
(VGG)VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION--Karen Simonyan
本文增加了深度,设计了从11层到19层几种VGG模型,然后通过训练集和测试集多尺度变化进一步提高了性能。在ILSVRC2014大赛上通过多模型融合取得了次于GoogleNet的第二名成绩。总之最大的成就应当是证明了深度对于图像分类的精度是有帮助的...
本文增加了深度,设计了从11层到19层几种VGG模型,然后通过训练集和测试集多尺度变化进一步提高了性能。在ILSVRC2014大赛上通过多模型融合取得了次于GoogleNet的第二名成绩。
总之最大的成就应当是证明了深度对于图像分类的精度是有帮助的
0、摘要
VGG在ILSVRC2014夺得第二名(第一是GoogleNet,也就是InceptionV1),VGG主要使用3x3的滤波器并将网络深度推向更深的16~19层,实现了显著的提升。
并且对其他数据集泛化很好,在其他数据集上取得了最好的结果。
1、引言
- 解决CNN另一个方面:深度
- 为了稳定增长深度,使用了3x3卷积
综上提出了更精准的CNN,不仅在ILSVRC分类和定位任务上取得的最佳的准确性,在其他图像识别数据集也获得优异的性能。
总共发布两款表现最好的模型,以便进一步研究
2、VGG配置
2.1 结构
训练时,输入固定224x224的RGB图像。唯一的预处理是每个像素减去(训练集上计算的)RGB均值。
卷积设置:
- 卷积层使用3x3的小滤波器(另一种配置中还有1x1卷积)
- 固定stride=1
- 为了保持分辨率大小,当卷积核=3时,padding=1
池化设置:
- 空间池化操作由VGG中的5个maxpooling完成(位于Conv层后面,但并非所有Conv都跟有)
- maxpooling大小=2,stride=2
全连接层设置:
- 有三个全连接层
- 前两个有4096通道,最后一个1000个通道(ILSVRC有1000个类)
- 最后再加上softmax层
激活函数:
- 所有隐藏层都有ReLU
所有的Conv和除了最后一个全连接层的所有全连接层后面都有ReLU
(实际上整个网络也只有Conv、MaxPool、Linear三种层+ReLU和Dropout,MaxPool后面肯定加激活,而最后一个Linear后面要跟Softmax)
(BN层是15年出来的,VGG中没有,但是比如在Pytorch的官方vgg实现代码中,可以通过参数batch_norm=True在Conv和ReLU之间加上BatchNorm层)
2.2 配置
从深度和宽度介绍,最后再比较下参数量
VGG总共有5中系列,不同在于深度不同。比如A有11层(8个conv+3个fc),而E有19层(16个conv+3个fc)。
