
Agent时代的Individual Research,什么是我们能把握的?
**从 2024 年底到 2026 年春天,不到一年半的时间,科研,尤其是对于独立研究工作者,这件事已经跟过去完全不是一回事了。****如果要在整个科研史上画一条分界线,2024 年底可能算一条。那之前,AI 是"辅助":是 Copilot 帮着补全一行代码,是 ChatGPT 帮着润色一段英文。那之后,AI 开始变成"主角":它写代码,复现论文,跑实验,一次性读完整个代码仓库,然后指出里面某个算
Agent时代的Individual Research,什么是我们能把握的?
从 2024 年底到 2026 年春天,不到一年半的时间,科研,尤其是对于独立研究工作者,这件事已经跟过去完全不是一回事了。
如果要在整个科研史上画一条分界线,2024 年底可能算一条。那之前,AI 是"辅助":是 Copilot 帮着补全一行代码,是 ChatGPT 帮着润色一段英文。那之后,AI 开始变成"主角":它写代码,复现论文,跑实验,一次性读完整个代码仓库,然后指出里面某个算法的设计缺陷。
我们不禁想问,Agent时代的Individual Research,什么是我们能把握的?
一、AI 如何重塑科研
1.1 从“代码补全”到“任务执行”:AI 工具的四年迁移
过去几年,AI 工具对科研工作的影响,并不是简单地表现为“写作更快”或“编程更快”,而是逐步改变了研究者与计算机交互的基本方式。尤其对计算机、人工智能、软件工程、应用数学、统计学、深度学习、强化学习等方向的研究生而言,AI 工具的角色已经从辅助插件,演变为能够参与设计、实现、调试、复现和文档生成的工作流代理。
| 阶段 | 大致时间 | 代表工具/事件 | 工具形态 | 对科研工作的主要影响 |
|---|---|---|---|---|
| 代码补全时代 | 2021—2023 | GitHub Copilot、ChatGPT | IDE 插件 + 对话式助手 | AI 主要承担代码补全、函数生成、解释代码、辅助写作等局部任务。GitHub Copilot 于 2022 年 6 月正式面向开发者开放;早期研究也显示,在受控实验中,使用 Copilot 的开发者完成任务速度显著提高。(The GitHub Blog) |
| 对话式编程时代 | 2022—2024 | ChatGPT、Claude、Gemini 等 | 浏览器/客户端中的通用助手 | ChatGPT 于 2022 年 11 月发布,使“用自然语言讨论代码、论文、实验设计”成为常规工作方式。(OpenAI) |
| IDE 原生时代 | 2023—2024 | Cursor、Windsurf、Copilot Chat | AI 深度嵌入编辑器 | AI 不再只是外置问答窗口,而开始直接理解代码库、修改多文件、解释依赖关系、辅助重构。Cursor 官方定位为 AI code editor,Windsurf 的 Cascade 则强调多步骤代码编辑能力。(Cursor) |
| 代理雏形时代 | 2024 | Claude 3.5 Sonnet、Devin、Aider、Cline | 可调用工具的 coding agent | Claude 3.5 Sonnet 在 agentic coding 评估中显著提升;Devin 宣称可在沙盒中使用 shell、编辑器和浏览器执行复杂工程任务;Aider、Cline 等开源/半开源工具跑通了“读代码—改文件—执行命令—修复错误”的闭环。(Anthropic) |
| Agent 爆发时代 | 2025 | Claude Code、Codex、MCP、Background Agent | 终端/云端/IDE 中的自主代理 | Claude Code 于 2025 年 2 月随 Claude 3.7 Sonnet 发布;OpenAI 于 2025 年推出 Codex,并在后续发布 GPT-5-Codex、GPT-5.1-Codex-Max、GPT-5.2-Codex 等面向长程软件工程任务的模型;MCP 成为连接模型、工具和数据源的重要协议。(Anthropic) |
| 桌面层与多 Agent 编排时代 | 2026 | Claude Cowork、Claude Design、Codex App、Antigravity、Kiro、Qoder | 桌面代理、多代理并行、跨应用工作流 | AI 开始从“写代码”扩展为“操作电脑、整理文件、生成文档、制作幻灯片、执行跨应用任务”。Claude Cowork 强调在本地文件和应用中完成任务;Claude Design 支持生成 prototypes、slides、one-pagers;Codex App 和 Google Antigravity 都强调多 Agent/任务控制台式工作流。(Anthropic) |
从时间线可以看出,AI 工具的核心变化并不是“模型变聪明”这么简单,而是交互边界不断外移:
第一阶段,AI 只是在光标附近补全代码;第二阶段,AI 可以通过对话参与推理;第三阶段,AI 进入 IDE,开始理解项目级上下文;第四阶段,AI 具备文件编辑、命令执行、浏览器操作、测试修复等工具调用能力;到 2026 年,AI 开始进入桌面层、办公软件层和多 Agent 编排层,成为能够执行较长工作流的任务代理。

Codex vs Claude Code 安装与使用全流程对比表
| 分类 | OpenAI Codex | Claude Code |
|---|---|---|
| npm安装(CLI) | 依赖Node.js ≥18;全局安装:npm install -g @openai/codex验证: codex --version;启动:codex(交互)/ codex "指令" |
依赖Node.js ≥18;全局安装:npm install -g @anthropic-ai/claude-code验证: claude --version;启动:claude(交互)/ claude -f 文件名 "指令" |
