
通过 SQL 机器学习运行简单的 Python 脚本
以往我们都是将DB中的数据取出供服务器上的应用程序调用使用。不过现在我们可以直接在Azure SQL托管实例/SQL SERVER 2017(14.x) 及更高版本中导入外部语言脚本直接运行,本文将简单讲述一下如何通过SQL机器学习去运行Python脚本。...
目录
(一)前言
以往我们都是将DB中的数据取出供服务器上的应用程序调用使用。不过现在我们可以直接在Azure SQL托管实例/SQL SERVER 2017(14.x) 及更高版本中导入外部语言脚本直接运行,本文将简单讲述一下如何通过SQL机器学习去运行Python脚本。
(二)什么是机器学习服务?
使用 Azure SQL 托管实例中的机器学习服务,你可以在数据库中执行 Python 和 R 脚本。 可以使用它来准备和清理数据、执行特征工程以及在数据库中定型、评估和部署机器学习模型。 此功能在数据所在的位置运行脚本,无需通过网络将数据传输到其他服务器。
使用 Azure SQL 托管实例中支持 R/Python 的机器学习服务,你可以:
-
运行 R 和 Python 脚本以准备数据和处理常规用途的数据 - 现在可以将 R/Python 脚本引入数据所在的 Azure SQL 托管实例,而无需将数据移出到其他服务器来运行 R 和 Python 脚本。 无需移动数据,避免发生延迟、安全性和合规性相关的问题。
-
在数据库中训练机器学习模型 - 可以使用任何开源算法来训练模型。 可以轻松地将训练扩展到整个数据集,而不用依赖于数据库中提取的示例数据集。
-
将模型和脚本部署到存储过程的生产环境中 - 只需将脚本和已训练的模型嵌入 T-SQL 存储过程,便可对它们进行操作。 连接到 Azure SQL 托管实例的应用只需调用存储过程,便可受益于这些模型中的预测和智能功能。 此外,还可以使用本机 T-SQL PREDICT 函数来操作模型,以便在高度并发的实时评分方案中进行快速评分。
(三)如何启用机器学习服务
利用以下 SQL 命令的扩展性,你可以启用 Azure SQL 托管实例中的机器学习服务(SQL 托管实例将重启,并在几秒钟内不可用):
sp_configure 'external scripts enabled', 1;
RECONFIGURE WITH OVERRIDE;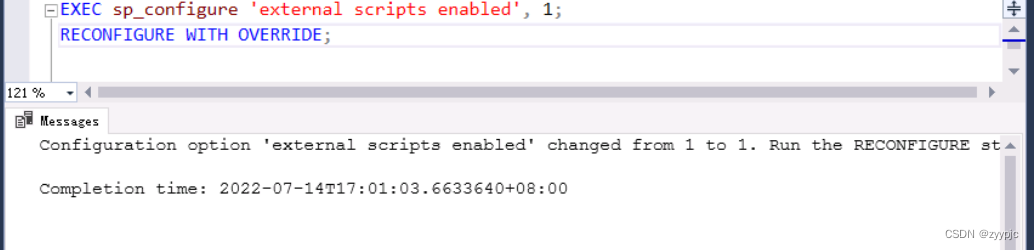
(四)脚本编写规范
1. 格式:
sp_execute_external_script
@language = N'language',
@script = N'script'
[ , @input_data_1 = N'input_data_1' ]
[ , @input_data_1_name = N'input_data_1_name' ]
[ , @input_data_1_order_by_columns = N'input_data_1_order_by_columns' ]
[ , @input_data_1_partition_by_columns = N'input_data_1_partition_by_columns' ]
[ , @output_data_1_name = N'output_data_1_name' ]
