │
│ │
│ 传统投入: │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 用户投入 │────▶│ 数据存储 │────▶│ 转换成本 │ │
│ │ (数据) │ │ (积累) │ │ (不舍) │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │
│ └── 投入是"沉没成本",用户"舍不得离开" │
│ │
│ AI 投入: │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 用户使用 │────▶│ AI 学习 │────▶│ 体验进化 │ │
│ │ (行为) │ │ (训练) │ │ (更好) │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │
│ └── 投入是"投资",用户"离不开因为体验越来越好" │
└─────────────────────────────────────────────────────────────────┘
案例:ChatGPT 的"记忆"功能
当你在 ChatGPT 中持续对话时,它会"记住"你的偏好、习惯、常用表达方式。这种记忆不是简单的"数据存储",而是"能力进化":
- 它记住了你的写作风格,下次生成内容时自动匹配
- 它记住了你的技术栈偏好,回答问题时自动选择相关技术
- 它记住了你的项目背景,建议时自动考虑上下文
这种投入带来的不是"转换成本",而是"进化红利"——你用得越多,它越懂你,你就越离不开它。
对比分析:
| 维度 | 传统投入 | AI 投入 |
|---|---|---|
| 投入形式 | 数据、关系、习惯 | 使用行为本身 |
| 投入效果 | 积累存储 | 持续进化 |
| 用户感知 | “舍不得离开” | “离不开” |
| 转换成本 | 外在(数据迁移) | 内在(体验降级) |
| 长期价值 | 静态(积累不变) | 动态(越用越好) |
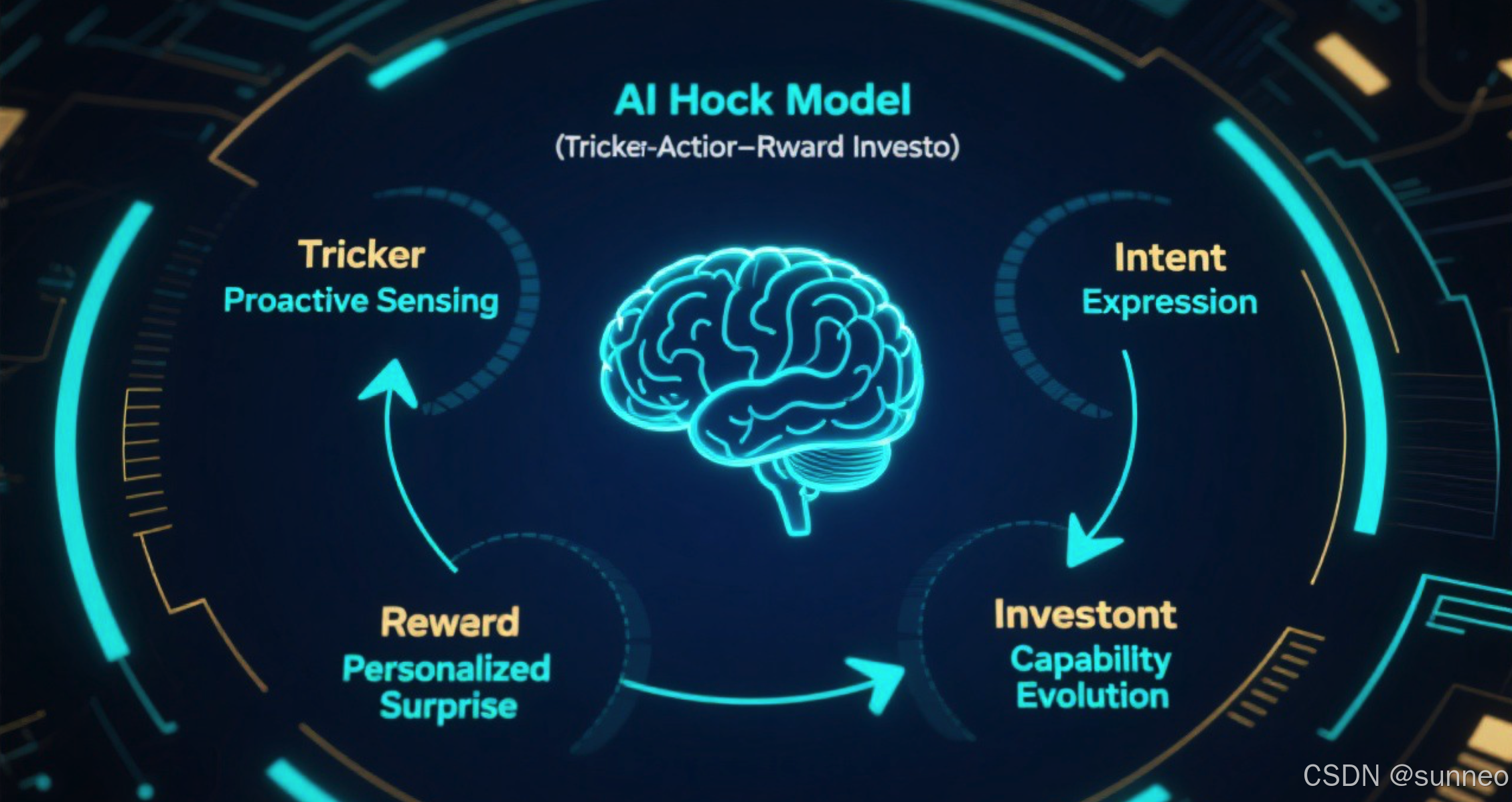
三、AI 上瘾模型的完整框架
将以上四个环节的重写整合,我们可以得到 AI 时代的上瘾模型:
┌─────────────────────────────────────────────────────────────────┐
│ AI 时代的 Hook Model 重构版 │
│ │
│ ┌──────────┐ │
│ ┌────▶│ 触发 │────┐ │
│ │ │ (主动 │ │ │
│ │ │ 感知) │ │ │
│ │ └──────────┘ │ │
│ │ │ │ │
│ │ ▼ │ │
│ ┌──────────┐ ┌──────────┐ │
│ │ 投入 │ │ 行动 │ │
│ │ (能力 │◀─────────│ (意图 │ │
│ │ 进化) │ │ 表达) │ │
│ └──────────┘ └──────────┘ │
│ │ │ │
│ │ ▼ │
│ │ ┌──────────┐ │
│ └──────────────│ 回报 │ │
│ │ (个性化 │ │
│ │ 惊喜) │ │
│ └──────────┘ │
│ │
│ 核心转变: │
│ · 触发:从"被动等待/主动打扰"到"主动感知预测" │
│ · 行动:从"操作界面"到"意图表达" │
│ · 回报:从"可变奖励"到"个性化惊喜" │
│ · 投入:从"数据存储"到"能力进化" │
└─────────────────────────────────────────────────────────────────┘
3.1 经典模型 vs AI 模型对比
| 维度 | 经典 Hook Model | AI Hook Model |
|---|---|---|
| 触发机制 | 外部触发 + 内部触发 | 主动感知 + 预测触发 |
| 行动门槛 | 降低操作复杂度 | 自然语言零门槛 |
| 回报形式 | 可变奖励(不确定性) | 个性化惊喜(超预期) |
| 投入价值 | 数据存储,转换成本 | 能力进化,体验升级 |
| 上瘾类型 | 被动上瘾(被钩住) | 主动上瘾(被赋能) |
| 用户感知 | “我停不下来” | “我离不开它” |
| 伦理风险 | 操纵用户行为 | 过度依赖风险 |
3.2 AI 上瘾模型的设计原则
