
【大模型入门】一文带你看懂大模型主流厂商和产品
现在各个公司推出的大模型产品花样繁多,但是他们都有基本的技术框架、产品形态,因为他们几乎都是模仿以ChatGPT为代表的GPT系列产品的。正是有了ChatGPT,才让人们认识到大语言模型的强大能力,原来基于一个叫做Transformer(Paper: Attention Is All You Need)神经网络架构、并有着大规模模型参数和大规模预训练数据的模型,可以拥有如此强大的内容生成能力(即涌
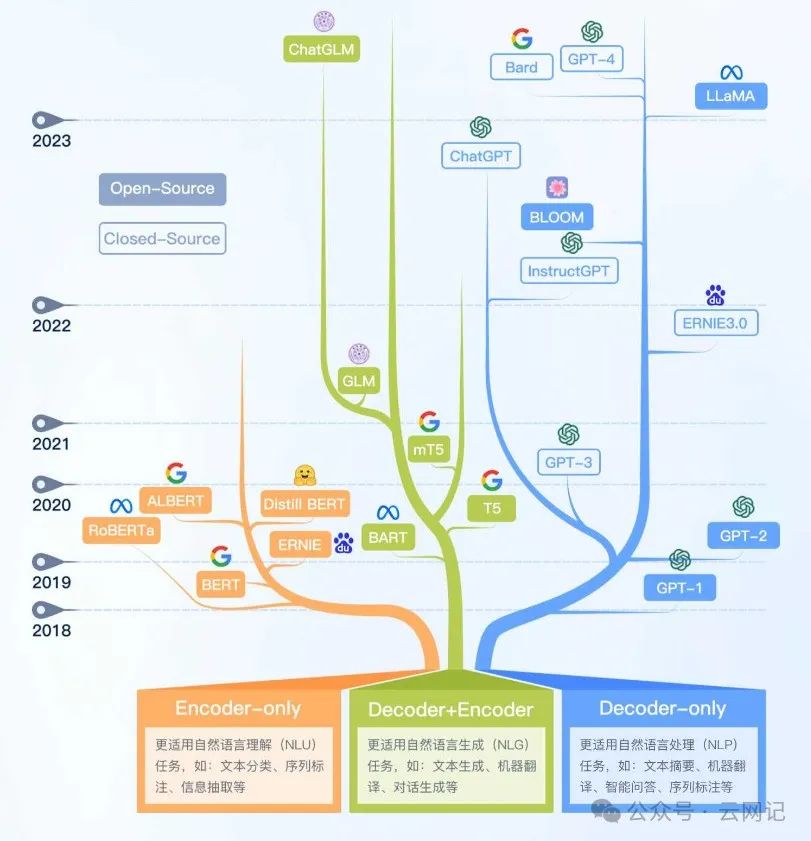
现在各个公司推出的大模型产品花样繁多,但是他们都有基本的技术框架、产品形态,因为他们几乎都是模仿以ChatGPT为代表的GPT系列产品的。
正是有了ChatGPT,才让人们认识到大语言模型的强大能力,原来基于一个叫做Transformer(Paper: Attention Is All You Need)神经网络架构、并有着大规模模型参数和大规模预训练数据的模型,可以拥有如此强大的内容生成能力(即涌现现象,至于为什么会出现涌现现象,大模型内部到底发生了什么,科学家们至今未给出明确的答案)。
