
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding翻译
我们提出了Imagen,这是一个具有前所未有的逼真度和深度语言理解能力的文本生成图像扩散模型。Imagen基于大型Transformer语言模型的文本理解能力,并结合了扩散模型在高保真图像生成中的优势。我们的关键发现是,使用预训练的仅包含文本的大型语言模型(如T5)在图像合成中出乎意料地有效:增大语言模型的规模比扩展图像扩散模型的规模更能提升样本的保真度和文本对齐度。
摘要
我们提出了Imagen,这是一个具有前所未有的逼真度和深度语言理解能力的文本生成图像扩散模型。Imagen基于大型Transformer语言模型的文本理解能力,并结合了扩散模型在高保真图像生成中的优势。我们的关键发现是,使用预训练的仅包含文本的大型语言模型(如T5)在图像合成中出乎意料地有效:增大语言模型的规模比扩展图像扩散模型的规模更能提升样本的保真度和文本对齐度。Imagen在未经过COCO数据集训练的情况下,达到了新的最先进的FID分数7.27,并且人类评估者认为Imagen生成的样本在图像和文本对齐度上与COCO数据本身相当。为了更深入地评估文本到图像模型,我们引入了DrawBench,一个全面且具挑战性的基准测试平台。通过DrawBench,我们将Imagen与最近的方法(包括VQ-GAN+CLIP、Latent Diffusion Models、GLIDE和DALL-E 2)进行了比较,发现人类评估者在样本质量和图像文本对齐度方面更倾向于Imagen。
Photorealism - 逼真度
Deep level of language understanding - 深度语言理解能力
Transformer language models - Transformer语言模型
Diffusion models - 扩散模型
Sample fidelity - 样本保真度
Image-text alignment - 图像文本对齐度
COCO dataset - COCO数据集
FID score - FID分数(Frechet Inception Distance)
DrawBench - DrawBench(基准测试平台)
VQ-GAN+CLIP - VQ-GAN+CLIP
Latent Diffusion Models - 潜在扩散模型
引言
多模态学习近年来备受关注,尤其是在文本生成图像(text-to-image synthesis)和图像文本对比学习(image-text contrastive learning)方面的应用。这些模型不仅改变了研究界,还在创意图像生成和编辑领域引发了广泛关注。为推动这一研究方向,我们引入了Imagen,一个结合了Transformer语言模型和高保真扩散模型的文本生成图像扩散模型。与之前仅使用图像-文本数据训练的工作不同,Imagen的关键发现是,大型语言模型(如T5)在仅使用文本数据进行预训练时,依然能够非常有效地用于文本生成图像任务。Imagen利用了新的采样技术,使得在使用大引导权重时,图像质量没有下降,生成的图像在保真度和文本对齐度上优于之前的模型。