| 原生安装(二进制/脚本) | macOS/Linux:brew install codexWindows:WSL2优先;下载GitHub Releases二进制包,解压加入PATH |
macOS/Linux/WSL:curl -fsSL https://claude.ai/install.sh | bashWindows PowerShell: irm https://claude.ai/install.ps1 | iexHomebrew: brew install --cask claude-code |
| App版本安装(桌面端) | macOS:下载Codex.dmg拖拽安装;Windows:微软商店/官网安装包;登录OpenAI账号(ChatGPT Plus/Team) | macOS/Windows:官网下载桌面App;登录Anthropic账号(Claude Pro/Max/Team);支持图形化文件选择、对话管理 |
| 官方订阅配置 | 需OpenAI ChatGPT Plus/Team/Enterprise订阅;或API按量计费;CLI支持账号登录/API Key双模式 | 需Anthropic Claude Pro/Max/Team订阅;Pro含基础Code额度,Max/Team解锁完整能力;CLI支持账号登录/API Key双模式 |
| API配置(密钥/环境变量) | 1. 平台获取OPENAI_API_KEY(sk-开头)2. 临时: export OPENAI_API_KEY="sk-xxx"(macOS/Linux);$env:OPENAI_API_KEY="sk-xxx"(Windows)3. 永久:写入 ~/.zshrc/~/.bashrc或系统环境变量 |
1. Anthropic Console获取ANTHROPIC_API_KEY(sk-ant-开头)2. 临时: export ANTHROPIC_API_KEY="sk-ant-xxx";$env:ANTHROPIC_API_KEY="sk-ant-xxx"3. 永久:写入shell配置或系统环境变量 |
| CC Switch工具配置 | 支持:安装cc-switch,添加OpenAI供应商,填入API Key、Base URL(默认https://api.openai.com/v1),一键切换模型/端点 |
官方推荐:安装cc-switch,添加Anthropic供应商,填入API Key、Base URL(默认https://api.anthropic.com),可视化管理多模型/代理 |
| Skills使用(技能/工作流) | 内置代码生成、重构、调试、文档;自定义Skills:编写codex-skills.json,定义命令/提示模板;命令:codex --skill 技能名 |
内置代码理解、生成、重构、测试、Git集成;Skills管理:claude skills list/install/uninstall;自定义Skills:编写YAML/JSON配置,绑定命令与提示 |
| 自动化办公/脚本集成 | 非交互模式:codex "生成批量重命名脚本" --no-interactive;支持管道/重定向:cat code.py | codex "修复bug" > fixed.py;CI/CD集成、批量文件处理 |
非交互/批处理:claude "批量注释代码" -f *.js -o output/;支持管道、定时任务、Git Hook;自动生成文档、测试用例、部署脚本;MCP协议扩展能力 |
这一轮变化并不只发生在国外工具链中。国内生态也在快速跟进补齐:Qwen Code、Kimi CLI、GLM 系列、OpenClaw 等工具开始覆盖终端编码、Agent 调用、Claude Code 兼容层和个人自动化场景。Qwen Code 已提供 CLI/IDE 相关能力,Kimi Code CLI 支持读写代码、执行 shell、检索网页并自主规划行动;智谱 GLM-5 官方也强调与 Claude Code、OpenClaw 等 agentic coding 工具的兼容性。(GitHub)
因此,更准确的说法是:2024 年以前,AI 更多是“辅助研究者完成任务”;2025 年以后,AI 开始变成“可被委派任务的执行单元”。 这一区别,对科研训练方式、实验节奏、论文生产流程都会产生系统性影响。
1.2 科研范式的整体迁移:从局部提效到流程重组
对研究者而言,AI 带来的影响不应仅被理解为“工具升级”。更深层的变化在于,科研工作中大量原本由人手工完成的中间环节,正在被重新分配给 AI 系统。研究者的核心职责也随之发生迁移:从亲自完成每一个细节,逐渐转向提出问题、设计验证路径、审查结果、控制风险和做最终判断。
| 科研环节 | 传统工作方式 | AI 介入后的典型方式 | 研究者仍需负责的核心判断 |
|---|---|---|---|
| 文献阅读 | 手动检索、逐篇阅读、整理笔记 | AI 定期跟踪 arXiv、目标实验室、会议论文与代码仓库,生成结构化简报(openclaw类工具) | 判断文献质量、识别真正的 gap、避免被 AI 摘要误导 |
| Idea 生成 | 依靠导师讨论、个人积累、组会碰撞 | AI 基于近期文献、已有实验结果、失败案例生成候选研究方向 (claude code,codex类工具) | 判断问题是否重要、是否可验证、是否有理论或应用价值 |
| 代码实现 | 手写样板代码、查 API、调依赖 | Claude Code、Codex、Cline、Aider 等执行多文件修改、测试、调试和重构 | 审查实现是否符合实验假设,避免“代码能跑但结论不成立” |
| 论文复现 | 阅读论文细节、配置环境、修 bug | AI 辅助定位依赖、补齐脚本、解释报错、修改开源代码 | 判断复现是否忠实,区分工程问题与方法本身问题 |
| 数据分析 | 手写统计脚本、画图、调格式 | AI 生成分析脚本、绘图代码、显著性检验、表格草稿 | 判断指标是否合理,避免 cherry-picking 与统计误用 |