VGG的宽度很小(通道数),从第一层的64开始,每次到maxpooling的下一个conv翻倍,直到最后的512通道总之不同深度的VGG实际上Maxpooling和FC的数量不变,而是每个块(nxConv+1xMaxPooling)中的Conv层数量不同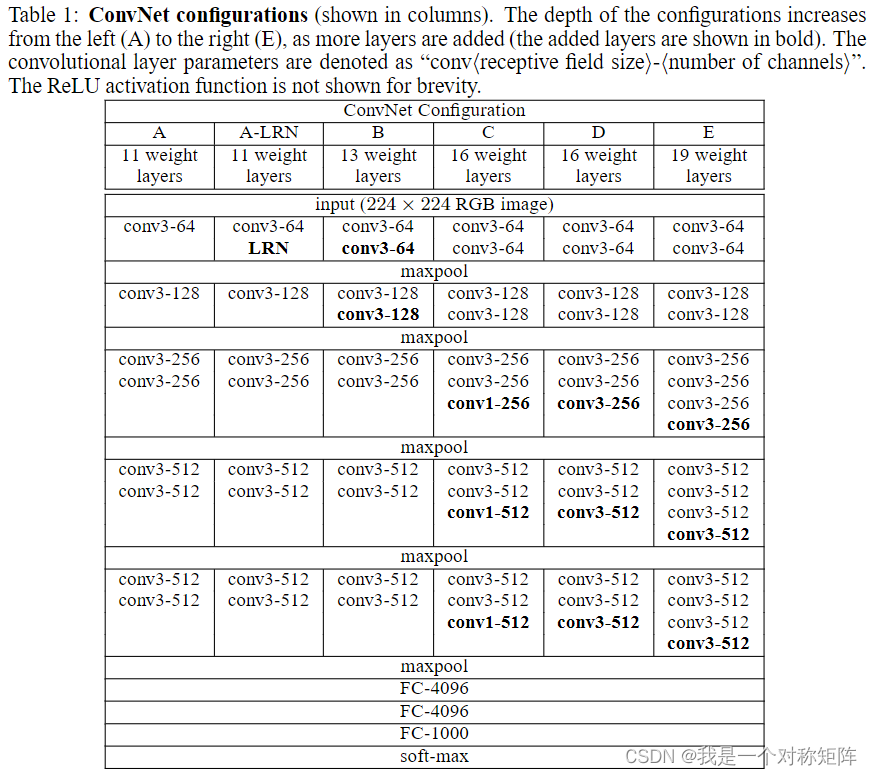
Pytorch的VGG19官方实现,可以看到:
- 最开始是64通道
- 每次MaxPool2d的下一个Conv负责通道翻倍
- 最后是512通道
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 224, 224] 1,792
ReLU-2 [-1, 64, 224, 224] 0
Conv2d-3 [-1, 64, 224, 224] 36,928
ReLU-4 [-1, 64, 224, 224] 0
MaxPool2d-5 [-1, 64, 112, 112] 0
Conv2d-6 [-1, 128, 112, 112] 73,856
ReLU-7 [-1, 128, 112, 112] 0
Conv2d-8 [-1, 128, 112, 112] 147,584
ReLU-9 [-1, 128, 112, 112] 0
MaxPool2d-10 [-1, 128, 56, 56] 0
Conv2d-11 [-1, 256, 56, 56] 295,168
ReLU-12 [-1, 256, 56, 56] 0
Conv2d-13 [-1, 256, 56, 56] 590,080
ReLU-14 [-1, 256, 56, 56] 0
Conv2d-15 [-1, 256, 56, 56] 590,080
ReLU-16 [-1, 256, 56, 56] 0
Conv2d-17 [-1, 256, 56, 56] 590,080
ReLU-18 [-1, 256, 56, 56] 0
MaxPool2d-19 [-1, 256, 28, 28] 0
Conv2d-20 [-1, 512, 28, 28] 1,180,160
ReLU-21 [-1, 512, 28, 28] 0
Conv2d-22 [-1, 512, 28, 28] 2,359,808
ReLU-23 [-1, 512, 28, 28] 0
Conv2d-24 [-1, 512, 28, 28] 2,359,808
ReLU-25 [-1, 512, 28, 28] 0
Conv2d-26 [-1, 512, 28, 28] 2,359,808
ReLU-27 [-1, 512, 28, 28] 0
MaxPool2d-28 [-1, 512, 14, 14] 0
Conv2d-29 [-1, 512, 14, 14] 2,359,808
ReLU-30 [-1, 512, 14, 14] 0
Conv2d-31 [-1, 512, 14, 14] 2,359,808
ReLU-32 [-1, 512, 14, 14] 0
Conv2d-33 [-1, 512, 14, 14] 2,359,808
ReLU-34 [-1, 512, 14, 14] 0