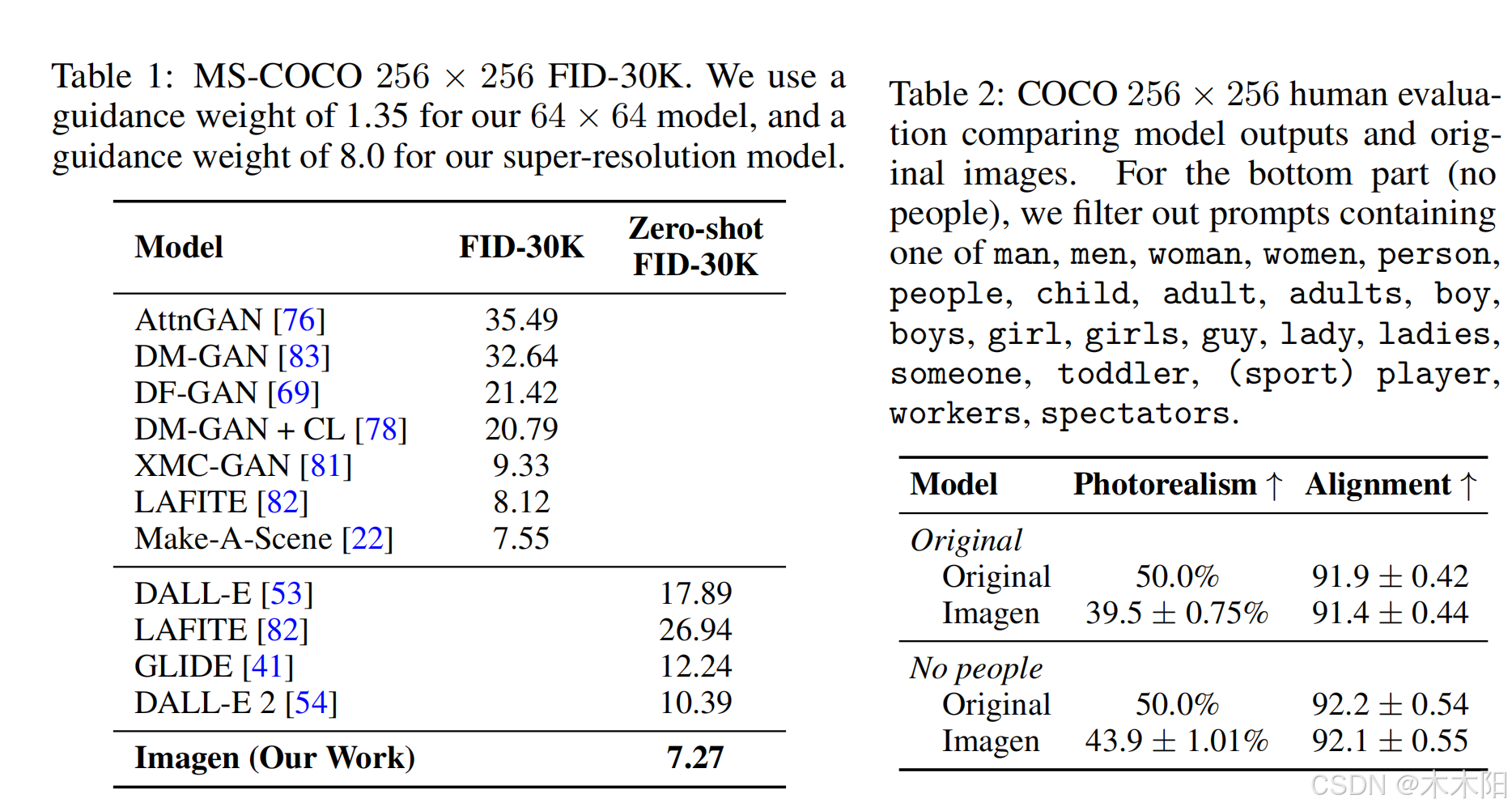
Imagen在COCO数据集上取得了7.27的零样本FID-30K分数,显著超越了GLIDE和DALL-E 2等模型,并且在人类评估中,Imagen生成的样本与COCO数据的文本对齐度相当。我们还引入了DrawBench,这是一个多维度的基准测试平台,用于评估文本生成图像模型。通过DrawBench,Imagen在多个维度上的表现都显著优于其他方法。该研究的关键贡献包括:
- 发现仅使用文本训练的大型冻结语言模型在文本生成图像任务中表现出色,扩展语言模型比扩展图像扩散模型对样本质量的提升更为显著。
- 引入动态阈值技术,使得可以使用更高的引导权重生成更逼真和细致的图像。 提出了一种新的高效U-Net架构,收敛更快,内存效率更高。
- 在COCO数据集上取得了新的最先进的FID分数7.27。引入了DrawBench,一个全面的文本生成图像任务评估基准测试平台,Imagen在该平台上表现优于所有其他模型。
Multimodal learning - 多模态学习
Text-to-image synthesis - 文本生成图像
Image-text contrastive learning - 图像文本对比学习
Transformer language models - Transformer语言模型
Diffusion models - 扩散模型
Text embeddings - 文本嵌入
Classifier-free guidance - 无分类器引导
Sample fidelity - 样本保真度
Image-text alignment - 图像文本对齐度
Zero-shot FID - 零样本FID(Frechet Inception Distance)
DrawBench - DrawBench(基准测试平台)
Dynamic thresholding - 动态阈值
Efficient U-Net - 高效U-Net

Imagen
Imagen模型由一个文本编码器和一系列条件扩散模型组成,用于将文本嵌入转换为逐步提高分辨率的图像。文本生成图像模型需要强大的语义文本编码器,以捕捉复杂的自然语言输入。当前大多数模型使用图像-文本配对数据进行训练,如CLIP模型。然而,像BERT和T5这样的大型语言模型仅通过文本数据进行预训练,且其规模比传统图像-文本模型中的文本编码器要大得多。Imagen选择使用这些预训练的文本编码器(如BERT、T5和CLIP),并将其权重冻结,以减少计算成本。研究发现,扩展冻结的文本编码器比增加扩散模型的规模更能提高图像生成质量。
扩散模型是一类通过逐步去噪将高斯噪声转化为数据分布样本的生成模型。Imagen使用无分类器引导(classifier-free guidance)技术,该技术通过在训练中随机丢弃条件信息来提升图像质量,同时降低多样性。此技术结合调整的预测公式,显著增强了文本到图像的条件生成效果。