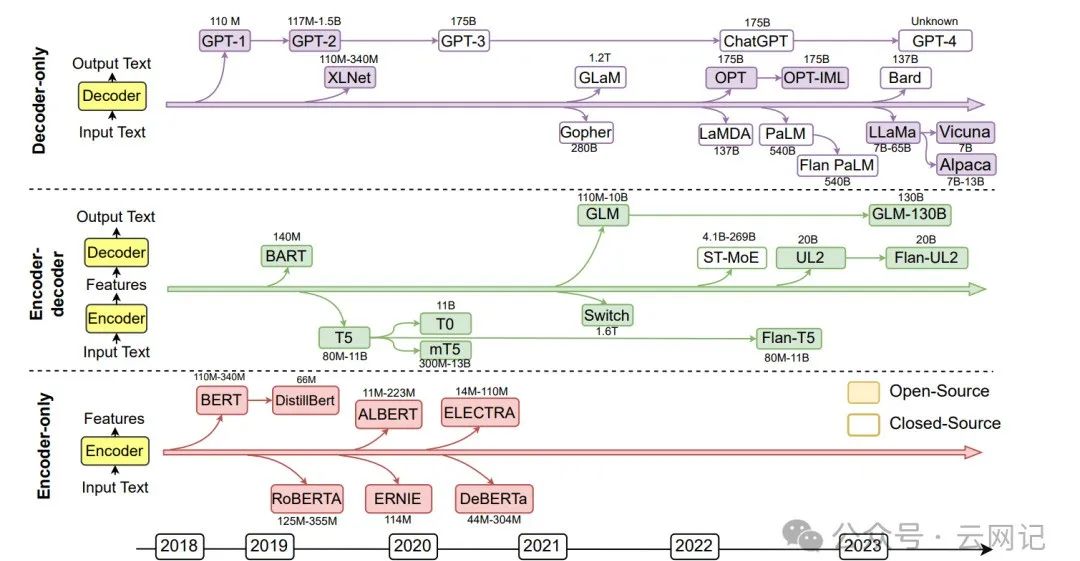
基于Transformer神经网络架构的产品大致可以分为三类:decoder-only LLMs、encoder-only LLMs、encoder-docoder LLMs。下面我们就简要总结各个技术路线的主流产品。
1、 技术路线
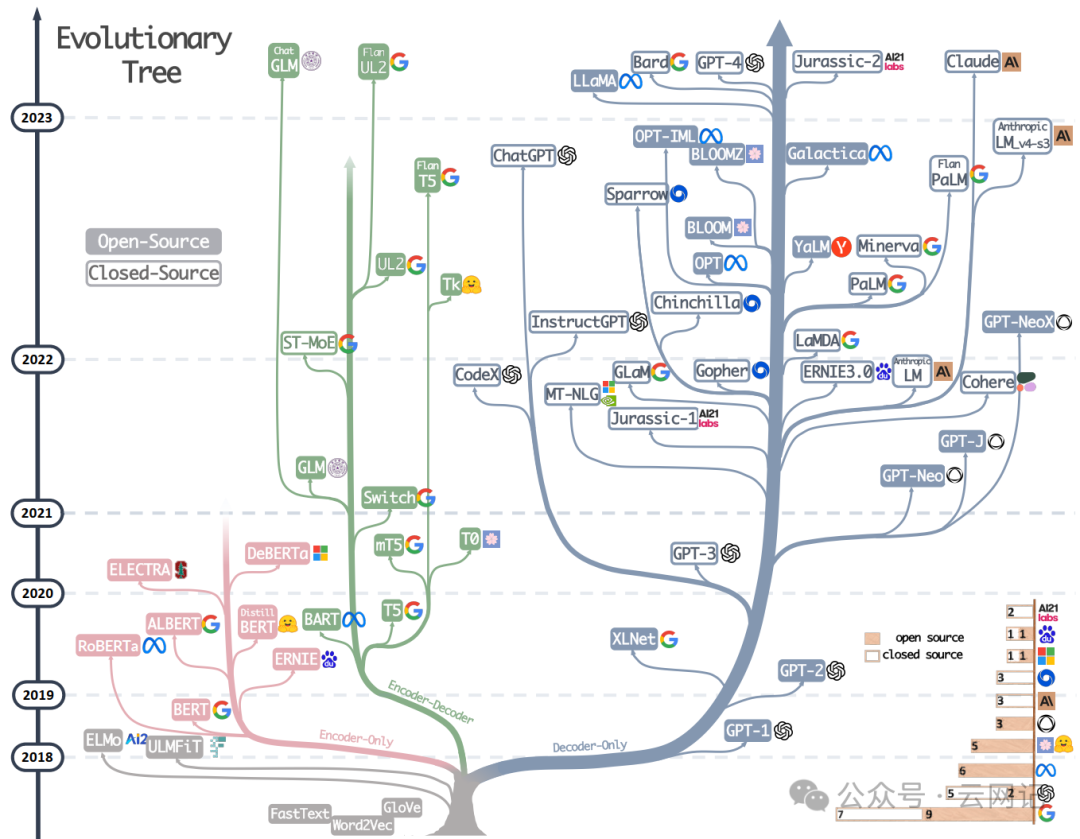
图源论文:Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
上图是一个现代大模型演进树,标识为非灰色的是基于Transformer的模型,可以分为三类:
用蓝色标注的分支是自回归模型(decoder-only LLMs):仅采用解码器模块来生成目标输出文本。很多decoder-only的大模型(如GPT, Generative Pre-trained Transformer)通常可以根据少量示例或简单指令执行下游任务,而无需添加预测头或微调。模型的训练范式是预测句子中的下一个单词。