| 原则 | 说明 | 反面做法 |
|---|---|---|
| 感知精准原则 | 触发必须基于对用户需求的准确预测 | 在用户不需要时频繁推送 |
| 意图理解原则 | 行动门槛应降到"表达意图"即可 | 要求用户学习复杂操作 |
| 惊喜真实原则 | 回报必须真正超出用户预期 | 用随机奖励制造虚假惊喜 |
| 进化可见原则 | 投入带来的进化应让用户感知到 | AI 学习但对用户不可见 |
四、系列预告
本系列将深度拆解 6 个核心主题,探索 AI 如何重构产品行为设计的每一个维度:
| 编号 | 文章标题 | 核心问题 | 关键理论 |
|---|---|---|---|
| 01 | 当上瘾设计遇见AI(本文) | Hook Model 如何被重写? | Hook Model、AI 重构框架 |
| 02 | 推荐算法如何"劫持"信息缺口理论 | AI 如何制造精准缺口? | 信息缺口理论、好奇心驱动 |
| 03 | 损失厌恶的订阅产品应用 | AI 如何放大损失感知? | 损失厌恶、前景理论 |
| 04 | 社会证明的AI升级 | AI 如何重构社会证明? | 社会证明原理、从众效应 |
| 05 | 稀缺性策略的新形态 | AI 时代的稀缺性是什么? | 稀缺性原理、FOMO 效应 |
| 06 | 上瘾设计的伦理边界 | AI 上瘾设计的红线在哪里? | 伦理框架、负责任设计 |
五、写给谁看?
本系列的目标读者包括:
- AI 产品经理:希望理解 AI 产品行为设计的底层逻辑,从"功能思维"升级到"行为设计思维"
- AI 应用开发者:希望在自己的 AI 产品中融入行为设计,提升用户留存和活跃度
- 交互设计师:希望了解 AI 时代的交互设计新范式
- 对 AI 产品化感兴趣的研究者:希望看到学术理论与产品实践的结合
如果你属于以上任何一类,这个系列就是为你准备的。
六、一个邀请
在正式进入下一篇之前,我想邀请你做一件事:
回想一下你最近使用 AI 产品时"离不开"的经历。是什么让你持续回来?是哪个瞬间让你感到"它真的懂我"?那个瞬间背后,大概率藏着 AI 重写后的 Hook Model。
带着这个觉察进入本系列,你会发现:好的 AI 产品,不是让你"停不下来",而是让你"离不开"。 而这背后,是一套正在被重写的行为设计系统。
这就是我们要拆解的东西。
🔖 系列连载中
本文属于「上瘾模型的AI重构」系列(开篇)
- 下一篇:《推荐算法如何"劫持"信息缺口理论》
- 关注本博客,第一时间收到更新推送
💎 关注后私信回复"上瘾",获取配套资料:
- AI 上瘾模型设计画布
- 行为设计检查清单(20项)
参考文献:
- Eyal, N. (2014). Hooked: How to Build Habit-Forming Products. Portfolio.
- Skinner, B. F. (1938). The Behavior of Organisms: An Experimental Analysis. Appleton-Century.
- Fogg, B. J. (2009). A Behavior Model for Persuasive Design. Proceedings of the 4th International Conference on Persuasive Technology.
- Loewenstein, G. (1994). The Psychology of Curiosity: A Review and Reinterpretation. Psychological Bulletin, 116(1), 75-98.
- Schultz, W., Dayan, P., & Montague, P. R. (1997). A Neural Substrate of Prediction and Reward. Science, 275(5306), 1593-1599.
- Kahneman, D., & Tversky, A. (1979). Prospect Theory: An Analysis of Decision under Risk. Econometrica, 47(2), 263-291.

AtomGit AI 社区提供模型库、数据集、Agent、Token等资源
更多推荐
 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)