Text encoder - 文本编码器
Text embeddings - 文本嵌入
Diffusion models - 扩散模型
Gaussian noise - 高斯噪声
Denoising process - 去噪过程
Classifier guidance - 分类器引导
Classifier-free guidance - 无分类器引导
Image-text alignment - 图像文本对齐度
Image fidelity - 图像保真度
Frozen text encoder - 冻结的文本编码器
BERT - BERT(双向编码器表示模型)
T5 - T5(文本到文本传输模型)
CLIP - CLIP(对比语言-图像预训练模型)
Guidance weight - 引导权重
研究表明,增加无分类器引导权重(classifier-free guidance weight)可以提升图像文本对齐度,但会导致图像过度饱和和不自然。造成这一问题的原因是训练和测试之间的不匹配。为解决此问题,研究引入了静态和动态阈值处理方法。静态阈值处理通过对预测值进行裁剪,防止生成空白图像,但仍会导致图像饱和度过高。而动态阈值处理通过将像素推向中间值,有效防止图像过饱和,提升图像保真度和文本对齐度,特别是在使用高引导权重时效果显著。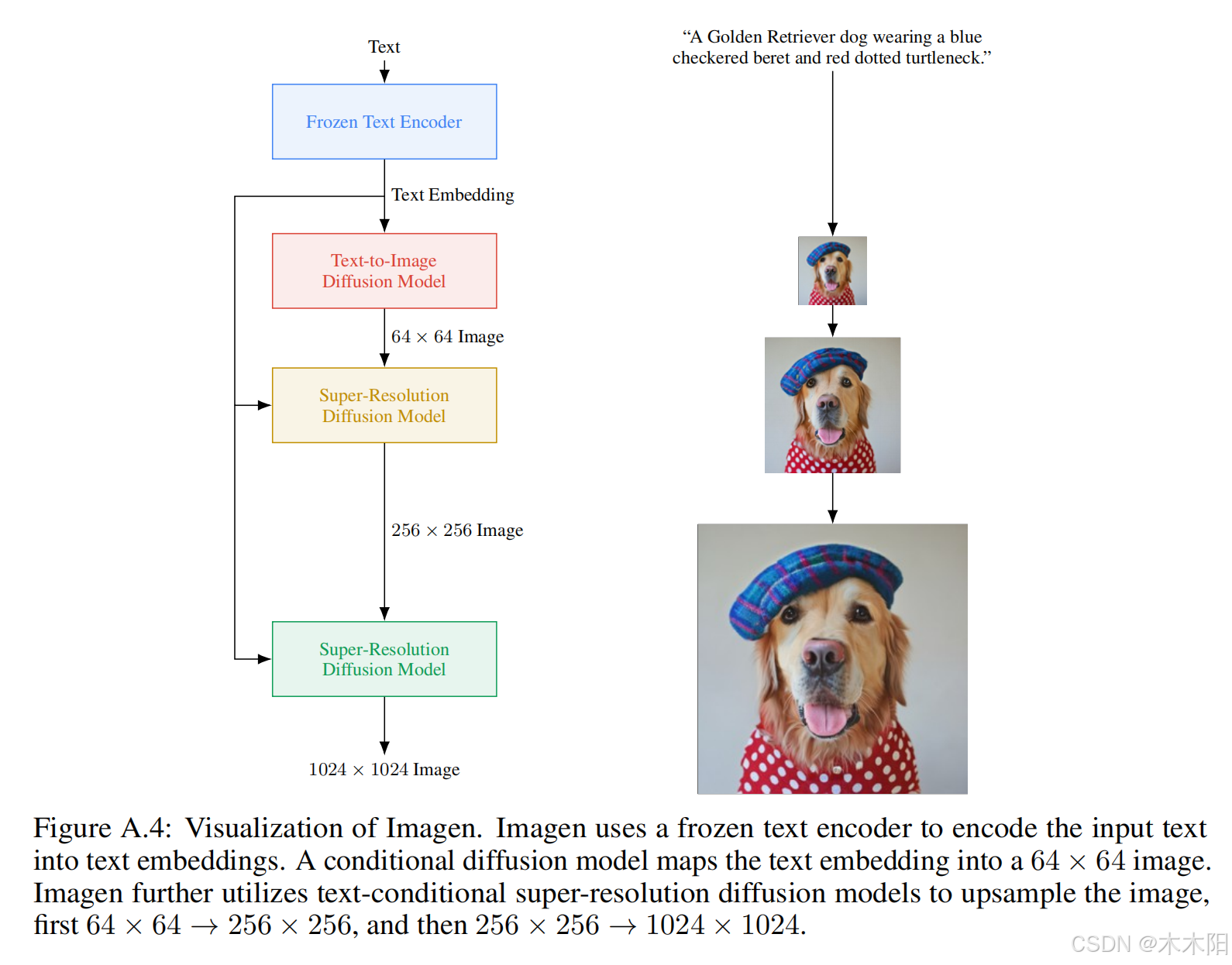
在模型架构上,Imagen使用一个基础64×64的模型,并通过两个超分辨率扩散模型将图像逐步放大到256×256和1024×1024。通过添加噪声条件增强技术,使得超分辨率模型在处理低分辨率模型生成的图像时更具鲁棒性,进而提高生成图像的质量。Imagen的基础模型采用U-Net架构,并在多个分辨率上使用跨注意力机制来增强文本嵌入。超分辨率模型也使用了高效的U-Net变体,显著提高了推理速度和内存效率。
Classifier-free guidance - 无分类器引导
Guidance weight - 引导权重
Static thresholding - 静态阈值处理
Dynamic thresholding - 动态阈值处理
Image fidelity - 图像保真度
Text-to-image diffusion model - 文本生成图像扩散模型
Super-resolution diffusion models - 超分辨率扩散模型
Noise conditioning augmentation - 噪声条件增强
U-Net architecture - U-Net架构
Cross attention - 跨注意力
Layer Normalization - 层归一化
Efficient U-Net - 高效U-Net

GitCode AI社区是一款由 GitCode 团队打造的智能助手,AI大模型社区、提供国内外头部大模型及数据集服务。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)