代表作品:OpenAI公司的GPT系列,对应论文《Generative Pre-trained Transformer: A Comprehensive Review on Enabling Technologies, Potential Applications, Emerging Challenges, and Future Directions》。
用粉色标注的分支是自编码器模型 (encoder-only LLMs):仅用编码器对句子进行编码并理解单词之间的关系(如BERT, Bidirectional Encoder Representations from Transformers),训练模式预测句子中的掩码词语,需要添加额外的预测头来解决下游任务,胜在自然语言理解任务(如文本分类、匹配)。
代表作品:Google公司的BERT系列,对应论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》。
用绿色标注的分支是序列到序列模型(encoder-decoder LLMs):同时使用编码器和解码器模块,编码器模块负责将输入句子进行编码,解码器用于生成目标输出文本。编码器-解码器大模型(如GLM,General Language Model)能够直接解决基于某些上下文生成句子的任务,例如总结、翻译和问答。
代表作品:清华大学的GLM系列,对应论文《GLM- General language model pretraining with autoregressive blank infilling》。
2 、国外大模型产品
2.1、OpenAI公司:技术路线吹哨人,背靠微软打造应用生态
主要产品为GPT系列:
- ChatGPT:基于GPT-3.5开发的对话大模型应用,2022年11月30日OpenAI发布ChatGPT,随即引爆社交网络。
- 新发布的GPT-4o,o代表omni(所有的,表示支持多模态)
- Sora:通过文本生成视频的大模型应用。
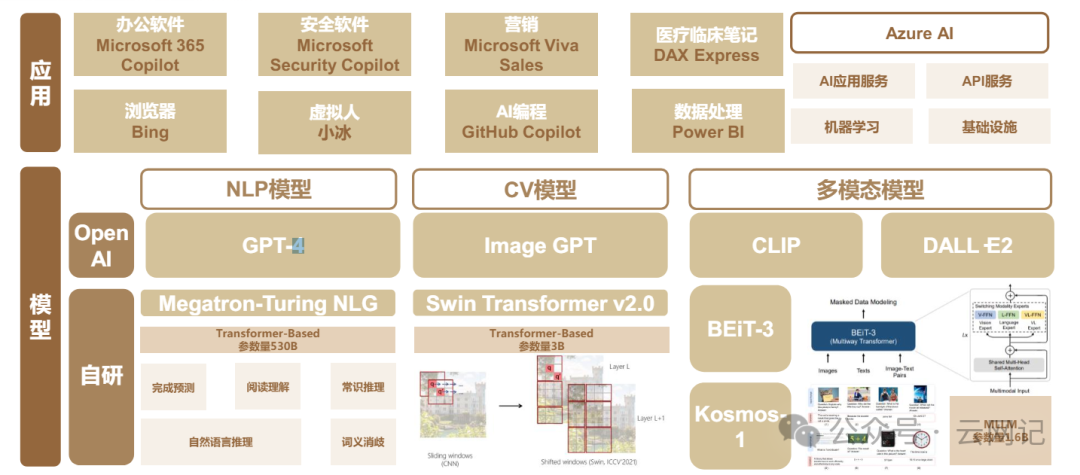
2.2、Google公司:大模型基础Transformer的研发者
- 发明Transformer神经网络架构
- 深度学习框架TensorFlow