| 写作与投稿 | 人工撰写初稿、润色、改格式 | AI 生成初稿、改学术语气、模拟审稿意见、辅助 LaTeX | 保证原创性、论证严谨性、引用准确性和伦理合规 |
| 汇报与展示 | 手工做 PPT、画流程图、录制 demo | Claude for PowerPoint/Excel/Word、Claude Design、Veo、Seedance、Runway 等辅助生成材料 | 控制表达准确性,防止视觉包装掩盖科学问题 |
这一变化在编程密集型学科中尤其明显。过去,研究者需要花费大量时间处理环境配置、样板代码、训练脚本、日志解析、bug 修复和图表生成;现在,越来越多这类任务可以交给 coding agent 处理。OpenAI 的 Codex App 已经明确面向多 Agent 工作流设计,Anthropic 的 Claude Code 也通过 hooks、skills、slash commands、subagents 等机制,将单次问答扩展为可复用、可编排的工程流程。(Claude)
这并不意味着“AI 已经替代研究者”。更准确的判断是:AI 正在替代科研过程中大量低层级、重复性、格式化、工程化的劳动;但对问题价值、实验设计、因果解释、理论贡献和学术责任的判断,仍然需要由研究者承担。
在文字工作上,AI 首先改变的是起草成本。 周报、组会 PPT、课程作业、读书笔记、论文 related work、答辩材料等,都可以先由 AI 生成结构化初稿,再由研究者进行事实核查、逻辑重排和风格统一。Claude for Excel、PowerPoint、Word 等办公软件集成也进一步降低了跨文件处理成本:AI 可以在打开的 Excel、PowerPoint、Word 文件之间共享上下文,读写文件并辅助完成表格、幻灯片和文档修改。(Claude Help Center)
编程是 AI 影响最强烈的环节之一。 对于机器学习、强化学习、统计建模、大数据分析和软件工程方向的研究者而言,手写大量样板代码的必要性显著下降。更常见的工作流正在变成:
- 在通用对话模型中讨论研究问题、方法选择和实验设计;
- 在 Claude Code、Codex、Cline、Aider 等 coding agent 中完成工程实现;
- 让 AI 运行实验、解析报错、修改依赖、生成日志分析脚本;
- 用 AI 辅助整理图表、LaTeX 公式、实验表格和投稿前 self-review;
- 最后由研究者进行结果审查、消融实验补充和论文论证。
这类流程的核心价值不是“省几行代码”,而是把研究者从低价值工程摩擦中释放出来,使更多时间用于问题定义、实验设计和结果解释。Claude 3.5 Sonnet、Claude Code、Codex 系列、Cursor Background Agent、Google Antigravity、Kiro、Qoder 等工具的共同方向,都是让 AI 从“回答问题”转向“完成工程任务”。(Anthropic)
视频生成和可视化工具也在改变科研表达方式。 Veo 3.1、Seedance 2.0、Runway Gen-4.5 等模型已经能够生成较高质量的视频素材,并支持更强的镜头控制、角色一致性或音视频联合生成。(Google DeepMind)
对研究者而言,这类工具的价值主要体现在三类场景:第一,制作算法 demo 或实验现象解释视频;第二,将复杂模型流程转化为更易理解的动画;第三,在答辩、课程展示、科普传播中降低视觉表达门槛。与此同时,OpenAI 已宣布 Sora web/app 将于 2026 年 4 月 26 日停用,API 将于 2026 年 9 月 24 日停用。这个事件标志着openai生成式 AI 的商业重心正在从单点内容生成,转向更稳定、更高频、更可嵌入业务流程的工作流执行。(OpenAI Help Center)
AI 对科研最深层的影响,可能不在写作和编程,而在 idea 生成、文献扫描、实验复现和自动化研究流程。 以 Sakana AI 的 The AI Scientist 为例,该系统尝试将 idea generation、literature search、experiment planning、code writing、experiment execution、figure generation、paper writing 和 review 串成端到端自动化流程。(Sakana AI)
这类系统说明,AI 已经不只是执行单个科研子任务,而是开始模拟完整的研究循环。即使不采用全自动研究系统,研究者也已经可以构建半自动流程:让 AI 每天跟踪 arXiv 和目标实验室论文,每周生成领域动态简报;让 AI 对开源仓库进行依赖分析和复现实验;让 AI 基于已有结果提出下一组消融实验;让 AI 在投稿前模拟审稿人给出批评意见。
但这一环节也最容易产生误判。AI 生成的 idea 往往语言完整、结构清楚,却可能缺乏真正的科学价值;AI 生成的实验计划看似严密,却可能遗漏关键控制变量;AI 生成的论文初稿可能像论文,但未必包含可被同行认可的原创贡献。因此,越是在“自动科研”环节,越需要强调研究者的责任:AI 可以扩大候选空间,但不能替代科学判断。
AI 对科研的重塑不是单点工具替换,而是科研劳动结构的再分配。过去,一个研究生的大量时间消耗在检索、格式、样板代码、调参、报错、画图和初稿写作上;现在,这些环节正在被 AI 系统部分接管。相应地,研究者的核心竞争力也在迁移:
| 过去更重要的能力 | 未来更重要的能力 |
|---|---|
| 手写大量代码 | 设计任务、审查代码、控制实验变量 |
| 从零写作 | 结构化表达、事实核查、论证修正 |
| 手动检索文献 | 建立持续文献监控与筛选机制 |
| 复现单篇论文 | 快速比较多篇方法并判断真实贡献 |
| 单人线性推进 | 人类 + 多 Agent 并行推进 |
| 会使用工具 | 会设计工作流、约束 AI、验证结果 |
二、AI 真的让Research“轻松”了吗?