[ , @parallel = 0 | 1 ]
[ , @params = N'@parameter_name data_type [ OUT | OUTPUT ] [ ,...n ]' ]
[ , @parameter1 = 'value1' [ OUT | OUTPUT ] [ ,...n ] ]2. 参数
@language = N'language'
指示脚本语言。 语言 为 sysname。 有效值为 R、 Python 和使用 CREATE EXTERNAL LANGUAGE 定义的任何语言 (,例如 Java) 。
@script = N'script' 外部语言脚本指定为文本或变量输入。 脚本 为 nvarchar (max) 。
[ @input_data_1 = N'input_data_1' ]指定外部脚本以 Transact-SQL 查询的形式使用的输入数据。 input_data_1的数据类型为 nvarchar (max) 。
[ @input_data_1_name = N'input_data_1_name' ] 指定用于表示由 @input_data_1 定义的查询的变量的名称。 外部脚本中变量的数据类型取决于语言。 对于 R,输入变量是数据帧。 对于 Python,输入必须是表格格式。 input_data_1_name 为 sysname。 默认值为 InputDataSet。
[ @input_data_1_order_by_columns = N'input_data_1_order_by_columns' ] 用于生成每分区模型。 指定用于对结果集进行排序的列的名称,例如产品名称。 外部脚本中变量的数据类型取决于语言。 对于 R,输入变量是数据帧。 对于 Python,输入必须是表格格式。
[ @input_data_1_partition_by_columns = N'input_data_1_partition_by_columns' ] 用于生成每分区模型。 指定用于对数据进行分段的列的名称,例如地理区域或日期。 外部脚本中变量的数据类型取决于语言。 对于 R,输入变量是数据帧。 对于 Python,输入必须是表格格式。
[ @output_data_1_name = N'output_data_1_name' ]指定外部脚本中变量的名称,其中包含在存储过程调用完成后要返回到SQL Server的数据。 外部脚本中变量的数据类型取决于语言。 对于 R,输出必须是数据帧。 对于 Python,输出必须是 pandas 数据帧。 output_data_1_name 为 sysname。 默认值为 OutputDataSet。
[ @parallel = 0 | 1 ] 通过将参数设置为 @parallel 1 来启用 R 脚本的并行执行。 此参数的默认值为 0 (无并行) 。 如果 @parallel = 1 输出直接流式传输到客户端计算机,则需要该 WITH RESULT SETS 子句,并且必须指定输出架构。
-
对于不使用 RevoScaleR 函数的 R 脚本,使用
@parallel参数可以有利于处理大型数据集,假设脚本可以简单并行化。 例如,将 Rpredict函数与模型结合使用以生成新预测时,设置为@parallel = 1查询引擎的提示。 如果查询可以并行化,则根据 MAXDOP 设置分布行。 -