- BERT系列大模型
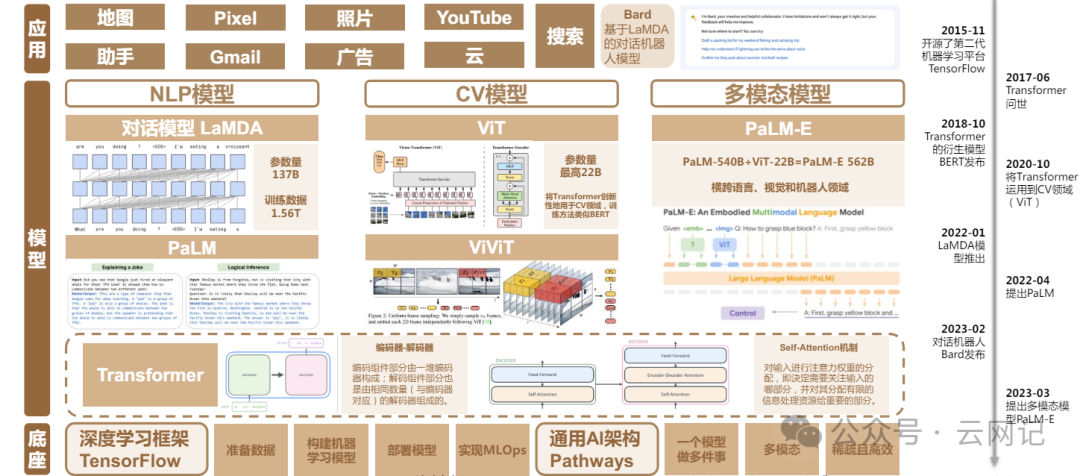
- NLP(自然语言处理,Nature Language Processing)对话模型LaMDA系列
- CV(计算机视觉,Computer Vision)模型ViT
- 多模态模型PaLM-E
- Bard系列大模型
2.3、Mata(元宇宙):Facebook背景,基于大模型完善元宇宙生态
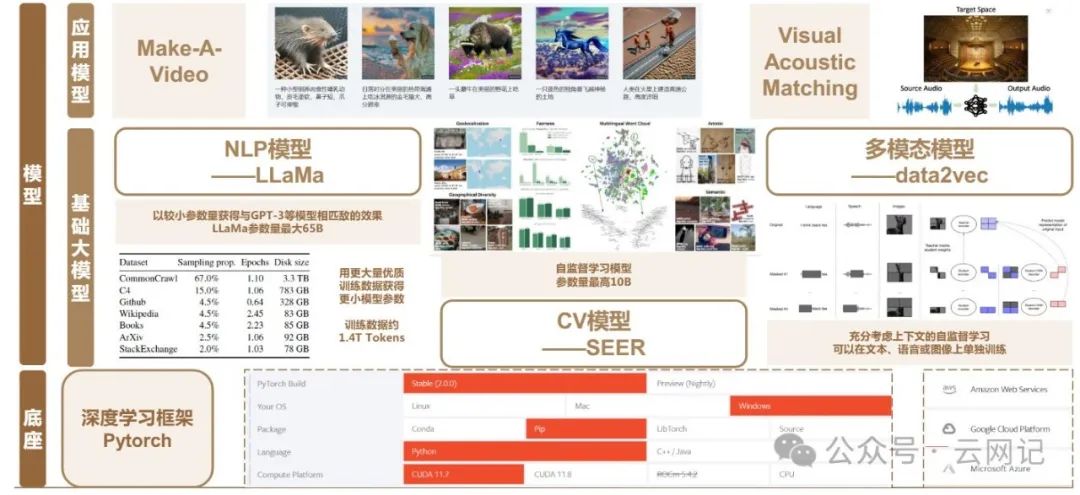
- 深度学习框架Pytorch
- NLP(自然语言处理,Nature Language Processing)对话模型LLaMA系列(LLaMA2,LLaMA3)
- CV(计算机视觉,Computer Vision)模型SEER
- 多模态模型data2vec
3、 国内大模型产品
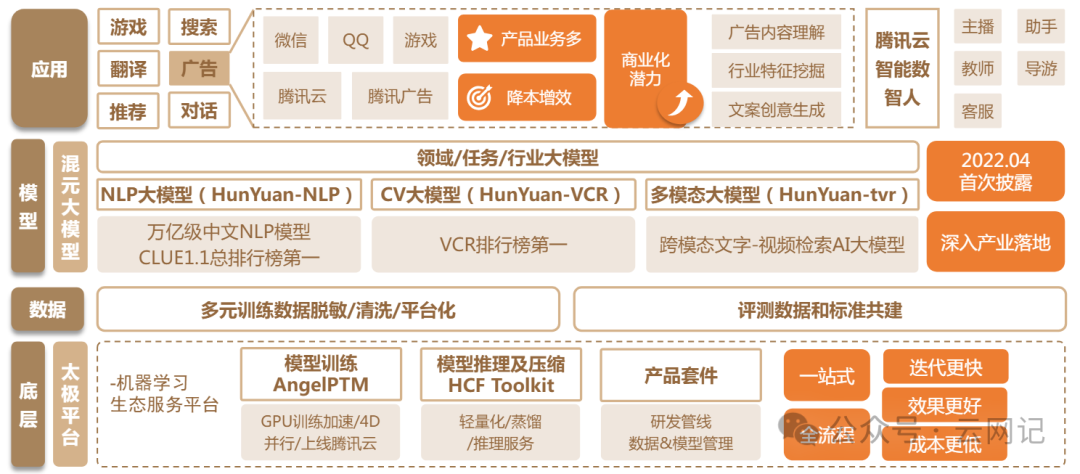
3.1、腾讯
主要基于混元大模型系列产品:
- NLP对话应用:腾讯元宝
- 智能体应用:腾讯元气