AI 的确降低了许多任务的执行成本,但它同时引入了新的依赖结构、成本结构、风险结构和认知负担。AI 并没有简单地“减少工作”,而是在重组科研劳动:有些工作被压缩了,有些工作被转移了,也有一些新的工作被创造出来了。
2.1 依赖与额度焦虑:工具越强,切换成本越高
在科研和工程社区中,“用上高水平模型之后很难退回去”已经成为一种普遍体验。 表面看,这只是用户对更好工具的偏好;更深层看,它反映的是工作流依赖的形成。
当研究者习惯了高水平模型在长上下文理解、多文件修改、复杂推理、代码调试和实验规划上的能力之后,次一级模型即使“也能用”,也会在关键任务上显得不够稳定。此时,AI 不再只是一个可替换的工具,而逐渐成为研究者日常工作流中的基础设施。
这种依赖进一步带来额度焦虑、账号焦虑和可用性焦虑。 Claude 官方说明中明确提到,usage limits 决定用户在特定时间段内可以发送多少消息,或可以使用 Claude Code 多长时间;OpenAI 的 ChatGPT 帮助文档也显示,不同套餐存在滚动消息上限,达到上限后会自动切换到较小模型或等待重置。也就是说,对于重度用户而言,“今天额度是否够用”确实会成为一个实际约束,而不是单纯的心理感受。(Claude Help Center)
这种状态对研究者尤其明显:如果一天的实验设计、代码修复、论文润色和组会材料都依赖同一套 AI 工作流,那么额度变化、模型降级、账号异常或网络波动,都会直接影响当天的科研产出。
| 依赖类型 | 典型表现 | 潜在后果 |
|---|---|---|
| 模型能力依赖 | 只愿意把复杂任务交给少数顶级模型 | 次级模型无法替代,工作流弹性下降 |
| 额度依赖 | 大任务前先检查剩余额度或 token 预算 | 工作节奏被平台限制牵引 |
| 账号依赖 | 担心账号异常、风控、支付失败 | 科研计划受到非学术因素干扰 |
| 工具链依赖 | IDE、终端、文档、浏览器都围绕某一套 agent 搭建 | 一旦工具变更,迁移成本高 |
| 心理依赖 | 不再愿意独立完成推导、debug 或写作初稿 | 长期可能削弱独立思考和问题定位能力 |
依赖本身并不一定是坏事。科研本来就依赖计算机、数据库、LaTeX、Git、云服务器和 GPU。问题在于,AI 依赖往往更加集中、更加不透明,也更容易受到额度、政策、区域、账号和服务状态影响。 因此,研究者需要从一开始就意识到:AI 工具应该被纳入科研基础设施管理,而不是仅仅作为聊天窗口使用。
2.2 使用门槛并未消失,只是从“技术门槛”转向“基础设施门槛”
AI 工具降低了很多任务的执行门槛,但并没有消除使用门槛。 相反,对于希望稳定使用第一梯队模型的重度用户而言,门槛正在从“会不会写代码、会不会查资料”,转向“能不能稳定获得模型、账号、支付、网络和算力资源”。
| 层级 | 现实问题 | 主要风险 | For example |
|---|---|---|---|
| 账号层 | 部分用户通过非官方渠道获取账号、共享账号或转售账号 | 账号封禁、隐私泄露、付款纠纷、服务条款风险 | 在 GamesGo、闲鱼、Tele***m 群里买账号,或参与"共享号"。面对 AI 厂商日益收紧的区域政策,有人为一个注册名额宁可重装一遍系统、换一整套指纹 |
| 区域与身份验证 | 部分服务存在区域限制或身份验证要求 | 访问不稳定、合规风险、账号追责困难 | SMS 接码平台(sms-activate、五次方、椰子 SMS 等)购买临时号码用于注册;Google Voice、各国虚拟号码轮换。 |
| 支付层 | 跨境支付、订阅失败、虚拟卡不可用 | 资金损失、支付风控、订阅中断 | 虚拟美国信用卡(Depay、OneKey Card、Bybit Card、WildCard 等),手续费不低,偶尔还会遇到发卡行被大厂封堵。极客们甚至会迈入币圈。 为给虚拟卡充值,有人专门去做币圈交易所的 KYC 实名,买入 USDT,再转入发卡平台——本质上不是为了炒币,只是把 USDT 当成一根"外汇转接管"。 |
| 网络层 | 不同地区访问体验差异明显 | 隐私风险、连接不稳定、账号风控 | 同时订阅多个“科学飞行”防止失效,或者直接买海外 V*S 自建飞行器(Tro**n、Hys***ia、V***S 协议轮番测试)。IP 纯净度、落地国家、住宅 IP 还是机房 IP,成了"日常关注话题"。 |