对于使用 RevoScaleR 函数的 R 脚本,并行处理会自动处理,不应指定
@parallel = 1sp_execute_external_script调用。
[ @params = N'@parameter_name data_type [ OUT | OUTPUT ] [ ,...n ]' ] 外部脚本中使用的输入参数声明的列表。
[ @parameter1 = 'value1' [ OUT | OUTPUT ] [ ,...n ] ] 外部脚本使用的输入参数的值列表。
(五)脚本案列
若要运行 Python 脚本,请将它作为参数传递给系统存储过程 sp_execute_external_script
。 此系统存储过程在 SQL 机器学习的上下文中启动 Python 运行时,将数据传递到 Python,安全地管理 Python 用户会话,并将所有结果返回到客户端。
1. 显示Python版本号:
exec sp_execute_external_script
@language =N'Python',
@script=N'import sys
OutputDataSet = pandas.DataFrame([sys.version])'
WITH RESULT SETS ((python_version nvarchar(max)))
GO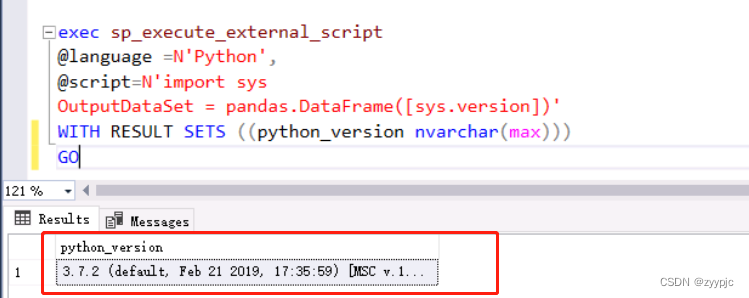
2. 输出一段Select * 语句的结果:
create table zyytest(col1 int,col2 nvarchar(10)) --创建zyytest表
insert into zyytest values(1,'zyy') --在zyytest表中插入数据
--执行脚本并将zyytest表中的字段重命名为NewColName1,NewColName2
EXECUTE sp_execute_external_script @language = N'Python'
, @script = N'OutputDataSet = InputDataSet;'
, @input_data_1 = N'SELECT * FROM zyytest;'
WITH RESULT SETS(([NewColName1] INT NOT NULL,[NewColName2] NVARCHAR(10) NOT NULL));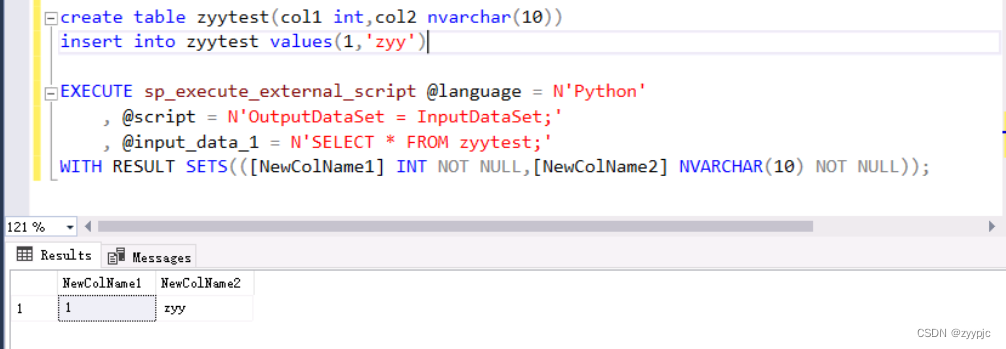
3. Python运算结果后输出
EXECUTE sp_execute_external_script @language = N'Python'
, @script = N'
a = 1
b = 2
c = a + b
print(c)
'
GO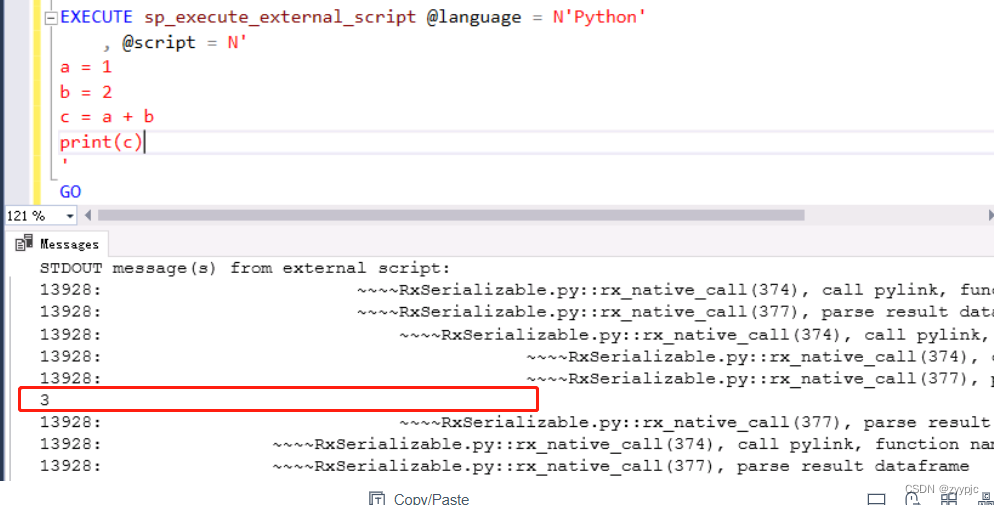

GitCode AI社区是一款由 GitCode 团队打造的智能助手,AI大模型社区、提供国内外头部大模型及数据集服务。
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)