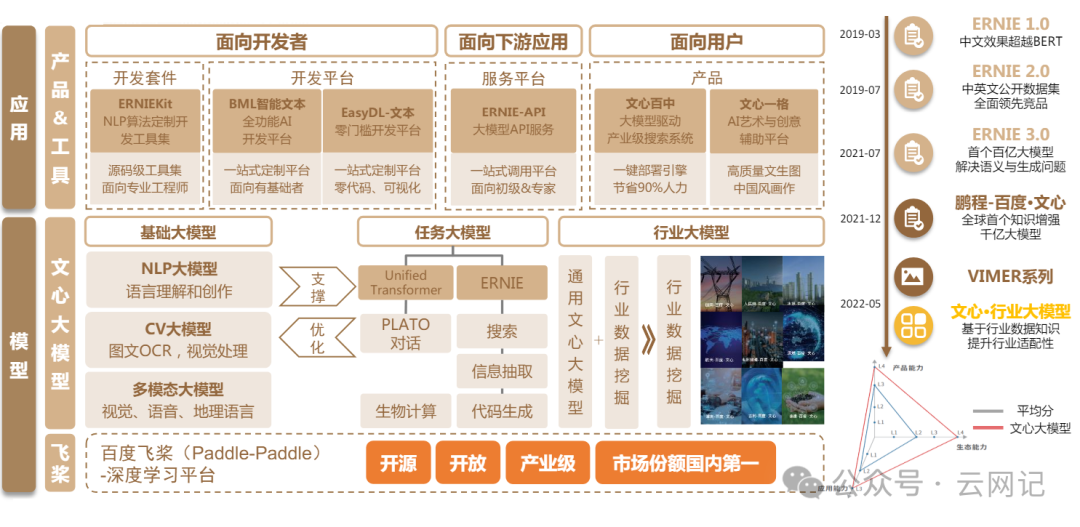
3.2、百度
主要基于文心大模型系列
- NLP对话应用:文心一言
3.3、阿里巴巴
主要基于通义大模型系列:
- NLP对话应用:通义千问
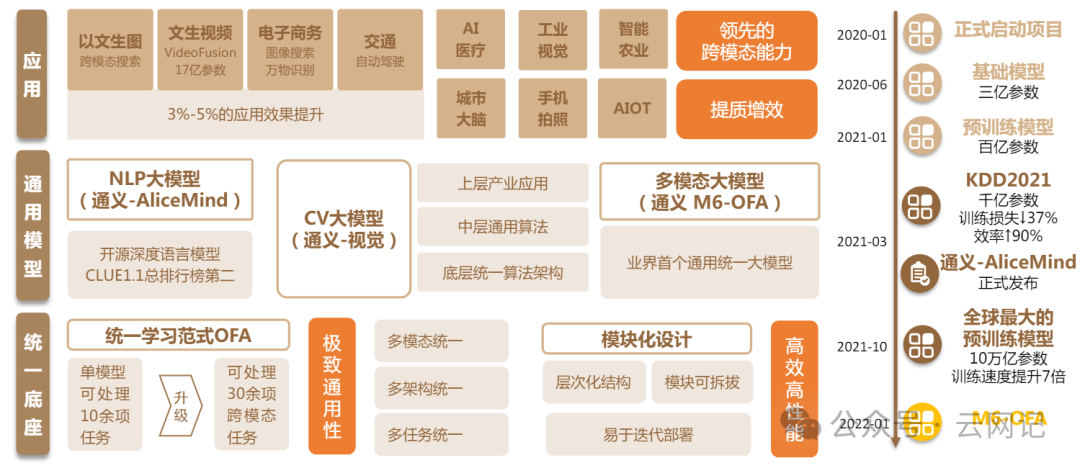
3.4、字节跳动
基于豆包大模型
- NLP对话应用:豆包
- 智能体应用:扣子
3.5、清华
主要基于智谱大模型系列:
- 对话应用:智谱清言
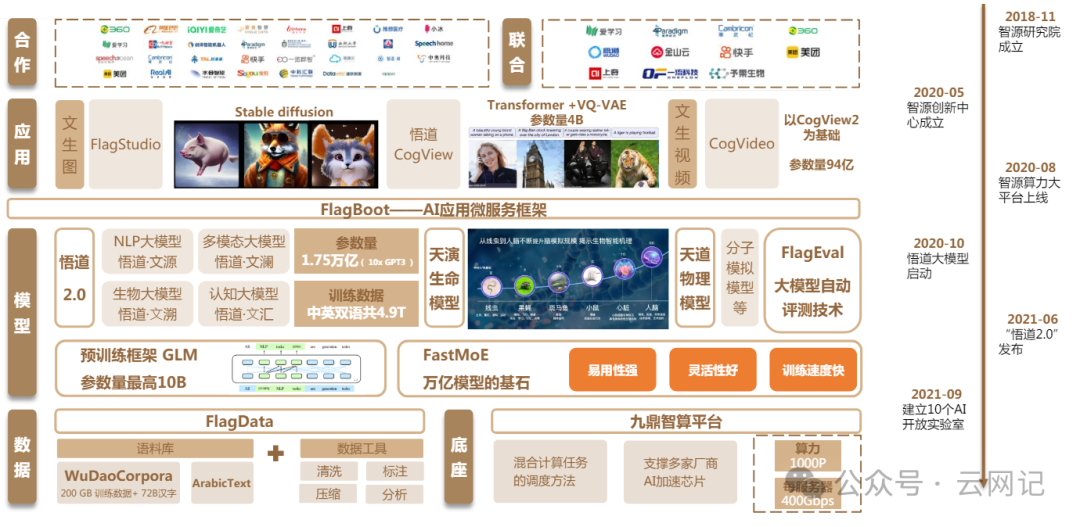
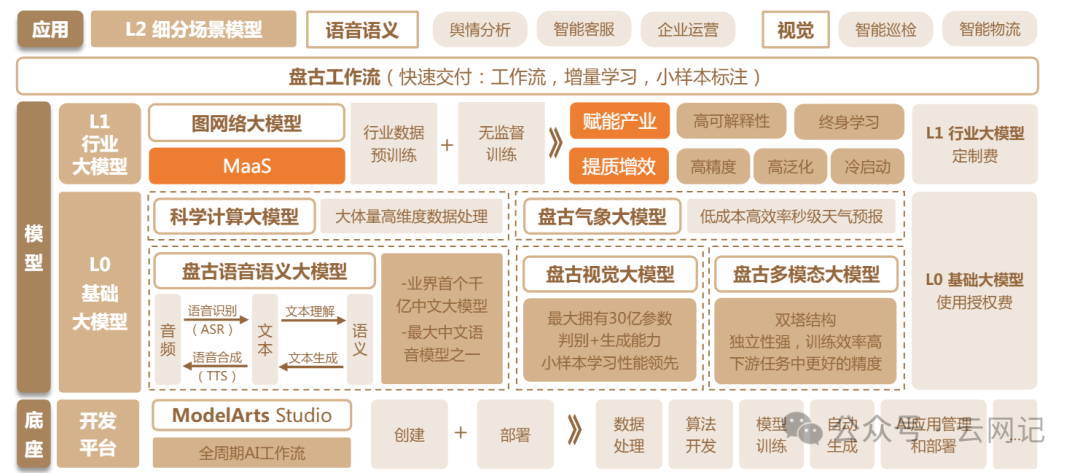
3.6、华为
主要基于盘古大模型系列。与其他公司使用英伟达(NVIDIA)GPU产品(CUDA深度绑定)不同,华为使用自己研发的GPU芯片进行研发,具有完整的自主可控技术栈。
3.7、月之暗面
主要基于moonshot大模型系列:
- 月之暗面kimi
4、 Takeaways
关于NLP对话模型产品,国内性能不错的NLP对话模型产品有腾讯元宝、月之暗面kimi、清华智谱清言、阿里的通义千问等。但是作为普通用户,如果想要减少学习成本,尽早形成自己的使用习惯和知识积累,强烈建议选择科技巨头推出的成熟产品,比如腾讯公司的腾讯元宝,理由如下:
第一,现在国内科技巨头纷纷加入大模型市场竞争,他们在资金、人才、技术、数据、市场等方面有着巨大优势,这让大模型创业公司的机会越来越少。比如腾讯公司在5月30日发布了自家大模型应用“腾讯元宝”,腾讯资金雄厚,人才储备丰富、技术积累深厚、拥有海量用户数据(微信、公众号等腾讯全家桶)、拥有国内用户粘性最高的应用微信,因此留给“小微企业”的机会已经不多了,迟早要接受被洗牌的结局。
第二,国内市场竞争归根到底还是资本的竞争,资本巨头在这近三十年的互联网竞争发展中早已布局完成。
第三,虽然现在还处在跑马圈地的阶段,但是大模型在AIGC方面本质上还是互联网产品,谁拥有流量,谁拥有用户,谁就是最终赢家。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐

 17
17 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)