| API 与中转层 | API 聚合、中转站、兼容层大量出现 | 数据泄露、密钥滥用、账单风险、服务不可控 | CLIProxyAPI、WebAPI、one-api、new-api 这类开源项目大量出现,做"把官方 API 包装成兼容各家客户端的中转层"。顺带诞生了一批商业中转站——市场已接近饱和,价格战正在开打。 |
| 本地算力层 | 本地部署开源模型需要 GPU、内存和工程维护 | 硬件成本高、模型效果不稳定、运维负担重 | 为了在本地跑开源大模型(DeepSeek、Qwen3、GLM),二手卡市场变换莫测。4090、3090、乃至 A100 80G 二手价常年在涨跌之间翻腾。 |
| 国产替代层 | Kimi、Qwen、DeepSeek、GLM 等承担日常任务 | 能力边界、生态兼容性、关键任务可靠性 | 把 Kimi、Qwen、DeepSeek、GLM 作为"日常备胎",保留 Claude/GPT 用于关键任务——这基本是目前多数人的务实选择。 |

这一部分最重要的判断是:AI 的使用成本并不只等于订阅费。 对重度用户而言,真实成本还包括账号稳定性成本、网络环境成本、工具迁移成本、数据安全成本、API 调试成本、本地部署成本,以及因为工具不可用而造成的时间损失。
此外,非官方渠道和绕过限制的使用方式往往存在明确的合规风险。OpenAI 的使用条款禁止规避速率限制、限制措施或安全保护;Anthropic 也明确表示,其服务条款禁止在某些不受支持地区使用服务,并会对违反政策、服务条款或区域政策的账号采取警告、暂停或终止访问等措施。 (OpenAI)
在 AI 成为科研基础设施之后,研究者面对的不再只是“是否会使用 AI”,而是“如何以稳定、合规、可持续的方式使用 AI”。这背后涉及账号、支付、网络、API、隐私、数据安全和本地算力等一整套新的基础设施问题。
2.3 效率悖论:单位任务变快,单位时间的任务变多
AI 最容易制造的误解是:既然单个任务更快完成,那么研究者就会更轻松。现实往往相反。效率提高之后,组织和个人对产出的预期也会同步提高。
已有研究确实证明,生成式 AI 能显著提高一些任务的完成效率。例如,GitHub Copilot 的受控实验显示,使用 Copilot 的开发者完成编程任务的速度快了 55.8%;Noy 和 Zhang 关于写作任务的实验显示,ChatGPT 使平均完成时间下降约 40%,输出质量提高约 18%;Dell’Acqua 等关于咨询任务的研究则提出了“锯齿状技术前沿”概念:AI 对某些任务显著提效,但在另一些看似相近的任务上可能反而降低表现。(arXiv)
这些研究共同说明:AI 的效率提升是真实存在的,但它并不自动转化为人的休息时间。更常见的结果是,任务颗粒度被压小,交付周期被压缩,并行项目数量增加。
| 过去的科研节奏 | AI 介入后的科研节奏 | 结果 |
|---|---|---|
| 复现一个 baseline 需要一到两周 | 期望几天内跑通核心结果 | 复现压力增大 |
| 论文初稿需要长期积累 | 期望快速形成完整 draft | 写作周期压缩 |
| 一个学生主要负责一个项目 | 一个学生同时推进多个方向 | 上下文切换增加 |
| 组会汇报重在阶段性进展 | 期望每周都有可视化结果、图表和 demo | 展示压力增加 |
| debug 是自然消耗时间 | AI 能帮忙后,debug 时间被认为应该显著缩短 | 容错空间变小 |
这就是所谓的效率悖论:AI 降低了单位任务的执行时间,但也抬高了单位时间的产出预期。 对研究者而言,最直接的表现是:以前一个项目由多人协作完成,现在一个人借助 AI 也能完成较大比例的实现;但与此同时,这个人很可能被分配更多项目、更多复现任务、更多材料撰写和更多横向协作。
因此,AI 没有简单地减少工作量,而是改变了工作量的形态:从长周期、低并行、低频反馈,变成短周期、高并行、高频反馈。人的疲劳也随之从“做得慢”转向“切换太快、判断太多、持续在线”。
2.4 思考能力的外包:Research过程中最值得警惕的问题