Conv2d-35 [-1, 512, 14, 14] 2,359,808
ReLU-36 [-1, 512, 14, 14] 0
MaxPool2d-37 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-38 [-1, 512, 7, 7] 0
Linear-39 [-1, 4096] 102,764,544
ReLU-40 [-1, 4096] 0
Dropout-41 [-1, 4096] 0
Linear-42 [-1, 4096] 16,781,312
ReLU-43 [-1, 4096] 0
Dropout-44 [-1, 4096] 0
Linear-45 [-1, 1000] 4,097,000
================================================================
几种VGG的参数量,可以看出似乎没有太大的区别,因为参数量绝大部分集中在FC层,从上面这个Param 列可见一斑
3、分类实验
实验是在ILSVRC-2012数据集上进行的,分为训练集、验证集和测试集
对于大多数实验,我们使用验证集作为测试集。在测试集上也进行了一些实验,并将其作为ILSVRC-2014竞赛(Russakovsky等,2014)“VGG”小组的输入提交到了官方的ILSVRC服务器。
3.1 单尺度评估
单尺度就是测试时尺寸固定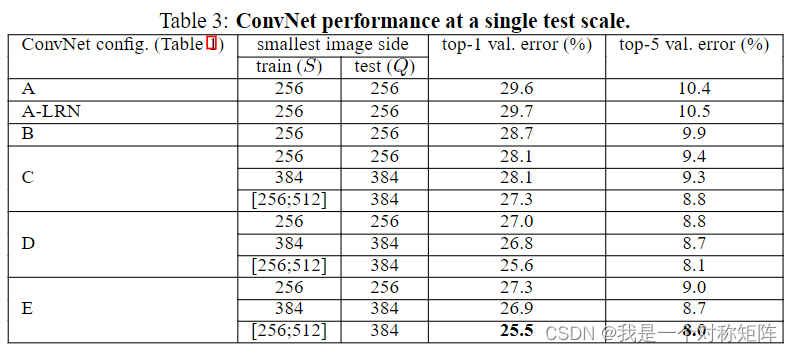
这里首先要注意S和Q的概念:
VGG的输入是固定的224x224,但是原图不一定是这个,也就是224x224是从原图直接裁剪来的。
S为等比缩放的训练图(理解为原图)的最小边(比如270x330则S=270),然后训练的输出是从上面裁剪224x224的图像。
这个S有两种方法来设置:
- 固定:固定S=256或S=384,然后裁剪出224x224的图像作为输入
- 随机:将S随机设置在如[256,512]的范围内的一个值,然后裁剪出224x224的图像作为输入
实际上这个随机方法有点数据增强的感觉,因为同一张图片每次都先缩放到[256,512]的随机尺寸,然后裁剪出224x224的尺寸训练,实际上从效果来看使用了随机的error都比同类型VGG要低。
同时因为ImageNet数据集中物体大小不同,这样不同尺度的缩放可能对于大小物体的分类有益,从而涨点
Q则是测试时图像的最小边,这里是直接将Q的尺寸作为输入图像,那么问题来了训练输入和测试输入不一致,这对于有全连接层的网络是行不通的,所以作者将全连接层(训练好的参数)转换成了卷积层:
- 第一个FC层转换为7x7的Conv
- 后两个FC层转换为1x1的Conv
如果S固定,则Q=S;若S不固定,则S=(Qmax+Qmin)/2