对研究者而言,AI 最大的风险不一定是写错代码,也不一定是生成错误引用,而是悄悄替代了训练过程中最关键的环节:独立思考。
研究者的核心不只是产出论文,而是形成研究判断力。这种判断力包括:能否识别一个问题是否重要;能否判断一个方法为什么有效;能否从异常实验结果中发现线索;能否看出一篇论文的真正贡献和局限;能否在没有标准答案的情况下推进问题。
这些能力很难通过“看 AI 生成结果”获得。它们往往来自大量低效、痛苦但必要的训练过程:自己推导公式、自己定位 bug、自己复现实验、自己组织论证、自己被审稿人质疑之后重新思考。
近年来的研究也开始提示这一风险。Microsoft Research 与 Carnegie Mellon 的一项研究调查了 319 名知识工作者,收集了 936 个生成式 AI 使用案例,指出知识工作者在使用 AI 时仍会进行目标设定、提示词修正和结果评估,但对 AI 的信心越高,投入批判性思考的努力可能越低。另一项关于 AI 工具、认知卸载与批判性思维的研究也发现,认知卸载在 AI 使用与批判性思维能力之间起到中介作用,即用户越倾向于把思考过程交给 AI,越可能削弱自身的批判性思维表现。(microsoft.com)
如果 AI 长期替代研究者完成 idea 生成、实验设计、理论解释和论文论证,那么研究者可能在短期内产出更多材料,却在长期失去判断问题的肌肉。
可以把 AI 使用分成三种层级:
| 使用层级 | 典型做法 | 对能力训练的影响 |
|---|---|---|
| 工具型使用 | 让 AI 查错、润色、生成代码模板、整理表格 | 风险较低,主要提高执行效率 |
| 协作型使用 | 让 AI 提出候选方案,人类比较、验证、反驳 | 风险可控,有助于扩大思路 |
| 替代型使用 | 让 AI 直接给 idea、结论、推导和论文主张,人类只做排版 | 风险较高,可能削弱独立研究能力 |
更健康的方式不是拒绝 AI,而是避免把最核心的思考过程完全交给 AI。一个可操作的原则是:
凡是决定论文贡献、实验结论和学术判断的环节,应先由研究者独立形成初步判断,再让 AI 扮演反方、审稿人或实现助手,而不是让 AI 先给出结论。
2.5 审稿环境也在变化:流畅但空泛的文字正在贬值
AI 写作能力的提升,还带来了另一个变化:审稿人和会议组织者对“AI 味”文本越来越敏感。这里的关键问题不是某一段文字是不是由 AI 生成,而是文本是否体现了作者对具体问题的真实判断。
在 AI 辅助写作普及之后,论文中更容易出现一些表面规范但实质空泛的表达:背景宏大、术语密集、逻辑平滑,但缺少具体问题锚点;related work 看似完整,但没有真正比较方法差异;contribution 列得很整齐,但没有解释为什么该贡献重要;limitation 写得礼貌,却没有触及方法的真实边界。
这种写作在过去可能只是“普通”,但在 AI 时代会显得更加可疑,因为它太像自动生成的“合理文本”。同时,学术出版界也已经开始更严肃地治理生成式 AI 使用问题。例如,ICML 2025 明确禁止审稿人使用生成式 AI 工具撰写评审,也禁止将投稿内容或评审内容输入生成式 AI 工具;Nature 也在 2026 年报道了 AI 幻觉引用污染科研文献的问题,指出 2025 年的大量出版物可能包含无效引用。(ICML)
因此,AI 时代的论文写作反而更需要作者的“原生判断”。审稿人真正看重的不是文字是否流畅,而是:
| 审稿人关注点 | AI 容易生成的表象 | 作者需要补上的实质 |
|---|---|---|
| 问题是否重要 | 宏大背景与通用动机 | 明确具体场景中的真实痛点 |
| 创新是否成立 | 列出三点 contribution | 说明与已有方法的不可替代差异 |
| 实验是否充分 | 自动生成整齐的表格和消融 | 解释实验为何能支撑核心论断 |
| 局限是否诚实 | 模板化 limitation | 说清楚方法在哪些条件下会失败 |
| 论证是否可信 | 流畅的学术表达 | 可追溯的证据链、代码、数据和引用 |
AI 并没有让科研自动变轻松。它确实减少了许多低层级执行工作,但也带来了新的压力:工具依赖、额度焦虑、基础设施维护、合规风险、任务并行化、认知外包和质量审查。
准确的说:AI 降低了“做出东西”的门槛,但提高了“做出可信、可复现、有判断力的东西”的要求。
三、Agent 时代的 Individual Research:研究者还能把握什么?
这个问题没有终极答案,但能先形成一个阶段性判断:Agent 时代的个人研究能力,不再体现在“是否亲手完成每一个步骤”,而体现在能否定义问题、组织证据、约束 AI、审查结果,并持续形成自己的研究判断。
2025 年以来,AI agent 相关研究与产业应用明显升温;已有综述指出,2025 年提及 “AI Agent” 或 “Agentic AI” 的论文数量超过 2020—2024 年总和的两倍以上。这说明,Agent 不再只是产品宣传词,而正在成为 AI 系统、知识工作和科研工具链的重要组织形式。(arXiv)
3.1 把握 AI:明确人机分工边界
Agent 时代最重要的第一步,不是追逐最新模型,而是重新定义 AI 在科研中的位置。比较稳妥的定位是:AI 是高能力执行层、低成本讨论伙伴和流程加速器,但不应成为问题定义者、最终判断者和学术责任主体。
这一点也符合当前主流 AI 治理框架的基本精神。NIST AI Risk Management Framework 强调对 AI 风险进行治理、映射、度量和管理;OECD AI Principles 也强调可信 AI 应服务于人本价值、透明性、责任和安全性。对于科研工作而言,这些原则可以转化为一个更具体的实践要求:AI 可以参与研究流程,但研究者必须保留决策权、解释权和责任边界。 (NIST)
第一,真问题的选择不完全交给 AI。
“这个问题为什么重要?”“它是否值得投入三年?”“它和我的长期研究方向有什么关系?”这些问题不能只靠 AI 生成的候选列表决定。AI 可以帮助研究者比较方向、补充背景、指出相关工作,但很难替代一个人基于学科积累、现实场景、导师训练和个人兴趣形成的问题意识。
第二,关键实验现象的解读不完全交给 AI。
曲线异常、baseline 反常、某个 setting 下方法突然失效,这些现象往往是研究中最有价值的线索。AI 可以帮助列出可能原因,但研究者必须亲自经历诊断过程。否则,debug 直觉、实验嗅觉和方法敏感度会逐渐退化。
第三,对自己工作价值的陈述不完全交给 AI。
论文 introduction、contribution、limitation、答辩陈述、组会总结,这些位置不是语言包装,而是作者研究判断的集中体现。如果连作者本人都不能用自己的语言解释“这个工作真正解决了什么问题”,AI 写得再流畅,也无法构成扎实的学术贡献。
3.2 把握时代:保留一段“无 AI 时间”
Agent 时代的研究者需要高效使用 AI,但也需要主动保留一段不被 AI 介入的思考时间。这个建议不是反技术,也不是复古,而是为了避免将形成判断的过程完全外包。
Microsoft Research 与 Carnegie Mellon 的研究调查了 319 名知识工作者、936 个生成式 AI 使用案例,发现用户在使用 GenAI 时会进行目标设定、提示修正和结果评估;但当用户对 AI 信心越高时,投入批判性思考的努力可能越低。这个结论对研究者尤其重要:如果 AI 被用于替代“想”的过程,而不仅是加速“做”的过程,长期训练效果可能会受损。(microsoft.com)
专家能力的形成通常需要长期、有目标的练习。Ericsson 等人在 deliberate practice 研究中提出,专家表现来自长期努力改进能力的过程;后续研究也指出,刻意练习并非解释一切,但某种形式的持续训练对于能力提升仍然不可替代。(教育资源信息中心)
因此,Agent 时代更需要一种“认知保留区”:
AI 可以加速执行,但研究者必须保留独立建模、独立推导、独立判断和独立表达的训练时间。
3.3 与成本和解:降低对顶级模型的迷信
很多研究者的焦虑来自一个隐含假设:只要能稳定使用最强模型,研究效率就会显著提升。这个假设只有一部分成立。
顶级模型在长上下文、多步骤推理、复杂代码库理解和跨文件任务中确实有优势。但在大量日常任务中,瓶颈并不是模型能力,而是研究者没有把问题定义清楚。换句话说,很多时候不是“模型不够强”,而是“问题没有被拆解成可以执行的形式”。