经过最后三个假Conv层得到(尺寸变换的因为与输入尺寸有关,并且通道数等于分类数)特征图,然后将特征图转换为分类分数,原话是“ the class score map is spatially averaged (sum-pooled)”,也就是使用sum-pooling将特征图转换为了分类分数。
这部分更详细的介绍看看vgg net 全连接层改成卷积层,可以对任意宽高的图片进行测试
其次LRN可以看到加了没效果,所以后面也就没加了
然后结论上
- 分类误差随着深度增加而减小
- CD配置一样,只不过D中某些3x3卷积在C中变成了1x1卷积,可以看到使用1x1卷积的C更差。所以使用额外的非线性虽然有帮助(C比B好),但是使用了更大感受野的D更胜一筹,可以捕获上下文。
- 19层的E的误差接近饱和了,但可能适合较大的数据集
- 将B和5x5卷积的浅层比较(将B中2个3x3替换为了5x5,感受野相同),发现5x5浅层的error高了7%,证明小的比大的好
- 抖动的S比固定的S的效果好
3.2 多尺度评估
4.1中讲了测试时尺度固定,多尺度就是测试时尺度不固定。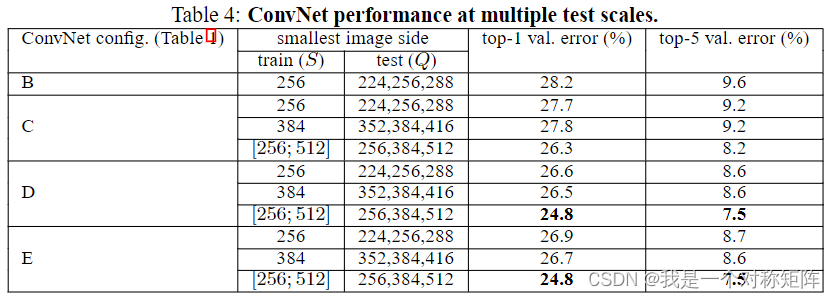
后面的error就是测试时不同尺度Q的均值。
考虑到测试时尺寸与训练时尺寸差太大也不好,所以Q取值= ( S − 32 , S , S + 32 ) (S-32,S,S+32) (S−32,S,S+32),如S不固定则= ( S m a x + S m i n ) / 2 (S_{max}+S_{min})/2 (Smax+Smin)/2
从表4可以看出测试集尺度抖动得到了更好的性能(与表3相比)
3.3 MULTI-CROP EVALUATION
太复杂,而且提升只有2个小数点
VGG神经网络论文中multi-crop evaluation的结论什么意思?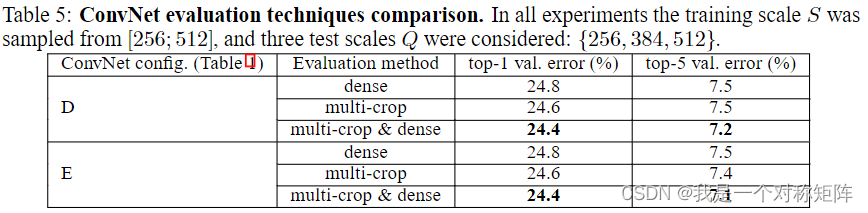
3.4 CNN融合
在ILSVRC12和13年提交过成绩,当时的性能如表6
ILSVRC submission是提交给ILSVRC的,作者训练了7个模型进行融合
post-submission是后面作者融合两个表现最好的多尺度模型组合
(单模型最好的表5的模型E,7.1%的error)
3.5 ILSVRC2014(与最新技术相比)
众所周知,VGG在ILSVRC2014获得了第2名(第一是GoogleNet,即InceptionV1)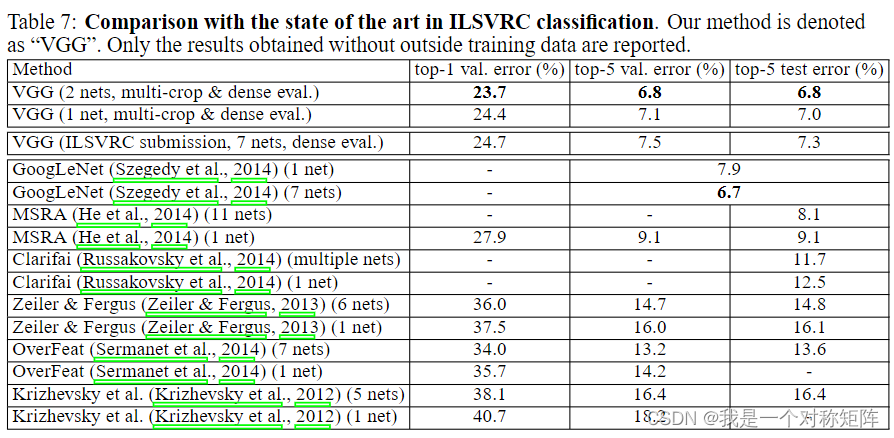
在ILSVRC2014上,GoogleNet成绩是6.7(6.665),VGG是7.3(看提交成绩)
4、结论
评估了非常深的CNN用于大规模图像分类。
证明了深度有利于分类精度,实现了最佳性能。
在附录B还展示了在其他数据集上的泛化能力

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐


 0
0 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)