Dell’Acqua 等关于知识工作者使用 GPT-4 的研究提出了 “jagged technological frontier” 概念:AI 对某些任务显著提升表现,但对另一些看似相近的任务可能反而造成干扰。这说明,AI 能力边界并不是平滑曲线,不能简单地用“模型越强越好”来替代具体任务判断。(SSRN)
日常任务用稳定、低成本、可替代的模型;关键任务才使用最强模型。 顶级模型应该服务于“硬骨头”:复杂推理、长文档综合、核心代码审查、论文主张反驳、实验路线推演,而不是被消耗在所有小任务上。
这也有助于避免“工具焦虑”变成新的拖延。花大量时间追逐账号、额度、插件、中转和模型切换,并不一定比认真定义一个实验问题更有价值。PLOS Computational Biology 关于科研中使用 AI 的“十条规则”也把“先框定科学问题”放在首位:研究者应先明确自己的科学问题,再判断 AI 是否适合介入,而不是从工具出发倒推研究方向。(PLOS)
3.4 把握自己:重新定义研究的价值
Agent 时代最容易带来的焦虑是:如果 idea 可以由 AI 生成,代码可以由 AI 编写,论文可以由 AI 起草,那么研究的价值在哪里?
这个问题不能用“AI 还不够强”来回避。 更严肃的回答是:研究的价值正在从“完成科研任务”转向“形成研究判断”。任务可以被拆解和委派,但判断难以被完全外包。
当前关于 AI 科学发现的研究也提示了类似边界。Scientific Reports 2025 年的一项研究认为,在其设定的分子遗传学任务中,当前 GenAI 更擅长产生增量式发现,而难以从零产生真正的基础性发现;作者还指出,当前系统难以像人类科学家那样从异常现象中形成原创性假设。这个结论不应被理解为 AI 永远无法创新,但至少说明:在当前阶段,科学判断、异常识别和原创问题形成仍然是人的关键责任。 (Nature)
第一,定义真问题的能力
一个好问题通常同时满足三个条件:有人在乎,尚未解决,在研究者的资源和能力射程之内。AI 可以帮助分析已有问题的优缺点,但很难替研究者找到真正属于自己的问题。
真正的问题意识往往来自具体场景:导师长期训练、实验室设备约束、企业合作需求、工程系统中的失败案例、数据采集中的异常、跨学科交流中的摩擦。这些东西不是单纯从论文摘要中生成出来的,而是长期浸泡在现实问题中形成的。
第二,建立长期判断力,也就是 taste / eye
研究中的 taste 不是审美偏好,而是判断一个方向是否值得投入、一个方法是否真正优雅、一个结果是否异常重要、一个领域是否即将转向的能力。
这种能力通常不能通过短期提示词获得。它来自长期阅读、长期失败、长期复盘,以及对同一类问题持续数年的观察。AI 可以帮助比较观点,但很难替人承担“几年后回头看,这个方向是否真的值得”的判断。
第三,处理不可完全数字化的现实约束
越是具身、现场化、跨组织、长周期的工作,越难被 AI 完全替代。例如:
| 场景 | 为什么难被完全替代 | 对研究者的训练价值 |
|---|---|---|
| 真实设备实验 | 设备状态、噪声、故障和校准无法完全文本化 | 训练工程直觉 |
| 长期数据采集 | 数据漂移、缺失、标注偏差需要现场判断 | 训练数据敏感度 |
| 跨学科合作 | 不同领域术语、评价标准和利益约束不同 | 训练沟通与抽象能力 |
| 企业/工程需求 | 真实需求经常不等于论文中的 clean problem | 训练问题重构能力 |
| 审稿与答辩 | 需要即时回应质疑、解释取舍和承认边界 | 训练学术责任感 |
| 部署与维护 | 系统上线后会暴露实验室环境看不到的问题 | 训练长期可靠性意识 |
这些“脏活”往往不容易被包装成AI demo,但它们恰恰构成研究者从学生走向独立研究员或工程专家的分水岭。
小结
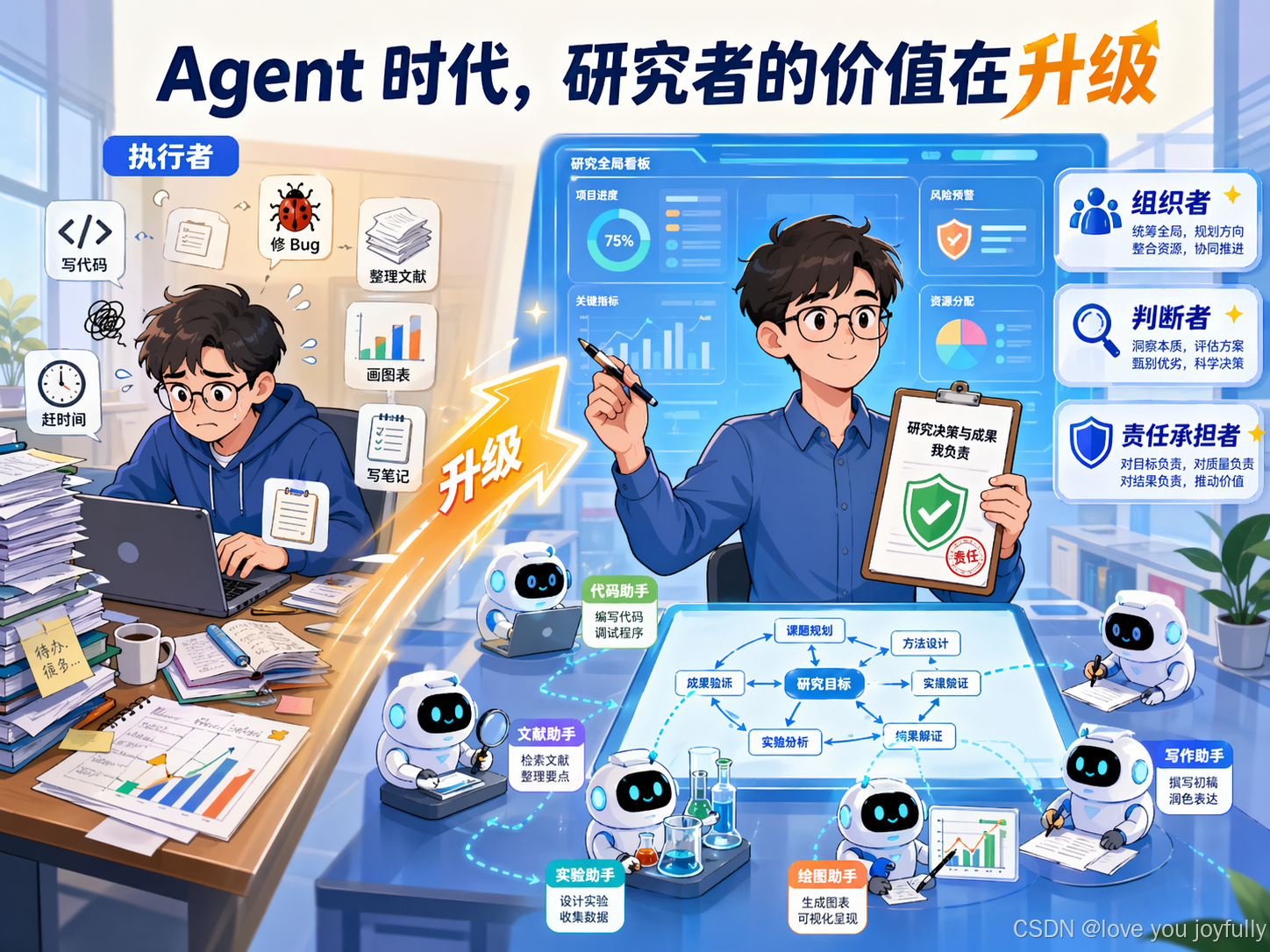
Agent 时代并不意味着个人研究者失去价值。相反,它要求研究者从执行者升级为更高阶的组织者、判断者和责任承担者。
Agent 时代最值得把握的,不是每一个任务都亲手完成,而是始终保留问题意识、判断能力、验证习惯和学术责任。

AtomGit AI 社区提供模型库、数据集、Agent、Token等资源
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)